[논문리뷰] Mesh-RFT: Enhancing Mesh Generation via Fine-grained Reinforcement Fine-Tuning
NeurIPS 2025 (Spotlight). [Paper] [Github]
Jian Liu, Jing Xu, Song Guo, Jing Li, Jingfeng Guo, Jiaao Yu, Haohan Weng, Biwen Lei, Xianghui Yang, Zhuo Chen, Fangqi Zhu, Tao Han, Chunchao Guo
CASIA | UCAS | ByteDance
22 May 2025

Introduction
Direct Preference Optimization (DPO)을 사용하여 메쉬 생성에 강화학습 기반 fine-tuning을 직접 적용하는 데에는 두 가지 주요 문제가 있다.
- 메쉬 품질을 객관적으로 정량화하기 어렵다. DeepMesh는 선호도 쌍에 대한 수동 주석에 의존하는데, 이는 비용이 많이 들고 시간이 오래 걸리며 주관적인 편향을 유발하고 학습 데이터를 5,000개 샘플로 제한하여 일반화 성능을 저해한다.
- 글로벌 reward 신호를 사용하기 때문에 3D 메쉬에 내재된 로컬 위상 변화를 포착하지 못한다.
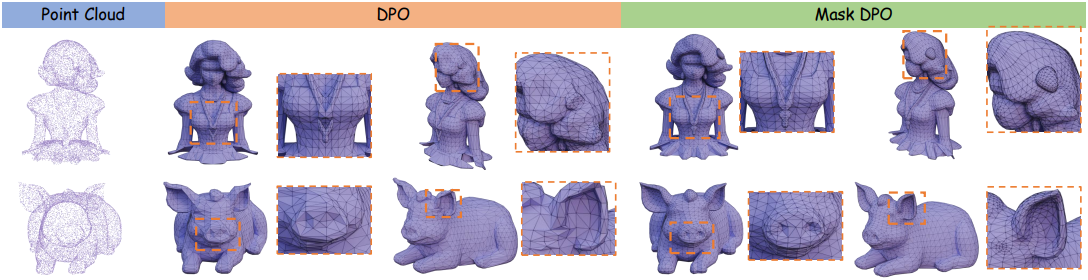
아래 그림에서 볼 수 있듯이, 고품질 구조와 저품질 구조가 하나의 메쉬 내에 공존하는 경우가 많아 supervision의 불일치로 인해 학습 노이즈가 발생한다.
이러한 한계를 극복하기 위해, 본 논문에서는 Masked Direct Preference Optimization (M-DPO)과 세밀한 메쉬 품질 평가를 결합하여 글로벌 및 로컬 개선을 모두 수행하는 새로운 프레임워크인 Mesh-RFT를 제안하였다. 주관적인 글로벌 reward를 supervision 신호로 사용했던 기존 연구와 달리, Mesh-RFT는 Boundary Edge Ratio (BER)와 위상 Topology Score (TS)라는 자동화된 metric을 사용하는 위상 기반 점수 시스템을 활용하여 object 및 face 수준에서 메쉬 품질을 객관적으로 평가함으로써, 번거로운 수동 주석 작업을 없애준다. 또한, Mesh-RFT는 M-DPO와 품질 마스크를 활용한 로컬 최적화 메커니즘을 통해 결함 영역을 구체적으로 개선하여 글로벌 reward의 coarse supervision을 해결하였다.
Method
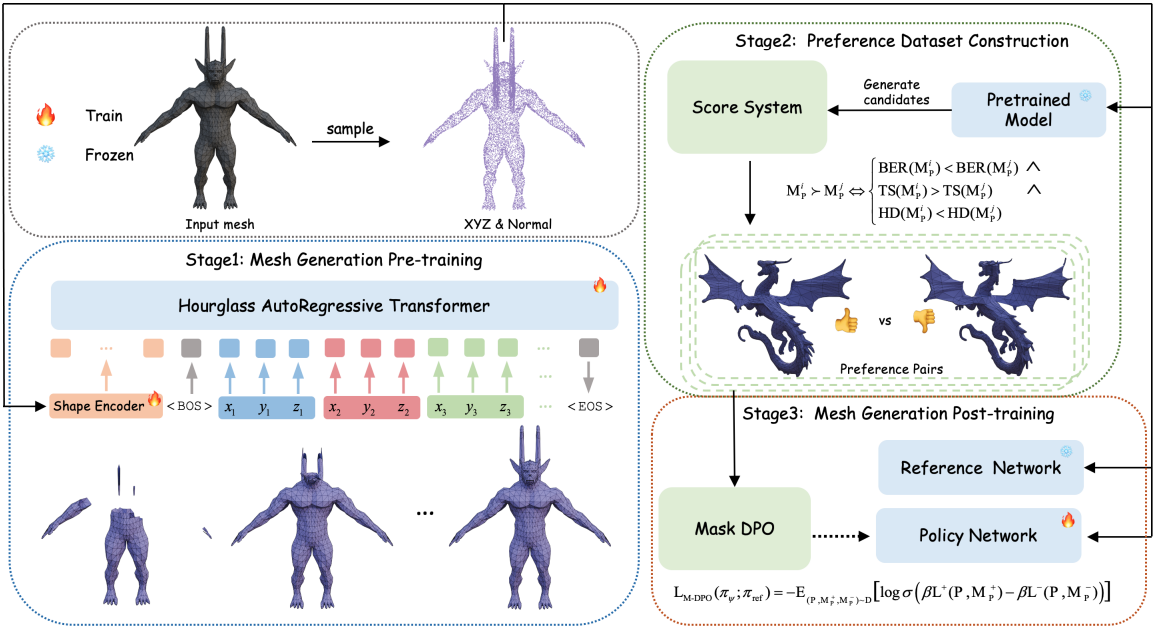
본 파이프라인은 세 단계로 구성된다.
- 포인트 클라우드와 GT 메쉬 시퀀스를 모델에 입력하여 supervised pretraining을 수행한다.
- 사전 학습된 모델은 후보를 생성하고, 위상 정보를 고려한 점수 시스템을 통해 선호도 데이터셋을 구축한다.
- 위상 정보를 고려한 M-DPO를 적용하여 이 선호도 데이터셋을 활용해 모델의 성능을 개선하는 post-training을 수행한다.
1. Mesh Generation Pre-training
기존 연구에서는 face의 수가 증가함에 따라 시퀀스 증가를 관리하기 위해 메쉬 시퀀스를 압축했지만, 이러한 기법은 토큰당 과도한 기하학적 정보를 포함하므로 하나의 토큰이 잘못될 경우 연쇄적인 face 오류가 발생한다. 저자들은 이러한 문제를 피하기 위해 MeshXL에서 소개된 비압축 메쉬 시퀀스 방법을 채택하였다. 구체적으로, 주어진 메쉬 $\mathcal{M}$에 대해 각 face의 vertex 좌표를 quantization한 다음 XYZ 순서로 flatten하여 완전한 토큰 시퀀스를 구성한다.
모델 아키텍처
저자들은 메쉬 생성을 일반적인 sequence task로 간주하는 대신 메쉬의 구조를 더 잘 포착하기 위해 Hourglass Transformer 아키텍처를 활용하였다. 본 모델은 입력을 계층적으로 처리하며 두 번의 shorten 연산과 두 번의 upsample 연산을 포함한다. Shorten 연산은 토큰 시퀀스 길이를 줄이고, upsample 연산은 시퀀스를 원래 길이로 확장한다. 이러한 디자인은 모델이 고수준 패턴과 미세한 디테일을 효율적으로 포착할 수 있도록 한다. 포인트 클라우드 기반 메쉬 생성에서 미세하고 복잡한 구조를 구현하려면 강력한 디코더뿐만 아니라 고품질 포인트 클라우드 feature가 필요하다. 이를 위해 Hunyuan3D 2.0에서 사전 학습된 포인트 클라우드 인코더를 사용한다. 이 feature는 cross-attention을 통해 key와 value로 디코더에 입력된다.
Truncated Training & Sliding-Window Inference
저자들은 메모리와 계산 비용을 줄이기 위해 고정 길이 세그먼트를 사용한 truncated training을 적용하였다. 이 접근 방식은 전체 시퀀스를 사용하는 대신 메쉬 시퀀스에서 더 작고 고정된 길이의 세그먼트를 추출하여 학습하는 것이다. 세그먼트에 start-of-sequence (SOS) 토큰이 없는 경우, 모델이 오인되는 것을 방지하기 위해 작은 prefix 부분을 추가한다. Inference 시에는 속도와 생성 품질을 모두 향상시키기 위해 sliding window 방식을 사용한다. 슬라이딩 과정은 학습 window 크기의 40%가 커버되면 시작되며, 가장 최근의 30% 토큰만 유지된다. 일반적으로 멀리 떨어진 토큰은 서로에게 미치는 영향이 적기 때문에 가장 관련성이 높은 토큰에 집중함으로써 계산 부하를 줄인다. 또한, 각 window의 끝부분에서 높은 perplexity를 완화하여 더욱 정확하고 효율적인 생성을 가능하게 한다.
2. Preference Dataset Construction
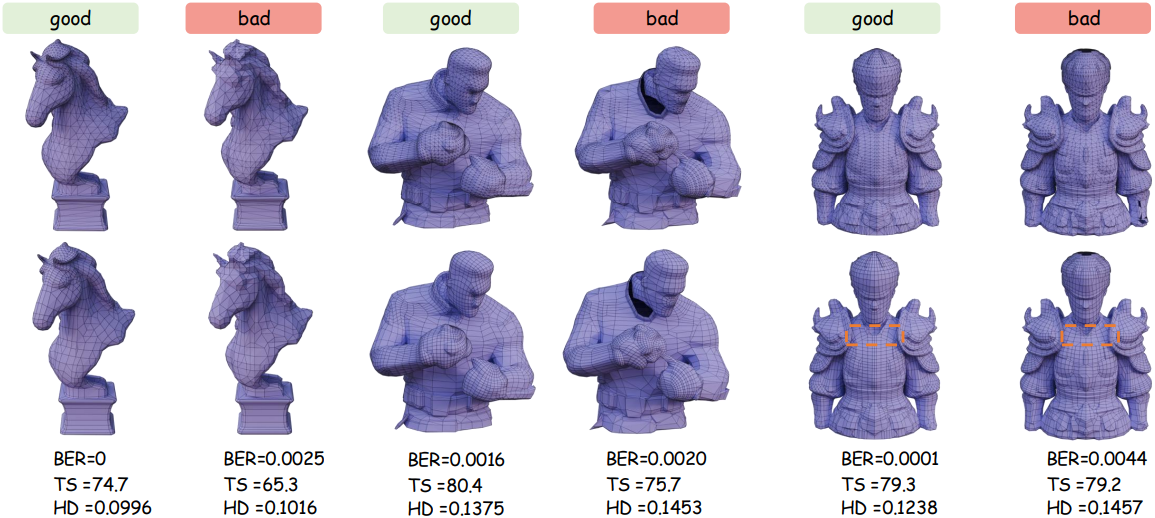
본 논문에서는 RLHF fine-tuning에 사용되는 선호도 데이터셋을 구축하기 위한 체계적인 파이프라인을 구축하였다. 이 파이프라인은 후보 생성, 다중 metric 평가, 선호도 순위 지정의 세 가지 핵심 구성 요소로 이루어져 있다.
후보 생성
각 입력 포인트 클라우드 $\mathcal{P}$에 대해 사전 학습된 모델 \(G_\theta^\textrm{pre}\)를 사용하여 8개의 후보 메쉬 \(\{\mathcal{M}_\mathcal{P}^1, \ldots, \mathcal{M}_\mathcal{P}^8\}\)을 생성한다.
다중 metric 평가
기하학적 일관성과 위상 품질을 모두 평가하기 위해 포괄적인 기준들을 사용하여 각 후보 메쉬를 평가한다. 저자들은 입력 데이터와의 기하학적 정렬을 측정하는 것 외에도, 생성된 메쉬의 구조적 무결성과 일관성을 구체적으로 포착하기 위한 두 가지 위상 중심 metric을 도입하였다.
Boundary Edge Ratio (BER)는 전체 edge 수 \(E_\mathcal{M}\) 대비 boundary edge 수 \(E_{\partial \mathcal{M}}\)의 비율을 계산하여 메쉬의 무결성을 정량화한다. Boundary edge는 한 face에만 연결된 edge이며, 높은 BER 값은 표면 불연속성, 구멍 또는 메쉬 손상과 같은 잠재적인 문제를 시사한다. 이상적으로, 닫힌 매니폴드 메쉬는 BER이 0이어야 한다.
\[\begin{equation} \textrm{BER}(\mathcal{M}) = \frac{E_{\partial \mathcal{M}}}{E_{\mathcal{M}}} \end{equation}\]Topology Score (TS)는 표준 triangle-to-quad merging을 통해 얻은 사각형 메쉬 $\mathcal{Q}(\mathcal{M})$을 분석하여 메쉬 $\mathcal{M}$의 구조적 품질을 평가한다.
\[\begin{equation} \textrm{TS}(\mathcal{M}) = \sum_{i=1}^4 w_i s_i (\mathcal{Q} (\mathcal{M})) \end{equation}\]이 점수는 네 가지 하위 metric의 가중 합이다.
- Quad Ratio ($w_1 = 0.4$): 변환 효율성을 측정
- Angle Quality ($w_2 = 0.2$): 사각형 각도가 90°에서 얼마나 벗어나는지를 정량화
- Aspect Ratio ($w_3 = 0.3$): 사각형 모양의 규칙성을 평가
- Adjacent Consistency ($w_4 = 0.1$): 인접한 사각형 간의 균일한 종횡비를 유도
응용 분야에서 quad mesh가 선호되기 때문에 이러한 metric들은 원래 삼각형 메쉬의 위상적 건전성을 나타내는 실질적인 지표가 된다.
Hausdorff Distance (HD)는 재구성된 메쉬 \(\mathcal{M}_\mathcal{P}^i\)와 입력 포인트 클라우드 $\mathcal{P}$ 사이의 기하학적 정렬을 정량화하기 위해 각각의 포인트 샘플 간의 최대 거리를 측정한 값이다. HD 값이 낮을수록 기하학적 재구성이 더 우수함을 나타낸다.
선호도 순위 지정
선호도 데이터셋을 구성하기 위해, 각 입력 포인트 클라우드 $\mathcal{P}$에 대해 8개의 후보 메쉬의 조합에 대해 쌍별 비교를 생성하며, 그 결과 총 $\binom{8}{2} = 28$개의 쌍이 생성된다. 각 쌍 \((\mathcal{M}_\mathcal{P}^i, \mathcal{M}_\mathcal{P}^j)\)에 대해, \(\mathcal{M}_\mathcal{P}^i\)가 세 가지 metric 모두에서 \(\mathcal{M}_\mathcal{P}^j\)보다 우수한 경우에만 \(\mathcal{M}_\mathcal{P}^i \succ \mathcal{M}_\mathcal{P}^j\)라는 선호도 관계를 정의한다.
\[\begin{aligned} \textrm{BER}(\mathcal{M}_\mathcal{P}^i) & > \textrm{BER}(\mathcal{M}_\mathcal{P}^j) \quad \wedge \\ \mathcal{M}_\mathcal{P}^i \succ \mathcal{M}_\mathcal{P}^j \iff \quad \textrm{TS}(\mathcal{M}_\mathcal{P}^i) & > \textrm{TS}(\mathcal{M}_\mathcal{P}^j) \quad \wedge \\ \textrm{HD}(\mathcal{M}_\mathcal{P}^i) & > \textrm{HD}(\mathcal{M}_\mathcal{P}^j) \end{aligned}\]이러한 선호도 관계를 만족하는 \(\mathcal{M}_\mathcal{P}^i\)를 해당 쌍에 대한 positive 샘플 \(\mathcal{M}_\mathcal{P}^{+}\)로, \(\mathcal{M}_\mathcal{P}^j\)를 negative 샘플 \(\mathcal{M}_\mathcal{P}^{-}\)로 한다. 이 규칙을 사용하여 \((\mathcal{P}, \mathcal{M}_\mathcal{P}^{+}, \mathcal{M}_\mathcal{P}^{-})\) 형태의 선호도 triplet 집합을 구성하며, 이는 RLHF를 위한 선호도 데이터셋을 구성한다.
3. Mesh Generation Post-training
사전 학습된 모델은 위상적으로 유효한 메쉬를 생성하지만, 두 가지 문제가 남아 있다.
- 곡률이 높은 영역에서 발생하는 로컬한 기하학적 결함
- 미적 아티팩트를 유발하는 불균일한 face 밀도 분포
DeepMesh는 메쉬 정제를 위해 RLHF를 사용하지만, reward function이 주로 글로벌 메쉬 구조에 기반하므로 로컬 메쉬 품질에 대한 세밀한 제어에는 불충분하다. 저자들은 이러한 한계를 해결하기 위해 공간 인식 기능을 갖춘 DPO의 확장 버전인 Masked Direct Preference Optimization (M-DPO)를 제안하였다. M-DPO는 로컬한 품질 마스크를 도입하여 문제 영역에 대한 학습을 유도함으로써 보다 효과적이고 정밀한 메쉬 정제를 가능하게 한다.
Quality-Aware Local Masking
로컬 마스킹의 목표는 메쉬의 고품질 영역과 저품질 영역을 구분하는 것이다. 삼각형 메쉬 $\mathcal{M}$이 주어졌을 때, 각 삼각형 면을 개별적으로 평가한다. 면은 다음 두 조건을 만족하면 양호한 것으로 분류된다.
- 사각형으로 성공적으로 병합될 수 있다.
- 생성된 사각형의 품질 점수가 미리 정의된 threshold보다 높다.
사각형의 품질은 앞서 소개된 세 가지 metric (Angle Quality, Aspect Ratio, Adjacent Consistency)의 가중 합을 사용하여 평가된다. 양호한 것으로 분류된 각 삼각형 면에 대해 메쉬 시퀀스에서 해당 토큰 위치에 모두 1의 값을 할당한다 (일반적으로 면당 9개 토큰). 반대로 기준을 충족하지 않는 면은 불량으로 간주하고 해당 토큰에는 0의 값을 할당한다. 로컬 마스킹 함수를 \(\Phi(\mathcal{M}) \in \{0, 1\}^{\vert M \vert}\)로 정의하며, 여기서 \(\vert M \vert\) 메쉬 $\mathcal{M}$을 나타내는 토큰 시퀀스의 길이이다.
Masked Direct Preference Optimization (M-DPO)
DPO는 전체 메쉬 시퀀스에 걸쳐 글로벌 reward 신호를 균일하게 최적화하는 경향이 있어 over-smoothing된 결과와 미세한 기하학적 디테일 손실을 초래할 수 있다. 본 논문에서 제시하는 M-DPO는 로컬 품질 마스크를 기반으로 element-wise 중요도 가중치를 적용하여 이러한 한계를 해결한다. 이를 통해 모델은 품질이 낮은 영역에 집중하여 최적화를 수행할 수 있다.
1단계에서 사전 학습된 모델 \(G_\theta^\textrm{pre}\)을 레퍼런스 모델 \(G_\textrm{ref}\)로 지정하고, 학습 과정 동안 해당 파라미터를 고정한다. 학습 가능한 policy 모델 \(G_\psi\)는 \(G_\theta^\textrm{pre}\)의 파라미터로 초기화된 후, 선호도 데이터셋에서 positive 샘플에 더 가까운 출력을 생성하도록 fine-tuning되어 인간의 선호도에 더 잘 부합하도록 한다. M-DPO의 목표는 로컬 마스크를 통해 식별된 품질이 중요한 영역에 초점을 맞춰, 덜 선호하는 negative 샘플보다 선호하는 positive 샘플의 likelihood를 최대화하는 것이다.
\[\begin{aligned} \mathcal{L}_\textrm{M-DPO} (\pi_\psi; \pi_\textrm{ref}) &= - \mathbb{E}_{(\mathcal{P}, \mathcal{M}_\mathcal{P}^{+}, \mathcal{M}_\mathcal{P}^{-}) \sim \mathcal{D}} \left[ \log \sigma (\beta \mathcal{L}^{+} (\mathcal{P}, \mathcal{M}_\mathcal{P}^{+}) - \beta \mathcal{L}^{-} (\mathcal{P}, \mathcal{M}_\mathcal{P}^{-})) \right] \\ \mathcal{L}^{+} (\mathcal{P}, \mathcal{M}_\mathcal{P}^{+}) &= \log \frac{\| \pi_\psi (\mathcal{M}_\mathcal{P}^{+} \vert \mathcal{P}) \odot \phi (\mathcal{M}_\mathcal{P}^{+}) \|_1}{\| \pi_\textrm{ref} (\mathcal{M}_\mathcal{P}^{+} \vert \mathcal{P}) \odot \phi (\mathcal{M}_\mathcal{P}^{+}) \|_1} \\ \mathcal{L}^{-} (\mathcal{P}, \mathcal{M}_\mathcal{P}^{-}) &= \log \frac{\| \pi_\psi (\mathcal{M}_\mathcal{P}^{-} \vert \mathcal{P}) \odot (1 - \phi (\mathcal{M}_\mathcal{P}^{-})) \|_1}{\| \pi_\textrm{ref} (\mathcal{M}_\mathcal{P}^{-} \vert \mathcal{P}) \odot (1 - \phi (\mathcal{M}_\mathcal{P}^{-})) \|_1} \end{aligned}\]($\mathcal{D}$는 선호도 데이터셋, $\odot$은 element-wise multiplication, \(\| \cdot \|_1\)은 토큰 시퀀스에 대한 \(\ell_1\) norm, $\sigma$는 sigmoid function)
M-DPO는 로컬 품질 마스크로 식별된 저품질 영역을 적극적으로 개선하면서 만족스러운 영역을 효과적으로 보존한다. 이러한 최적화 전략은 글로벌 구조를 유지할 뿐만 아니라 로컬 geometry 정확도를 향상시켜 DPO에 비해 메쉬 생성 품질을 더욱 세밀하게 제어할 수 있도록 한다.
Experiments
- 데이터셋: ShapeNetV2, 3D-FUTURE, Objaverse, Objaverse-XL
- pretraining: 200만 개의 메쉬
- fine-tuning: 필터링된 80만 개의 메쉬
- 구현 디테일
- M-DPO의 경우, 1만 개의 포인트 클라우드에 대해 8개의 버전의 메쉬를 생성
- optimizer: AdamW (\(\beta_1 = 0.9, \beta_2 = 0.99\))
- Flash Attention 사용
- GPU
- pretraining: NVIDIA H20 256개로 10일
- M-DPO: NVIDIA H20 64개로 8시간
1. Qualitative Results
다음은 아티스트가 디자인한 메쉬들에 대한 비교 결과이다.

다음은 out-of-distribution 메쉬들에 대한 일반화 결과이다.

2. Quantitative Results
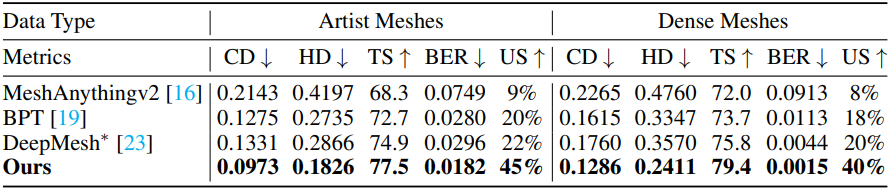
다음은 정량적으로 다른 방법들과 비교한 결과이다.
3. Ablation Study
다음은 점수 시스템과 M-DPO에 대한 ablation study 결과이다. N-DPO는 Hausdorff Distance만을 사용한 DPO이고, S-DPO는 본 논문의 점수 시스템을 사용한 DPO이다.
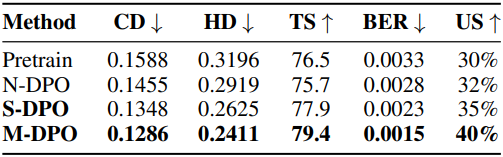
다음은 M-DPO에 대한 ablation study 결과이다.