[논문리뷰] MeshLLM: Empowering Large Language Models to Progressively Understand and Generate 3D Mesh
ICCV 2025. [Paper] [Page] [Github]
Shuangkang Fang, I-Chao Shen, Yufeng Wang, Yi-Hsuan Tsai, Yi Yang, Shuchang Zhou, Wenrui Ding, Takeo Igarashi, Ming-Hsuan Yang
Beihang University | The University of Tokyo | Atmanity Inc. | StepFun Inc. | UC Merced
2 Aug 2024
Introduction
최근 LLaMA-Mesh는 3D 메쉬를 text-serialization 형식으로 직접 표현하는 방식을 제안하여, LLM이 본래의 텍스트 처리 방식으로 3D 메쉬를 파싱하고 생성할 수 있도록 했다. 이 접근 방식은 두 가지 핵심적인 관찰에 기반한다.
- 텍스트 기반 메쉬 serialization은 추가적인 인코더를 필요로 하지 않으므로 LLM의 텍스트 모델링 기능과 자연스럽게 호환된다.
- LLM은 프로그래밍 코드나 SVG와 같은 다른 규칙 기반 텍스트 형식과도 호환성을 보여주므로, 비교적 간단한 메쉬에서도 LLM의 잠재력을 확인할 수 있다.
LLaMA-Mesh는 다음과 같은 한계점이 있다.
- 데이터 규모의 한계: 대규모 데이터는 LLM의 성능 향상에 핵심적인 요소이다. 그러나 LLM의 토큰 길이 제한으로 인해 LLaMA-Mesh는 많은 수의 긴 메쉬 시퀀스를 사용할 수 없었으며, 학습에는 단 31,000개의 샘플만 사용되어 잠재력이 크게 제한되었다.
- 불충분한 3D 구조 인식: Text-serialized mesh 표현을 직접 학습하는 방식은 LLM이 3D 메쉬의 고유한 공간 구조를 간과하게 만든다.
이러한 문제들을 해결하기 위해, 본 논문에서는 MeshLLM을 제안하였으며, 주요 설계 특징은 다음과 같다.
1. Primitive-Mesh 구성
먼저 KNN 알고리즘을 이용하여 복잡한 메쉬를 여러 개의 Primitive-Mesh로 사전 분해한다. 이 간단한 접근 방식을 통해 150만 개 이상의 학습 샘플로 구성된 대규모 데이터셋을 신속하게 구축할 수 있다. 그러나 이러한 샘플들은 내재된 semantic 일관성을 완벽하게 포착하지 못할 수 있다. 따라서, 저자들은 고품질 3D 메쉬 분할 도구를 활용하여 10만 개 이상의 semantic-level Primitive-Mesh 샘플로 구성된 부분집합을 선별하였다. 이러한 샘플들은 자연어에서 LLM이 로컬 윈도우를 처리하는 방식과 유사하게 정확한 구조적 및 semantic 디테일 제공하여 모델의 3D 메쉬 이해도를 더욱 향상시킨다.
2. Task별 학습 전략
저자들은 구축된 데이터셋을 기반으로, vertex-face 예측과 로컬 메쉬 조립이라는 두 가지 추가 학습 task를 설계했다. Vertex-face 예측은 vertex로부터 face 연결성을 추론하여 LLM의 위상 추론 능력을 향상시키고, 로컬 메쉬 조립은 로컬 구조로부터 완전한 메쉬를 재구성하여 글로벌 모델링 기능을 개선하였다. 이 전략을 통해 LLM은 text-serialized mesh에서 로컬 및 글로벌 3D 구조 정보를 모두 효과적으로 포착할 수 있다. 이러한 task들을 보완하기 위해, 저자들은 방대한 Primitive-Mesh 데이터셋을 활용한 대규모 사전 학습에서 특정 task에 대한 목표 지향적 fine-tuning으로 전환하는 점진적 학습 프로세스를 구현했다.
Method
1. Preliminaries: Text-serialized Mesh
LLM을 사용하여 3D 메쉬 데이터를 직접 모델링하려면 이를 텍스트 시퀀스로 변환해야 한다. 본 논문은 LLaMA-Mesh와 유사하게, 메쉬의 기본 표현으로 OBJ 형식을 채택하였다. 메쉬 $\mathcal{M} = (\mathcal{V}, \mathcal{F})$가 주어졌을 때, \(\mathcal{V} = \{v_i\}_{i=1}^{N_v}\)는 $N_v$개의 vertex를 나타내며, 각 vertex \(v_i \in \mathbb{R}^3\)는 공간 좌표, 즉 $v_i = (x_i, y_i, z_i)$에 대응한다. Face 집합 \(\mathcal{F} = \{f_j\}_{j=1}^{N_f}\)는 세 개의 vertex 인덱스로 정의된 $N_f$개의 삼각형 면으로 구성된다.
메쉬는 다음 단계를 통해 텍스트화된다.
- Quantization: 메쉬 vertex의 좌표 값은 정수 값으로 매핑되어 무한한 숫자 값을 유한한 범위로 제한한다. 문자 ‘v’, ‘f’ 및 숫자 0~64는 일반적인 기호이므로 LLM의 tokenizer나 vocabulary를 수정할 필요가 없다.
- Sorting: PolyGen과 유사한 정렬 전략을 사용하여 각 메쉬에 고유한 순서를 할당한다. 구체적으로, Vertex는 z-y-x 좌표를 기준으로 오름차순으로 정렬된다. 그런 다음 face는 각 face 내에서 가장 작은 vertex 인덱스를 기준으로 정렬된다.
- Textual sequence unfolding: 정렬된 메쉬는 텍스트 형식으로 flatten된다.
($\vert \vert$는 시퀀스 concat)
2. Primitive-Mesh
Text-serialized mesh에서 LLM을 직접 학습시키는 데에는 다음과 같은 몇 가지 어려움이 있다.
- LLM의 제한된 토큰 길이로 인해 학습 가능한 샘플 수가 제한된다.
- 텍스트 시퀀스는 내재된 3D 구조를 제대로 전달하지 못한다.
- 긴 시퀀스에서 학습하는 것은 LLM에게 본질적으로 어렵다.
이러한 문제들을 해결하기 위해, 본 논문에서는 메쉬를 여러 개의 구성 요소로 분해하는 Primitive-Mesh라는 방법을 제안하였다.
\[\begin{equation} \mathcal{M} = \{\mathcal{M}_1, \mathcal{M}_2, \ldots, \mathcal{M}_N\} \end{equation}\]($N$은 Primitive-Mesh 개수)
이러한 디자인은 LLM이 잘린 로컬 텍스트를 활용할 때 이점을 얻는다는 점에서 비롯되었다. 마찬가지로, 메쉬 구성 요소는 공간 정보를 유지하여 LLM이 3D 공간 구조를 인식하는 데 도움을 준다. 또한, Primitive-Mesh 시퀀스는 길이가 더 짧고 개수가 훨씬 많아 대규모 데이터셋에서 LLM의 잠재력을 더욱 활용할 수 있다.
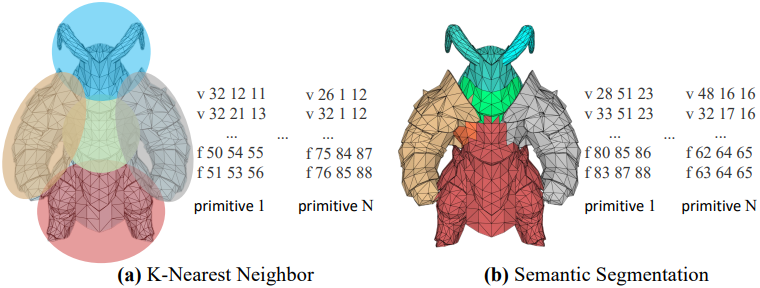
저자들은 두 가지 전략을 사용하여 Primitive-Mesh를 구성하였다.
1. KNN 기반
메쉬 $\mathcal{M}$이 주어졌을 때, 먼저 메쉬에서 포인트 클라우드를 샘플링한 다음, farthest point sampling (FPS)과 KNN을 적용하여 중심점과 포인트 클러스터를 식별하고, 이를 통해 메쉬를 여러 개의 로컬 영역으로 분할한다. 이 접근 방식은 계산 효율성이 높고 기존의 모든 메쉬 데이터셋에 적용 가능하다.
저자들은 이 전략을 사용하여 150만 개 이상의 학습 샘플을 생성했다. 그러나 KNN을 통해 얻은 메쉬는 semantic 일관성이 부족할 수 있다. 따라서 기존 데이터를 보완하고 개선하기 위해 추가 데이터셋을 구축했다.
2. Semantic 기반
Semantic 경계가 명확하게 정의된 Primitive-Mesh를 얻기 위해, 미적 필터링 후 SAMPart3D를 활용하여 메쉬 분할을 수행하였다. 이를 통해 저자들은 10만 개 이상의 고품질 Primitive-Mesh 샘플을 얻었다. 이러한 데이터셋은 LLM이 고수준 semantic 정보를 이해하는 능력을 더욱 향상시킨다.
3. Training Task Design
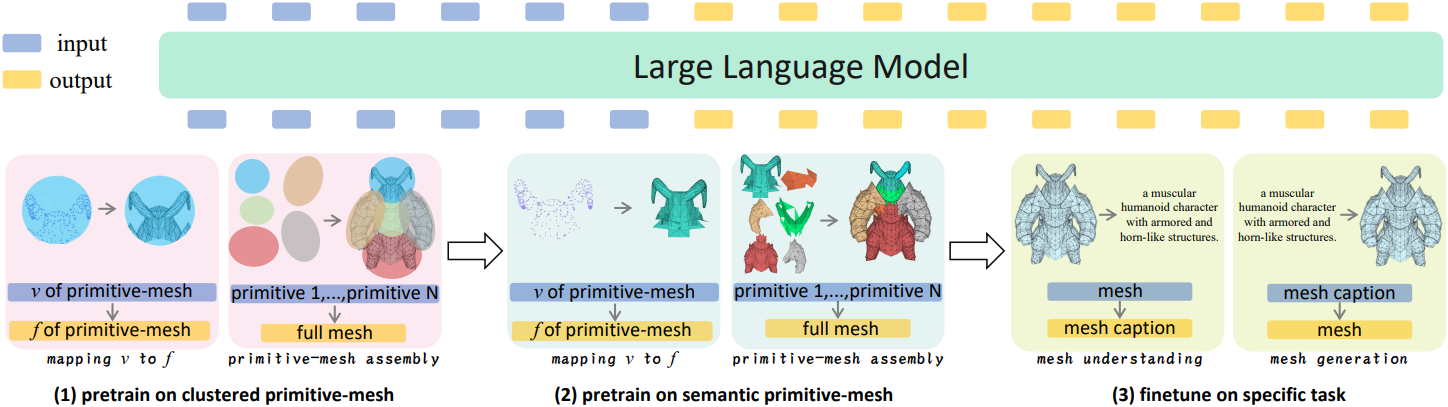
저자들은 구축된 데이터셋을 기반으로, LLM의 3D 메쉬 이해 및 생성 능력을 향상시키기 위해 4개의 Supervised Fine-Tuning (SFT) task들을 설계했다.
Vertex-Face 예측
Vertex 좌표 집합 $\mathcal{V}$와 이에 대응하는 face 집합 $\mathcal{F}$가 주어졌을 때, LLM은 다음 objective에 따라 최적화된다.
\[\begin{equation} \max_\theta P(\mathcal{F} \vert \mathcal{V}, \theta) \end{equation}\]이 task를 통해 LLM은 vertex가 주어졌을 때 face 연결성을 예측하고, 이를 통해 vertex 간의 위상 관계를 학습할 수 있다.
메쉬 조립
완전한 메쉬 $\mathcal{M}$과 그에 대응하는 Primitive-Mesh 집합 \(\{\mathcal{M}_i\}_{i=1}^k\)이 주어졌을 때, LLM은 최적화를 통해 전체 메쉬를 재구성하는 방법을 학습한다.
\[\begin{equation} \max_\theta P (\mathcal{M} \vert \{\mathcal{M}_i\}_{i=1}^k, \theta) \end{equation}\]이 task는 로컬 Primitive-Mesh 간의 기하학적 관계를 포착하여 text serialization에 내재된 3D 공간 정보 손실을 완화함으로써 모델의 메쉬 구조 추론 능력을 향상시킨다.
메쉬 이해
주어진 메쉬 $\mathcal{M}$과 해당 메쉬에 대한 텍스트 설명 $\mathcal{T}$를 바탕으로 다음과 같은 objective가 구성된다.
\[\begin{equation} \max_\theta P (\mathcal{T} \vert \mathcal{M}, \theta) \end{equation}\]이를 통해 LLM은 메쉬 데이터를 기반으로 정확하고 유창한 설명을 생성하여 고수준 semantic 정보를 이해할 수 있다.
메쉬 생성
텍스트 설명 $\mathcal{T}$와 메쉬 $\mathcal{M}$이 주어졌을 때, LLM은 다음을 최적화하도록 학습된다.
\[\begin{equation} \max_\theta P (\mathcal{M} \vert \mathcal{T}, \theta) \end{equation}\]이는 LLM이 텍스트 설명으로부터 그럴듯한 메쉬 구조를 생성하는 방법을 학습하도록 유도한다.
이러한 task들은 서로 독립적인 것이 아니라 점진적인 학습 과정을 통해 구현된다. 초기에는 vertex-face 예측 및 메쉬 조립 task를 통해 모델이 기본적인 메쉬 구조와 로컬 semantic에 익숙해지도록 한다. 이후에는 메쉬 이해 및 메쉬 생성 task를 통해 모델이 복잡한 3D 구조와 고수준 semantic을 더욱 정교하게 이해할 수 있도록 한다.
4. SFT Data Curation

LLM의 downstream task 학습에서 SFT는 가장 널리 사용되는 전략 중 하나이다. 위 그림에서 볼 수 있듯이, 저자들은 앞서 언급한 네 가지 task를 포괄하는 다양한 형태의 SFT 데이터를 구성했다. 이 방법은 표준 언어 모델링 objective로 고품질 입력-출력 데이터 쌍을 사용하여 LLM을 fine-tuning함으로써 3D task에 더 잘 적응하도록 한다.
Experiments
- 데이터셋: Objaverse-XL, ShapeNet
- 구현 디테일
- GPU: A800 128개 (데이터셋 구성 3일, 학습 6일 소요)
- base model: LLaMA-8B-Instruct
- 최대 컨텍스트 길이: 8,192
- optimizer: AdamW
- learning rate: $2 \times 10^{-5}$
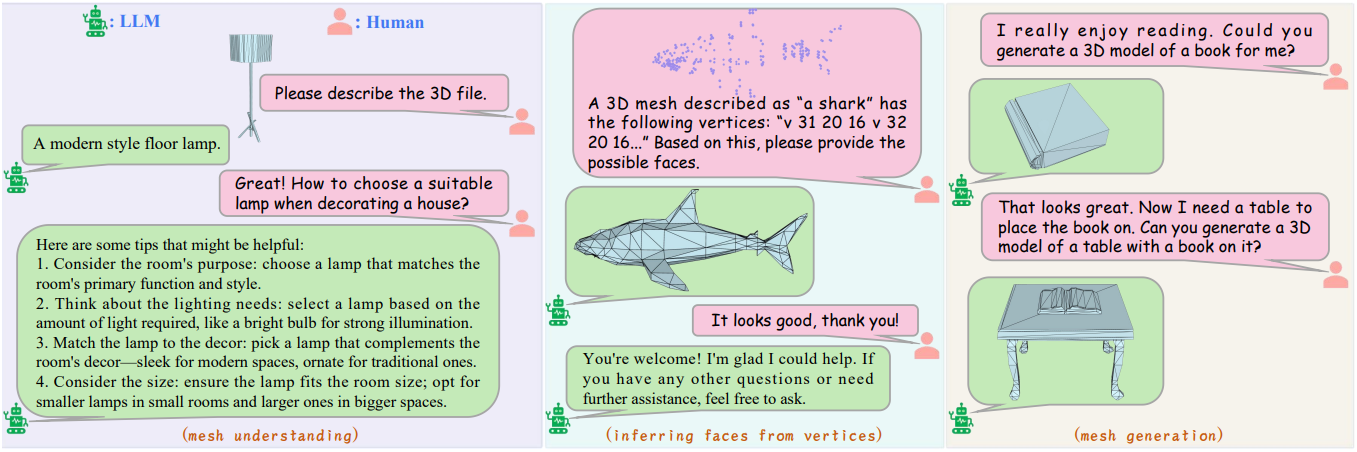
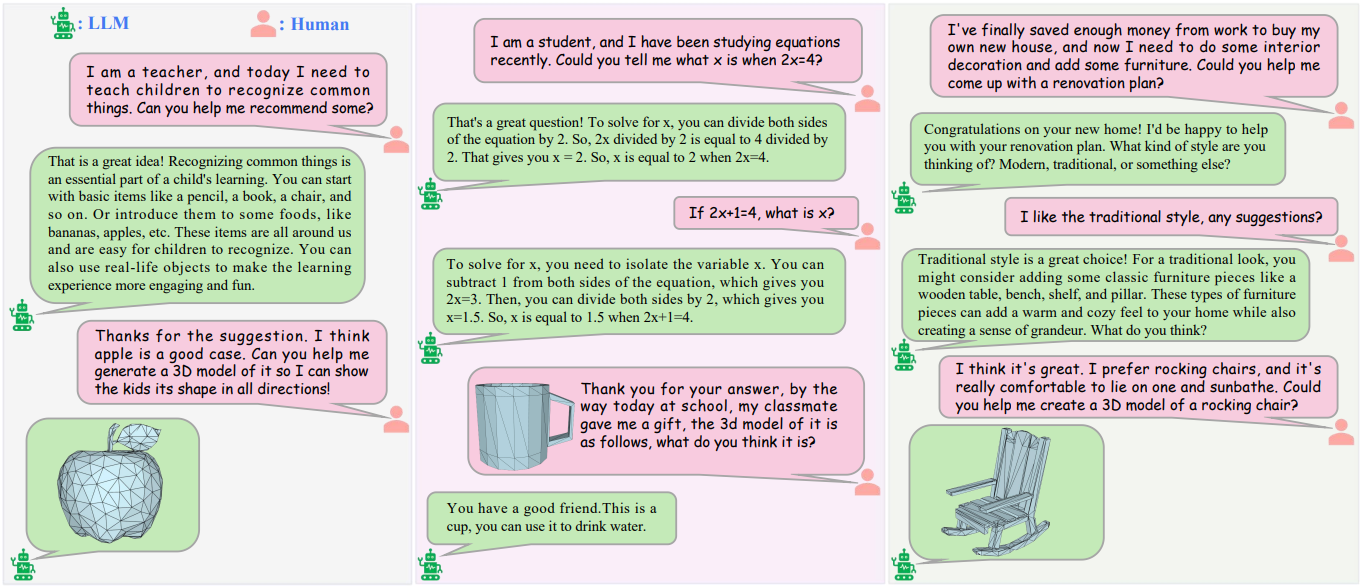
1. Dialogue Ability
다음은 대화형 시나리오의 예시들이다.
2. Performance Evaluation
다음은 생성된 메쉬 품질을 비교한 결과이다.


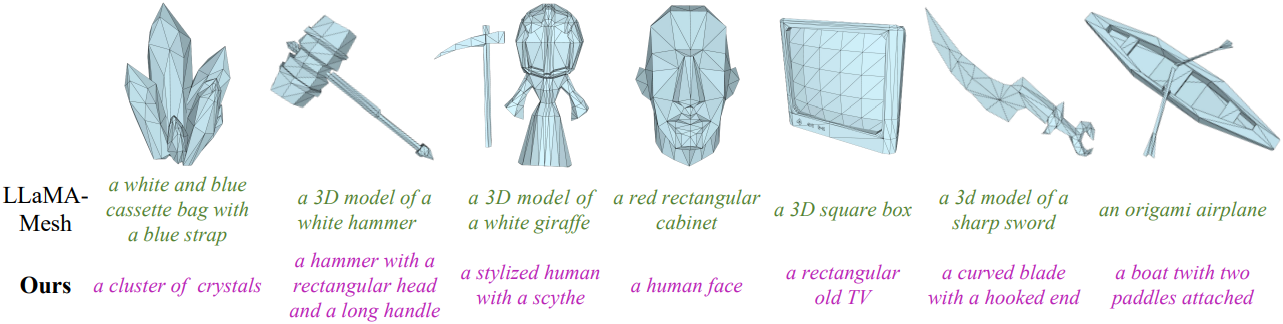
다음은 메쉬 이해 능력을 LLaMA-Mesh와 비교한 결과이다.

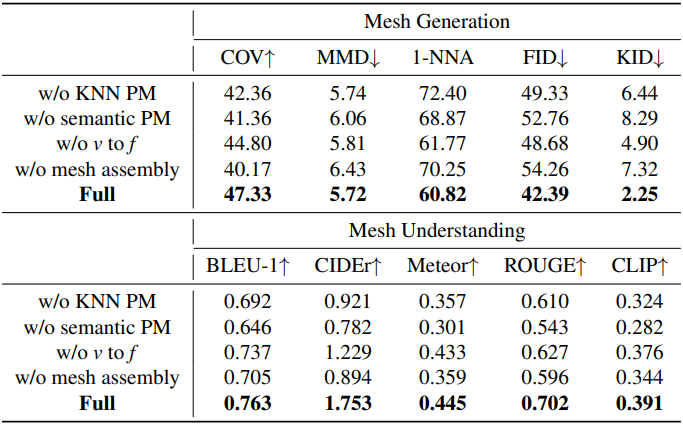
3. Ablation Studies
다음은 ablation study 결과이다.