[논문리뷰] Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
INTERSPEECH 2023. [Paper] [Page]
Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
Zhejiang University | ByteDance
6 Jun 2023
Introduction
TTS 합성은 텍스트에서 사람과 같은 음성을 생성하는 것을 목표로 하며 기계 학습 분야에서 상당한 주목을 받았다. 기존의 TTS 시스템은 일반적으로 제한된 데이터셋에서 학습되므로 다양하고 일반화 가능한 결과를 생성하는 모델의 능력이 손상된다. 반대로 대규모 TTS 시스템은 수만 시간의 음성 데이터로 학습되어 zero-shot 능력이 크게 향상된다. 현재의 대규모 TTS 시스템은 일반적으로 뉴럴 코덱 모델을 중간 표현으로 사용하여 음성 파형을 latent로 인코딩하고 autoregressive 언어 모델 (LM) 또는 diffusion model로 모델링한다.
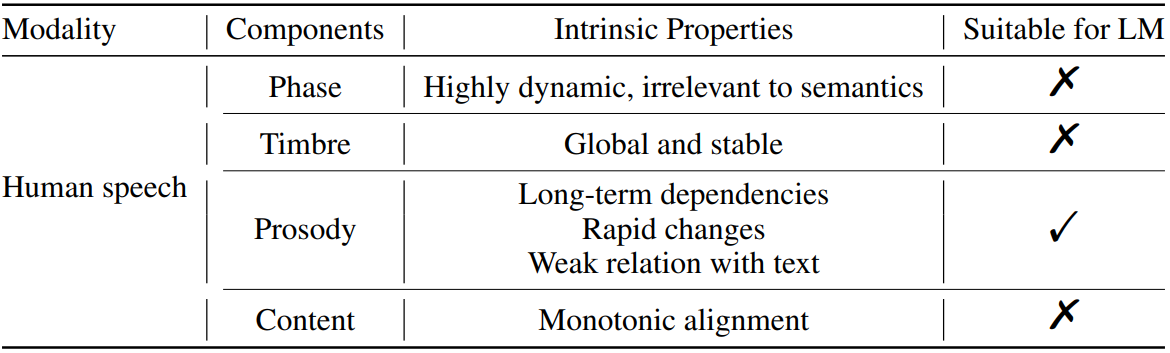
위 표와 같이 인간의 음성은 콘텐츠, 음색(timbre), 운율(prosody), 위상(phase) 등 여러 속성으로 분리될 수 있다. 그러나 현재 대규모 TTS 시스템은 뉴럴 오디오 코덱 모델을 직접 사용하여 전체 음성을 latent로 인코딩하고 음성의 본질적인 특성을 무시한다.
- 위상은 매우 역동적이고 semantic과 관련이 없다. 즉, 특히 모노 오디오의 경우 사람들이 운율과 음색보다 위상에 훨씬 덜 민감하다. 따라서 파형 재구성에는 합당한 단 하나의 위상만 필요하며 가능한 모든 위상을 모델링할 필요는 없다. LM 또는 diffusion model을 사용한 모델링 위상은 위상의 전체 분포를 모델링하기 때문에 많은 모델 파라미터를 낭비할 수 있다.
- 음색은 글로벌 벡터로서 문장 내에서 안정적으로 유지되어야 한다. 시간에 따라 변하는 latent를 가진 모델링 음색은 비용이 많이 든다.
- 운율은 일반적으로 로컬 및 장기 의존성을 모두 가지며 텍스트와의 약한 상관 관계로 시간이 지남에 따라 빠르게 변경되므로 조건부 음소 레벨 LLM은 본질적으로 운율 시퀀스를 생성하는 데 이상적이다.
- 콘텐츠는 음성과 단조 정렬되지만 autoregressive LM은 이를 보장할 수 없으므로 단어가 반복되거나 누락될 수 있다.
본 논문은 모델의 inductive bias와 음성의 고유한 특성을 일치시키면서 크고 거친 학습 데이터셋을 사용하기 위해 Mega-TTS라는 zero-shot TTS 모델인 Mega-TTS를 제안한다.
- 뉴럴 오디오 코덱 모델의 한계를 고려하여 위상과 다른 속성을 분리하기 위한 중간 표현으로 mel-spectrogram을 선택한다. 모델의 효율성을 향상시키기 위해 위상 정보를 재구성하며, 이를 위해 GAN 기반 vocoder를 채택한다.
- 음색 정보를 모델링하기 위해 음색은 시간이 지남에 따라 천천히 변하는 글로벌한 속성이므로 글로벌 벡터를 사용한다. 동일한 speaker의 다른 음성에서 global speaker encoder를 사용하여 글로벌 정보를 추출하여 음색과 콘텐츠 정보를 분해한다.
- 문장에서 운율 정보를 포착하기 위해 mel-spectrogram을 생성하는 VQGAN 기반 acoustic model과 운율 분포에 맞는 P-LLM이라는 latent code 언어 모델을 채택한다. P-LLM은 운율 모델링을 위한 로컬 및 장거리 의존성을 모두 캡처할 수 있다.
Mega-TTS는 speaker 유사성, 음성 자연성, 생성 견고성 측면에서 SOTA zero-shot TTS 시스템을 능가하며 적절한 inductive bias 도입의 우수성을 입증하였다. 또한 Mega-TTS는 음성 편집 및 교차 언어 TTS task에서 SOTA 모델보다 성능이 뛰어나다.
Method
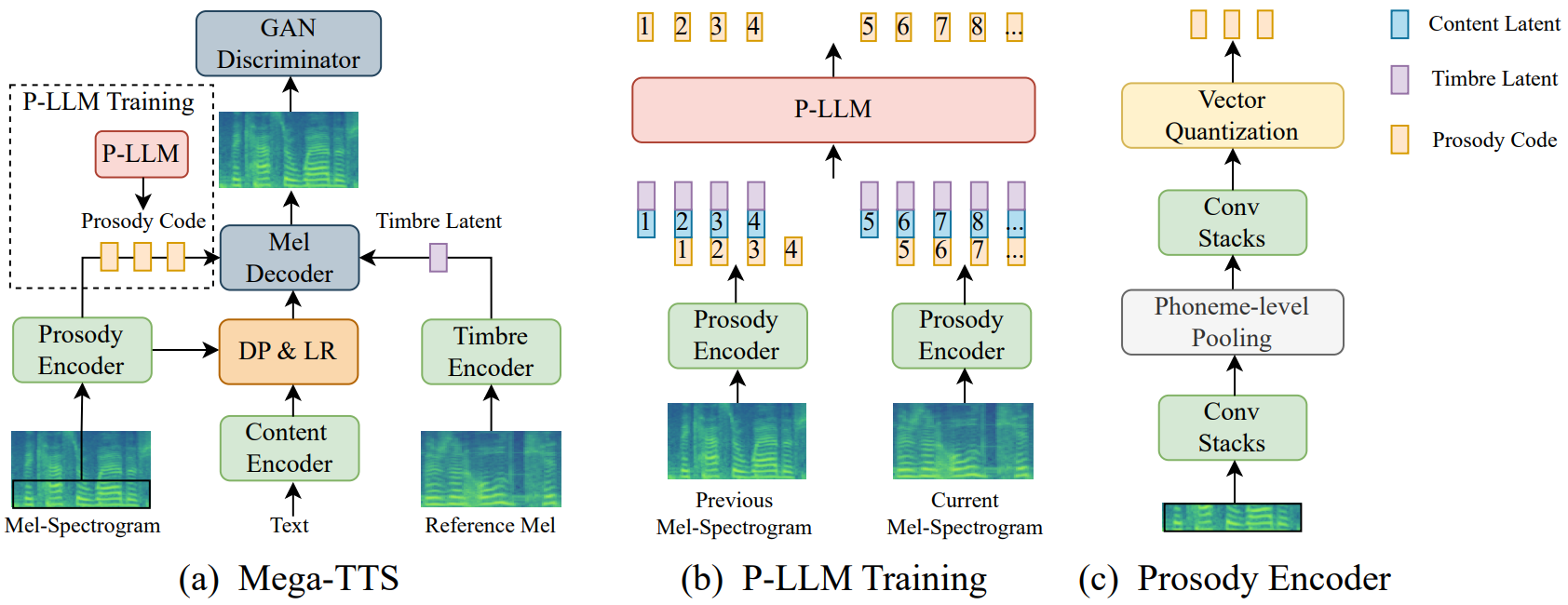
본 논문은 대규모 TTS 시스템에 적절한 inductive bias를 도입하기 위해 다양한 시나리오 (ex. zero-shot 프롬프트 기반 TTS, 음성 편집, 교차 언어 TTS)에서 자연스럽고 강력한 음성 생성을 위한 zero-shot TTS 시스템인 Mega-TTS를 제안한다. 위 그림과 같이 Mega-TTS는 VQGAN 기반의 TTS 모델과 P-LLM (prosody large language model)으로 구성된다. 다양한 음성 속성을 다양한 방식으로 신중하게 모델링한다.
- mel-spectrogram을 중간 표현으로 선택한다. 이는 위상을 다른 속성과 매우 잘 분리하기 때문이다.
- 동일한 speaker의 임의의 이전 문장에서 글로벌 음색 인코더를 사용하여 글로벌 벡터를 추출하여 음색 정보와 콘텐츠 정보를 분리한다.
- VQGAN 기반 acoustic model을 사용하여 mel-spectrogram을 생성하고 운율 분포에 맞는 P-LLM이라는 latent code 언어 모델을 제안한다. 언어 모델은 로컬 및 장거리 의존성을 모두 캡처할 수 있기 때문이다.
Inference하는 동안 주어진 텍스트 시퀀스의 콘텐츠, 프롬프트 음성에서 추출한 음색, P-LLM에서 예측한 운율을 사용하여 운율 지향 음성 디코딩 (prosody-oriented speech decoding)이라는 새로운 TTS 디코딩 메커니즘으로 음성을 생성한다. 마지막으로 모델이 다양한 시나리오에 적용될 수 있음을 입증하기 위해 다운스트림 task에 대한 inference 전략을 설계한다.
1. Disentangling speech into different components
서로 다른 음성 속성에 적절한 inductive bias를 도입하려면 이러한 속성을 별도로 표현하고 서로 다른 아키텍처를 신중하게 설계해야 한다. 콘텐츠 표현, 운율 표현, 음색 표현을 별도로 인코딩하기 위해 세 가지 유형의 인코더를 사용한다. 그런 다음 GAN 기반 mel-spectrogram 디코더를 채택하여 이러한 표현으로 mel-spectrogram을 생성한다.
Disentangling strategy
오토인코더의 reconstruction loss와 세심하게 설계된 bottleneck을 사용하여 mel-spectrogram을 콘텐츠 표현, 운율 표현, 음색 표현으로 분리한다.
- Mel-spectrogram을 운율 인코더에 공급하고, 신중하게 튜닝된 차원 축소와 음소 레벨 다운샘플링을 도입하여 운율 인코더가 정보 흐름을 제한하도록 한다
- 콘텐츠 인코더는 음소 시퀀스를 콘텐츠 표현으로 인코딩한다.
- 동일한 speaker의 다른 음성에서 샘플링된 레퍼런스 mel-spectrogram을 공급하여 음색 정보와 콘텐츠 정보를 분리하고 음색 인코더의 출력을 시간적으로 평균하여 1차원 글로벌 음색 벡터를 얻는다. 올바르게 설계된 bottleneck은 운율 인코더의 출력에서 콘텐츠 정보와 전체 음색 정보를 제거하는 방법을 학습하여 분리 성능을 보장한다.
Architecture design of encoders
- 운율 인코더는 두 개의 convolution 스택, 음소 레벨 풀링 레이어, vector quantization (VQ) bottleneck으로 구성된다. 첫 번째 convolution 스택은 mel-spectrogram을 음소 경계에 따라 음소 레벨 hidden state로 압축하고 두 번째 스택은 음소 레벨 상관 관계를 캡처한다. 그런 다음 VQ layer는 이러한 hidden state를 활용하여 음소 레벨의 운율 코드 \(u = \{u_1, u_2, \cdots, u_T\}\)와 hidden state $H_\textrm{prosody}$를 얻는다. Disentanglement의 어려움을 완화하기 위해 mel-spectrogram의 저주파 대역 (각 mel-spectrogram 프레임의 처음 20개 bin)만 입력으로 사용된다. 이는 전체 대역에 비해 거의 완전한 운율과 훨씬 적은 음색/콘텐츠 정보를 포함하기 때문이다.
- 콘텐츠 인코더는 여러 feed-forward Transformer layer로 구성된다. 음성 콘텐츠와 생성된 음성 사이의 단조 정렬을 위해 non-autoregressive TTS 시스템에서 일반적인 관행에 따라 duration predictor와 length regulator를 채택한다. 일대다 매핑 문제를 완화하기 위해 운율 인코더에서 추출한 운율 정보를 duration predictor에 공급한다.
- 음색 인코더는 주어진 음성의 speaker ID를 포함하는 글로벌 벡터 $H_\textrm{timbre}$를 추출하도록 설계되었다. 음색 인코더는 convolution layer의 여러 스택으로 구성된다. 시간 축에 걸쳐 음색 정보의 안정성을 보장하기 위해 음색 인코더의 출력을 시간적으로 평균하여 1차원 음색 벡터 $H_\textrm{timbre}$를 얻는다.
좋은 지각 품질을 유지하기 위해 GAN 기반 mel-spectrogram 디코더를 도입한다. Discriminator로 길이가 다른 무작위 window을 기반으로 하는 multi-length discriminator를 채택한다. 전반적으로 Mega-TTS의 1단계 학습 loss $\mathcal{L}$은 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{VQ} = \| y_t - \hat{y}_t \|^2 + \| \textrm{sg} [E (y_t)] - z_q \|_2^2 + \| \textrm{sg} [z_q] - E (y_t) \|_2^2 \\ \mathcal{L} = \mathbb{E} [\mathcal{L}_\textrm{VQ} + \mathcal{L}_\textrm{Adv}] \end{equation}\]여기서 $y_t$는 타겟 음성이고 \(\hat{y}_t\)는 생성된 음성이다. \(\mathcal{L}_\textrm{rec} = \| y_t - \hat{y}_t \|^2\)는 reconstruction loss이고 $\textrm{sg} [\cdot]$는 stop-gradient 연산자이며, $z_q$는 코드북 entry의 시간적 컬렉션이다. \(\mathcal{L}_\textrm{VQ}\)는 VQVAE loss function이고, \(\mathcal{L}_\textrm{Adv}\)는 예측된 mel-spectrogram과 ground-truth mel-spectrogram 사이의 분포 거리를 최소화하는 LSGAN 스타일의 adversarial loss이다.
2. P-LLM
P-LLM은 운율 모델링을 위한 로컬 및 장거리 의존성을 캡처하는 latent code 언어 모델이다.
Prosody-oriented speech decoding
프롬프트 음성-전사 쌍과 타겟 음성-전사 쌍을 $(y_p, x_p)$와 $(y_t, x_t)$를 나타내자. 처음 보는 음성 프롬프트 $y_p$가 주어지면 고품질의 타겟 음성 $y_t$를 합성하는 것이 목표이다. Inference하는 동안 타겟 음성의 음색 \(H_\textrm{timbre}\)은 프롬프트 음성의 음색과 동일할 것으로 예상된다. 따라서 타겟 음성 $y_t$를 생성하기 위해서는 타겟 음성의 운율 정보 $\tilde{u}$만 있으면 된다. 따라서 운율 지향 음성 디코딩 절차는 다음과 같다.
인코딩:
\[\begin{equation} u = E_\textrm{prosody} (y_p), \quad H_\textrm{content} = E_\textrm{content} (x_p), \\ \tilde{H}_\textrm{timbre} = E_\textrm{timbre} (y_p), \quad \tilde{H}_\textrm{content} = E_\textrm{content} (x_t) \end{equation}\]운율 예측:
\[\begin{equation} \tilde{u} = f (\tilde{u} \vert u, H_\textrm{content}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}; \theta) \end{equation}\]디코딩:
\[\begin{equation} \hat{y}_t = D (\tilde{u}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}) \end{equation}\]여기서 \(E_\textrm{prosody}\), \(E_\textrm{timbre}\), \(E_\textrm{content}\), $D$는 각각 운율 인코더, 음색 인코더, 콘텐츠 인코더, mel decoder이다. $u$는 프롬프트 음성의 운율 토큰이고 $\tilde{u}$는 예측된 타겟 음성의 운율 토큰이다. $f$는 운율 예측 함수이고 $\theta$는 P-LLM의 파라미터이다. \(\hat{y}_t\)는 생성된 음성이다.
Generating prosody codes
운율 지향 음성 디코딩 메커니즘은 타겟 음성의 예측 운율 코드 $\tilde{u}$를 필요로 한다. LLM의 강력한 in-context learning 능력을 활용하여 $\tilde{u}$를 예측하는 P-LLM 모듈을 설계한다. P-LLM은 운율 모델링을 위한 디코더 전용 trasnformer 기반 아키텍처로, 프롬프트로 $y_p$의 운율 코드 $u$를 사용하고 조건으로 $H_\textrm{content}$, \(\tilde{H}_\textrm{content}\), \(\tilde{H}_\textrm{timbre}\)을 사용한다. P-LLM의 autoregressive 운율 예측 프로세스는 다음과 같다.
\[\begin{aligned} & p (\tilde{u} \vert u, H_\textrm{content}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}; \theta) \\ & \qquad = \prod_{t=0}^T p (\tilde{u}_t \vert \tilde{u}_{<t}, u, H_\textrm{content}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}; \theta) \end{aligned}\]여기서 $\theta$는 P-LLM의 파라미터이다. Discrete한 운율 시퀀스 $u$는 음소 레벨이므로 $H_\textrm{content}$, \(\tilde{H}_\textrm{content}\), \(\tilde{H}_\textrm{timbre}\)을 입력으로 직접 concat한다. P-LLM은 cross entropy loss를 통해 학습 단계에서 teacher-forcing 모드로 학습된다.
3. Speech prompting for inference
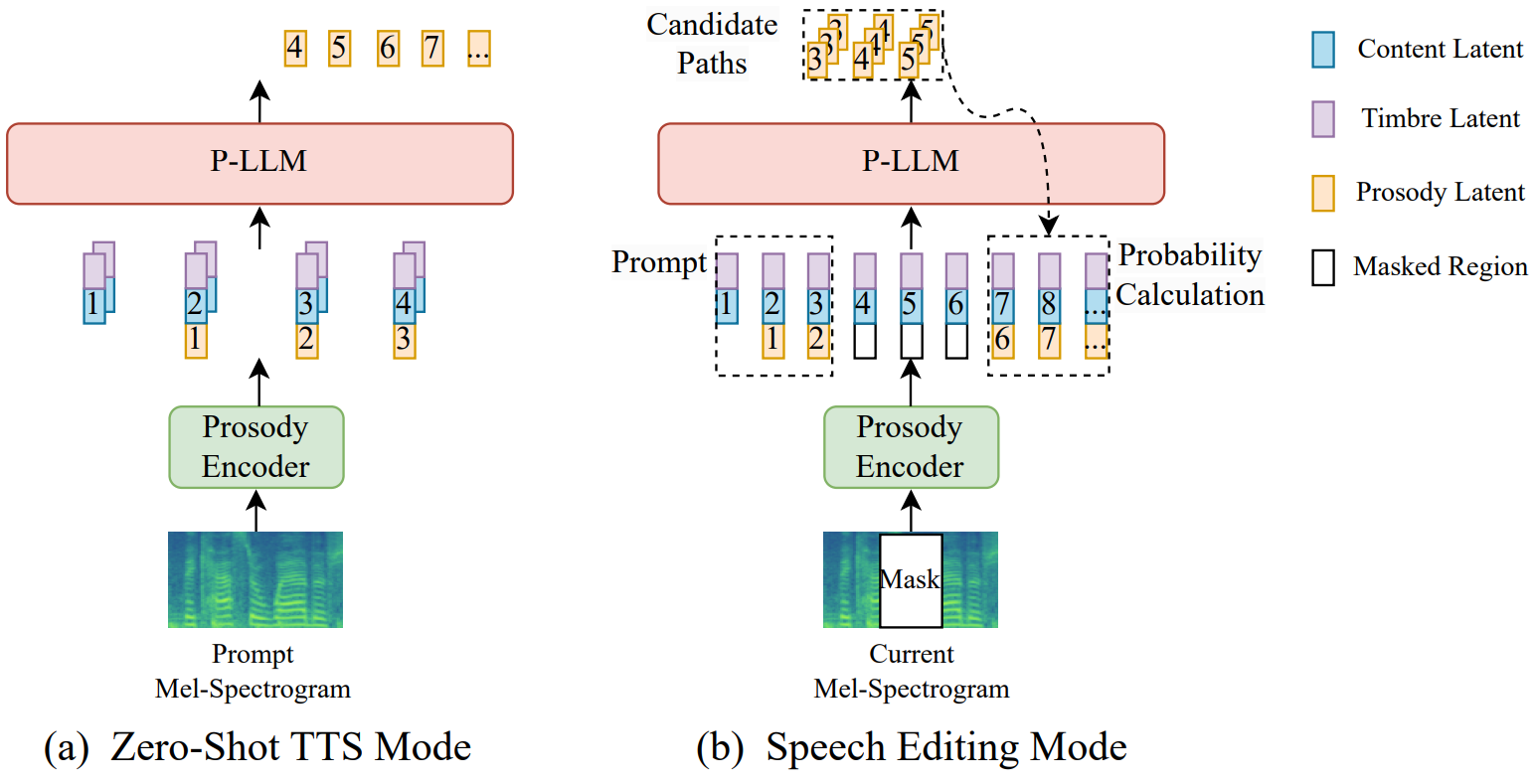
저자들은 다양한 음성 생성 task에 대한 in-context learning을 용이하게 하기 위해 Mega-TTS가 음성 프롬프트의 정보를 따르도록 장려하는 다양한 음성 프롬프트 메커니즘을 설계하였다.
Inference for TTS
Zero-shot TTS의 경우 P-LLM은 $u$, $H_\textrm{content}$, \(\tilde{H}_\textrm{timbre}\), \(\tilde{H}_\textrm{content}\)를 사용하여 타겟 음성에 대한 타겟 운율 코드 $\tilde{u}$를 생성한다. 샘플링 기반 방법이 생성된 음성의 다양성을 증가시킬 수 있기 때문에 결과를 샘플링하기 위해 top-k 랜덤 샘플링 방식을 사용한다. 그런 다음 콘텐츠 \(\tilde{H}_\textrm{content}\), 음색 \(\tilde{H}_\textrm{timbre}\), 운율 정보 $\tilde{u}$를 연결하여 mel decoder를 사용하여 타겟 음성 $y_t$를 생성한다. P-LLM의 적절한 inductive bias와 강력한 in-context learning 능력을 활용하여 생성된 음성은 유사한 음색뿐만 아니라 즉각적인 음성의 리듬 습관도 유지할 수 있다. 교차 언어 TTS의 경우 외국어 프롬프트 음성에서 $u$, $H_\textrm{content}$, \(\tilde{H}_\textrm{timbre}\), \(\tilde{H}_\textrm{content}\)을 추출하고 이후 과정은 zero-shot TTS와 동일하게 유지한다.
Inference for speech editing
음성 편집에서 예측된 운율 코드는 마스킹된 영역의 왼쪽 및 오른쪽 경계 모두에서 부드럽게 전환되어야 한다. EditSpeech와 같은 이전 연구들은 왼쪽과 오른쪽의 autoregressive inference를 개별적으로 수행하고 최소 L2-norm 차이 융합 지점에서 mel-spectrogram을 연결한다. 그러나 mel-spectrogram의 L2-norm 차이는 인간의 인지와는 거리가 멀기 때문에 오디오의 자연스러움에 좋지 않다. Mega-TTS의 운율 표현은 discrete하므로 discrete한 운율 표현에서 연산하여 전환 문제를 해결할 수 있다.
- 마스크의 왼쪽 영역을 top-k 랜덤 샘플링 전략으로 $N$개의 후보 경로를 생성하기 위한 프롬프트로 간주한다.
- 생성된 $N$개의 경로를 새로운 프롬프트로 사용하여 마스크 우측 영역의 확률 행렬을 생성하고, 확률 행렬로부터 각 디코딩 단계의 확률을 얻기 위해 ground-truth 운율 코드를 사용한다.
- 후보 경로에 대한 각 디코딩 단계의 로그 확률을 합산한다.
- 최대 확률을 달성하는 경로를 예측 결과로 선택한다.
음성 편집을 위한 디코딩 전략은 다음과 같다.
\[\begin{aligned} \max_{i \in [1, N]} \textrm{Likelihood} =\;& \max_{i \in [1, N]} \prod_{t = L}^R p (u_t^i \vert u_{<t}^i, H_\textrm{content}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}; \theta) \\ & \quad \cdot \prod_{t = R}^T p (u_t^\textrm{gt} \vert u_{<t}^i, H_\textrm{content}, \tilde{H}_\textrm{timbre}, \tilde{H}_\textrm{content}; \theta) \end{aligned}\]여기서 $L$과 $R$은 마스크의 왼쪽과 오른쪽 경계이다. $T$는 mel-spectrogram의 길이이다. $u^i$는 $i$번째 후보 경로의 운율 코드이다. $u_t^\textrm{gt}$는 ground-truth 운율 코드이다. 이 디코딩 전략은 양쪽 경계의 운율 정보를 고려하기 때문에 편집된 영역은 부드러운 전환을 달성할 수 있다.
Experiments
- 학습 데이터셋: GigaSpeech, WenetSpeech
- 평가 데이터셋: VCTK, LibriSpeech
- 모델 설정
- 운율 인코더, 음색 인코더, mel generator: convolution 블록 5개
- hidden size = 320
- convolution 1D kernel size = 5
- 콘텐츠 인코더
- Transformer layer 개수 = 4
- attention head 개수 = 2
- 임베딩 차원 = 320
- 1D convolution filter size = 1280
- convolution 1D kernel size = 5
- duration predictor: 3-layer 1D convolution
- ReLU, layer normalization
- hidden size = 320
- discriminator: SyntaSpeech를 따름
- P-LLM 모델
- Transformer layer 개수 = 8
- attention head 개수 = 8
- 임베딩 차원 = 512
- 1D convolution filter size = 2048
- convolution 1D kernel size = 5
- 전체 파라미터 개수: 2억 2250만개
- 운율 인코더, 음색 인코더, mel generator: convolution 블록 5개
- Training
- GPU: NVIDIA A100 8개
- batch size: 각 GPU당 30 문장
- optimizer: Adam ($\beta_1$ = 0.9, $\beta_2$ = 0.98, $\epsilon = 10^{-9}$)
- learning rate: Transformer와 동일
- Inference
- top-5 랜덤 샘플링 방식 사용
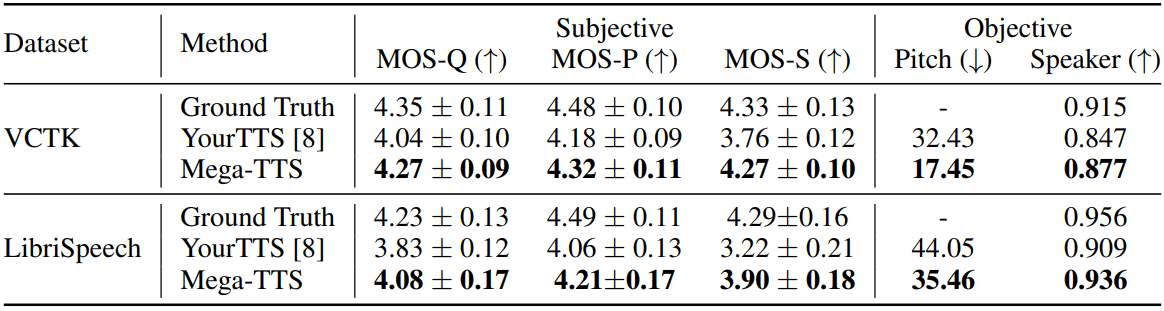
1. Results of zero-shot synthesis
다음은 zero-shot TTS에 대한 객관적 및 주관적 비교 결과이다.
다음은 Mega-TTS와 VALL-E의 비교 결과이다.
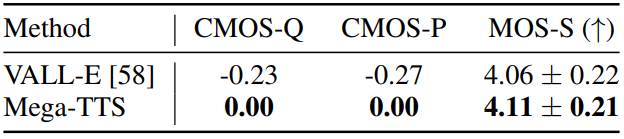
2. Results of zero-shot speech editing
다음은 VCTK에서 음성 편집 task에 대한 음성 품질, 음성 운율, speaker 유사성에 대한 MOS 평가 결과이다 (95% 신뢰 구간).
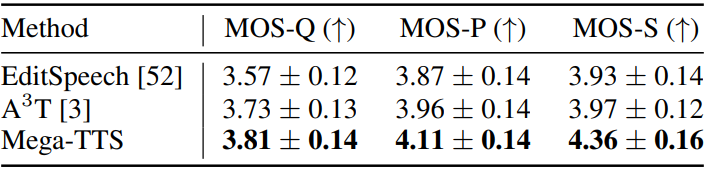
3. Results of zero-shot cross-lingual TTS
다음은 교차 언어 TTS 합성에 대한 비교 결과이다 (95% 신뢰 구간).
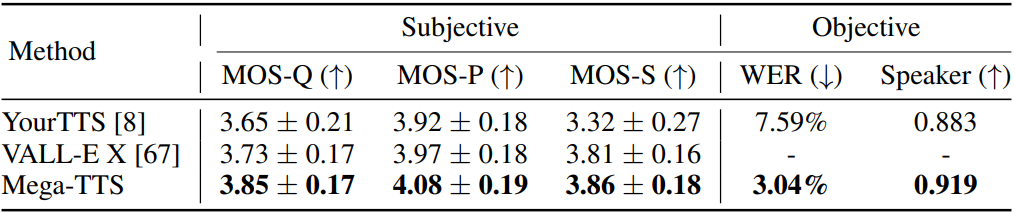
4. Results of robustness evaluation
다음은 50개의 특정 어려운 문장에 대한 robustness 비교 결과이다.
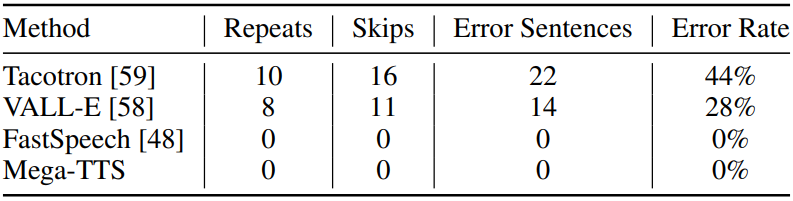
Limitations
- Data coverage: 학습을 위해 2만 시간의 다중 도메인 데이터를 사용하지만 Mega-TTS는 여전히 모든 사람의 목소리를 다룰 수 없다. 특히 악센트가 극도로 강한 일부 speaker의 경우, Mega-TTS는 말하는 스타일을 잘 모방할 수 없다.
- Reconstruction Robustness: VQGAN 기반 TTS 모델의 재구성 품질은 클린 데이터셋에서 만족스럽지만 배경 음악이나 매우 큰 잔향의 영향을 받는다.