[논문리뷰] Mask-Enhanced Autoregressive Prediction: Pay Less Attention to Learn More
ICML 2025. [Paper] [Page] [Github]
Xialie Zhuang, Zhikai Jia, Jianjin Li, Zhenyu Zhang, Li Shen, Zheng Cao, Shiwei Liu
University of Chinese Academy of Sciences | SCITIX (SGP) TECH | South China Normal University | University of Texas at Austin | Sun YatSen University | University of Oxford
11 Feb 2025
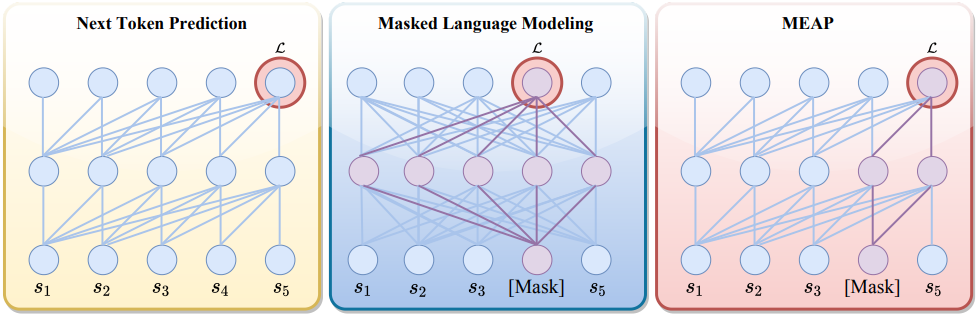
Introduction
Next-token prediction (NTP)은 많은 LLM의 기본적인 training objective이다. NTP는 이전 토큰을 모두 고려하여 시퀀스의 다음 토큰을 예측하는 모델을 학습시킨다. 뛰어난 scaling 효율성과 텍스트 생성 성능 덕분에 NTP 기반 LLM은 SOTA LLM의 주요 패러다임으로 자리매김했다. 그러나 최근 연구들에 따르면 NTP 기반 LLM은 컨텍스트에서 핵심 정보를 정확하게 검색하는 데 한계가 있음이 나타났다.
이와 대조적으로, BERT에서 사용되는 masked language modeling (MLM)은 양방향 attention을 사용하여 마스킹된 입력을 재구성한다. 이러한 특성으로 인해 MLM은 정확한 정보 검색과 문장 수준의 이해가 필요한 task에 특히 효과적이다. 그러나 MLM은 마스킹된 토큰 재구성에 본질적으로 초점을 맞추기 때문에 일관되고 긴 형식의 텍스트 생성이 필요한 task에서는 그 효과가 떨어진다.
NTP와 MLM을 결합하여 각각의 장점을 활용하는 것은 여전히 쉽지 않은 과제이다. MLM은 일반적으로 2-stack 인코더-디코더 아키텍처에서 가장 잘 작동하며, decoder-only Transformer에 적용하면 성능이 크게 저하된다. 두 가지를 통합하려는 노력은 일반적으로 사전 학습 과정에서 두 objective를 번갈아 가며 사용하는 파이프라인에 의존한다. 그러나 이러한 방식은 학습 파이프라인에 상당한 복잡성을 유발하여 scaling이 어렵고, 특히 파라미터가 굉장히 많은 모델의 경우 더욱 그렇다.
본 논문은 마스킹된 토큰을 NTP에 완벽하게 통합하는 간단하면서도 효과적인 LLM 학습 패러다임인 Mask-Enhanced Autoregressive Prediction (MEAP)을 제안하였다. 구체적으로, 먼저 입력 토큰의 일부를 무작위로 마스킹한 후, decoder-only Transformer를 사용하여 autoregressive 방식으로 NTP를 직접 수행한다. 이러한 간단한 수정을 통해 양방향 attention이나 값비싼 인코더-디코더 아키텍처가 필요 없으므로 학습 중 추가적인 계산 오버헤드가 발생하지 않는다. Inference 시에 생성된 LLM은 추가적인 엔지니어링 노력 없이 NTP로 학습된 LLM만큼 간단하게 작동한다. MEAP의 단순성 덕분에 decoder-only LLM의 뛰어난 scaling 효율성을 유지하면서도 LLM의 핵심 정보 검색 및 긴 컨텍스트 추론 성능을 향상시킬 수 있다.
MEAP는 사전 학습과 fine-tuning 시나리오 모두에서 효과적으로 작동한다. MEAP의 효과는 가려지지 않은 토큰의 수를 줄여 attention 구분 능력을 향상시키는 능력에서 비롯된다. 이 메커니즘은 주변 컨텍스트의 영향을 줄이는 동시에 task 관련 신호에 대한 모델의 attention을 예리하게 한다. 본질적으로 MEAP는 더 적은 토큰에 attention을 기울임으로써 더 많은 것을 학습한다.
Method
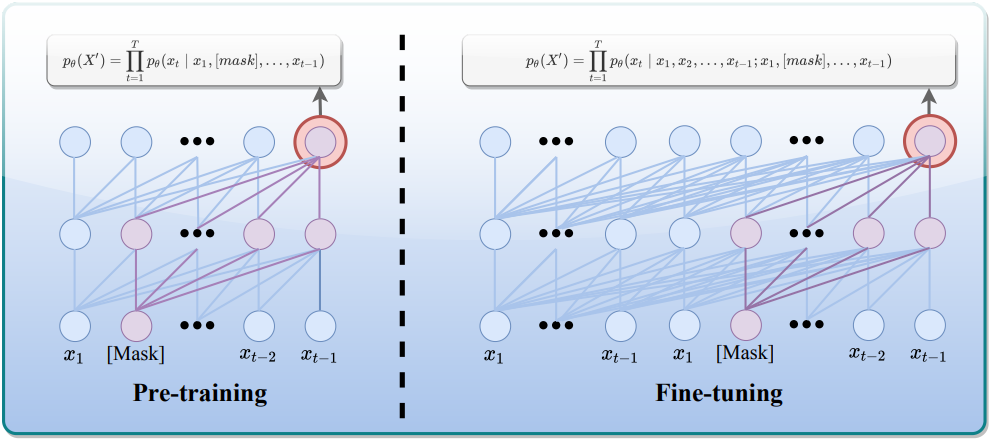
1. LLM pre-training
MEAP의 핵심 아이디어는 사전 학습 단계에서 입력의 일부를 선택적으로 마스킹하는 것이다. 구체적으로, 입력 시퀀스의 토큰을 미리 정의된 비율 $P$에 따라 무작위로 마스킹하는 고정 비율 마스킹 메커니즘을 사용한다. 이러한 방식으로 모델은 컨텍스트 정보가 없는 상황에서도 학습하도록 강제되며, 이는 모델의 깊은 이해 및 추론 능력을 향상시키는 데 도움이 된다.
Decoder-only Transformer $\theta$와 입력 시퀀스 $X = (x_1, \ldots, x_n)$이 주어졌을 때, 먼저 $P$의 비율로 토큰 일부를 무작위로 마스킹한다.
\[\begin{equation} X^\prime = (x_1, [\textrm{mask}], \ldots, x_{t-1}, x_t) \end{equation}\]그런 다음, 마스킹된 입력을 사용하여 왼쪽에서 오른쪽으로 이동하는 방식으로 일반적인 NTP를 수행한다.
\[\begin{equation} p_\theta (X^\prime) = \prod_{t=1}^T p_\theta (x_t \, \vert \, x_1, [\textrm{mask}], \ldots, x_{t-1}) \end{equation}\]NTP와 마찬가지로, 모델이 마스킹된 토큰을 예측할 때, causal masked attention을 사용하여 이전 토큰만으로 마스킹된 토큰을 예측한다. 사전 학습을 위한 마스크 비율 $P = 15\%$는 모델이 사전 학습 과정을 과도하게 방해하지 않으면서 적절한 수준의 학습 난이도와 학습 신호를 받을 수 있도록 신중하게 선택되었다. 마스킹된 토큰의 수가 비교적 적기 때문에 이 접근법은 사전 학습 오버헤드를 크게 증가시키거나 원래 학습 절차를 변경하지 않고도 기존 NTP 프레임워크에 원활하게 통합될 수 있다.
2. LLM fine-tuning
MEAP는 fine-tuning 시나리오에도 확장될 수 있다. Fine-tuning 시나리오에서는 학습 샘플을 복제하고 fine-tuning 과정에서 복사된 시퀀스에 동일한 랜덤 마스킹 전략을 적용한다. 원본 시퀀스와 마스킹된 시퀀스를 하나의 입력 시퀀스로 결합하여 모델에 입력한다.
Cross-entropy loss는 답변 토큰 $U_q$의 마스킹된 토큰 $U_m$에 대해서만 계산된다. 이 디자인은 supervised fine-tuning에서 입력 시퀀스가 종종 후속 task에 필수적인 핵심 정보를 포함한다는 중요한 문제를 해결한다. 원본 시퀀스를 직접 마스킹하면 중요한 정보가 제거되어 대상 task에서 모델의 성능이 저하될 위험이 있다. 복제된 시퀀스를 마스킹하면 이러한 문제를 피하면서 MLM과 NTP를 통합할 수 있다.
Fine-tuning의 경우, $P = 10\%$를 선택한다. 답변 길이가 50을 초과하는 QA 쌍에 대해서만 MEAP를 수행하고, 그렇지 않은 경우에는 해당 쌍에 대해 일반적인 NTP를 수행한다. Fine-tuning을 위한 objective는 다음과 같다.
\[\begin{equation} \mathcal{L} (\theta) = - \sum_{t \in U_q \cup U_m} \log p_\theta (x_t \, \vert \, x_1, \ldots, x_{t-1}, \hat{x}_1, [\textrm{mask}], \ldots, \hat{x}_{t-1}) \end{equation}\](시퀀스 \(\{\hat{x}_i\}\)는 원본 시퀀스 \(\{x_i\}\)의 복사본, 즉 \(\hat{x}_i = x_i\))
주목할 점은 MEAP가 fine-tuning 중에 시퀀스 길이를 두 배로 늘리는 반면, NTP보다 절반의 학습 시간으로 더 뛰어난 성능을 달성하며, 본질적으로 더 적은 학습 토큰으로 더 강력한 결과를 얻는다는 것이다.
MEAP의 효과는 LLM 학습 중 더 적은 토큰에 집중함으로써 더 명확한 attention을 유도하는 능력에 기인한다. 왜냐하면 가려진 토큰은 일반적으로 무시할 만한 attention을 받기 때문이다. 이러한 수정은 모델이 주변 컨텍스트의 영향을 줄이면서 task 관련 신호에 집중할 수 있도록 도와준다.
Experimental Results
1. Pre-training Evaluation
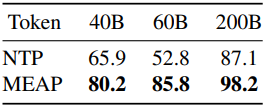
다음은 사전 학습에 대한 언어 모델링 평가 결과이다.

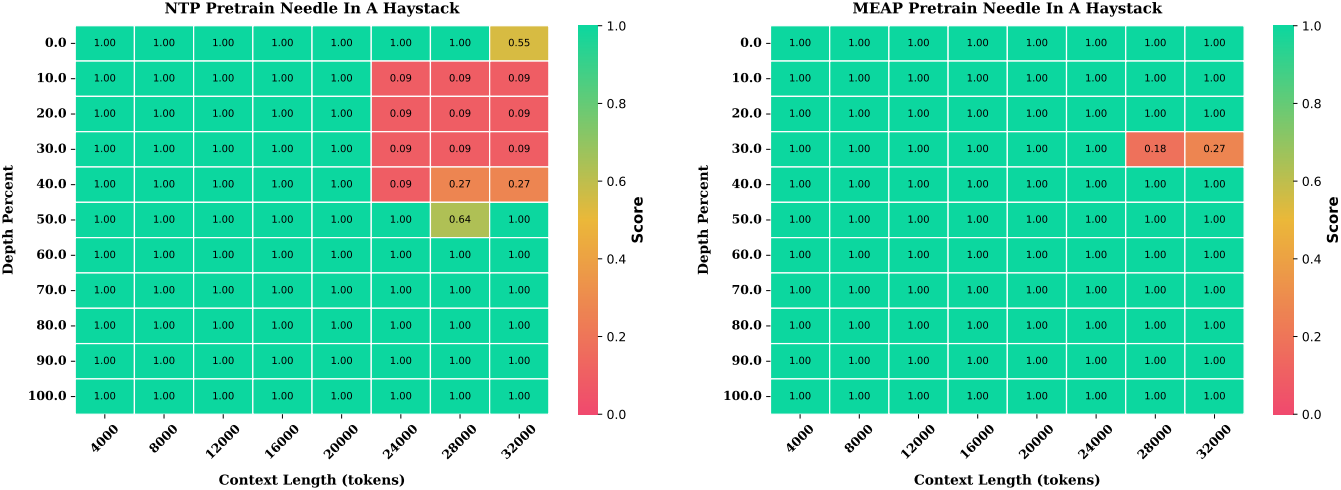
다음은 Needle-in-a-Haystack 결과이다.
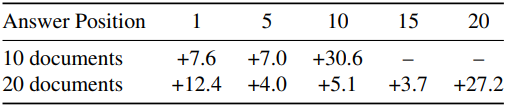
다음은 여러 문서에 대한 QA 성능을 비교한 결과이다. (NTP 대비 성능 정확도 증가)
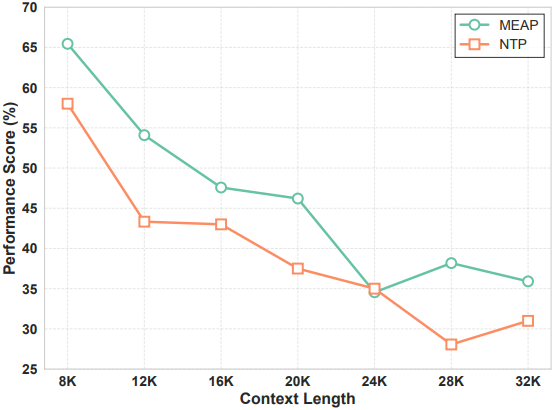
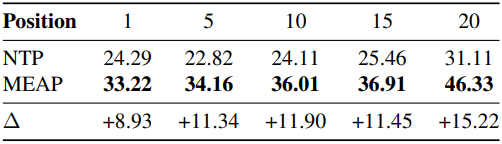
다음은 긴 컨텍스트 추론 성능을 비교한 결과이다. (Multi-Needle Reasoning Task)
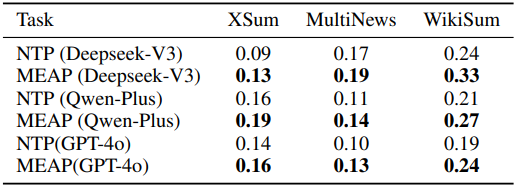
다음은 여러 LLM judge로 hallucination을 평가한 결과이다.
2. Fine-tuning Evaluation
다음은 fine-tuning에 대한 언어 모델링 평가 결과이다.

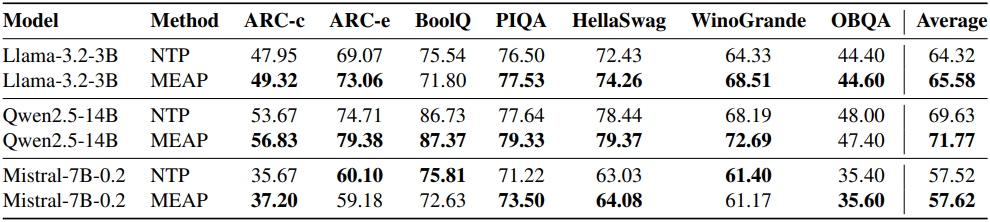
다음은 상식적 추론 task에 대한 fine-tuning 성능을 비교한 결과이다.
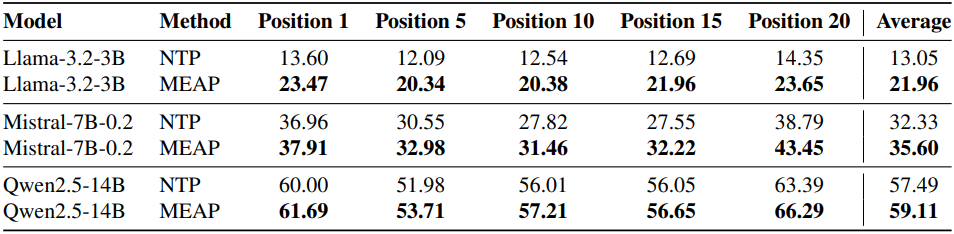
다음은 여러 문서에 대한 QA 성능을 비교한 결과이다. (문서 20개)
3. Training Efficiency Analysis
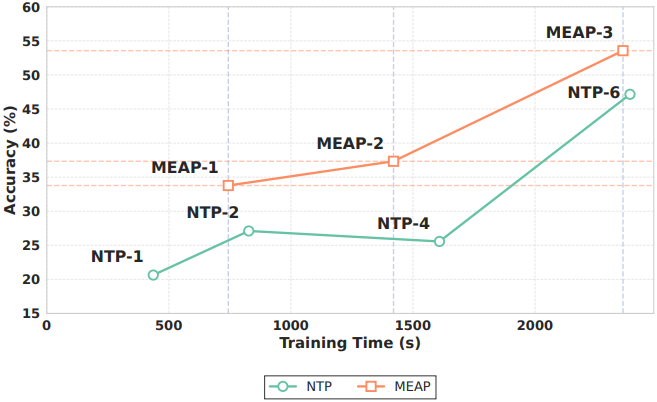
다음은 fine-tuning 효율성을 비교한 결과이다. (MEAP-n은 n epoch으로 MEAP 학습)
4. Why Does MEAP Work?
마스킹은 더욱 뚜렷한 attention으로 유도한다.
다음은 attention score 패턴에 대한 통계적 분석 결과이다.
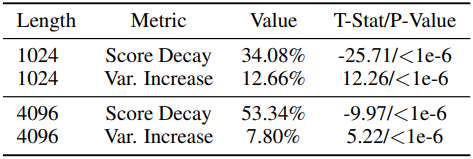
- Attention Score Decay: 마스킹된 위치에서 평균 attention score의 감소 백분율
- Attention Variance Increase: 마스킹 되지 않은 위치에서 attention 분산 증가
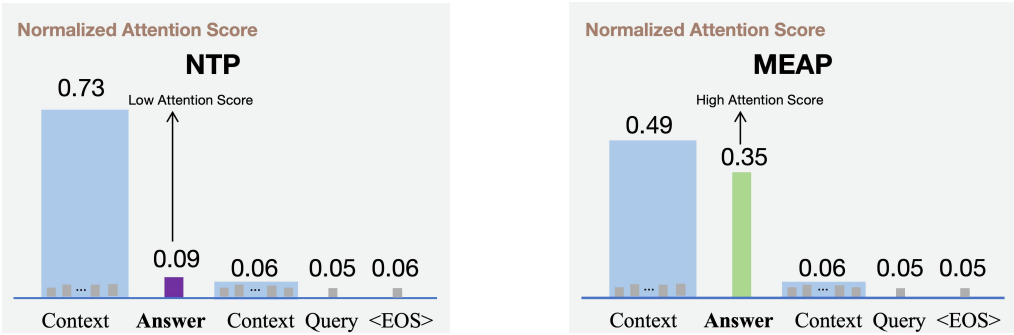
MEAP는 task 관련 토큰에 더 집중한다.
다음은 inference 중에 다음과 같은 입력 시퀀스에 대한 NTP와 MEAP의 attention 분포를 비교한 것이다.
Context: “In the heart of Paris, the Eiffel Tower stands tall, symbolizing both the city and the entire country.”
Answer: “Designed by Gustave Eiffel”
Context: “, it was completed in 1889 for the World’s Fair. Originally criticized for its unusual design, it has since become one of the most recognizable landmarks in the world. Tourists from all over the globe visit it every year, making it one of the most photographed monuments.”
Query: “question: Who designed the Eiffel Tower?”
5. Ablation Study
다음은 마스킹 비율에 대한 ablation 결과이다.
