[논문리뷰] Masked Diffusion Transformer is a Strong Image Synthesizer (MDT)
ICCV 2023. [Paper] [Github]
Shanghua Gao, Pan Zhou, Ming-Ming Cheng, Shuicheng Yan
Sea AI Lab | Nankai University
25 Mar 2023

Introduction
Diffusion probabilistic model (DPM)은 이미지 레벨 생성 모델의 최근 발전에 앞장서 왔으며 종종 이전의 SOTA GAN을 능가한다. 또한 DPM은 text-to-image 생성과 음성 생성을 비롯한 수많은 다른 애플리케이션에서 성공을 입증했다. DPM은 확률 미분 방정식(SDE)을 채택하여 Gaussian noise를 여러 timestep으로 샘플에 점진적으로 매핑하며 각 단계는 네트워크 평가에 해당한다. 실제로 SDE가 수렴하는 데 필요한 수천 개의 timestep으로 인해 샘플을 생성하는 데 시간이 많이 걸린다. 이 문제를 해결하기 위해 inference 속도를 가속화하기 위해 다양한 생성 샘플링 전략이 제안되었다. 그럼에도 불구하고 DPM의 학습 속도를 개선하는 것은 덜 탐구되었지만 매우 바람직하다. 또한 DPM 학습에는 SDE 수렴을 보장하기 위해 불가피하게 많은 timestep이 필요하므로 특히 생성 성능을 개선하기 위해 대규모 모델과 데이터가 자주 사용되는 이 생성에는 계산 비용이 매우 많이 든다.

저자들은 먼저 DPM이 이미지의 개체 부분 간의 관련 관계들을 학습하는 데 어려움을 겪는 것을 관찰하였다. 이로 인해 학습 과정이 느려진다. 구체적으로, 위 그림에서 볼 수 있듯이 DiT를 backbone으로 하는 고전적인 DPM인 DDPM은 5만 번째 학습 step에서 개의 모양을 학습한 다음 20만 번째 step까지 강아지의 한쪽 눈과 입을 학습하였다. 또한 두 귀의 상대적 위치는 30만 번째 step에서도 그다지 정확하지 않다. 이 학습 과정은 DPM이 semantic 부분 간의 관련 관계를 학습하지 못하고 실제로 각 semantic을 독립적으로 학습한다는 것을 보여준다. 이러한 현상의 원인은 DPM이 이미지의 개체 부분 간의 관련 관계를 무시하는 픽셀당 예측 loss를 최소화하여 실제 데이터의 로그 확률을 최대화하여 학습 진행이 느리기 때문이다.
본 논문은 위의 관찰에서 영감을 받아 DPM의 학습 효율성을 향상시키기 위해 효과적인 Masked Diffusion Transformer (MDT)를 제안한다. MDT는 문맥 학습 능력을 명시적으로 향상시키고 이미지의 semantic 간의 관련 관계 학습을 향상시키기 위해 transformer 기반 DPM용으로 설계된 mask latent modeling 체계를 제안한다. 특히 MDT는 latent space에서 diffusion process를 수행하여 계산 비용을 절감한다. 특정 이미지 토큰을 마스킹하고 asymmetric masking diffusion transformer (AMDT)를 설계하여 마스킹되지 않은 토큰에서 마스킹된 토큰을 diffusion 생성 방식으로 예측한다. 이를 위해 AMDT에는 인코더, side-interpolater, 디코더가 포함되어 있다.
인코더와 디코더는 마스킹된 토큰을 예측하는 데 도움이 되도록 글로벌 토큰과 로컬 토큰 위치 정보를 삽입하여 DiT의 transformer 블록을 수정한다. 인코더는 마스크가 없기 때문에 inference 중에 모든 토큰을 처리하는 동안 학습 중에 마스킹되지 않은 토큰만 처리한다. 따라서 디코더가 학습 예측 또는 inference 생성을 위해 항상 모든 토큰을 처리하도록 하기 위해 소규모 네트워크에서 구현된 side-interpolater는 학습 중에 인코더 출력에서 마스킹된 토큰을 예측하는 것을 목표로 하며 inference 중에 제거된다.

이 masking latent modeling 체계를 통해 MDT는 컨텍스트의 불완전한 입력에서 이미지의 전체 정보를 재구성하여 이미지의 semantic 간의 관련 관계를 학습할 수 있다. 위 그림에서 볼 수 있듯이 MDT는 일반적으로 거의 동일한 학습 단계에서 개의 두 눈과 두 귀를 생성하며 mask latent modeling 체계를 활용하여 이미지의 관련 의미를 올바르게 학습한다. MDT는 DiT보다 우수한 관계 모델링과 빠른 학습 능력을 가진다.
MDT는 이미지 합성 task에서 우수한 성능을 달성하고 ImageNet 데이터셋에서 클래스 조건부 이미지 합성에 대한 새로운 SOTA를 달성하였다. 또한 MDT는 DiT보다 약 3배 더 빠르게 학습이 진행된다.
Masked Diffusion Transformer
1. Overview
DiT backbone이 있는 DPM은 이미지의 semantic 간의 관련 관계를 천천히 학습하기 때문에 느린 학습 수렴을 나타낸다. 이 문제를 해결하기 위해 본 논문은 mask latent modeling 체계를 도입하여 상황별 학습 능력을 명시적으로 향상시키고 이미지의 다른 semantic 간에 관련 관계를 설정하는 능력을 향상시키는 Masked Diffusion Transformer (MDT)를 제안한다.
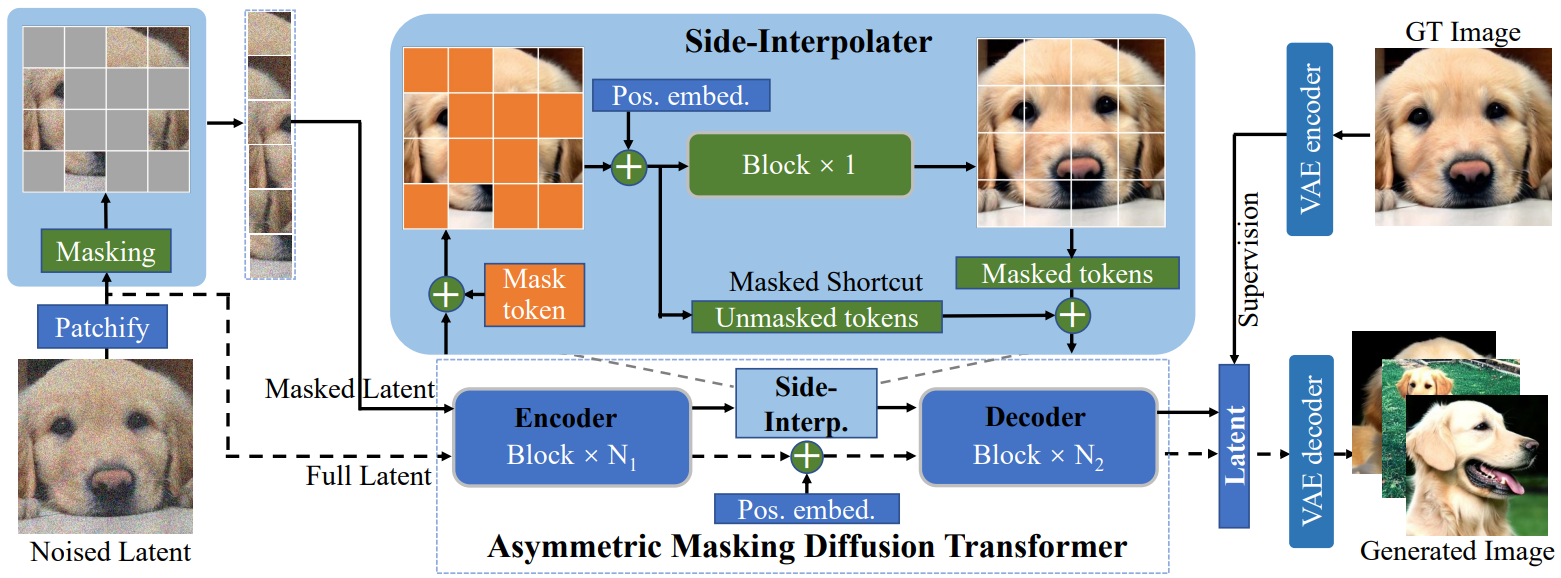
이를 위해 MDT는 위 그림과 같이 2가지로 구성된다.
- latent space에서 입력 이미지를 마스킹하는 latent masking 연산
- DPM으로 마스킹된 입력을 받으며 diffusion process를 수행하는 asymmetric masking diffusion transformer
계산 비용을 줄이기 위해 MDT는 Latent Diffusion을 따라 픽셀 space 대신 latent space에서 생성 학습을 수행한다.
학습 단계에서 MDT는 먼저 사전 학습된 VAE 인코더를 사용하여 이미지를 latent space로 인코딩한다. 그런 다음 MDT의 latent masking 연산은 이미지 latent 임베딩에 Gaussian noise를 추가하고 noisy한 latent 임베딩을 일련의 토큰으로 패치하고 특정 토큰을 마스킹한다. 나머지 마스킹되지 않은 토큰은 마스킹되지 않은 토큰에서 마스킹된 토큰을 예측하기 위해 인코더, side-interpolater, 디코더가 포함된 asymmetric masking diffusion transformer에 공급된다. Inference 중에 MDT는 side-interpolater를 위치 임베딩 추가 연산으로 대체한다. MDT는 Gaussian noise의 latent 임베딩을 입력으로 받아 denoise된 latent 임베딩을 생성한 다음 이미지 생성을 위해 사전 학습된 VAE 디코더로 전달한다.
학습 단계에서 위의 masking latent modeling 체계는 diffusion model이 컨텍스트상의 불완전한 입력으로부터 이미지의 전체 정보를 재구성하도록 강제한다. 따라서 모델은 이미지 latent 토큰 간의 관계, 특히 이미지의 semantic 간의 관련 관계를 학습하도록 권장된다. 예를 들어, 위 그림과 같이 모델은 먼저 개 이미지의 작은 이미지 부분 (토큰) 간의 올바른 연관 관계를 잘 이해해야 한다. 그런 다음 마스킹되지 않은 다른 토큰을 컨텍스트 정보로 사용하여 마스킹된 “눈” 토큰을 생성해야 한다.
2. Latent Masking
Latent diffusion model (LDM)에 따라 MDT는 픽셀 space 대신 latent space에서 생성 학습을 수행하여 계산 비용을 줄인다.
Latent diffusion model (LDM)
LDM은 사전 학습된 VAE 인코더 $E$를 사용하여 이미지 $v \in \mathbb{R}^{3 \times H \times W}$를 latent 임베딩 $z = E(v) \in \mathbb{R}^{c \times h \times w}$로 인코딩한. Forward process에서 $z$에 점진적으로 noise를 추가한 다음 reverse process에서 $z$를 예측하기 위해 noise를 제거한다. 마지막으로 LDM은 사전 학습된 VAE 디코더 $D$를 사용하여 $z$를 고해상도 이미지 $v = D(z)$로 디코딩한다. VAE 인코더와 디코더는 학습과 inference 중에 고정된 상태로 유지된다. $h$와 $w$는 $H$와 $W$보다 작기 때문에 저해상도 latent space에서 diffusion process를 수행하는 것이 픽셀 space에 비해 더 효율적이. 본 논문에서는 LDM의 효율적인 diffusion process를 채택한다.
Latent masking operation
학습하는 동안 먼저 이미지의 latent 임베딩 $z$에 Gaussian noise를 추가한다. 그런 다음 noisy한 임베딩 $z$를 $p \times p$ 크기의 토큰 시퀀스로 나누고 행렬 $u \in \mathbb{R}^{d \times N}$에 concat한다. 여기서 $d$는 채널 수이고 $N$은 토큰 수이다. 다음으로 비율 $\rho$로 랜덤하게 토큰을 마스킹하고 나머지 토큰을 $\hat{u} \in \mathbb{R}^{d \times \hat{N}}$으로 concat한다. 여기서 $\hat{N} = \rho N$이다. 따라서 1이 마스킹된 토큰을 나타내고 0이 마스킹되지 않은 토큰을 나타내는 이진 마스크 $M ∈ \mathbb{R}^{N}$을 생성할 수 있다. 마지막으로 마스킹되지 않은 토큰 $\hat{u}$를 처리를 위해 diffusion model에 공급한다. 모델이 마스킹된 토큰을 예측하는 대신 semantic 학습에 집중해야 하기 때문에 마스킹되지 않은 토큰 $\hat{u}$만 사용한다. 또한 $N$개의 토큰을 모두 처리하는 것에 비해 학습 비용이 절감된다.
3. Asymmetric Masking Diffusion Transformer
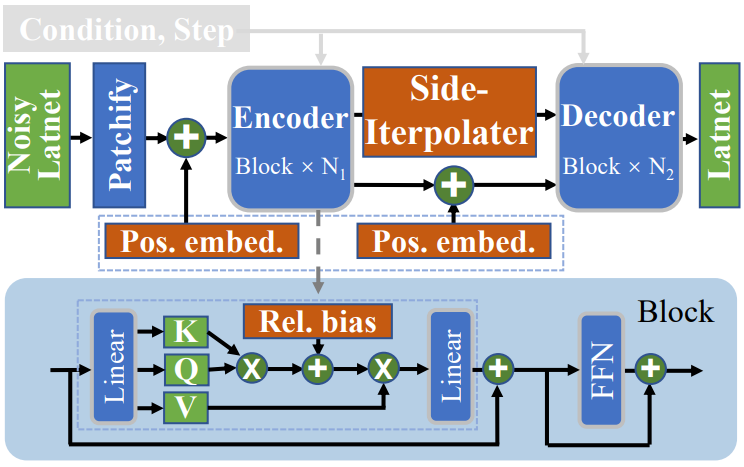
Mask latent modeling과 diffusion process의 공동 학습을 수행하기 위한 asymmetric masking diffusion transformer를 도입한다. 위 그림과 같이 인코더, side-interpolater, 디코더의 세 가지 구성 요소로 구성된다.
Position-aware encoder and decoder
MDT에서 마스킹되지 않은 토큰에서 마스킹된 latent 토큰을 예측하려면 모든 토큰의 위치 관계가 필요하다. 저자들은 모델의 위치 정보를 향상시키기 위해 마스킹된 latent 토큰의 학습을 용이하게 하는 위치 인식 인코더와 디코더를 제안하였다. 구체적으로 인코더와 디코더는 두 종류의 토큰 위치 정보를 추가하여 표준 DiT 블록을 맞춤화하고 각각 $N_1$ 개와 $N_2$개의 맞춤 블록을 포함한다.
첫째, 인코더는 기존의 학습 가능한 글로벌 위치 임베딩을 noisy한 latent 임베딩 입력에 추가한다. 유사하게, 디코더도 학습 가능한 위치 임베딩을 입력에 도입하지만 학습 및 inference 단계에서 다른 접근 방식을 사용한다. 학습 중에 side-interpolater는 이미 아래에 소개된 것처럼 학습 가능한 글로벌 위치 임베딩을 사용하여 글로벌 위치 정보를 디코더에 전달할 수 있다. Inference하는 동안 side-interpolater가 폐기되기 때문에 디코더는 위치 정보를 향상시키기 위해 위치 임베딩을 입력에 명시적으로 추가한다.
둘째, 인코더와 디코더는 self-attention의 attention score를 계산할 때 각 블록의 각 head에 로컬한 상대적 위치 바이어스를 추가한다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = \textrm{Softmax} \bigg( \frac{QK^\top}{\sqrt{d_k}} + B_r \bigg) V \end{equation}\]여기서 $Q$, $K$, $V$는 각각 self-attention 모듈의 query, key, value를 나타내고, $d_k$는 key의 차원이며, $B_r \in \mathbb{R}^{N \times N}$은 $i$번째 위치와 다른 위치 사이의 상대적 위치 차이 $\Delta$에 의해 선택되는 상대적 위치 바이어스, 즉 $B_r (i, \Delta)$이다. 학습 가능한 매핑 $B_r$은 학습 중에 업데이트된다. 로컬한 상대적 위치 바이어스는 토큰 간의 상대적 관계를 포착하는 데 도움이 되어 masking latent modeling을 용이하게 한다.
인코더는 마스킹되지 않은 noisy한 latent 임베딩을 가져와 학습/inference 중에 side-interpolater/디코더에 출력을 공급한다. 디코더의 경우 입력은 학습을 위한 side-interpolater의 출력 또는 인코더 출력과 inference를 위한 학습 가능한 위치 임베딩의 조합이다. 학습하는 동안 인코더와 디코더는 각각 마스킹되지 않은 토큰과 전체 토큰을 처리하므로 모델을 “비대칭” 모델이라고 한다.
Side-interpolater
학습 중에 효율성과 성능 향상을 위해 인코더는 마스킹되지 않은 토큰 $\hat{u}$만 처리한다. Inference 단계에서 인코더는 마스크 부족으로 인해 모든 토큰 $u$를 처리한다. 이는 적어도 토큰 수 측면에서 학습과 inference 중에 인코더 출력 (즉, 디코더 입력)에 큰 차이가 있음을 의미한다. 디코더가 학습 예측 또는 inference 생성을 위해 항상 모든 토큰을 처리하도록 하기 위해 소규모 네트워크에 의해 구현된 side-interpolater는 학습 중에 인코더 출력에서 마스킹된 토큰을 예측하는 것을 목표로 하며 inference 중에 제거된다.
학습 단계에서 인코더는 마스킹되지 않은 토큰을 처리하여 $\hat{q} \in \mathbb{R}^{d \times \hat{N}}$을 임베딩하는 출력 토큰을 얻는다. 그런 다음 side-interpolater는 먼저 공유된 학습 가능한 마스크 토큰으로 마스킹된 위치를 채우고 학습 가능한 위치 임베딩을 추가하여 임베딩 $q \in \mathbb{R}^{d \times N}$을 얻는다. 다음으로 인코더의 기본 블록을 사용하여 $q$를 처리하여 보간된 임베딩 $\hat{k}$를 예측한다. $\hat{k}$의 토큰은 예측된 토큰을 나타낸다. 마지막으로 마스킹된 shortcut connection을 사용하여
\[\begin{equation} k = M \cdot q + (1 −M) \cdot \hat{k} \end{equation}\]로 예측된 $\hat{k}$와 $q$를 결합한다. 요약하면 마스킹된 토큰의 경우 side-interpolater에 의한 예측을 사용한다. 마스킹되지 않은 토큰의 경우 여전히 $q$에서 해당 토큰을 채택한다. 이는
- 학습 단계와 inference 단계 사이의 일관성을 높이고
- 디코더에서 마스크 재구성 프로세스를 제거할 수 있다.
Inference 중에 마스크가 없기 때문에 side-interpolater는 학습된 위치 임베딩을 추가하는 위치 임베딩 연산으로 대체된다. 이렇게 하면 디코더가 항상 모든 토큰을 처리하고 학습 예측 또는 inference 생성을 위해 동일한 위치 임베딩을 사용하므로 이미지 생성 성능이 향상된다.
4. Training
학습하는 동안 전체 latent 임베딩 $u$와 마스킹된 latent 임베딩 $\hat{u}$을 diffusion model에 공급한다. 마스킹된 latent 임베딩만 사용하면 모델이 diffusion 학습을 무시하면서 마스크 영역 재구성에 너무 집중하게 되기 때문이다. 비대칭 마스킹 구조로 인해 마스킹된 latent 임베딩을 사용하기 위한 추가 비용이 적다. 이는 MDT가 여전히 총 학습 시간 측면에서 이전 SOTA DiT보다 약 3배 더 빠른 학습이 가능하다.
Experiments
- 데이터셋: ImageNet 256$\times$256
- 모델 아키텍처
- DiT를 따라 전체 블록 수 $N_1 + N_2$, 토큰 수, 채널 수를 설정
- 작은 패치 크기를 사용할 때 성능이 좋으므로 $p = 2$ 사용
- VAE: Stable Diffusion의 VAE를 고정하여 사용 (다운샘플링 비율 = 1/8, 채널 차원 = 4)
- 학습 디테일
- optimizer: AdamW
- learning rate: $3 \times 10^{-4}$
- batch size: 256
- 마스킹 비율: 0.3
- $N_2$ = 2
- diffusion step: 1000
- 분산 schedule: $10^{-4}$ ~ $2 \times 10^{-2}$ (선형)
- 기타 세팅은 DiT와 동일
1. Comparison Results
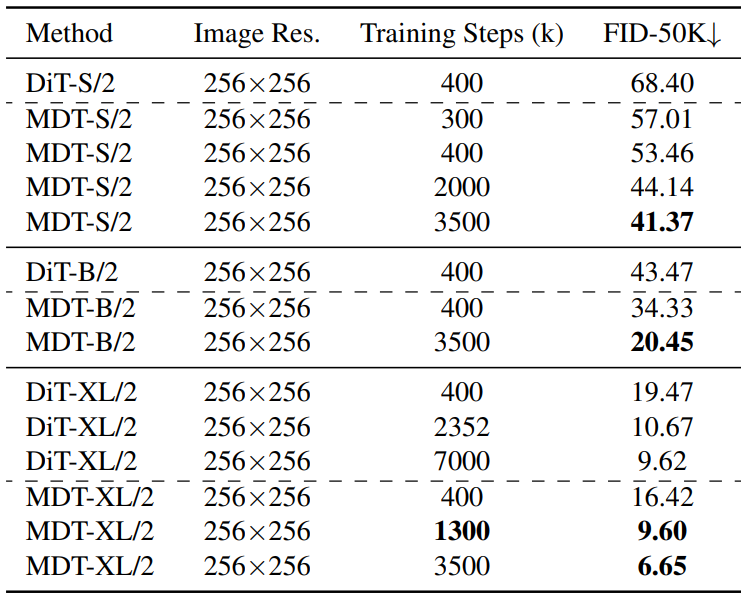
다음은 다양한 모델 크기와 학습 step 하에서 DiT와 MDT를 비교한 표이다.
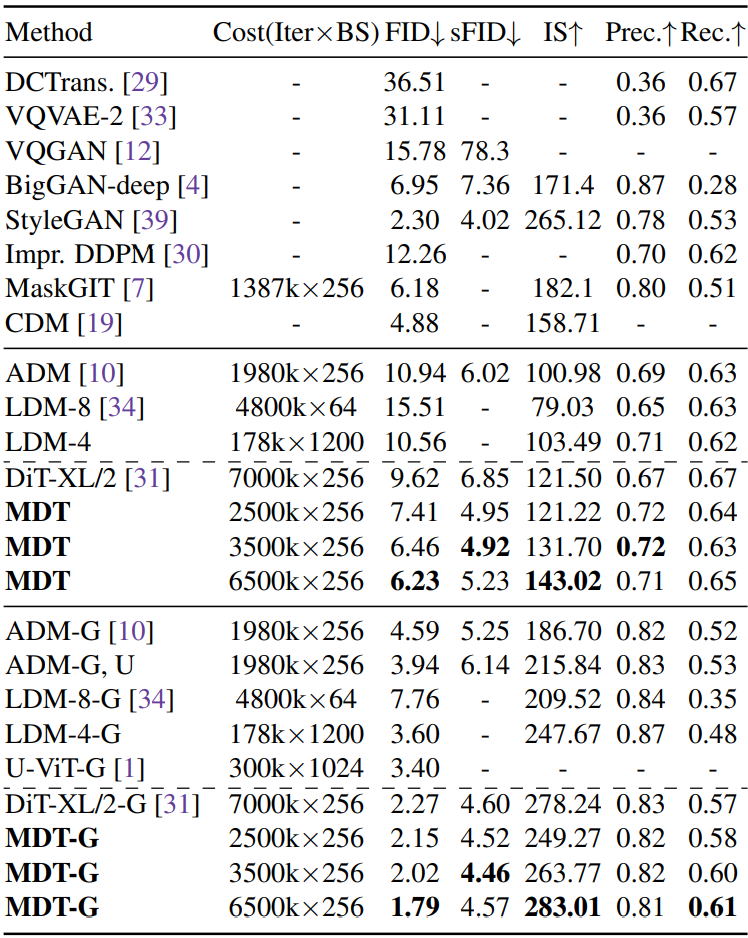
다음은 다양한 방법들과 클래스 조건부 이미지 생성 성능을 비교한 표이다.
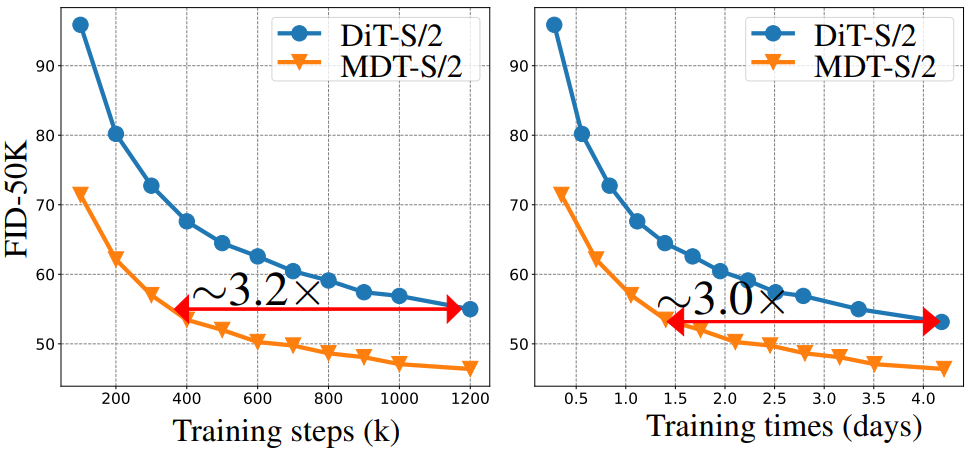
다음은 DiT와 MDT의 학습 속도를 비교한 그래프이다.
2. Ablation
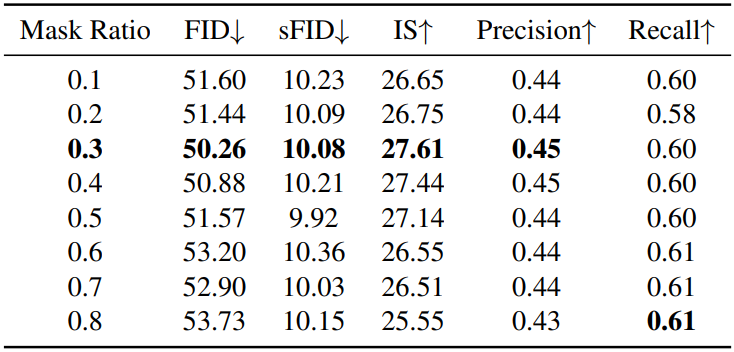
다음은 다양한 마스킹 비율에 따른 성능을 비교한 표이다.
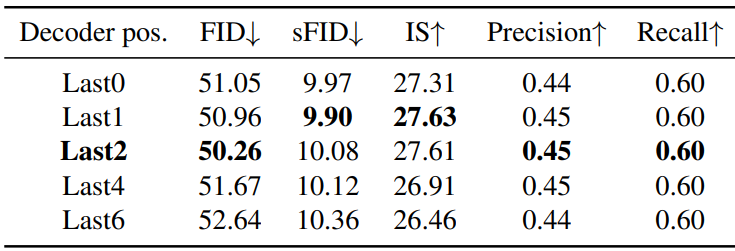
다음은 side-interpolater의 위치에 따른 성능을 비교한 표이다.
다음은 다양한 ablation study 결과이다.
