[논문리뷰] Motion-Conditioned Diffusion Model for Controllable Video Synthesis (MCDiff)
arXiv 2023. [Paper] [Page]
Tsai-Shien Chen, Chieh Hubert Lin, Hung-Yu Tseng, Tsung-Yi Lin, Ming-Hsuan Yang
University of California | Meta | NVIDIA | Google Research
27 Apr 2023

Introduction
사용자가 원하는 콘텐츠와 모션을 지정할 수 있는 제어 가능한 동영상 합성은 시각 효과 합성, 동영상 편집 및 애니메이션과 같은 분야에서 수많은 애플리케이션이 있다. Diffusion model이 동영상 합성에서 상당한 발전을 이루었지만 제어 가능성의 정도는 거친 클래스 또는 텍스트 프롬프트로 제한된다. 이 관찰은 동영상 합성 절차에 대한 보다 세분화된 사용자 제어, 특히 사용자가 합성 동영상 내에서 예상되는 피사체와 움직임을 정확하게 지정할 수 있는 방법에 대한 저자들의 관심을 불러일으켰다.
동영상은 컨텐츠와 모션 컴포넌트의 조합으로 볼 수 있다는 점을 고려하여 레퍼런스 이미지를 동영상의 시작 프레임으로 사용하여 컨텐츠를 지정하고 스트로크 입력의 집합으로 모션을 제어할 수 있는 인터페이스를 설계한다. 이러한 스트로크는 동영상 전체에서 전경 피사체와 카메라 조정(ex. 확대/축소 또는 시점 이동)의 원하는 동작을 묘사할 수 있다. 본 논문의 목표는 지정된 콘텐츠와 모션 정보를 충실히 반영하는 동영상 시퀀스를 합성하는 것이다.
이전 연구들은 TaiChiHD나 Human3.6M과 같은 간단한 데이터셋으로 유사한 문제에 대한 탐색 결과를 보여주지만 이러한 데이터셋은 단순하게 유지되며 합성 품질이 좋지 못하다. Diffusion model의 표현력을 활용하여 시각적 품질 문제를 해결하기 위한 시도로 시작 이미지 프레임과 스트로크 입력을 기반으로 동영상을 직접 합성하는 단일 단계 조건부 diffusion model을 구현한다. 그러나 이러한 naive한 접근 방식은 만족스럽지 못한 결과를 초래한다. 저자들은 이 실패가 다음 두 가지 측면에서 task의 까다로운 특성으로 인해 발생한다고 가정한다.
- 희박한 스트로크에 의해 나타나는 모호성
- 사실적인 동영상 합성을 위한 의미론적 이해의 요구
예를 들어, 입력 스트로크가 캐릭터의 손을 위로 움직이는 것을 나타내는 경우를 고려하자. 스트로크는 단일 픽셀에만 연결되지만 task는 손에 해당하는 모든 픽셀을 통해 전파되어야 한다. 한편, 캐릭터의 팔은 스트로크와 같은 방향과 크기로 불필요하게 일관된 움직임을 가져야 한다. 이러한 문제는 데이터셋 내의 개체, 장면 및 활동의 다양성이 증가함에 따라 훨씬 더 어려워진다. 따라서 합당한 영상을 고품질로 수렴하여 제작하는 diffusion model을 부정한다.
단일 단계 end-to-end 학습 task에서 나타나는 모호함과 어려움을 줄이기 위해 task를 두 가지 하위 문제로 나누는 2단계 프레임워크인 Motion Conditioned Diffusion Model (MCDiff)을 제시한다.
- sparse-to-dense flow completion
- 미래 프레임 예측
Flow completion task는 입력 스트로크(sparse flow에 해당)를 입력 동영상 프레임의 의미론적 의미에 따라 동영상 내의 움직임을 나타내는 dense flow로 변환하는 것을 목표로 한다. 미래 프레임 예측 모델은 현재 프레임과 예측된 dense flow를 기반으로 조건부 diffusion process를 통해 다음 동영상 프레임을 생성한다. 마지막으로 두 네트워크는 일관되고 시너지 효과가 있는 모델로 end-to-end fine-tuning된다. 2단계 모델은 학습을 안정화하고 diffusion model의 우수성을 성공적으로 활용하여 입력 스트로크로 만든 명령을 충실히 따르면서 뛰어난 시각적 품질을 달성한다.
Method
MCDiff는 두 가지 유형의 입력, 동영상 콘텐츠를 나타내는 시작 프레임 이미지 $x_0$와 모션을 제어하는 일련의 스트로크를 사용한다. 이러한 스트로크는 sparse flow \(S = \{s_{1 \rightarrow 2}, \cdots, s_{(n-1) \rightarrow n}\}\)의 집합으로 해석되며, 여기서 sparse flow $s_{i \rightarrow (i+1)}$은 timestep $i$에서 $i + 1$까지 제어된 픽셀이다. 이러한 입력을 기반으로 내용과 동작이 입력 조건을 따르는 $n$ 프레임의 동영상 \(X = \{x_1, \cdots, x_n\}\)을 합성하는 것이 목표이다.
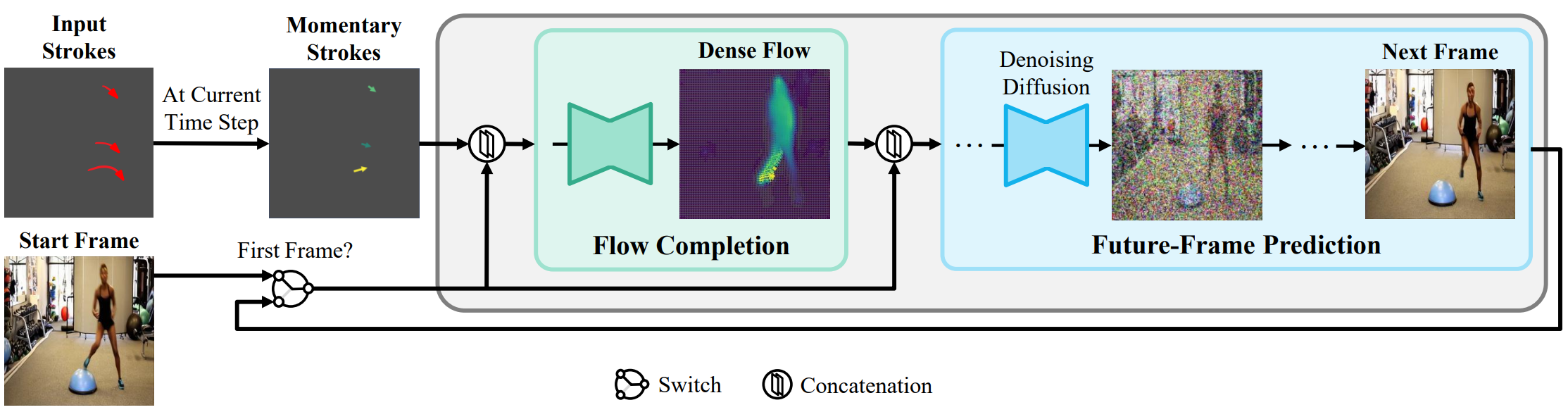
실제로 sparse flow를 입력으로 하는 조건부 diffusion model을 직접 구동하면 좋지 못한 성능을 초래한다. 이러한 관찰은 sparse flow 입력의 모호성과 어려움을 해결하기 위한 추가 모듈이 있는 2단계 프레임워크의 개발에 영감을 주었다. 구체적으로 위 그림에 나와 있는 것처럼 autoregressive 방식으로 동영상을 합성하고 flow completion $F$와 미래 프레임 예측 $G$의 두 가지 구성 요소로 동영상 프레임 합성을 수행한다. 동영상 프레임 $x_{(i+1)}$을 생성하기 위해 다음을 수행한다. 먼저 flow completion 모델을 활용하여 현재 동영상 프레임 $x_i$와 sparse flow $s_{i \rightarrow (i+1)}$을 기반으로 dense flow map $d_{i \rightarrow (i+1)}$을 예측한다. 그 후, 현재 프레임 $x_i$와 예측된 dense flow $d_{i \rightarrow (i+1)}$를 기반으로 미래 프레임 $x_{(i+1)}$을 생성하는 조건부 diffusion model을 설계한다.
1. Annotations of Video Dynamics
Flow는 동영상 역학을 표현하기 위한 직관적인 표현이다. Dense flow는 한 동영상 프레임에서 다른 동영상 프레임으로의 픽셀별 모션 방향을 표시하여 경과 시간 동안 해당 픽셀의 발생한 모션을 설명한다.
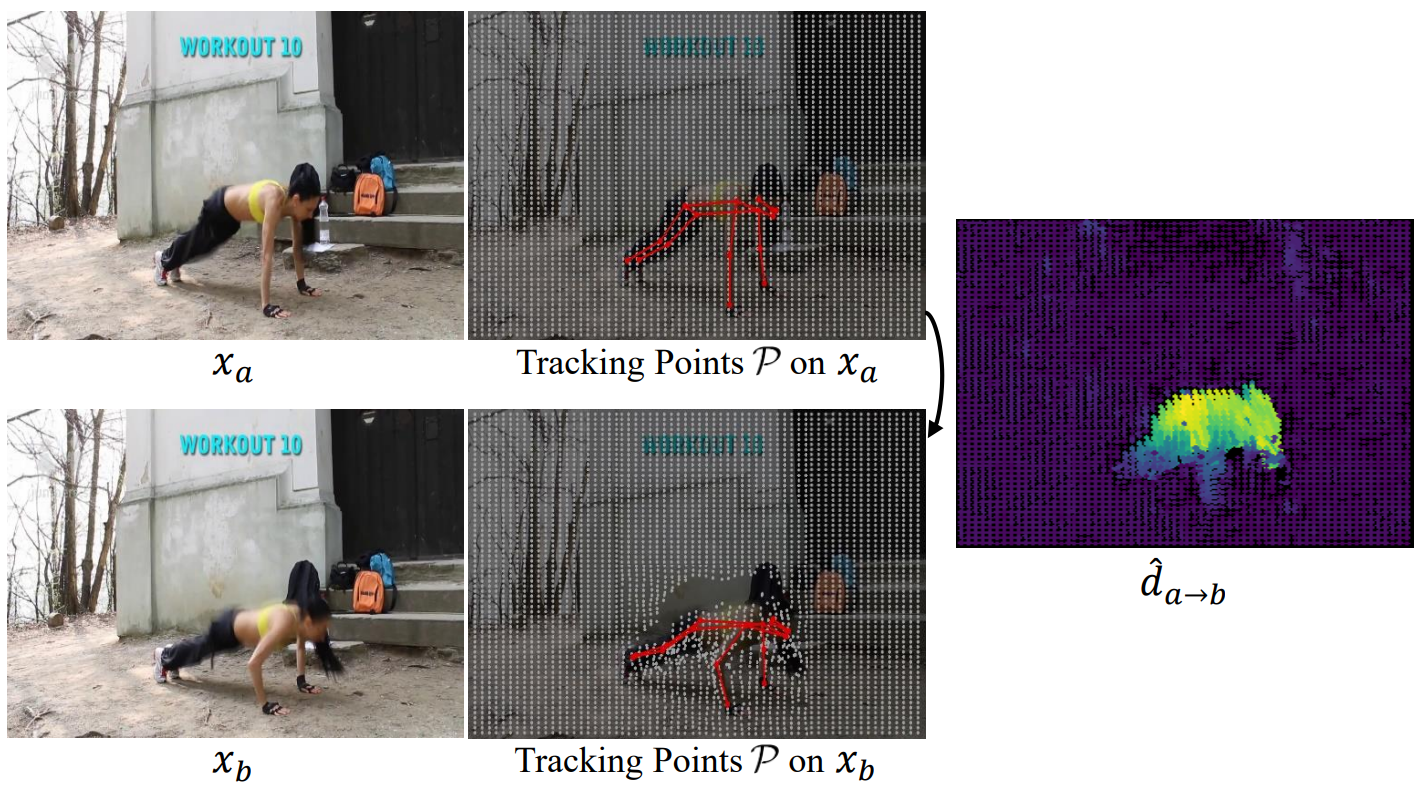
위 그림에서와 같이 동영상의 dense flow를 얻기 위해 이미지 프레임에 tracking point $P$의 배열을 분산시킨 다음 일반적인 점 및 키포인트 추적 알고리즘을 통해 동영상 전체에서 이러한 tracking point의 궤적을 검색한다. 일반 점의 궤적을 키포인트의 궤적으로 재정의하여 두 결과를 집계한다. 키포인트의 궤적은 사람 모양 prior에서 더 정확한 경향이 있기 때문이다. 결국, 동영상 전체에 조밀하게 주석이 달린 궤적을 통해 \(\hat{d}_{a \rightarrow b}\)로 표시되는 두 개의 임의 프레임 $(x_a, x_b)$ 사이에 dense flow map을 쉽게 생성할 수 있다.
2. Flow Completion Mode
현재 프레임 $x_i$와 순간적인 sparse flow $s_{i \rightarrow (i+1)}$이 주어지면 flow completion model $F$는 dense flow map $d_{i \rightarrow (i+1)}$을 예측하는 것을 목표로 한다. 먼저 sparse flow $s_{i \rightarrow (i+1)}$을 각 픽셀이 timestep $i$에서 $(i + 1)$까지의 사용자 지정 동작을 나타내는 2D 맵으로 재포맷한다. 이 연산은 flow $s_{i \rightarrow (i+1)}$의 sparsity로 인해 누락된 값이 많이 발생한다. 이러한 픽셀에 사용자 지정 모션이 없음을 나타내기 위해 공유되고 학습 가능한 임베딩으로 누락된 값을 채운다. 그런 다음 2D 맵은 UNet으로 구현되는 $F$의 입력 데이터를 형성하는 $x_i$와 concat된다.
$F$는 self-supervised 방식으로 학습된다. 즉, 학습 데이터인 각 프레임 쌍 $(x_a, x_b)$에 대해 추출된 dense flow \(\hat{d}_{a \rightarrow b}\)를 다운샘플링하여 사용자 지정 sparse flow $s_{a \rightarrow b}$를 시뮬레이션한다. Sparse flow 집합 내에서 의미 있는 동영상 역학을 더 잘 보존하기 위해 키포인트 픽셀에 해당하는 flow의 샘플링에 대한 우선 순위를 지정한다. 이는 동영상 내에서 피사체의 움직임을 나타내는 데 더 중요하기 때문이다. 또한 일반적으로 크기가 큰 flow가 더 대표적이라는 점을 고려하여 flow 크기를 샘플링 확률로 사용하여 키포인트의 flow를 샘플링한다. 한편, 카메라 조정으로 인한 다른 물체의 움직임과 배경 움직임을 나타내기 위해 일반 tracking point의 flow도 랜덤하게 샘플링한다.
시뮬레이션된 sparse flow $s_{a \rightarrow b}$를 입력으로 사용하여 \(\hat{d}_{a \rightarrow b}\)와 예측된 dense flow $d_{a \rightarrow b}$ 사이의 MSE loss로 $F$를 supervise한다. 그러나 flow 크기의 분포는 여전히 카메라가 있는 특정 장면에서 0 값에 의해 지배될 수 있다. 이러한 불균형 분포로 인해 모델은 작은 동작 생성을 선호한다. 이 불만족스러운 문제를 완화하기 위해 각 tracking point $p \in \mathcal{P}$에 대해 flow 크기에 따라 추가 픽셀당 가중치 $w_p$를 적용한다. 전반적으로 다음 목적 함수로 $F$를 학습한다.
\[\begin{aligned} L_F &= \frac{1}{\|\mathcal{P}\|} \sum_{p \in \mathcal{P}} w_p \cdot \| d_{a \rightarrow b} (p) - \hat{d}_{a \rightarrow b} (p) \|_2 \\ w_p &= \lambda + \frac{\| \hat{d}_{a \rightarrow b} (p) \|_2}{\hat{d}_\textrm{max}} \end{aligned}\]여기서 \(\hat{d}_\textrm{max}\)는 가장 큰 flow의 크기이고 $\lambda$는 픽셀의 최소 loss 가중치이다.
3. Future-Frame Prediction
다음으로 현재 프레임 $x_i$와 예측된 dense flow map $d_{i \rightarrow (i+1)}$을 기반으로 미래 프레임 $x_{(i+1)}$을 생성한다. Diffusion model의 표현력을 활용하기 위해 동영상 프레임 합성 문제를 일련의 denoising diffusion process로 공식화한다. 미래 프레임 $x_{(i+1)}$을 합성하기 위해 먼저 가우시안 분포에서 변수 $x_{i+1}^T$를 샘플링한 다음 noisy한 변수 $x_{i+1}^t$를 샘플링한 다음 UNet을 통해 $x_{(i+1)}^t$를 점진적으로 denoising한다. 현재 프레임 $x_i$와 dense flow map $d_{i \rightarrow (i+1)}$로 컨디셔닝된 denoising process를 만들기 위해 LDM을 따르고 $x_{(i+1)}^t$를 두 조건, $x_i$와 $d_{i \rightarrow (i+1)}$와 concat하여 denoising UNet의 입력 데이터를 형성한다. 마지막으로 출력 $x_{(i+1)}^0$를 예측된 미래 프레임 $x^{(i+1)}$로 가져온다.
학습 동영상 프레임 쌍 $(x_a, x_b)$으로 미래 프레임 예측 모듈 $G$를 학습하기 위해 현재 프레임 $x_a$와 추출된 dense flow map \(\hat{d}_{a \rightarrow b}\)를 입력으로 사용하고 $\epsilon$-prediction의 목적 함수에 따라 $G$를 supervise한다.
\[\begin{equation} \mathcal{L}_G = \mathbb{E}_{x_b, \epsilon \sim \mathcal{N}(0,I), t} \| \epsilon - \epsilon_\theta (x_b^t, t, x_a, \hat{d}_{a \rightarrow b}) \|_2^2 \end{equation}\]4. End-to-End Fine-Tuning
$F$와 $G$가 수렴될 때까지 개별적으로 학습된 후 전체 파이프라인을 end-to-end로 fine-tuning하여 두 모델 간의 도메인 간격을 줄이고 상호 작용을 더 잘 시너지화한다. 두 개의 모델을 연속적으로 연결하여 사용한다. 이를 위해서 $G$ 모델은 현재 프레임 $x_a$와 $F$ 모델에서 예측된 dense flow map \(\hat{d}_{a \rightarrow b}\)를 조건으로 사용한다. 이러한 방식으로 end-to-end로 연결된 미분 가능한 파이프라인 $G(x_a, F (x_a, s_{a \rightarrow b}))$을 구성한다. 다음 목적 함수를 가지고 end-to-end 방식으로 전체 파이프라인을 fine-tuning한다.
\[\begin{equation} \mathcal{L} = \lambda_F \cdot \mathcal{L}_F + \lambda_G \cdot \mathcal{L}_G \end{equation}\]Experiments
- 데이터셋: TaiChi-HD, Human3.6M, MPII Human Pose (MPII)
- Model Architecture
- $F$와 $G$ 모두 LDM-4를 사용
- 256$\times$256 크기의 동영상을 사전 학습된 VQ-4 autoencoder를 사용하여 64$\times$64 크기의 latent 변수로 인코딩
- Inference 중에 latent 변수를 다시 256$\times$256 크기로 디코딩
- Model Training
- 첫 번째 stage: 개별 학습
- 400k iteration, batch size 40
- learning rate: $F$는 $4.5 \times 10^{-6}$, $G$는 $7 \times 10^{-5}$
- $\lambda = 0.2$
- 두 번째 stage: fine-tuning
- 100k iteration, batch size 20
- learning rate: $7 \times 10^-5$
- $\lambda_F = 0.05$, $\lambda_G = 1$
- NVIDIA A100 GPU 8개로 학습
- 첫 번째 stage: 개별 학습
1. Comparisons with Prior Methods
Quantitative Evaluation
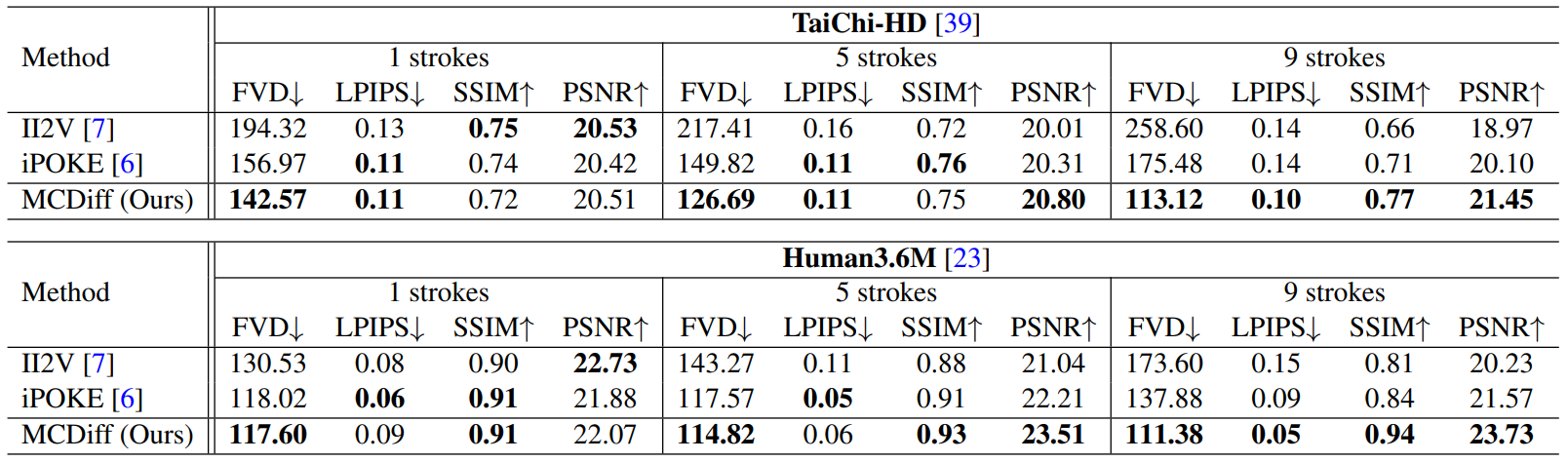
다음은 MCDiff를 이전의 다른 방법들과 비교한 표이다.
Qualitative Comparisons
다음은 MCDiff를 iPOKE와 비교한 샘플들이다.

2. Failure of Single-Stage Framework
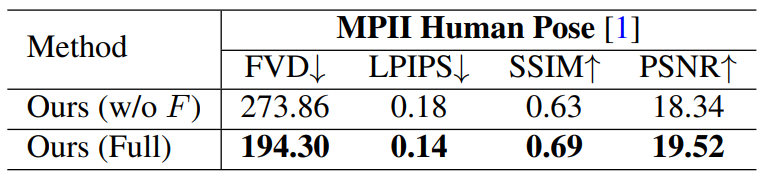
다음은 MPII Human Pose에서의 flow completion model에 대한 ablation study 결과이다.
3. Synthesis with Diverse Contents and Motions
Flow Completion Model
다음은 MPII의 테스트 동영상에서 샘플링된 동영상 프레임과 스트로크를 $F$에 입력한 결과이다.

Video Synthesis
다음은 서로 다른 유형의 콘텐츠와 모션 조건을 나타내는 5개의 샘플이다.

Limitations
- Flow completion model은 데이터 기반 방식으로 학습되기 때문에 학습 분포를 훨씬 넘어서는 편집을 수행하기 어렵다.
- 일반적인 인터넷 동영상에는 실제 motion field에 대한 특별한 감각 정보가 포함되어 있지 않기 때문에 패턴 인식 기반의 방법으로 학습 flow를 추출한다. 이러한 방법은 동영상 프레임 전체에서 이미지 패턴의 관계를 해결하도록 설계되었기 때문에 일반적으로 텍스처가 없는 표면 또는 착시가 있는 동영상에서는 실패한다. 따라서 MCDiff는 학습 데이터에서 이러한 제한 사항을 상속하며 이러한 특수한 경우에는 작동하지 않을 수 있다.