[논문리뷰] Material Magic Wand: Material-Aware Grouping of 3D Parts in Untextured Meshes
CVPR 2026. [Paper] [Page]
Umangi Jain, Vladimir Kim, Matheus Gadelha, Igor Gilitschenski, Zhiqin Chen
University of Toronto | Adobe Research
18 Mar 2026
Introduction
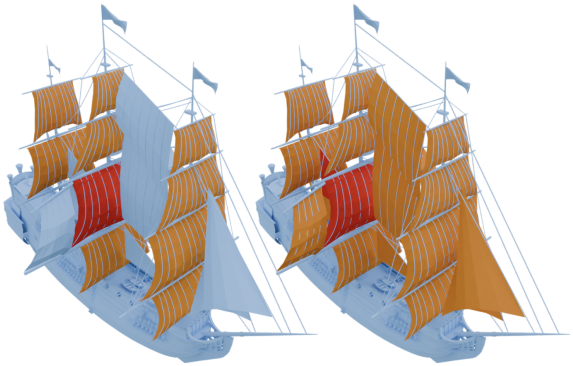
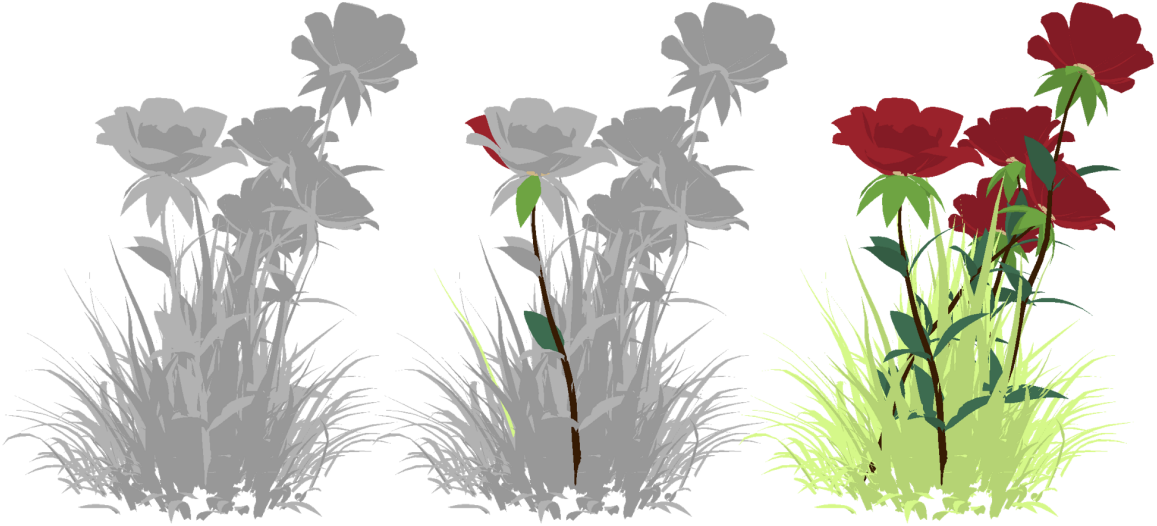
포토샵의 Magic Wand 도구처럼 Material Magic Wand는 아티스트가 하나의 part를 클릭하여 동일한 material을 공유하는 part들을 선택할 수 있도록 한다. Magic Wand의 Tolerance 파라미터가 유사성이 낮은 픽셀을 더 많이 선택할지, 아니면 유사성이 높은 픽셀을 더 적게 선택할지 균형을 맞추는 것처럼, Material Magic Wand는 Threshold 파라미터를 조정하여 신뢰도가 낮은 part를 더 많이 선택하거나 신뢰도가 높은 part를 더 적게 선택할 수 있도록 함으로써 세밀한 제어와 계층적 선택을 가능하게 한다. 이 도구는 material 할당 프로세스를 크게 가속화하여 단 한 번의 조작으로 수백 개의 part에 material을 지정할 수 있도록 한다.
본 논문의 핵심 아이디어는 각 part를 material 유사성을 인코딩하는 임베딩 공간에 임베딩하는 것이다. 이를 통해 쿼리 part의 임베딩과 유사한 임베딩을 검색하여 part들을 그룹화할 수 있다. 이러한 임베딩 공간을 도출하는 것은 쉽지 않은데, 기존의 geometric descriptor와 DINO 또는 SigLIP과 같은 최신 이미지 임베딩 모델 모두 material에 대한 이해가 부족하기 때문이다.
따라서 본 연구에서는 대규모 3D shape 데이터셋으로부터 material 임베딩을 학습하는 part encoder 모델을 설계했다. 인코더는 각 3D part에 대한 임베딩 코드를 생성하며, 입력으로는 part의 여러 이미지를 사용한다. 이 이미지들은 로컬한 geometry 특성과 전체적인 컨텍스트를 모두 포착하기 위해 특정 설정으로 렌더링되었다. 인코더는 supervised contrastive loss를 사용하여 학습되며, 동일한 material을 공유하는 part들의 임베딩을 임베딩 공간에서 서로 가깝게 배치하고, material이 다른 part들의 임베딩은 서로 분리하도록 설계되었다.
Material을 고려한 그룹화를 위한 기존의 3D 데이터셋은 없다. 하지만 저자들은 Objaverse에서 제공되는 3D shape들을 활용하여, 신뢰할 수 있는 material 주석이 포함된 약 190만 개의 part로 구성된 22,000개의 메쉬 데이터셋을 구축하여 학습에 사용하였다. 그럼에도 불구하고, material을 고려한 그룹화 과정에서는 자연스럽게 모호성이 발생하여, 장면을 해석하는 방식에 따라 part들이 다양한 방식으로 그룹화될 수 있다. 이러한 모호성으로 인한 오류를 줄이기 위해, 본 논문에서는 100개의 shape으로 구성된 벤치마크를 제안하고, 검색을 위해 241개의 part 그룹을 정의했다. 벤치마크에 포함된 shape들은 반복되지만 기하학적으로 다양한 구조를 가지고 있으며, 깨끗한 GT 데이터를 생성하기 위해 part-material 연관 관계를 수동으로 정제했다.
Method
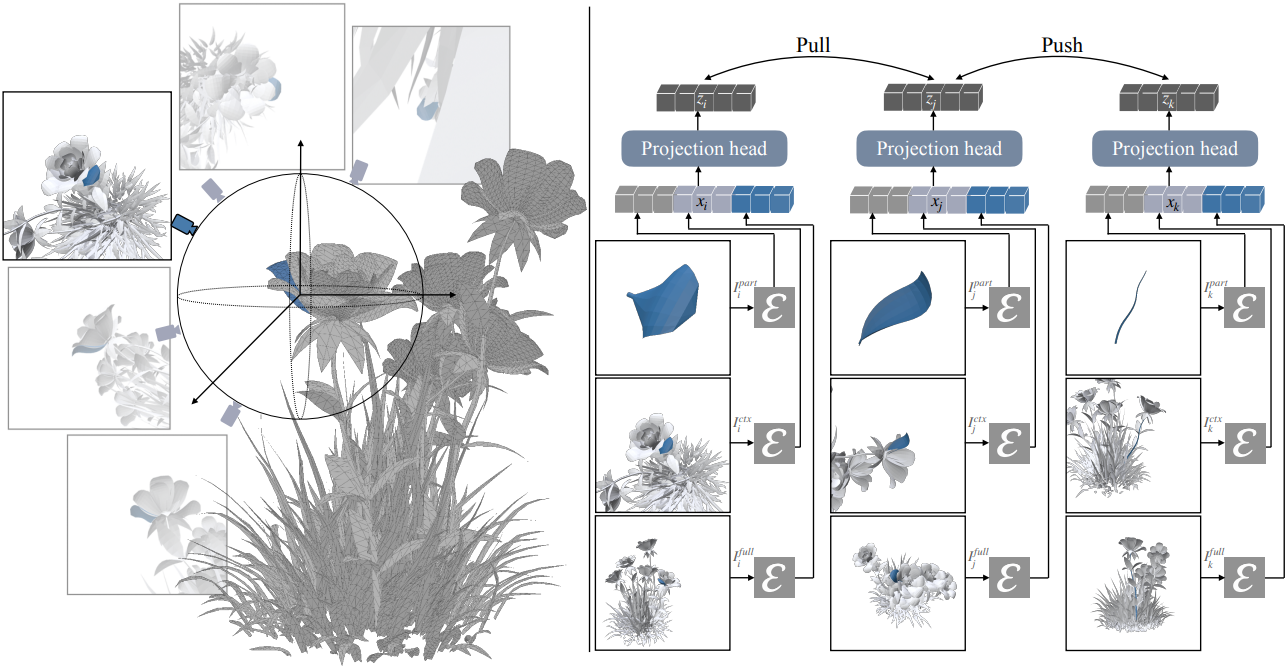
기존에 part 분할이 이루어진 텍스처가 없는 3D 메쉬가 주어졌을 때 (일반적으로 메쉬의 연결 구성 요소를 찾아 얻음), 본 방법은 각 part에 대한 material 임베딩 공간을 학습한다. 여기서 각 part는 렌더링된 뷰를 통해 인코더 네트워크에 의해 인코딩된다.
Notations
메쉬 $\mathcal{S}$가 part $p_i$로 분할되고 각 part에 material 레이블 $y_i$가 부여되었다고 가정하자. 본 논문의 목표는 각 part $p_i$를 latent 임베딩 $z_i$로 매핑하는 part encoder 네트워크를 학습하는 것이다. 이상적으로는 $z_i = z_j$는 $y_i = y_j$일 때만 성립한다. Part $p_i$에 대해, positive 집합을
\[\begin{equation} P_i = \{j \vert j \ne i, y_j = y_i\} \end{equation}\]로 정의한다. 이 집합에는 메쉬 $\mathcal{S}$에서 $p_i$와 동일한 material을 공유하는 다른 모든 part가 포함된다. 그리고 여집합을
\[\begin{equation} A_i = \{j \vert j \ne i\} \end{equation}\]로 정의한다. 이 여집합에는 메쉬 $\mathcal{S}$에서 $p_i$를 제외한 모든 part가 포함된다.
각 part $p_i$를 인코딩하기 위해, 세 가지 렌더링된 이미지 \([I_i^\textrm{part}, I_i^\textrm{ctx}, I_i^\textrm{full}]\)를 사용한다. 이 이미지들은 각각 단독 part 뷰, 컨텍스트가 있는 part 뷰, 그리고 전체 object 뷰에 해당한다.
Part Encoder
본 논문에서는 세 개의 렌더링된 이미지를 개별적으로 인코딩하기 위해 foundation vision model $\mathcal{E}$를 채택하고, backbone을 DINO-v3 small 모델로 초기화한 후 마지막 세 개의 transformer block을 fine-tuning하였다. 세 이미지의 feature를 concat하여 1152차원 임베딩 벡터 $x_i$를 얻고, projection head $f$를 사용하여 이 feature들을 latent space로 매핑하여 128차원 임베딩 $z_i$를 얻는다. Projection head는 ReLU를 사용하는 2-layer MLP이다. 최종 임베딩 $z_i$는 \(\ell_2\) 정규화된다.
\[\begin{equation} x_i = [\mathcal{E}(I_i^\textrm{part}), \mathcal{E}(I_i^\textrm{ctx}), \mathcal{E}(I_i^\textrm{full})], \quad z_i = \frac{f(x_i)}{\| f(x_i) \|_2} \end{equation}\]Training objective
같은 material로 이루어진 part는 임베딩 위치가 가깝고, 서로 다른 material로 이루어진 part는 멀리 떨어져 있기를 바란다. 따라서 임베딩 공간 학습을 위해 Supervised Contrastive Loss를 채택한다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_\mathcal{S} \mathbb{E}_i \mathbb{E}_{j \in P_i} \left( - \log \frac{\exp (z_i \cdot z_j / \tau)}{\sum_{a \in A_i} \exp (z_i \cdot z_a / \tau)} \right) \end{equation}\]($\tau$는 temperature 파라미터)
실제로 학습을 안정화하기 위해 $p_i$ 자체를 제외한 학습 batch의 모든 part를 $A_i$에 포함한다.
Inference
압축된 임베딩 $z_i$ 대신 원래의 고차원 임베딩 $x_i$를 사용하면 일관적으로 더 나은 성능을 얻을 수 있다. 따라서 3D 메쉬의 각 part $p_i$에 대해 임베딩 $x_i$를 계산한다. 두 part $p_i$와 $p_j$ 사이의 유사도를 다음과 같이 정의한다.
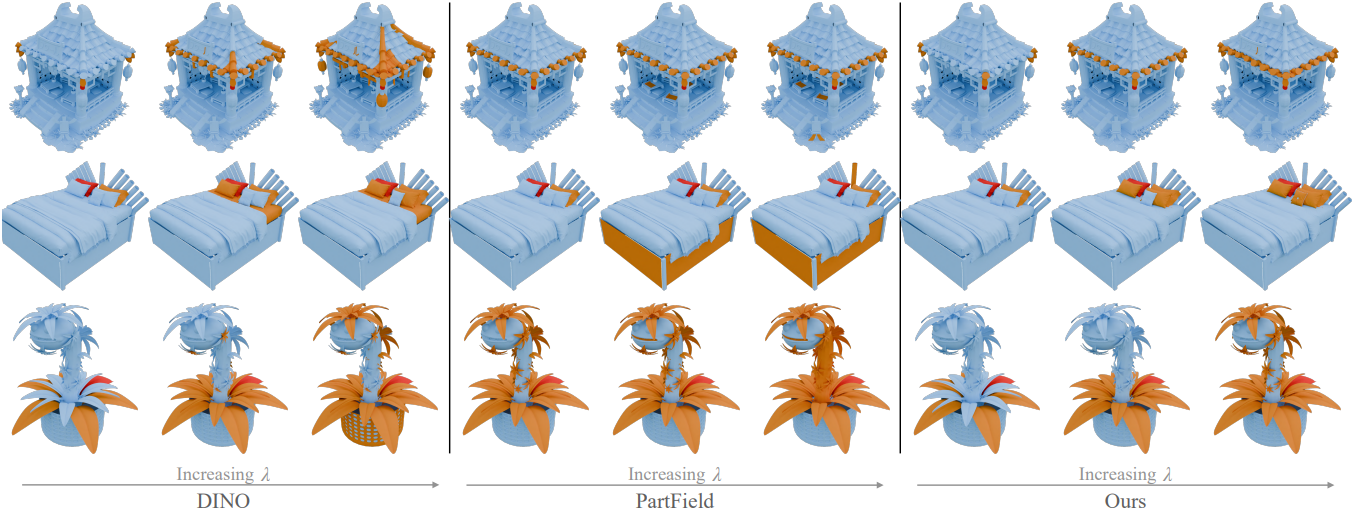
\[\begin{equation} s(p_i, p_j) = - \| x_i - x_j \|_1 \end{equation}\]그러면 쿼리 part $p_i$가 주어졌을 때, part 그룹 \(\{p_j \vert s(p_i, p_j) \le λ\}\)을 선택할 수 있다. Threshold $\lambda$가 높을수록 더 많은 part를 포함하여 그룹화가 느슨해지고, $\lambda$가 낮을수록 가장 유사한 part으로 선택 범위가 제한된다.
View selection
Part 수준 표현을 인코딩하기 위해 각 part를 단독 part, 컨텍스트가 있는 part, 전체 object에 대해 렌더링한다. 단독 part 뷰 \(I_i^\textrm{part}\)에서는 part $p_i$만 강조 표시되고 다른 part는 숨겨진다. 컨텍스트가 있는 part 뷰 \(I_i^\textrm{ctx}\)에서는 part $p_i$와 메쉬의 다른 part들을 모두 렌더링하지만, $p_i$만 강조 표시된다. 렌더링된 뷰에서 $p_i$가 이미지의 너비나 높이 중 하나의 약 25\%를 차지하도록 카메라 거리를 조정한다. 전체 object 뷰 \(I_i^\textrm{full}\)에서는 전체 메쉬를 렌더링하고 $p_i$도 강조 표시된다.
\(I_i^\textrm{ctx}\)의 경우, part를 둘러싼 반구상에서 16개의 후보 카메라 위치를 샘플링하고 렌더링된 이미지에서 part의 보이는 영역을 최대화하는 뷰를 선택한다. 만약 part가 모든 후보 시점에서 심하게 가려진다면, 카메라를 해당 part 쪽으로 확대하여 컨텍스트 영역을 축소한다. \(I_i^\textrm{part}\)의 경우, \(I_i^\textrm{ctx}\)와 동일한 시점을 사용하지만 카메라가 해당 part를 확대한다. \(I_i^\textrm{full}\)의 경우, 카메라를 object 중심에서 part 중심 방향으로 배치한다. 본 방법은 텍스처가 없는 메쉬를 대상으로 하므로 렌더링 전에 모든 material과 텍스처를 제거한다.
Part deduplication
메쉬는 본질적으로 동일하지만 크기와 방향이 다른 변환을 거친 중복된 part를 가질 수 있다. Rigid transformation에서 중복된 part를 식별하는 것은 히스토그램 매칭 알고리즘을 사용하면 비교적 쉽다. 따라서 각 메쉬에서 동일한 part를 그룹화하고, 각 그룹에서 무작위로 하나의 대표 part를 선택하여 그룹 내 모든 part에 대한 임베딩을 계산하기 위해 알고리즘을 실행한다. 이러한 중복 제거 단계는 계산 비용을 줄여준다.
Training dataset
본 논문에서는 각 part에 material ID가 부여된 대규모 3D 데이터셋을 필요로 하며, 동일한 material ID는 여러 part에서 공유되어야 한다. 따라서 Objaverse에서 material이 할당된 22,000개의 메쉬로 구성된 part 집합을 선별했다. Objaverse는 세밀한 part 분할을 제공하지 않으므로, 메쉬에서 vertex merging을 수행하여 분할된 connected component를 방지한 후 connected component를 사용하여 part를 추출한다. 각 part에는 해당 part를 구성하는 face에 대해 가장 많이 사용된 material 레이블을 선택하여 material ID를 할당한다. Material ID는 각 메쉬마다 독립적으로 정의된다.
Objaverse의 메쉬는 material 분포가 불균형한 경우가 있다. 예를 들어, material의 99%가 한 part에만 사용되거나, 하나의 material이 99%의 part에 사용되는 경우이다. 저자들은 메쉬 내 불균형과 메쉬 간 불균형을 완화하기 위해 데이터 균형 조정 전략을 적용하여 메쉬와 material ID 모두에 걸쳐 보다 균일한 분포를 얻었다.
Experiments
- 구현 디테일
- OpenGL 기반 렌더러로 데이터 생성
- 이미지 해상도: 512$\times$512
- optimizer: Adam (learning rate = $1 \times 10^{-5}$)
- batch size: 256
- steps: 20,000
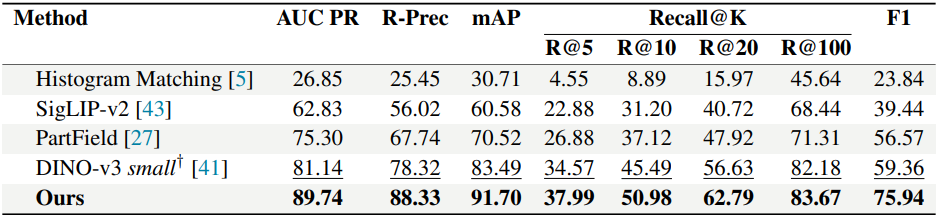
Comparison
다음은 다른 방법들과의 비교 결과이다.
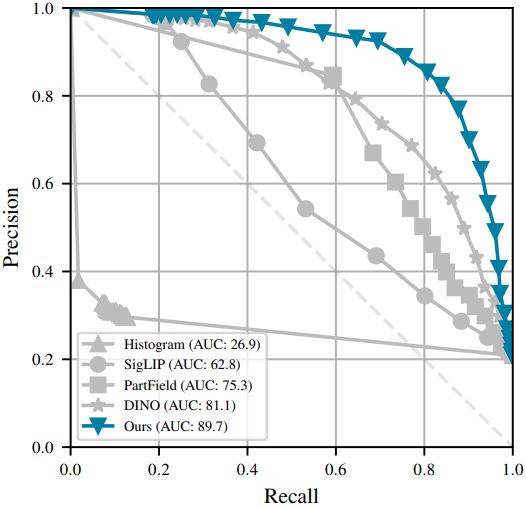
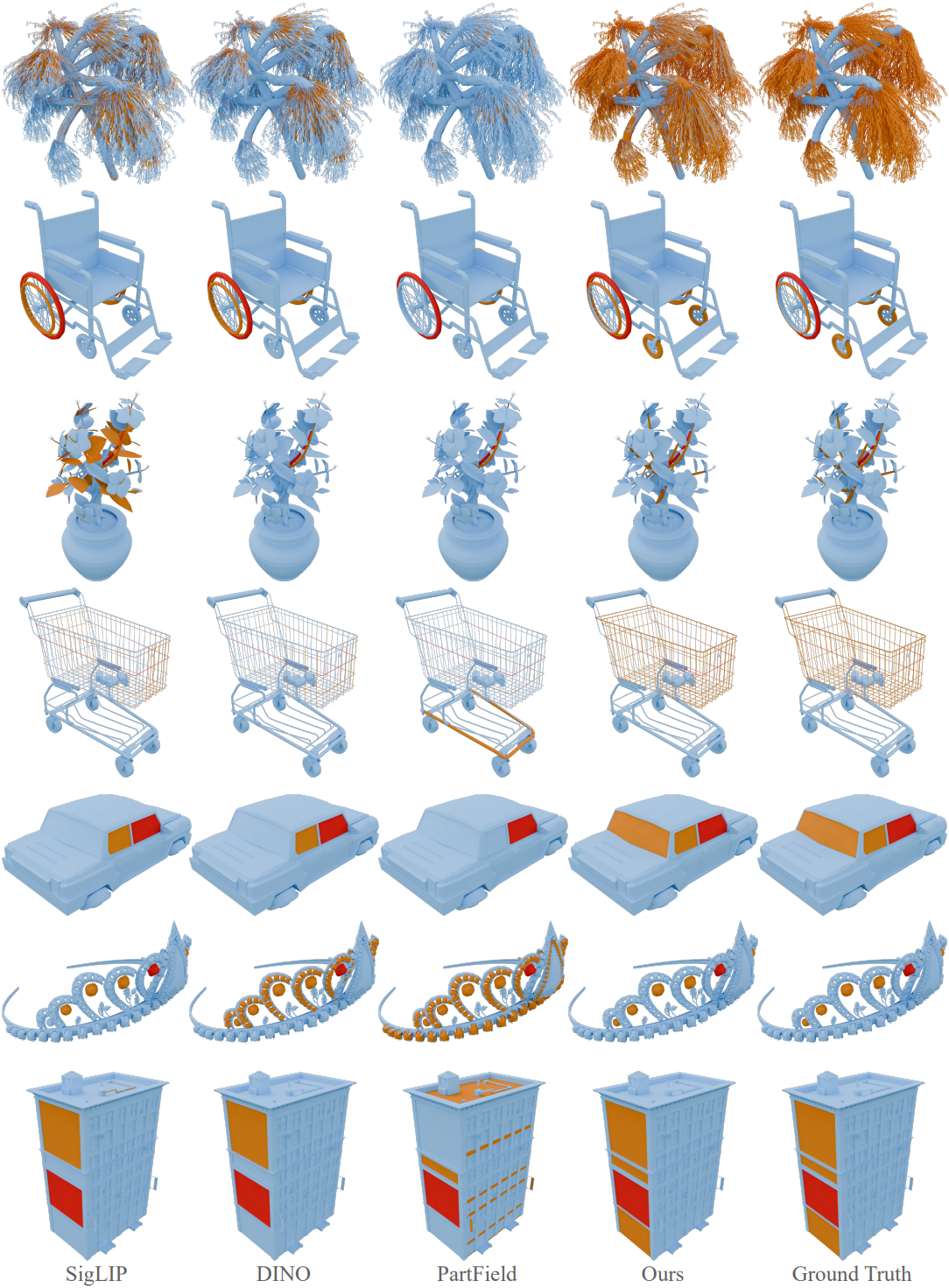
Effect of changing threshold
다음은 $\lambda$에 따른 영향을 비교한 결과이다.
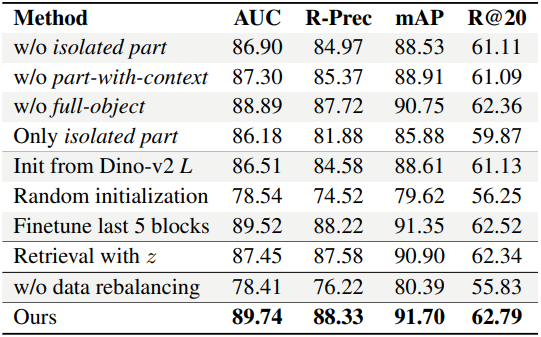
Ablation study
다음은 ablation study 결과이다.
Multiple Clicks
다음은 여러 쿼리를 선택하였을 때의 결과이다. 왼쪽은 초기 쿼리에 대한 결과이고, 오른쪽은 추가로 쿼리를 하여 나머지도 찾은 결과이다.