[논문리뷰] MaskViT: Masked Visual Pre-Training for Video Prediction
arXiv 2022. [Paper] [Page]
Agrim Gupta, Stephen Tian, Yunzhi Zhang, Jiajun Wu, Roberto Martín-Martín, Li Fei-Fei
Stanford University | Salesforce AI
23 Jun 2022
Introduction
신경과학의 증거는 인간의 인지 및 지각 능력이 미래의 사건과 감각 신호를 예상하는 예측 메커니즘에 의해 뒷받침된다는 것을 시사한다. 이러한 정신 모델은 다양한 가능한 행동 중에서 시뮬레이션, 평가 및 선택하는 데 사용할 수 있다. 이 프로세스는 생물학적 두뇌의 계산적 한계 하에서도 빠르고 정확하다. 로봇에 유사한 예측 능력을 부여하면 복잡하고 동적인 환경에서 여러 task에 대한 솔루션을 계획할 수 있다.
그러나 구현된 에이전트에 대한 시각적 관찰을 예측하는 것은 어렵고 계산이 까다롭다. 모델은 로봇의 동작을 지원하는 inference 속도를 유지하면서 미래 이벤트의 복잡성과 내재된 확률을 캡처해야 한다. 따라서 신경 구조를 구축하기 위해 transformer를 활용하고 self-supervised 생성 사전 학습을 통해 좋은 표현을 학습하는 autoregressive 생성 모델의 최근 발전은 동영상 예측이나 로봇 애플리케이션에 도움이 되지 않았다. 특히 세 가지 기술적 과제가 존재한다.
- Transformer의 전체 attention 메커니즘에 대한 메모리 요구 사항은 입력 시퀀스의 길이에 따라 2차적으로 확장되어 동영상의 경우 엄청나게 큰 비용이 든다.
- 동영상 예측 task와 autoregressive 사전 학습 사이에 불일치가 있다. 학습 프로세스는 ground truth 미래 프레임에 대한 부분 지식을 가정하지만, 테스트 시간에 모델은 처음부터 미래 프레임의 전체 시퀀스를 예측해야 한다.
- 셋째, 다른 도메인에서 효과적인 일반적인 autoregressive 패러다임은 로봇 애플리케이션에 대해 너무 느리다.
본 논문은 이러한 문제를 해결하기 위해 Masked Video Transformers (MaskViT)를 소개한다. 이는 masked visual modeling을 기반으로 하는 동영상 예측을 위한 간단하고 효과적이며 확장 가능한 방법이다. 픽셀을 프레임 토큰으로 직접 사용하려면 엄청난 양의 메모리가 필요하기 때문에 프레임을 더 작은 시각적 토큰 그리드로 압축하는 discrete variational autoencoder (dVAE)를 사용한다. 시공간 도메인 (동영상) 대신 공간 도메인 (이미지)에서의 압축을 선택한다. 각 원본 동영상 프레임과 토큰화된 동영상 프레임 간의 대응 관계를 유지하면 프레임의 모든 부분 집합에 대한 유연한 조건이 가능하기 때문이다. 그러나 토큰에서 연산함에도 불구하고 프레임당 256개 토큰에서 16개 프레임을 나타내려면 여전히 4,096개의 토큰이 필요하므로 완전한 attention을 위해서는 엄청난 메모리 요구 사항이 발생한다. 따라서 메모리를 추가로 줄이기 위해 MaskViT는 중복되지 않는 window-restricted attention이 있는 transformer layer로 구성된다.
마스킹된 사전 학습과 동영상 예측 task 사이의 불일치를 줄이고 inference 속도를 높이기 위해 다른 도메인의 생성 알고리즘에서 non-autoregressive, 반복 디코딩 방법에서 영감을 얻는다. Inference 중에 각 iteration에서 디코딩되고 보관될 토큰의 수를 지정하는 마스크 스케줄링 함수를 기반으로 동영상에 대한 새로운 반복 디코딩 방식을 제안한다. 몇 개의 초기 토큰이 여러 초기 iteration을 통해 예측되고 나머지 토큰의 대부분은 마지막 몇 번의 iteration에서 빠르게 예측될 수 있다. 이것은 첫 번째 프레임만 알려져 있고 다른 프레임에 대한 모든 토큰을 추론해야 하는 궁극적인 동영상 예측 task에 더 가까워진다. 본 논문이 제안한 예측 절차는 반복적인 non-autoregressive 특성으로 인해 시간적으로 증가하는 품질 저하 없이 빠른 예측을 제공한다. 학습-테스트 격차를 더 좁히기 위해 학습 중에 고정 마스킹 비율을 사용하는 대신 토큰의 가변 비율을 마스킹한다. 이는 실제 동영상 예측 task에서 반복 디코딩 중에 MaskViT가 마주하게 될 다양한 마스킹 비율을 시뮬레이션한다.
저자들은 여러 실제 동영상 예측 데이터셋에 대한 실험을 통해 MaskViT가 다양한 메트릭에서 경쟁적이거나 SOTA 결과를 달성한다는 것을 입증하였다. 또한 MaskViT는 이전 방법보다 훨씬 더 높은 해상도의 동영상(256$\times$256)을 예측할 수 있다. 더 중요한 것은 반복 디코딩 덕분에 MaskViT가 autoregressive 방법보다 최대 512배 더 빠르기 때문에 실제 로봇에서 계획을 세우는 데 적용할 수 있다는 것이다. 이러한 결과는 도메인별 솔루션을 엔지니어링하지 않고도 언어 및 비전에서 self-supervised 학습의 발전을 활용하여 구현된 에이전트에 강력한 예측 모델을 부여할 수 있음을 나타낸다.
MaskViT: Masked Video Transformer
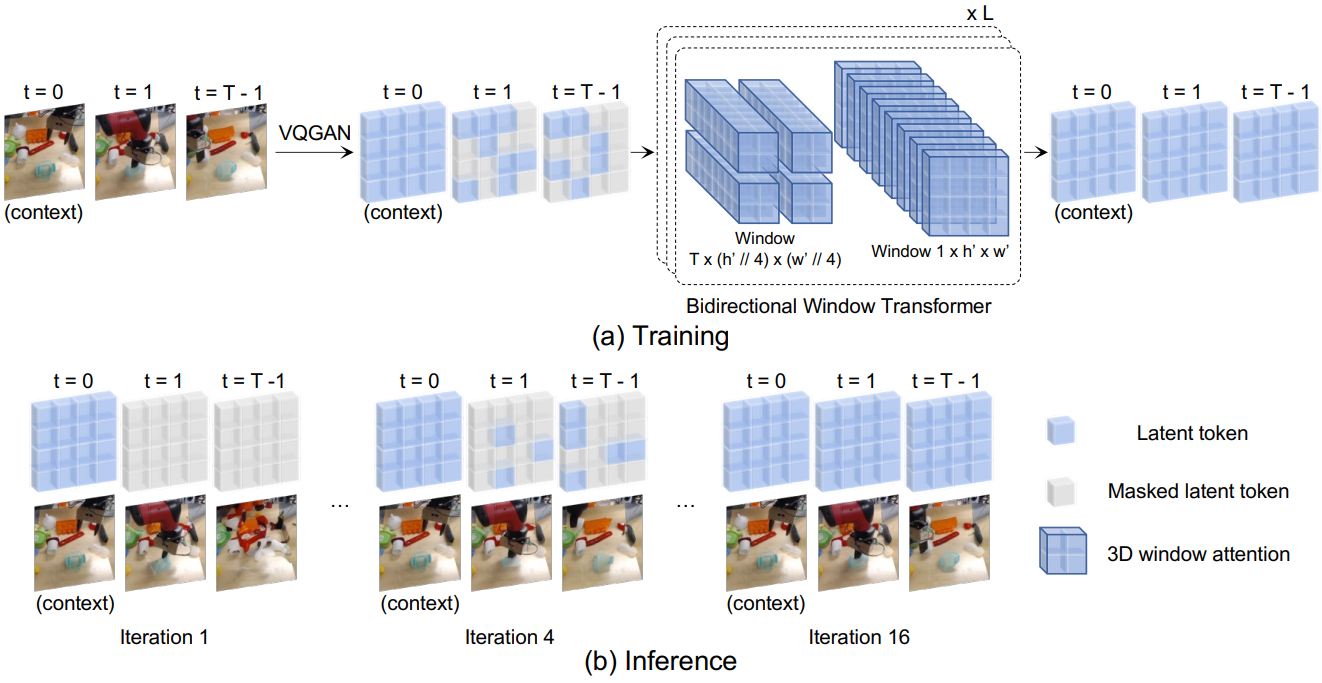
MaskViT는 2단계 학습 절차의 결과이다. 먼저 discrete variational autoencoder (dVAE)를 기반으로 이미지를 토큰으로 이산화하는 시각적 데이터의 인코딩을 학습한다. 다음으로 일반적인 autoregressive 목적 함수에서 벗어나 masked visual modeling (MVM)을 통해 window-restricted attention을 사용하여 양방향 transformer를 사전 학습한다.
1. Learning Visual Tokens
동영상에는 transformer 아키텍처에서 토큰으로 직접 사용하기에는 너무 많은 픽셀이 포함되어 있다. 따라서 차원을 줄이기 위해 먼저 개별 동영상 프레임에 대해 VQ-VAE를 학습하여 동영상을 이산 토큰의 그리드 시퀀스로 나타낼 수 있다. VQ-VAE는 입력 이미지 $x \in \mathbb{R}^{H \times W \times 3}$를 일련의 latent 벡터로 인코딩하는 인코더 $E(x)$로 구성된다. 벡터는 quantize된 임베딩의 코드북 \(\mathcal{Z} = \{z_k\}_{k=1}^K \subset \mathbb{R}^{n_z}\)에서 nearest neighbour 조회를 통해 이산화된다. 디코더 $D$는 quantize된 인코딩에서 이미지 $\hat{x}$의 재구성을 예측하도록 학습된다. 본 논문에서는 VQ-VAE를 개선하여 adversarial loss와 perceptual loss를 추가하여 VQ-GAN을 활용한다. 각 동영상 프레임은 원래 해상도에 관계없이 16$\times$16 토큰 그리드로 개별적으로 토큰화된다. 동영상의 시공간 압축을 수행하는 VQ-VAE의 3D 확장을 사용하는 대신 프레임당 압축을 사용하면 초기, 최종, 중간 프레임과 같은 임의의 컨텍스트 프레임으로 컨디셔닝할 수 있다.
2. Masked Visual Modeling (MVM)
마스킹된 언어 및 이미지 모델링의 성공에 영감을 받아 도메인 간 방법론을 통합하는 정신으로 동영상 예측을 위해 MVM을 통해 MaskViT를 사전 학습한다. 사전 학습과 마스킹 전략은 간단하다. 컨텍스트 프레임에 해당하는 latent code를 그대로 유지하고 향후 프레임에 해당하는 임의의 수의 토큰을 마스킹한다. 네트워크는 마스킹되지 않은 latent code에 따라 마스킹된 latent code를 예측하도록 학습된다.
구체적으로 $T_c$ timestep에 대한 입력 컨텍스트 프레임에 대한 액세스를 가정하고 테스트 시간 동안 $T_p$ 프레임을 예측하는 것이 목표이다. 먼저 전체 동영상 시퀀스를 latent code $Z \in \mathbb{R}^{T \times h \times w}$로 quantize된다. $Z_p = [z_i]_{i=1}^N$는 미래의 동영상 프레임에 해당하는 latent 토큰을 나타내며, 여기서 $N = T_p \times h \times w$이다. 고정된 마스킹 비율을 사용하는 MVM에 대한 이전 연구들과 달리, 사전 학습과 inference 사이의 간격을 줄여 더 나은 평가 결과를 이끌어내는 가변 마스킹 비율을 사용한다. 구체적으로 학습하는 동안 배치의 각 동영상에 대해 먼저 마스킹 비율 $r \in [0.5, 1)$ 토큰을 선택한다. 사전 학습 목적 함수는 입력으로 주어진 마스킹된 동영상의 시각적 토큰의 negative log-likelihood를 최소화하는 것이다.
\[\begin{equation} \mathcal{L}_\textrm{MVM} = \mathbb{E}_{x \in \mathcal{D}} [\sum_{\forall i \in N^M} \log p (z_i \vert Z_p^M, Z_c)] \end{equation}\]여기서 $\mathcal{D}$는 학습 데이터셋이고, $N^M$은 임의로 마스킹된 위치를 나타내고, $Z_p^M$은 $Z_p$에 마스크를 적용한 출력이고, $Z_c$는 컨텍스트 프레임에 해당하는 latent 토큰이다. MVM 목적 함수는 조건부 의존성이 양방향이므로 인과적 autoregressive 목적 함수와 다르다.
3. Bidirectional Window Transformer
전체적으로 글로벌 self-attention 모듈로 구성된 transformer 모델은 특히 동영상 task의 경우 상당한 컴퓨팅 및 메모리 비용을 발생시킨다. 보다 효율적인 모델링을 위해 두 가지 유형의 겹치지 않는 구성을 기반으로 window에서 self-attention을 계산한다.
- Spatial Window (SW): attention은 $1 \times h \times w$ 크기의 서브프레임 내의 모든 토큰으로 제한된다 (첫 번째 차원은 시간).
- Spatiotemporal Window (STW): attention은 $T \times h’ \times w’$ 크기의 3D window 내에서 제한된다.
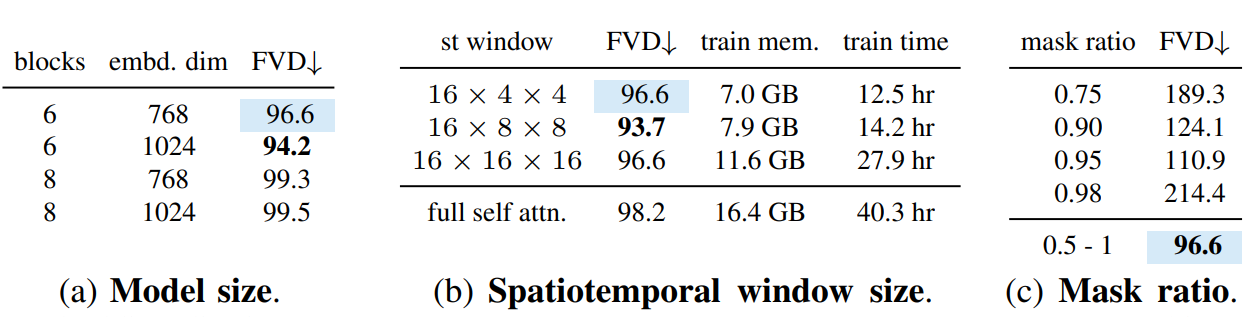
$L$번 반복하는 단일 블록에서 로컬 및 글로벌 상호 작용을 모두 얻기 위해 두 가지 유형의 window 구성을 순차적으로 쌓는다. 저자들은 놀랍게도 $h’ = w’ = 4$의 작은 window 크기가 메모리 요구 사항을 크게 줄이면서 우수한 동영상 예측 모델을 학습하기에 충분하다는 것을 발견했다. 제안된 블록은 이전 연구들과 같이 패딩이나 순환 이동이 필요하지 않고, 두 window 구성이 간단한 텐서 reshaping을 통해 인스턴스화될 수 있으므로 sparse attention을 위한 사용자 정의 CUDA 커널을 개발하지 않고도 글로벌 상호 작용 능력을 얻을 수 있다.
4. Iterative Decoding
Inference 중에 autoregressive하게 토큰을 디코딩하는 것은 프로세스가 토큰 수에 따라 선형적으로 확장되기 때문에 시간이 많이 걸리며 이는 엄청나게 클 수 있다. 예를 들어, 프레임당 256개의 토큰이 있는 16프레임 동영상의 경우 총 토큰 수가 4,096개이다. 본 논문의 동영상 예측 학습은 diffusion model의 forward diffusion process와 생성 모델의 반복 디코딩에서 영감을 얻은 새로운 반복적인 non-autoregressive 디코딩 체계를 통해 미래 동영상 프레임을 예측할 수 있다. 구체적으로, 예측할 총 토큰 수가 $N$일 때 $T \ll N$인 $T$ step으로 동영상을 예측한다.
$\gamma (t)$를 디코딩 step의 함수로 토큰에 대한 마스크 비율을 계산하는 마스크 스케줄링 함수로 두자. 여기서 \(t \in \{ \frac{0}{T}, \frac{1}{T}, \ldots, \frac{T-1}{T}\}\)이다. $t$에 대해 단조 감소하도록 $\gamma (t)$를 선택하고 $\gamma (0) \rightarrow 1$와 $\gamma (1) \rightarrow 0$을 유지하여 본 논문의 방법이 수렴되도록 한다. $t = 0$에서 $Z = [Z_c, Z_p]$로 시작한다. 여기서 $Z_p$의 모든 토큰은 [MASK] 토큰이다. 각 디코딩 iteration에서 이전에 예측된 모든 토큰을 조건으로 하는 모든 토큰을 예측한다. 다음 iteration을 위해 현재 디코딩 step에서 이전에 예측된 모든 토큰과 가장 확실한 토큰 예측을 유지하여 $n = \lceil \gamma (\frac{t}{T}) N \rceil$개의 토큰을 마스킹한다. 신뢰도 측정을 위해 softmax 확률을 사용한다.
Experimental Evaluation
- 데이터셋: RoboNet, KITTI, BAIR
- 구현 디테일
- transformer 모델은 $L$개의 블록의 스택
- 각 블록은 $1 \times 16 \times 16$ (SW)와 $T \times 4 \times 4$ (STW)의 window 크기로 attention이 제한된 두 개의 transformer layer로 구성
- 공간 및 시간 위치 임베딩의 합인 학습 가능한 위치 임베딩을 사용
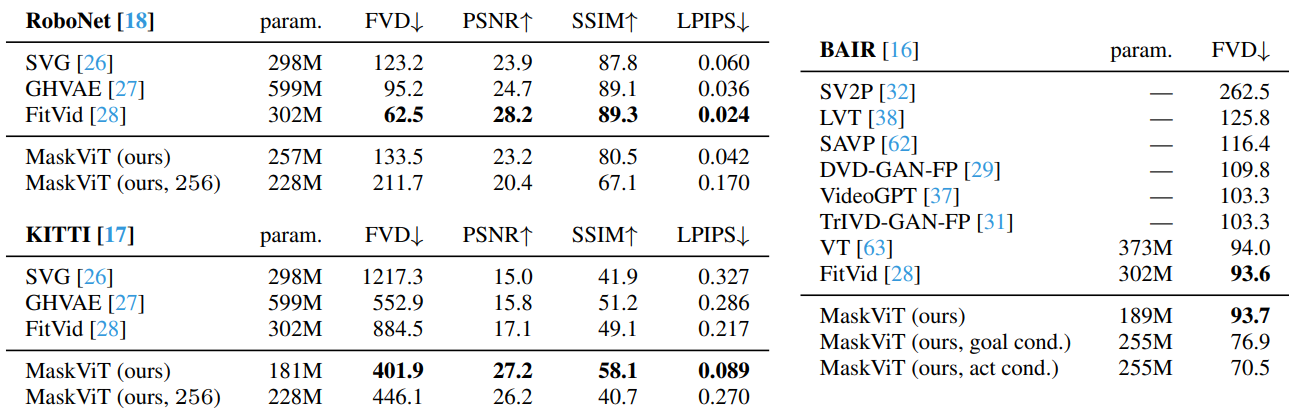
1. Comparison with Prior Work
다음은 기존 방법들과 비교한 표이다.
다음은 동영상 예측 예시이다.

2. Ablation Studies
다음은 모델 크기, 시공간적 window 크기, 마스킹 비율에 대한 ablation 결과이다.
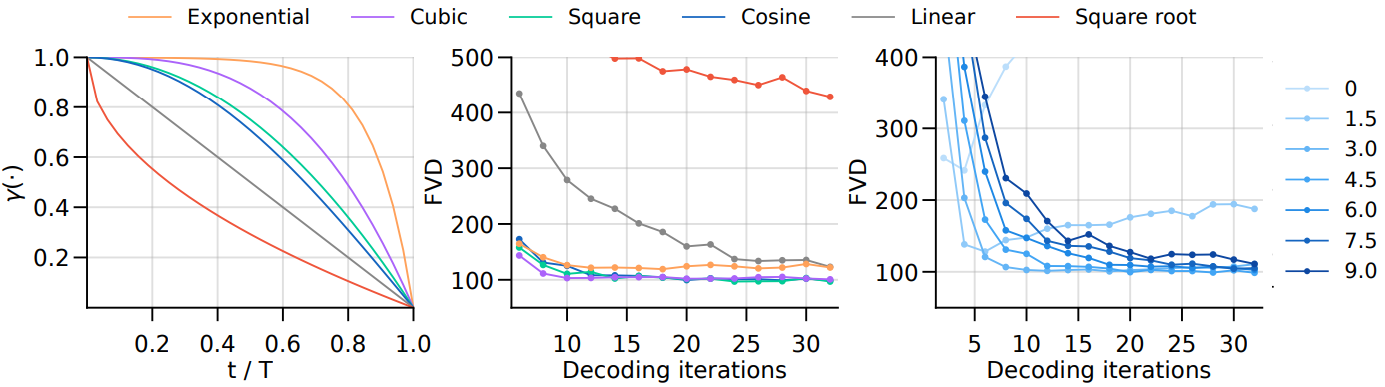
다음은 마스크 스케줄링 함수에 대한 ablation 결과이다. 왼쪽은 스케줄링 함수의 개형, 중간은 스케줄링 함수에 따른 FVD 점수, 오른쪽은 여러 temperature 값에 따른 FVD 점수이다.
다음은 forward pass 수로 autoregressive 생성과 비교한 MaskViT의 inference 속도 향상을 나타낸 표이다.

3. Visual Model Predictive Control with MaskViT on a Real Robot

저자들은 RoboNet을 보강하기 위해 설정에서 추가 fine-tuning 데이터의 12만 프레임을 자율적으로 수집하였다. 각 프레임 쌍 사이에서 로봇은 end-effector 위치 (gripper 위치 $[x, y, z]$, yaw angle $\theta$, 이진 gripper 열기/닫기 명령)의 변화를 나타내는 5차원 동작을 수행한다. 데이터를 수집하는 동안 로봇은 임의의 가정 용품의 다양한 컬렉션과 상호 작용한다.
다음은 제어 평가 결과이다.

MaskViT는 fine-tuning 데이터가 제공되었을 때 강력한 계획 성능을 달성하지만 fine-tuning 데이터를 통합하는 특정 방법은 중요하지 않다.
Limitations
- 프레임당 quantization을 사용하면 특히 RoboNet과 같은 정적 배경이 있는 동영상에서 깜박임 아티팩트가 발생할 수 있다.
- 상당한 카메라 움직임이 있는 시나리오 (ex. 자율 주행 동영상)의 경우 동영상 예측을 확장하는 것은 여전히 어려운 일이다.