[논문리뷰] MaskGIT: Masked Generative Image Transformer
CVPR 2022. [Paper] [Page] [Github]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, William T. Freeman
Google Research
8 Feb 2022

Introduction
심층 이미지 합성은 최근 몇 년 동안 많은 발전을 보였다. 현재 SOTA 결과는 GAN으로, 높은 충실도의 이미지를 빠른 속도로 합성할 수 있다. 그러나 학습 불안정성과 mode collapse 등 잘 알려진 문제로 인해 샘플 다양성이 부족하다. 이러한 문제를 해결하는 것은 여전히 미해결 연구 문제로 남아 있다.
NLP에서 Transformer와 GPT의 성공에 영감을 받은 생성적 transformer 모델은 이미지 합성에 대한 높아진 관심을 받고 있다. 일반적으로 이러한 접근 방식은 시퀀스와 같은 이미지를 모델링하고 기존 autoregressive 모델을 활용하여 이미지를 생성하는 것을 목표로 한다. 이미지는 두 단계로 생성된다. 첫 번째 단계는 이미지를 이산 토큰 (또는 시각적 단어)의 시퀀스로 quantize하는 것이다. 두 번째 단계에서는 이전에 생성된 결과(즉, autoregressive 디코딩)를 기반으로 이미지 토큰을 순차적으로 생성하도록 autoregressive 모델 (ex. transformer)을 학습한다. GAN에서 사용되는 미묘한 최소-최대 최적화와 달리 이러한 모델은 maximum likelihood estimation으로 학습된다. 디자인의 차이로 인해 기존 연구들은 안정화된 학습과 향상된 분포 커버리지 또는 다양성을 제공하는 데 있어 GAN에 비해 장점이 있음을 보여주었다.
생성적 transformer에 대한 기존 연구들은 대부분 첫 번째 단계, 즉 정보 손실이 최소화되도록 이미지를 양자화하는 방법에 중점을 두고 있으며 NLP에서 차용하여 동일한 두 번째 단계를 공유한다. 결과적으로 최신 생성적 transformer조차도 이미지를 순진하게 시퀀스로 취급한다. 여기서 이미지는 raster scan ordering에 따라 토큰의 1D 시퀀스로 flatten된다 (왼쪽에서 오른쪽으로, 위에서 아래로). 저자들은 이 표현이 이미지에 대해 최적이지도 효율적이지도 않다고 생각하였다. 텍스트와 달리 이미지는 순차적이지 않다. 작품이 어떻게 만들어지는지 상상해 보면, 화가는 스케치로 시작한 다음 세부 사항을 채우거나 조정하여 점진적으로 다듬는데, 이는 한 줄씩 인쇄하는 것과 분명한 대조를 이룬다. 또한 이미지를 플랫 시퀀스로 취급한다는 것은 autoregressive 시퀀스 길이가 2차적으로 증가하여 어떤 자연어 문장보다 더 긴 매우 긴 시퀀스를 쉽게 형성한다는 것을 의미한다. 이것은 장기적인 상관 관계를 모델링할 뿐만 아니라 디코딩을 다루기 어렵게 만드는 문제를 제기한다. 예를 들어 32$\times$32 토큰을 사용하여 GPU에서 autoregressive하게 단일 이미지를 생성하는 데 30초가 걸린다.
본 논문은 Masked Generative Image Transformer (MaskGIT)라 불리는 이미지 합성을 위한 새로운 양방향 transformer를 소개한다. 학습 중에 MaskGIT는 BERT의 마스크 예측과 유사하게 학습한다. Inference 시 MaskGIT는 새로운 non-autoregressive 디코딩 방법을 채택하여 이미지를 일정한 step으로 합성한다. 특히, 각 iteration에서 모델은 모든 토큰을 병렬로 동시에 예측하지만 가장 신뢰할 수 있는 토큰만 유지한다. 나머지 토큰은 마스킹되고 다음 iteration에서 다시 예측된다. 마스킹 비율은 몇 번의 정제 반복으로 모든 토큰이 생성될 때까지 감소한다.
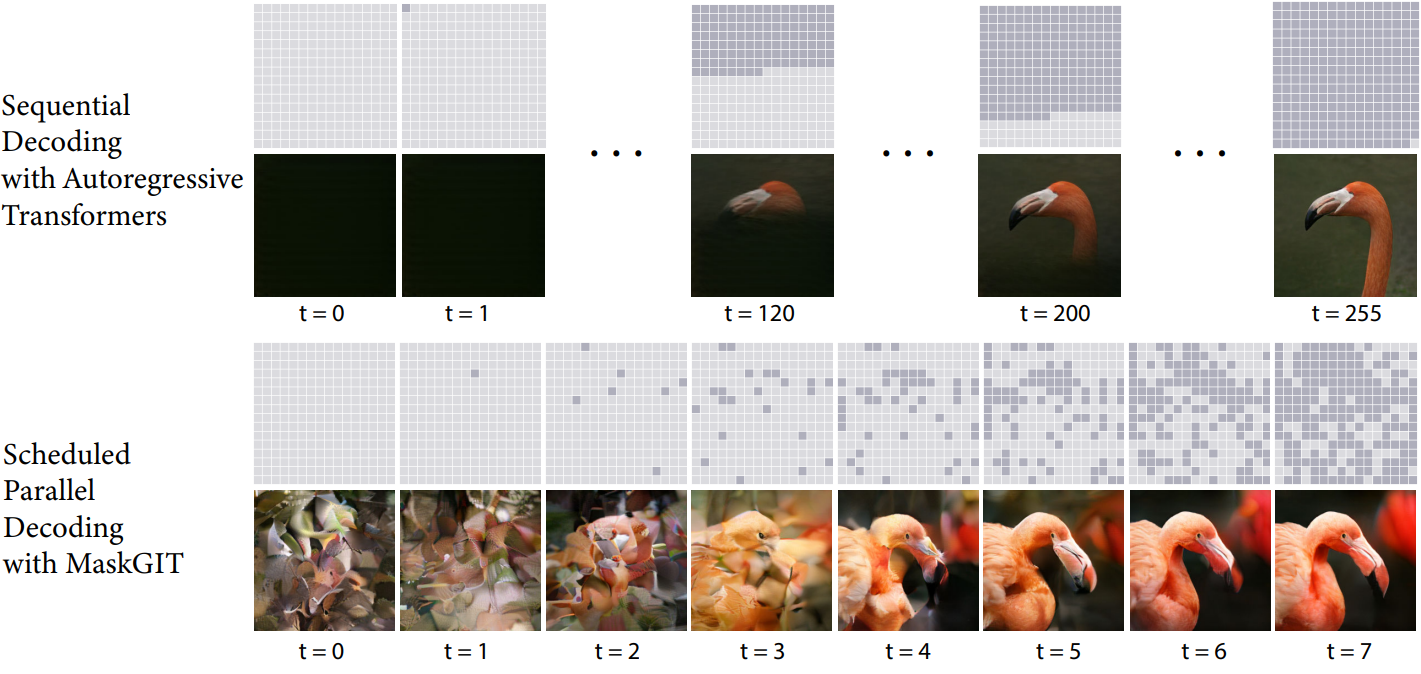
위 그림에서 볼 수 있듯이 MaskGIT의 디코딩은 이미지를 생성하는 데 256 step이 아닌 8 step만 걸리고 각 step 내 예측이 병렬화 가능하기 때문에 autoregressive 디코딩보다 훨씬 빠르다. 또한 raster scan 순서로 이전 토큰에만 컨디셔닝하는 대신 양방향 self-attention을 통해 모델이 생성된 토큰에서 모든 방향으로 새 토큰을 생성할 수 있다. 저자들은 마스크 스케줄링이 생성 품질에 상당한 영향을 미친다는 것을 발견했다.
MaskGIT은 상당히 빠르면서도 고품질의 샘플들을 생성할 수 있다. 선도적인 GAN 모델 (ex. BigGAN)이나 diffusion model (ex. ADM)과 비교해도 MaskGIT는 비슷한 샘플 품질을 제공하면서 더 유리한 다양성을 제공한다. 또한 MaskGIT의 다방향 특성으로 인해 autoregressive 모델에서는 어려운 이미지 조작 task로 쉽게 확장할 수 있다.
Method
본 논문의 목표는 병렬 디코딩과 양방향 생성을 활용하는 새로운 이미지 합성 패러다임을 설계하는 것이다.
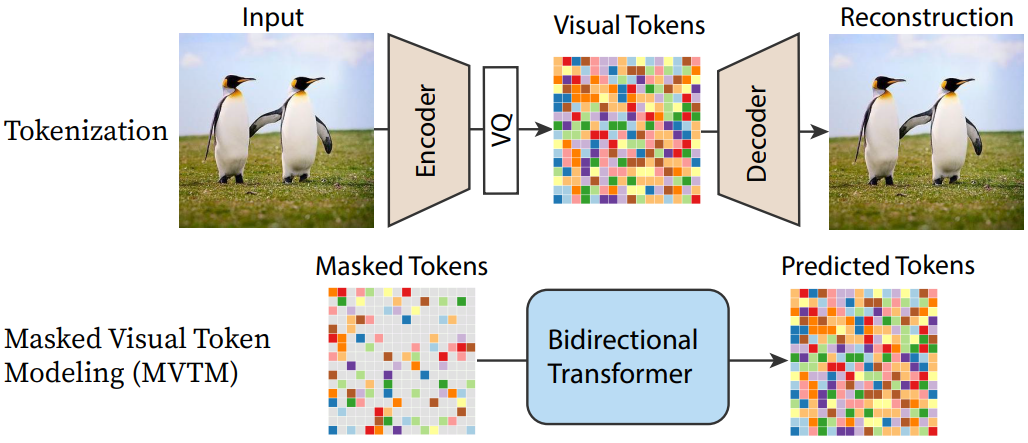
MaskGIT는 위 그림과 같이 2단계 방식을 따른다. 본 논문의 목표는 두 번째 단계를 개선하는 것이므로 첫 번째 단계에 VQGAN 모델과 동일한 설정을 사용한다. 두 번째 단계의 경우 Masked Visual Token Modeling (MVTM)에 의한 양방향 transformer 학습을 제안한다.
1. MVTM in Training
$Y = [y_i]{i=1}^N$은 이미지를 VQ 인코더에 입력하여 얻은 latent 토큰을 나타내며, 여기서 $N$은 재구성된 토큰 행렬의 길이이고 $M = [m_i]{i=1}^N$은 해당 이진 마스크이다. 학습 중에 토큰의 부분 집합을 샘플링하고 특수 토큰 [MASK]로 대체한다. 토큰 $y_i$는 $m_i = 1$이면 [MASK]로 교체되고, $m_i = 0$이면 $y_i$는 그대로 남는다.
샘플링 절차는 마스크 스케줄링 함수 $\gamma (r) \in (0, 1]$에 의해 parameterize되고 다음과 같이 실행된다. 먼저 0에서 1까지의 비율을 샘플링한 다음 $Y$에서 균일하게 $\lceil \gamma (r) \cdot N \rceil$개의 토큰을 선택하여 마스크를 배치한다. 여기서 $N$은 길이이다. 마스크 스케줄링은 이미지 생성 품질에 큰 영향을 미친다.
마스크 $M$을 $Y$에 적용한 후의 결과를 $Y_M$으로 나타낸다. 목적 함수는 마스킹된 토큰의 negative log-likelihood를 최소화하는 것이다.
\[\begin{equation} \mathcal{L}_\textrm{mask} = \mathbb{E}_{Y \in \mathcal{D}} [\sum_{\forall i \in [1, N], m_i = 1} \log p (y_i \vert Y_M)] \end{equation}\]구체적으로, 마스킹된 $Y_M$을 multi-layer 양방향 transformer에 공급하여 각 마스킹된 토큰에 대한 확률 $P (y_i \vert Y_M)$을 예측한다. 여기서 negative log-likelihood는 ground-truth one-hot 토큰과 예측된 토큰 사이의 cross-entropy를 계산한다. Autoregressive 모델링과 달리, MVTM의 조건부 의존성은 두 가지 방향이 있어 이미지 생성 시 이미지의 모든 토큰에 attend하여 더 풍부한 컨텍스트를 활용할 수 있다.
2. Iterative Decoding
Autoregressive 디코딩에서는 이전에 생성된 출력을 기반으로 토큰이 순차적으로 생성된다. 이 프로세스는 병렬화할 수 없으므로 이미지 토큰 길이 때문에 매우 느리다. 본 논문은 이미지의 모든 토큰이 병렬로 동시에 생성되는 새로운 디코딩 방법을 소개한다. 이것은 MTVM의 양방향 self-attention으로 인해 가능하다.
이론적으로 모델은 모든 토큰을 추론하고 한 번의 pass로 전체 이미지를 생성할 수 있다. 그러나 학습과의 불일치로 인해 어려움을 겪는다. Inference 시에 이미지를 생성하기 위해 모든 토큰이 가려진 빈 캔버스, 즉 $Y_M^{(0)}$에서 시작한다. Iteration $t$의 경우 알고리즘은 다음과 같이 실행된다.
- Predict: 현재 iteration에서 마스킹된 토큰 $Y_M^{(t)}$이 주어지면 모델은 마스킹된 모든 위치에 대해 병렬로 $p^{(t)} \in \mathbb{R}^{N \times K}$로 표시되는 확률을 예측한다.
- Sample: 마스킹된 각 위치 $i$에서 코드북의 모든 가능한 토큰에 대한 예측 확률 $p_i^{(t)} \in \mathbb{R}^{K}$를 기반으로 토큰 $y_i^{(t)}$를 샘플링한다. 토큰 $y_i^{(t)}$가 샘플링된 후 해당 예측 점수는 이 예측에 대한 모델의 믿음을 나타내는 “신뢰도” 점수로 사용된다. $Y_M^{(t)}$의 마스킹되지 않은 위치에 대해 신뢰도 점수를 1.0으로 설정한다.
- Mask Schedule: 마스크 스케줄링 함수 $\gamma$에 따라 마스킹할 토큰 수를 $n = \lceil \gamma (t/T) N \rceil$로 계산한다. 여기서 $N$은 입력 길이이고 $T$는 총 반복 횟수이다.
- Mask: $Y_M^{(t)}$에서 $n$개의 토큰을 마스킹하여 $Y_M^{(t+1)}$을 얻는다. $i$번째 토큰의 신뢰도 점수가 $c_i$일 때, iteration $t+1$에 대한 마스크 $M^{t+1}$은 다음과 같이 계산된다.
디코딩 알고리즘은 이미지를 $T$ step으로 합성한다. 각 iteration에서 모델은 모든 토큰을 동시에 예측하지만 가장 확실한 토큰만 유지한다. 나머지 토큰은 마스킹되고 다음 iteration에서 다시 예측된다. $T$ iteration에서 모든 토큰이 생성될 때까지 마스킹 비율이 감소한다. 실제로 마스킹 토큰은 더 많은 다양성을 장려하기 위해 temperature 어닐링으로 랜덤하게 샘플링된다.
3. Masking Design
저자들은 이미지 생성의 품질이 마스킹 디자인에 크게 영향을 받는다는 것을 발견했다. 주어진 latent 토큰에 대한 마스킹 비율을 계산하는 마스크 스케줄링 함수 $\gamma$로 마스킹 절차를 모델링한다. 함수 $\gamma$는 학습과 inference 모두에 사용된다. Inference 동안 디코딩 진행률을 나타내는 $0/T, 1/T, \cdots, (T-1)/T$의 입력을 받는다. 학습에서 다양한 디코딩 시나리오를 시뮬레이션하기 위해 $[0, 1)$에서 비율 $r$을 무작위로 샘플링한다.
BERT는 15%의 고정 마스크 비율을 사용한다. 즉, 항상 토큰의 15%를 마스킹한다. 이는 디코더가 처음부터 이미지를 생성해야 하기 때문에 MaskGIT에 적합하지 않다. 따라서 새로운 마스킹 스케줄링이 필요하다. 마스크 스케줄링 함수의 속성은 다음과 같다.
- $\gamma (r)$은 $r \in [0, 1]$에 대해 0과 1 사이의 경계를 갖는 연속 함수여야 한다.
- $\gamma (r)$은 $r$에 대해 단조 감소해야 하며 $\gamma (0) \rightarrow 1$과 $\gamma (1) \rightarrow 0$임을 유지해야 한다.
두 번째 속성은 디코딩 알고리즘의 수렴을 보장한다.
본 논문은 일반적인 함수를 고려하고 속성을 만족하도록 간단한 변환을 수행하였으며, 다음 세 가지 그룹으로 함수를 나누었다.
- 선형 함수는 매번 동일한 양의 토큰을 마스킹하는 간단한 솔루션이다.
- 오목 함수는 이미지 생성이 더 적은 정보 흐름을 따른다는 직관을 포착한다. 처음에는 대부분의 토큰이 마스킹되므로 모델은 모델이 확신할 수 있는 몇 가지 올바른 예측만 하면 된다. 끝으로 가면 마스킹 비율이 급격히 떨어지며 모델이 훨씬 더 정확한 예측을 하게 된다. 이 과정에서 효과적인 정보가 증가한다.
- 볼록 함수는 더 많은 프로세스를 구현한다. 모델은 처음 몇 번의 iteration 내에서 대부분의 토큰을 마무리해야 한다.
Experiments
- 데이터셋: ImageNet, Places2
- 구현 디테일
- 코드북 토큰 수 = 1024, 이미지를 16배로 압축
- 레이어 수 = 24, attention head 수 = 8
- 임베딩 차원 = 768, hidden 차원 = 3072
- 학습 가능한 positional embedding, LayerNorm, truncated normal initialization (stddev=0.02) 사용
- label smoothing = 0.1
- optimizer: Adam ($\beta_1$ = 0.9, $\beta_2$ = 0.96)
- data augmentation: RandomResizeAndCrop
- batch size: 256
- epoch: ImageNet은 300, Places2는 200
1. Class-conditional Image Synthesis
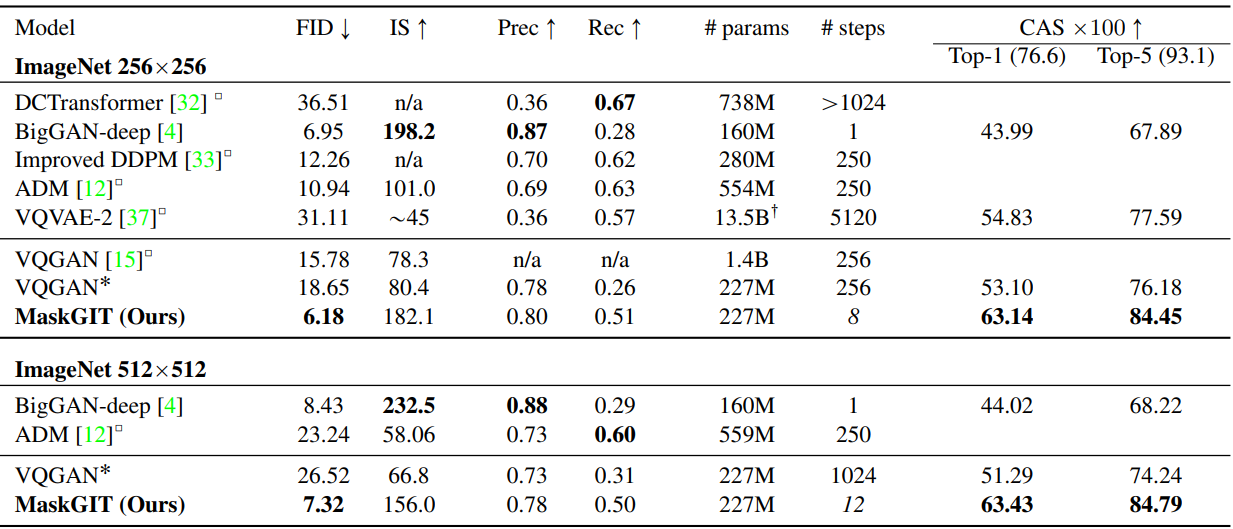
다음은 ImageNet에서 SOTA 모델들과 정량적으로 비교한 표이다.
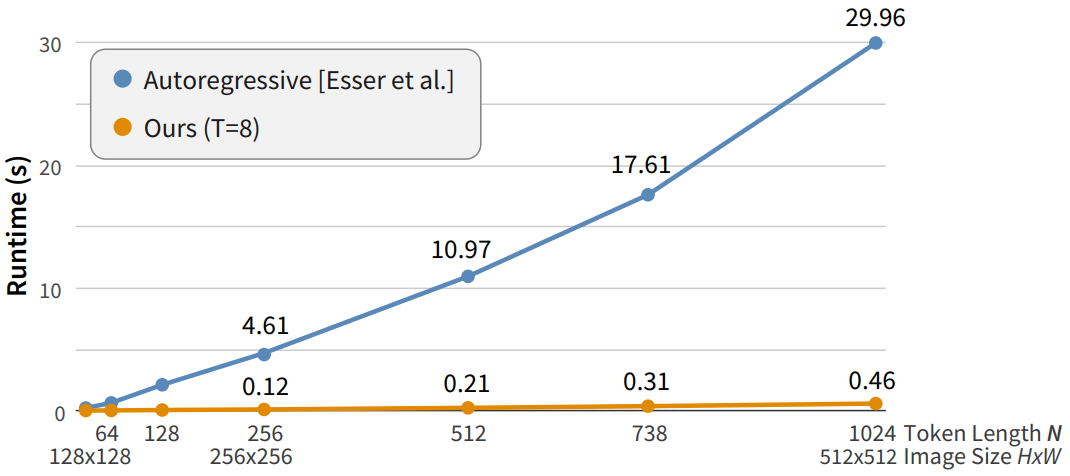
다음은 VQGAN과 MaskGIT 사이의 transformer 런타임을 비교한 그래프이다.
다음은 Image 256$\times$256에서 BigGAN-deep과 샘플 다양성을 비교한 것이다.

2. Image Editing Applications
다음은 클래스 조건부 이미지 편집 예시이다.

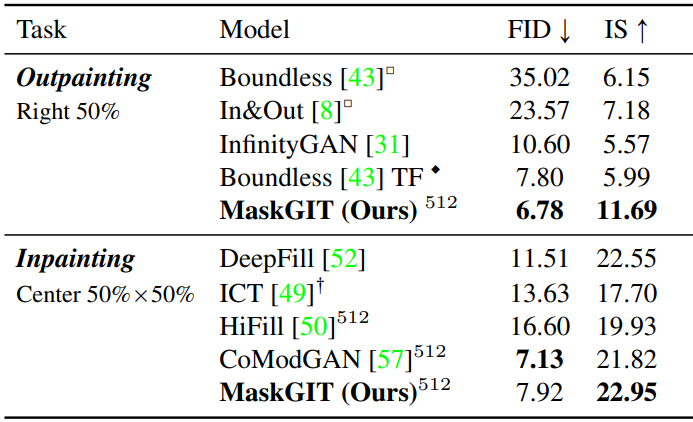
다음은 Places2에서 inpainting과 outpainting 결과를 비교한 표이다.
다음은 inpainting과 outpainting 예시이다.

3. Ablation Studies
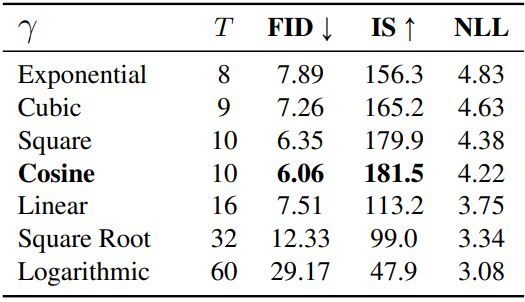
다음은 마스크 스케줄링 함수 $\gamma (t/T)$와 iteration 수 $T$의 선택에 따른 FID 변화를 나타낸 그래프이다.
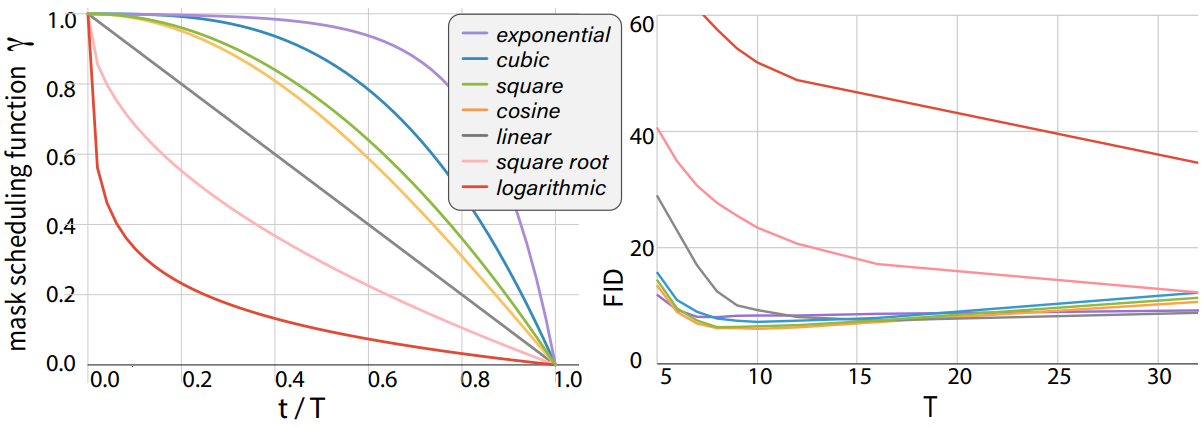
다음은 마스크 스케줄링 함수에 대한 ablation study 결과이다.