[논문리뷰] Per-Pixel Classification is Not All You Need for Semantic Segmentation (MaskFormer)
NeurIPS 2021. [Paper] [Page] [Github]
Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
Facebook AI Research (FAIR) | University of Illinois at Urbana-Champaign (UIUC)
13 Jul 2021
Introduction
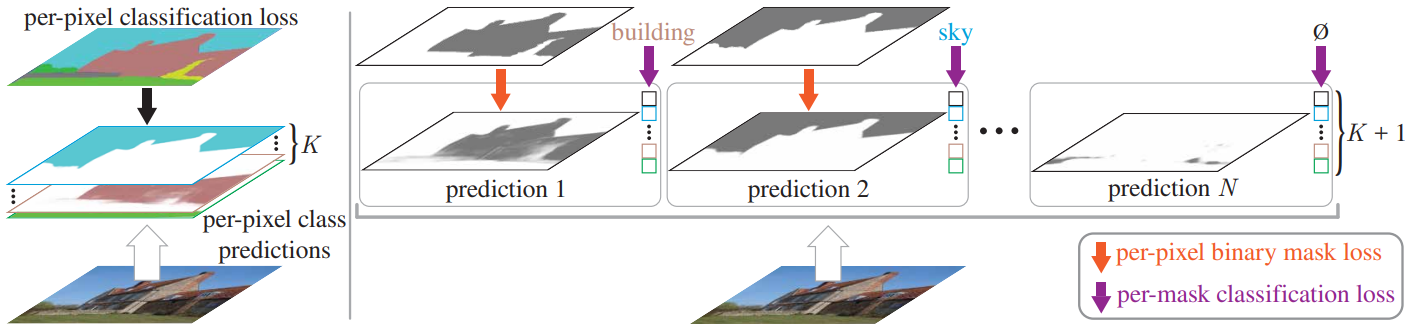
Semantic segmentation의 목표는 이미지를 다양한 semantic 카테고리를 갖는 영역으로 분할하는 것이다. Fully Convolutional Network (FCN)에서 시작하여 대부분의 딥러닝 기반 semantic segmentation 접근 방식은 semantic segmentation을 픽셀별 분류 (per-pixel classification)로 공식화하고 (위 그림의 왼쪽) 각 출력 픽셀에 classification loss를 적용한다. 이 공식의 픽셀별 예측은 자연스럽게 이미지를 다양한 클래스의 영역으로 분할한다.
마스크 분류 (mask classification)는 image segmentation과 segmentation의 분류 측면을 분리하는 대체 패러다임이다. 각 픽셀을 분류하는 대신 마스크 분류 기반 방법은 각각 단일 클래스 예측과 연관된 이진 마스크 집합을 예측한다 (위 그림의 오른쪽). 보다 유연한 마스크 분류가 instance segmentation 분야를 지배한다. Mask R-CNN과 DETR은 모두 instance segmentation과 panoptic segmentation을 위해 세그먼트당 단일 클래스 예측을 생성한다. 이와 대조적으로 픽셀별 분류는 출력의 고정 개수를 가정하며 인스턴스 레벨 task에 필요한 예측 영역/세그먼트의 가변 개수를 반환할 수 없다.
저자들의 주요 관찰은 마스크 분류가 semantic segmentation과 instance segmentation을 모두 해결하기에 충분히 일반적이라는 것이다. 실제로 FCN 이전에는 O2P나 SDS와 같은 가장 성능이 좋은 semantic segmentation 방법에서는 마스크 분류 공식을 사용했다. 이러한 관점을 고려할 때 자연스러운 질문이 떠오른다.
하나의 마스크 분류 모델이 semantic segmentation과 instance segmentation에 대한 효과적인 접근 방식을 단순화할 수 있는가?
그리고 그러한 마스크 분류 모델이 semantic segmentation을 위한 기존의 픽셀별 분류 방법보다 성능이 뛰어날 수 있는가?
두 가지 질문을 해결하기 위해 기존의 픽셀별 분류 모델을 마스크 분류로 원활하게 변환하는 간단한 MaskFormer 접근 방식을 제안한다. DETR에서 제안된 집합 예측 메커니즘을 사용하여 MaskFormer는 Transformer 디코더를 사용하여 각각 클래스 예측과 마스크 임베딩 벡터로 구성된 쌍들의 집합을 계산한다. 마스크 임베딩 벡터는 기본 fully-convolutional network에서 얻은 픽셀별 임베딩과 내적을 통해 이진 마스크 예측을 얻는 데 사용된다. 새로운 모델은 semantic segmentation과 instance segmentation을 모두 통합된 방식으로 해결한다. 즉, 모델, loss, 학습 절차를 변경할 필요가 없다. 특히, semantic segmentation과 전체 panoptic segmentation의 경우 MaskFormer는 동일한 픽셀별 이진 마스크 loss와 마스크당 단일 분류 loss로 supervise된다. 마지막으로 MaskFormer 출력을 task에 의존하는 예측 형식으로 혼합하는 간단한 inference 전략을 설계한다.
Swin-Transformer backbone을 사용한 MaskFormer는 ADE20K semantic segmentation에서 새로운 SOTA를 달성하였으며 (55.6 mIoU), 같은 backbone을 사용하는 픽셀별 분류 모델보다 2.1 mIoU가 높고 더 효율적이다 (파라미터 10% 감소, FLOPs 40% 감소). 또한 MaskFormer는 COCO panoptic segmentation에서 새로운 SOTA를 달성하였으며 (52.7 PQ), 기존 SOTA보다 1.6PQ가 높다.
From Per-Pixel to Mask Classification
1. Per-pixel classification formulation
픽셀별 분류의 경우 segmentation 모델은 $H \times W$ 이미지의 모든 픽셀에 대해 가능한 $K$개의 모든 카테고리에 대한 확률 분포를 예측하는 것을 목표로 한다.
\[\begin{equation} y = \{p_i \; \vert \; p_i \in \Delta^K\}_{i=1}^{H \cdot W} \end{equation}\]여기서 $\Delta^K$는 $K$차원 probability simplex이다. 픽셀별 분류 모델을 학습시키는 것은 간단하다. 주어진 ground truth 카테고리 레이블 \(y^\textrm{gt} = \{y_i^\textrm{gt} \vert y_i^\textrm{gt} \in \{1, \ldots, K\}_{i=1}^{H \cdot W}\}\) 모든 픽셀에 대해 픽셀별 cross-entropy loss가 일반적으로 적용된다.
\[\begin{equation} \mathcal{L}_\textrm{pixel-cls} (y, y^\textrm{gt}) = \sum_{i=1}^{H \cdot W} -\log p_i (y_i^\textrm{gt}) \end{equation}\]2. Mask classification formulation
마스크 분류는 segmentation task를 다음과 같이 나눈다.
- 이진 마스크 \(\{m_i \; \vert \; m_i \in [0, 1]^{H \times W}\}_{i=1}^N\)로 표시되는 $N$개의 영역으로 이미지를 분할/그룹화
- 각 영역을 $K$개 카테고리에 대한 일부 분포와 전체적으로 연결
세그먼트를 공동으로 그룹화하고 분류하기 위해, 즉 마스크 분류를 수행하기 위해 원하는 출력 $z$를 $N$개의 확률-마스크 쌍 집합, 즉 $z = {(p_i, m_i)}_{i=1}^N$로 정의한다. 픽셀별 클래스 확률 예측과 달리 마스크 분류의 확률 분포 $p_i \in \Delta^{K+1}$1에는 $K$개의 카테고리 레이블 외에 보조 “객체 없음” 레이블 $\varnothing$이 포함된다. $\varnothing$ 레이블은 $K$개의 카테고리에 해당하지 않는 마스크에 대해 예측된다. 마스크 분류를 사용하면 동일한 관련 클래스로 여러 마스크 예측이 가능하므로 semantic segmentation과 instance segmentation 모두에 적용할 수 있다.
마스크 분류 모델을 학습시키기 위해 예측 집합 $z$와 $N^\textrm{gt}$개의 ground truth 세그먼트
\[\begin{equation} z^\textrm{gt} = \{(c_i^\textrm{gt}, m_i^\textrm{gt}) \; \vert \; c_i^\textrm{gt} \in \{1, \ldots, K\}, m_i^\textrm{gt} \in \{0, 1\}^{H \times W}\}_{i=1}^{N^\textrm{gt}} \end{equation}\]가 필요하다. 여기서 $c_i^\textrm{gt}$는 $i$번째 ground truth 세그먼트의 ground truth 클래스이다. 예측 집합의 크기 $\vert z \vert = N$와 ground truth 집합의 크기 $\vert z^\textrm{gt} \vert = N^\textrm{gt}$는 일반적으로 다르다. $N \ge N^\textrm{gt}$라고 가정하고 일대일 매칭을 허용하기 위해 $\varnothing$로 ground truth 레이블 집합을 채운다.
Semantic segmentation의 경우 예측 개수 $N$이 카테고리 레이블 개수 $K$와 일치하면 자명한 고정 매칭이 가능하다. 이 경우 $i$번째 예측은 클래스 레이블이 $i$인 ground truth 영역에 매칭되고, 다음 영역인 경우에는 $\varnothing$로 매칭된다. 클래스 라벨 $i$는 ground truth에 존재하지 않는다. 실험에서 저자들은 이분 매칭 기반 할당이 고정 매칭보다 더 나은 결과를 보인다는 것을 발견했다. 매칭 문제에 대해 예측 $z_i$와 ground truth $z_j^\textrm{gt}$ 사이의 할당 비용을 계산하기 위해 bounding box를 사용하는 DETR과 달리 클래스 및 마스크 예측을 직접 사용한다.
\[\begin{equation} −p_i (c_j^\textrm{gt}) + \mathcal{L}_\textrm{mask} (m_i, m_j^\textrm{gt}) \end{equation}\]여기서 \(\mathcal{L}_\textrm{mask}\)는 이진 마스크 loss이다.
주어진 매칭으로 모델 파라미터를 학습하기 위해 기본 마스크 분류 loss \(\mathcal{L}_\textrm{mask-cls}\)는 각 예측 세그먼트에 대한 cross-entropy loss와 이진 마스크 loss \(\mathcal{L}_\textrm{mask}\)로 구성된다.
\[\begin{equation} \mathcal{L}_\textrm{mask-cls} (z, z^\textrm{gt}) = \sum_{j=1}^N [-\log p_{\sigma (j)} (c_j^\textrm{gt}) + \unicode{x1D7D9}_{c_j^\textrm{gt} \ne \varnothing} \mathcal{L}_\textrm{mask} (m_{\sigma (j)}, m_j^\textrm{gt})] \end{equation}\]대부분의 기존 마스크 분류 모델은 \(\mathcal{L}_\textrm{mask-cls}\) 외에 보조 loss (ex. bounding box loss, instance discrimination loss)를 사용한다. MaskFormer는 \(\mathcal{L}_\textrm{mask-cls}\)만으로 end-to-end 학습을 허용하는 간단한 마스크 분류 모델을 사용한다.
3. MaskFormer
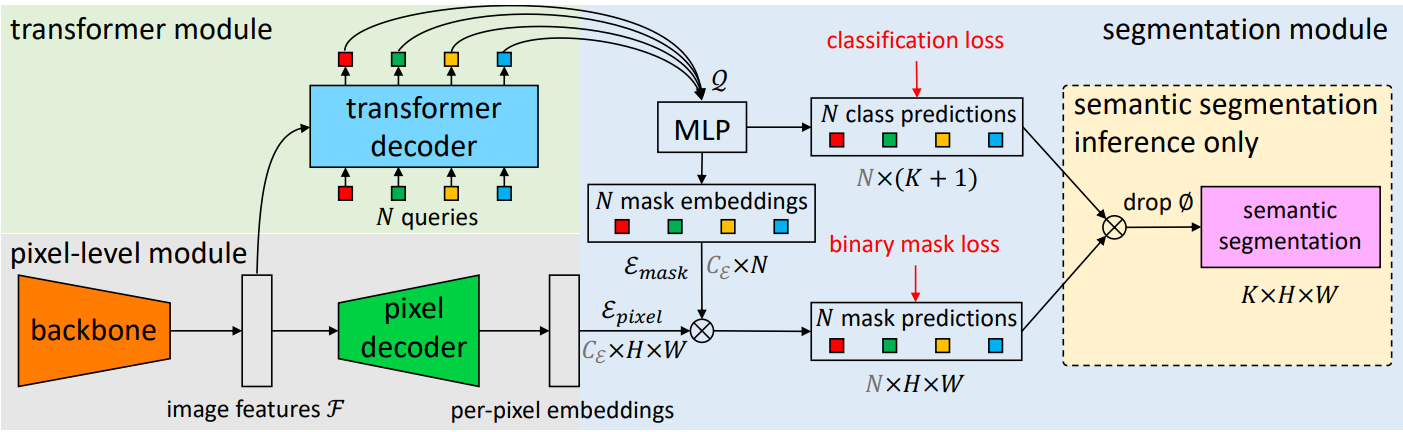
본 논문은 $N$개의 확률-마스크 쌍 \(z = \{(p_i, m_i)\}_{i=1}^N\)을 계산하는 새로운 마스크 분류 모델인 MaskFormer를 도입한다. 모델에는 세 가지 모듈이 포함되어 있다 (위 그림 참조).
- 이진 마스크 예측을 생성하는 데 사용되는 픽셀별 임베딩을 추출하는 pixel-level 모듈
- Transformer 디코더 레이어의 스택이 $N$개의 세그먼트당 임베딩을 계산하는 transformer 모듈
- 이러한 임베딩으로부터 예측 \(\{(p_i, m_i)\}_{i=1}^N\)을 생성하는 segmentation 모듈
Inference하는 동안 $p_i$와 $m_i$가 최종 예측으로 조립된다.
Pixel-level module
Pixel-level 모듈은 $H \times W$ 크기의 이미지를 입력으로 사용한다. Backbone은 저해상도 이미지 feature map \(\mathcal{F} \in \mathbb{R}^{C_\mathcal{F} \times \frac{H}{S} \times \frac{W}{S}}\)를 생성한다. 여기서 \(C_\mathcal{F}\)는 채널 수이고 $S$는 feature map의 stride이다. 그런 다음 픽셀 디코더는 점차적으로 feature를 업샘플링하여 픽셀별 임베딩 \(\mathcal{E}_\textrm{pixel} \in \mathbb{R}^{C_\mathcal{E} \times H \times W}\)를 생성한다. 여기서 $C_\mathcal{E}$는 임베딩 차원이다. 모든 픽셀별 분류 기반 segmentation 모델은 최신 Transformer 기반 모델을 포함한 pixel-level 모듈 디자인에 적합하다. MaskFormer는 이러한 모델을 마스크 분류로 원활하게 변환한다.
Transformer module
Transformer 모듈은 표준 Transformer 디코더를 사용하여 이미지 feature $\mathcal{F}$와 $N$개의 학습 가능한 위치 임베딩 (즉, query)으로부터 출력을 계산한다. 즉, MaskFormer가 예측한 각 세그먼트에 대한 글로벌 정보를 인코딩하는 차원 $C_\mathcal{Q}$의 $N$개의 세그먼트별 임베딩 \(\mathcal{Q} \in \mathbb{R}^{C_\mathcal{Q} \times N}\)을 출력한다. 디코더는 모든 예측을 병렬로 생성한다.
Segmentation module
Segmentation 모듈은 linear classifier를 적용한 후 세그먼트별 임베딩 $\mathcal{Q}$ 위에 softmax activation을 적용하여 각 세그먼트에 대해 클래스 확률 예측 \(\{p_i \in \Delta^{K+1}\}_{i=1}^N\)을 생성한다. 임베딩이 어떤 영역에도 해당하지 않는 경우 classifier는 $\varnothing$를 예측한다. 마스크 예측의 경우 2개의 hidden layer가 있는 MLP는 세그먼트별 임베딩 $\mathcal{Q}$를 차원 \(C_\mathcal{E}\)의 $N$개의 마스크 임베딩 \(\mathcal{E}_\textrm{mask} \in \mathbb{R}^{C_\mathcal{E} \times N}\)으로 변환한다. 마지막으로, $i$번째 마스크 임베딩과 pixel-level 모듈에 의해 계산된 픽셀별 임베딩 \(\mathcal{E}_\textrm{pixel}\) 사이의 내적을 통해 각 이진 마스크 예측 $m_i \in [0, 1]^{H \times W}$를 얻는다. 내적 뒤에는 sigmoid activation이 온다.
경험적으로 저자들은 softmax activation을 사용하여 마스크 예측이 서로 상호 배타적이 되도록 강제하지 않는 것이 유익하다는 것을 발견했다. 학습 중에 \(\mathcal{L}_\textrm{mask-cls}\) loss는 예측된 각 세그먼트에 대해 cross-entropy classification loss와 이진 마스크 loss \(\mathcal{L}_\textrm{mask}\)를 결합한다. 단순화를 위해 DETR과 동일한 \(\mathcal{L}_\textrm{mask}\)를 사용한다. 즉, focal loss와 dice loss의 선형 결합에 각각 hyperparameter \(\lambda_\textrm{focus}\)와 \(\lambda_\textrm{dice}\)를 곱한 것이다.
4. Mask-classification inference
먼저, 마스크 분류 출력 \(\{(p_i, m_i)\}_{i=1}^N\)을 panoptic segmentation 또는 semantic segmentation 출력 형식으로 변환하는 간단한 일반 inference 절차를 설명한다. 그런 다음 semantic segmentation을 위해 특별히 설계된 semantic inference를 설명한다. Inference 전략의 구체적인 선택은 task보다는 평가 지표에 크게 좌우된다.
General inference
일반 추론은
\[\begin{equation} \underset{i : c_i \ne \varnothing}{\arg \max} p_i (c_i) \cdot m_i [h, w] \end{equation}\]를 통해 각 픽셀을 $N$개의 예측-확률 마스크 쌍 중 하나에 할당하여 이미지를 세그먼트로 분할한다. 여기서 $c_i$는 각 확률-마스크 쌍 $i$에 대해 가장 가능성이 높은 클래스 레이블
\[\begin{equation} c_i = \underset{c \in \{1, \ldots, K, \varnothing\}}{\arg \max} p_i(c) \end{equation}\]이다. 직관적으로 이 절차는 가장 가능성이 높은 클래스 확률 $p_i (c_i)$와 마스크 예측 확률 $m_i$가 모두 높은 경우에만 확률-마스크 쌍 $i$에 위치의 픽셀을 할당한다. 동일한 확률-마스크 쌍 $i$에 할당된 픽셀은 각 픽셀이 $c_i$로 레이블이 지정된 세그먼트를 형성한다. Semantic segmentation의 경우 동일한 카테고리 레이블을 공유하는 세그먼트가 병합된다. 반면, instance segmentation의 경우 확률-마스크 쌍의 인덱스 $i$는 동일한 클래스의 서로 다른 인스턴스를 구별하는 데 도움이 된다. 마지막으로 panoptic segmentation에서 false positive 비율을 줄이기 위해 DETR의 전략을 따른다. 구체적으로 inference하기 전에 신뢰도가 낮은 예측을 필터링하고 다른 예측에 의해 가려진 이진 마스크 ($m_i > 0.5$)의 상당 부분이 있는 예측 세그먼트를 제거한다.
Semantic inference
Semantic inference는 semantic segmentation을 위해 특별히 설계되었으며 간단한 행렬 곱셈을 통해 수행된다. 저자들은 확률-마스크 쌍에 대한 marginalization, 즉
\[\begin{equation} \underset{c \in \{1, \ldots, K\}}{\arg \max} \sum_{i=1}^N p_i(c) \cdot m_i [h, w] \end{equation}\]가 각 픽셀을 확률에 하드 할당하는 것보다 더 나은 결과를 산출한다는 것을 경험적으로 발견했다. 일반적인 inference 전략에 사용한 마스크 쌍이다. 표준 semantic segmentation에서는 각 출력 픽셀이 레이블을 취해야 하므로 argmax에는 $\varnothing$이 포함되지 않는다. 이 전략은 픽셀당 클래스 확률 $\sum_{i=1}^N p_i(c) \cdot m_i [h, w]$를 반환한다. 그러나 저자들은 픽셀당 클래스 가능성을 직접적으로 최대화하면 성능이 저하된다는 것을 관찰했다. 이는 기울기가 모든 query에 고르게 분포되어 학습이 복잡해지기 때문이다.
Experiments
- 데이터셋
- semantic segmentation: ADE20K (150 클래스), COCO-Stuff-10K (171 클래스), Cityscapes (19 클래스), Mapillary Vistas (65 클래스)
- open-vocabulary: ADE20K-Full (874 클래스)
- panotic segmenation: COCO (80 “things” + 53 “stuff”), ADE20K-Panoptic (100 “things” + 50 “stuff”)
- semantic segmentation: ADE20K (150 클래스), COCO-Stuff-10K (171 클래스), Cityscapes (19 클래스), Mapillary Vistas (65 클래스)
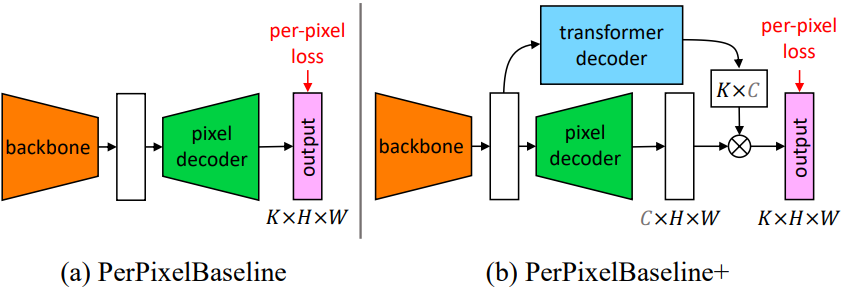
Baseline 모델로 PerPixelBaseline과 PerPixelBaseline+가 사용된다. PerPixelBaseline는 MaskFormer의 pixel-level 모듈을 사용하여 바로 픽셀별 클래스 점수를 출력한다. PerPixelBaseline+는 공정한 비교를 위해 transformer 모듈과 mask embedding MLP를 PerPixelBaseline에 추가한 것이다. 따라서 PerPixelBaseline+와 MaskFormer는 분류 방식만 픽셀별 분류와 마스크 분류로 다르다.
1. Main results
Semantic segmentation
다음은 카테고리 150개의 ADE20K val에서의 semantic segmenation 결과이다.
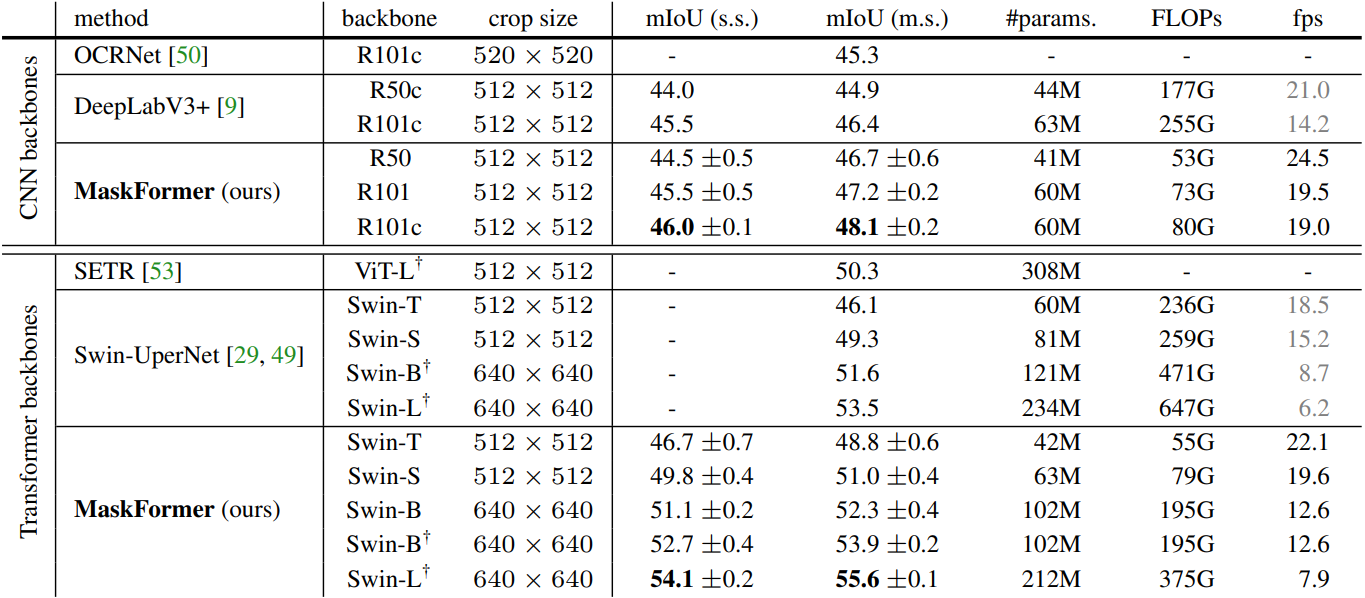
다음은 4개의 semantic segmenation 데이터셋에서 MaskFormer와 픽셀별 분류 모델들을 비교한 표이다.

Panoptic segmentation
다음은 카테고리 133개의 COCO panoptic val에서의 panoptic segmenation 결과이다.
2. Ablation studies
픽셀별 분류 vs. 마스크 분류
다음은 semantic segmentation에 대한 픽셀별 분류와 마스크 분류의 성능을 비교한 결과이다. 모든 모델들은 공정한 비교를 위해 150개의 query를 사용했으며, 카테고리 150개의 ADE20K val에서 모델들을 평가했다.
아래 표는 비슷한 고정 매칭 방식 (ex. 카테고리 인덱스로 매칭)으로 픽셀별 분류와 마스크 분류의 성능을 비교한 표이다.
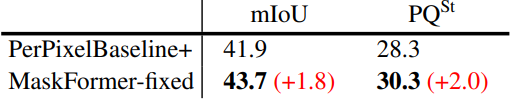
아래 표는 MaskFormer에 고정 매칭과 이분 매칭을 적용한 결과를 비교한 표이다.
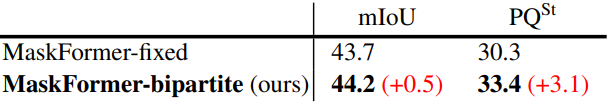
Query의 개수
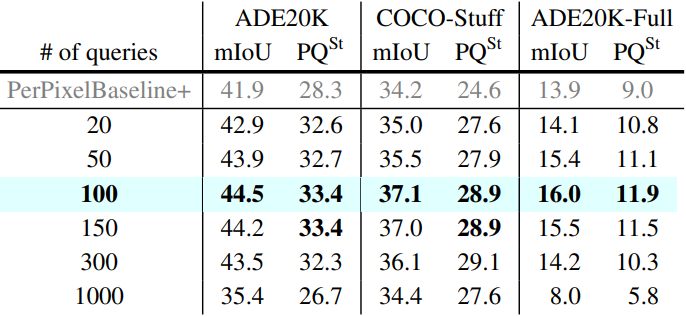
다음은 학습할 때 사용한 query의 개수에 따른 MaskFormer의 성능을 비교한 표이다.
다음은 각 데이터셋에 대한 MaskFormer의 각 queury에 의해 예측된 고유 카테고리 수를 내림차순으로 정렬한 그래프이다.
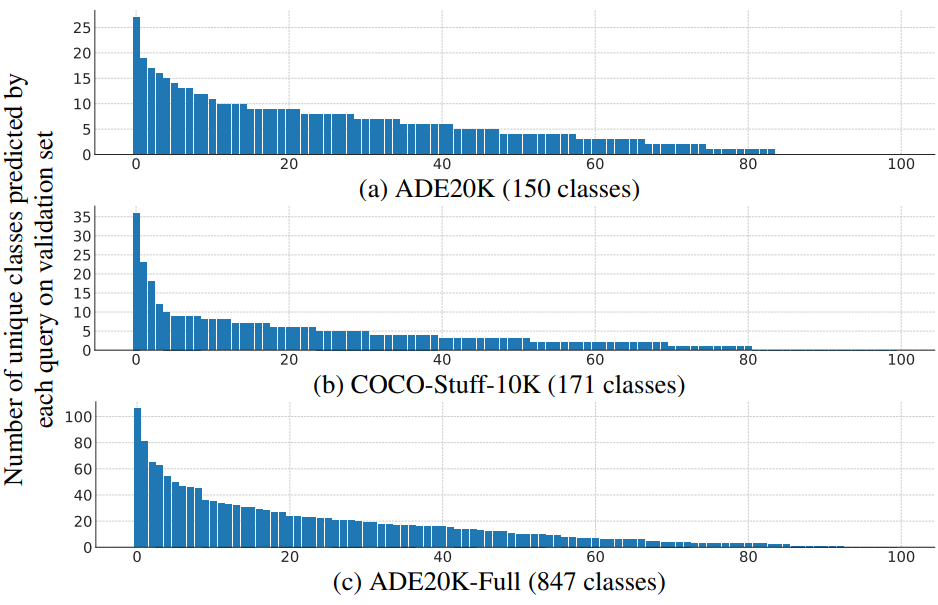
흥미롭게도 query당 고유 카테고리 수는 균일한 분포를 따르지 않는다. 일부 query는 다른 query보다 더 많은 클래스를 캡처한다.
Discussion
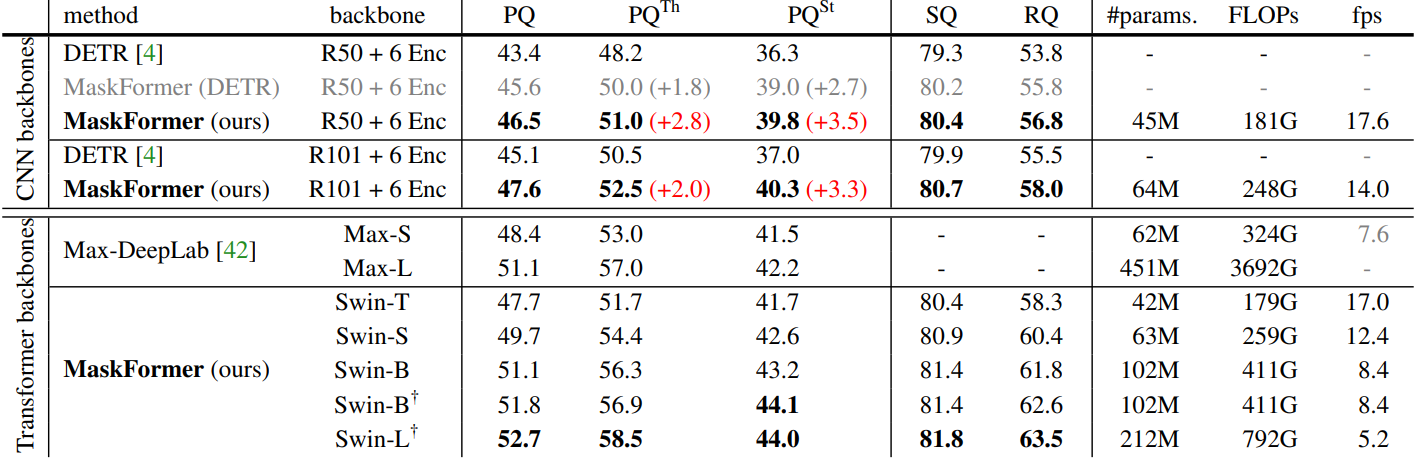
다음은 박스 기반 매칭을 사용하는 DETR을 각각 박스와 마스크 기반 매칭으로 학습된 두 개의 MaskFormer 모델과 비교한 표이다.

마스크 기반 매칭은 박스 기반 매칭보다 좋은 성능을 보인다. 저자들은 박스와의 매칭이 마스크와의 매칭보다 더 모호하다고 가정하였다. 특히 “stuff” 영역이 종종 이미지의 넓은 영역에 퍼져 있기 때문에 완전히 다른 마스크가 유사한 박스를 가질 수 있는 “stuff” 카테고리의 경우 더욱 그렇다.
MaskFormer의 mask head는 예측 품질에 영향을 미치지 않으면서 계산량을 감소시킨다. MaskFormer에서는 먼저 이미지 feature를 업샘플링하여 고해상도 픽셀별 임베딩을 얻고 고해상도에서 이진 마스크 예측을 직접 생성한다. 업샘플링 모듈 (즉, 픽셀 디코더)의 픽셀별 임베딩은 모든 query에서 공유된다. 이와 대조적으로 DETR은 먼저 저해상도 attention map을 생성하고 각 query에 독립적인 업샘플링 모듈을 적용한다. 따라서 DETR의 mask head는 MaskFormer의 mask head보다 계산 비용이 $N$배 더 높다 (여기서 $N$은 query 수).