[논문리뷰] Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
CVPR 2023. [Paper] [Github]
Feng Li, Hao Zhang, Huaizhe xu, Shilong Liu, Lei Zhang, Lionel M. Ni, Heung-Yeung Shum
The Hong Kong University of Science and Technology | Tsinghua University | International Digital Economy Academy (IDEA)
6 Jun 2022
Introduction
Object detection과 image segmentation은 컴퓨터 비전의 기본 task이다. 두 task 모두 이미지에서 관심 개체의 위치를 파악하는 것과 관련이 있지만 집중하는 레벨이 다르다. Object detection은 관심 객체의 위치를 파악하고 bounding box와 카테고리 레이블을 예측하는 반면, image segmentation은 다양한 semantic을 픽셀 레벨로 그룹화하는 데 중점을 둔다. 더욱이, image segmentation은 instance segmentation, panoptic segmentation, 다양한 semantic에 대한 semantic segmentation을 포함한 다양한 task를 포함한다.
Object detection을 위한 Faster RCNN, instance segmentation을 위한 Mask-R-CNN, semantic segmentation을 위한 FCN과 같은 특수 아키텍처들은 각 task를 위해 개발된 convolution 기반 알고리즘에 의해 놀라운 발전이 이루어졌다. 이러한 방법은 개념적으로 간단하고 효과적이지만 전문적인 task에 맞게 조정되었으며 다른 task를 처리하는 일반화 능력이 부족하다. 다양한 task를 연결하려는 야망으로 인해 HTC, Panoptic FPN, K-net과 같은 고급 방법들이 등장했다. Task 통합은 알고리즘 개발을 단순화하는 데 도움이 될 뿐만 아니라 여러 task에서 성능 향상을 가져온다.
최근 Transformer를 기반으로 개발된 DETR-like 모델은 많은 detection 및 segmentation task에서 고무적인 진전을 이루었다. End-to-end object detector로서 DETR은 집합 예측 목적 함수를 채택하고 anchor 디자인이나 non-maximum suppression와 같은 수작업으로 만든 모듈을 제거한다. DETR은 object detection과 panoptic segmentation을 모두 처리하지만 segmentation 성능은 여전히 기존 segmentation 모델보다 열등하다. Transformer 기반 모델의 detection 및 segmentation 성능을 향상시키기 위해 연구자들은 각 task에 대한 특수 모델을 개발했다.
Object detection을 개선하려는 노력 중 DINO는 DAB-DETR의 dynamic anchor box와 DN-DETR의 query denoising 학습을 활용하고 DETR-like 모델로서 처음으로 COCO object detection 리더보드에서 SOTA를 달성하였다. 마찬가지로 image segmentation을 개선하기 위해 MaskFormer와 Mask2Former는 query 기반 Transformer 아키텍처를 사용하여 마스크 분류를 수행하는 다양한 image segmentation task를 통합할 것을 제안하였다. 이러한 방법은 다중 분할 task에서 놀라운 성능 향상을 달성했다.
그러나 Transformer 기반 모델에서는 가장 성능이 좋은 detection 및 segmentation 모델이 여전히 통합되지 않아 두 task 간의 작업과 데이터 협력이 방해된다. 그 증거로 CNN 기반 모델에서는 Mask-R-CNN과 HTC가 detection과 segmentation 간의 상호 협력을 통해 특수 모델보다 우수한 성능을 달성하는 통합 모델로 여전히 널리 인정받고 있다. 저자들은 Transformer 기반 모델의 통합 아키텍처에서 detection과 segmentation이 서로 도움이 될 수 있다고 믿지만, 단순히 segmentation에서 DINO를 사용하고 detection에 Mask2Former를 사용한 결과는 다른 task를 잘 수행할 수 없음을 나타낸다. 더욱이 multi-task 학습은 원래 task의 성능을 저하시킬 수도 있다. 이는 자연스럽게 두 가지 질문으로 이어진다.
- Transformer 기반 모델에서 detection과 segmentation이 서로 도움이 되지 않는 이유는 무엇인가?
- 전문화된 아키텍처를 대체할 통합 아키텍처를 개발하는 것이 가능한가?
이러한 문제를 해결하기 위해 본 논문은 DINO의 박스 예측 분기와 병렬로 마스크 예측 분기를 사용하여 DINO를 확장하는 Mask DINO를 제안한다. Image segmentation을 위한 다른 통합 모델에서 영감을 받아 DINO의 content query 임베딩을 재사용하여 backbone과 Transformer 인코더 feature에서 얻은 고해상도 픽셀 임베딩 맵 (입력 이미지 해상도의 1/4)에서 모든 segmentation task에 대한 마스크 분류를 수행한다. 마스크 분기는 픽셀 임베딩 맵을 사용하여 임베딩된 각 content query를 간단히 내적하여 이진 마스크를 예측한다. DINO는 영역 레벨 회귀를 위한 detection 모델이므로 픽셀 레벨용으로 설계되지 않았다. Detection과 segmentation 간의 feature를 더 잘 정렬하기 위해 segmentation 성능을 향상시키는 세 가지 주요 구성 요소도 제안하였다.
- 통합되고 향상된 query selection을 제안한다. 마스크 query를 anchor로 초기화하기 위해 최상위 토큰에서 마스크를 예측함으로써 encoder dense prior를 활용한다. 또한, 저자들은 픽셀 레벨 segmentation이 초기 단계에서 배우기 더 쉽다는 것을 관찰하고 초기 마스크를 사용하여 박스를 향상시켜 task 협력을 달성할 것을 제안한다.
- Segmentation 학습을 가속화하기 위해 마스크에 대한 통합 denoising 학습을 제안한다.
- Ground truth에서 박스와 마스크 모두 보다 정확하고 일관된 매칭을 위해 하이브리드 이분 매칭을 사용한다.
Mask DINO는 개념적으로 간단하고 DINO 프레임워크에서 구현하기 쉽다.
Mask DINO
Mask DINO는 DINO의 확장이다. Content query 임베딩 외에도 DINO에는 박스 예측과 레이블 예측을 위한 두 가지 분기가 있다. 박스는 동적으로 업데이트되어 각 Transformer 디코더의 deformable attention을 가이드하는 데 사용된다. Mask DINO는 마스크 예측을 위한 또 다른 분기를 추가하고 segmentation task에 맞게 detection의 여러 주요 구성 요소를 최소한으로 확장한다.
1. Preliminaries: DINO
DINO는 backbone, Transformer 인코더, Transformer 디코더로 구성된 DETR-like 모델이다. DAB-DETR을 따라 DINO는 DETR의 각 위치 query를 4D anchor box로 공식화하며 이는 각 디코더 레이어를 통해 동적으로 업데이트된다. DINO는 deformable attention을 가진 멀티스케일 feature를 사용한다. 따라서 업데이트된 anchor box는 sparse하고 부드러운 방식으로 deformable attention을 제한하는 데에도 사용된다. DN-DETR을 따라 DINO는 denoising 학습을 채택하고 contrastive denoising을 더욱 개발하여 학습 수렴을 가속화한다. 또한 DINO는 디코더에서 위치 query를 초기화하기 위한 혼합된 query selection 방식과 박스 기울기 역전파를 개선하기 위해 look-forward-twice 방법을 제안하였다.
2. Why a universal model has not replaced the specialized models in DETR-like models?
Transformer 기반 detector와 segmentation 모델을 통해 놀라운 발전이 이루어졌다. 예를 들어 DINO와 Mask2Former는 각각 COCO detection과 panoptic segmentation에서 SOTA 결과를 얻었다. 이러한 발전에 영감을 받아 저자들은 이러한 특수 모델을 다른 task에 대해 단순히 확장하려고 시도했지만 다른 task의 성능이 원래 모델보다 크게 뒤떨어지는 것을 발견했다. 원래 task의 성능도 저하된다. 그러나 convolution 기반 모델에서는 detection과 instance segmentation task를 결합하는 것이 효과적이고 상호 이익이 되는 것으로 나타났다. 예를 들어 Mask R-CNN head를 사용한 detection 모델은 여전히 COCO instance segmentation에서 1위를 차지하였다. 본 논문은 Transformer 기반 detection 및 segmentation을 통합하는 데 따른 문제점을 논의하기 위해 DINO와 Mask2Former를 예로 들었다.
전문화된 detection 모델과 segmentation 모델의 차이점은 무엇인가?
Image segmentation은 픽셀 레벨 분류 task인 반면 object detection은 영역 레벨 회귀 task이다. DETR 기반 모델에서는 디코더 query가 이러한 task를 담당한다. 예를 들어 Mask2Former는 이러한 디코더 query를 사용하여 고해상도 feature map을 내적하여 segmentation mask를 생성하는 반면 DINO는 이를 사용하여 박스를 회귀한다. 그러나 Mask2Former의 query는 픽셀당 유사성을 이미지 feature와 비교하기만 하면 되므로 각 인스턴스의 영역 레벨 위치를 인식하지 못할 수도 있다. 반대로 DINO의 query는 픽셀 레벨 표현을 학습하기 위해 이러한 하위 레벨 feature와 상호 작용하도록 설계되지 않았다. 대신, detection을 위해 풍부한 위치 정보와 높은 수준의 semantic을 인코딩한다.
Mask2Former가 detection을 잘 할 수 없는 이유는 무엇인가?
Mask2Former의 Transformer 디코더는 segmentation task를 위해 설계되었지만 세 가지 이유로 detection에 적합하지 않다.
- 해당 query는 조건부 DETR, Anchor DETR, DAB-DETR에서 연구된 대로 더 나은 위치 prior를 활용하지 않고 DETR의 디자인을 따른다. 예를 들어 content query는 Transformer 인코더의 feature와 의미론적으로 정렬되는 반면, 위치 query는 단일 모드 위치와 관련되지 않고 바닐라 DETR에서와 같이 학습 가능한 벡터일 뿐이다. 마스크 분기를 제거하면 최근 개선된 DETR 모델보다 성능이 떨어지는 DETR 변형으로 축소된다.
- Mask2Former는 Transformer 디코더에 마스킹된 attention을 채택한다. 이전 레이어에서 예측된 attention 마스크는 고해상도이며 attention 계산을 위한 제약 조건으로 사용된다. 박스 예측에는 효율적이지도 않고 유연하지도 않다.
- Mask2Former는 레이어별로 박스 fine-tuning을 명시적으로 수행할 수 없다. 더욱이 디코더의 대략적인 마스크 fine-tuning은 인코더의 멀티스케일 feature를 사용하지 못한다. 아래 표에서 볼 수 있듯이 마스크에서 생성된 박스 AP는 DINO보다 4.5 AP가 낮고 detection head를 추가한 multi-task 학습이 작동하지 않는다.
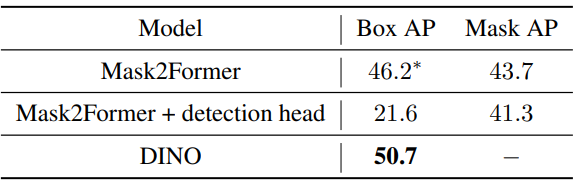
DETR/DINO가 segmentation을 잘 수행할 수 없는 이유는 무엇인가?
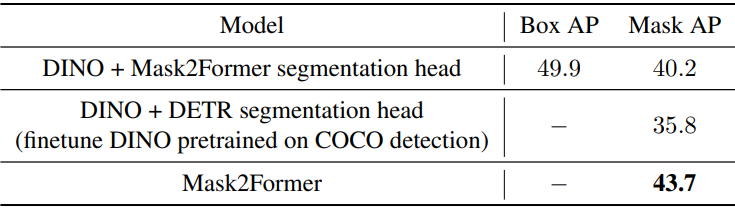
위 표에서 볼 수 있듯이 단순히 DETR의 segmentation head를 추가하거나 Mask2Former의 segmentation head를 추가하면 Mask2Former에 비해 성능이 저하된다.
단순히 DETR의 segmentation head를 추가했을 때 성능이 저하되는 이유는 DETR의 segmentation head가 최적이 아니기 때문이다. 바닐라 DETR을 사용하면 각 qeury에 가장 작은 feature map이 포함된 내적을 사용하여 attention map을 계산한 다음 업샘플링하여 마스크 예측을 얻을 수 있다. 이 디자인에는 query와 bakcbone의 더 큰 feature map 간의 상호 작용이 부족하다. 게다가 마스크 개선을 위해 마스크 보조 loss를 사용하기에는 head가 너무 무겁다.
Mask2Former의 segmentation head를 추가했을 때 성능이 저하되는 이유는 향상된 detection 모델의 feature가 segmentation과 일치하지 않기 때문이다. 예를 들어 DINO는 query 공식, denoising 학습, query selection 등의 다양한 디자인을 상속한다. 그러나 이러한 구성 요소는 detection을 위한 영역 레벨 표현을 강화하도록 설계되었으며 이는 segmentation에 적합하지 않다.
3. Our Method: Mask DINO
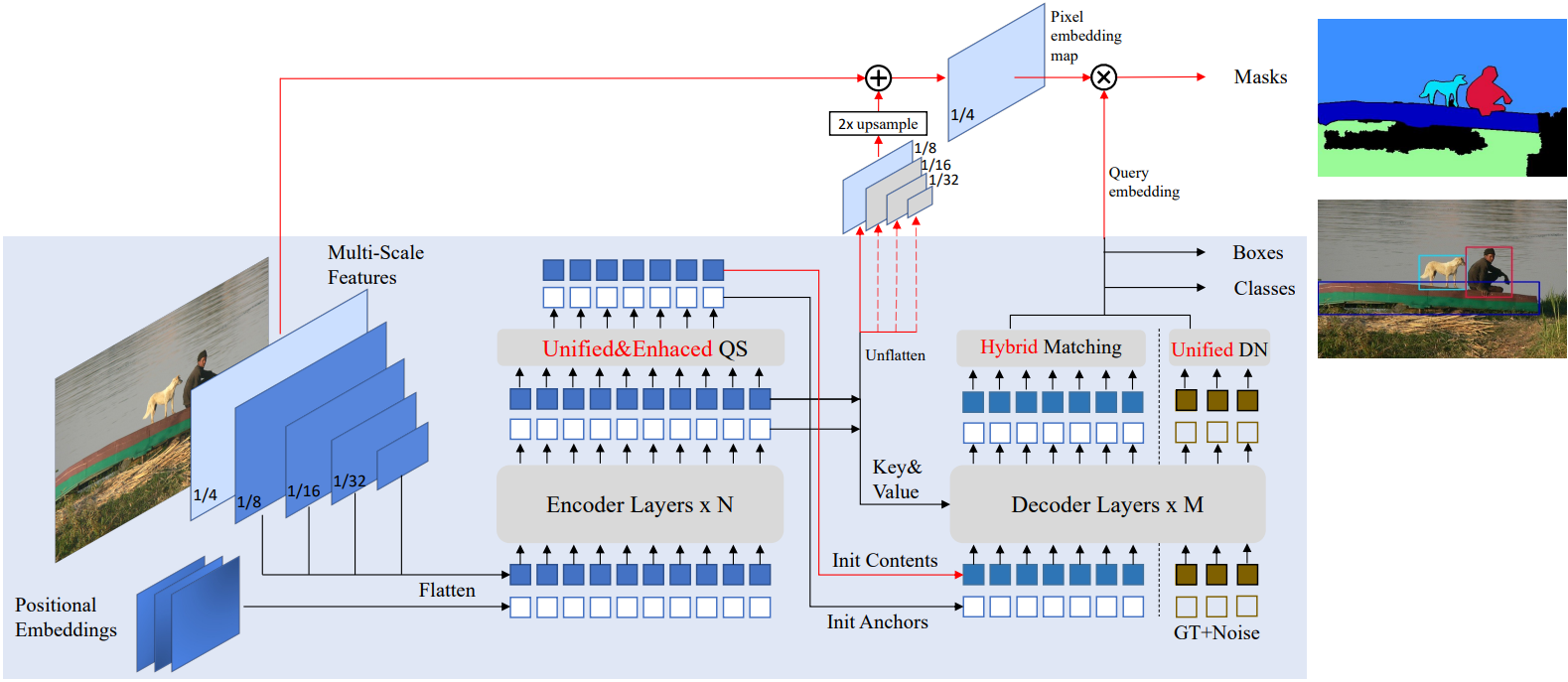
Mask DINO는 최소한의 수정만으로 DINO와 동일한 detection 아키텍처 설계를 채택한다. Transformer 디코더에서 Mask DINO는 segmentation을 위한 마스크 분기를 추가하고 segmentation task를 위해 DINO의 여러 주요 구성 요소를 확장한다. 위 그림에서와 같이 파란색으로 표시된 부분의 프레임워크는 원본 DINO 모델이며 segmentation을 위한 추가 디자인은 빨간색 선으로 표시되어 있다.
4. Segmentation branch
Image segmentation을 위한 다른 통합 모델에 따라 모든 segmentation task에 대해 마스크 분류를 수행한다. DINO는 위치 query가 anchor box로 공식화되고 content query가 박스 오프셋과 클래스를 예측하는 데 사용되므로 픽셀 레벨 정렬용으로 설계되지 않았다. 마스크 분류를 수행하기 위해 Mask2Former의 핵심 아이디어를 채택하여 backbone과 Transformer 인코더 feature에서 얻은 픽셀 임베딩 맵을 구성한다. 위 그림에 표시된 것처럼 픽셀 임베딩 맵은 backbone의 1/4 해상도 feature map $C_b$를 Transformer 인코더의 업샘플링된 1/8 해상도 feature map $C_e$와 융합하여 얻는다. 그런 다음 출력 마스크 $m$을 얻기 위해 픽셀 임베딩 맵과 디코더의 각 content query 임베딩 $q_c$를 내적한다.
\[\begin{equation} m = q_c \otimes \mathcal{M} (\mathcal{T} (C_b) + \mathcal{F} (C_e)) \end{equation}\]여기서 $\mathcal{M}$은 segmentation head이고, $\mathcal{T}$는 채널 차원을 Transformer hidden 차원에 매핑하는 convolution layer이며, $\mathcal{F}$는 $C_e$의 2배 업샘플링을 수행하는 간단한 보간 함수이다. 이 segmentation 분기는 개념적으로 간단하고 DINO 프레임워크에서 구현하기 쉽다.
5. Unified and Enhanced Query Selection
Unified query selection for mask
Query selection은 detection 성능을 향상시키기 위해 전통적인 2단계 모델과 많은 DETR-like 모델에서 널리 사용되었다. 본 논문은 segmentation task를 위해 Mask DINO의 query selection 방식을 더욱 개선했다.
인코더 출력 feature에는 디코더에 대한 더 나은 prior 역할을 할 수 있는 dense feature들이 포함되어 있다. 따라서 인코더 출력에는 세 가지 예측 head (classification, detection, segmentation)를 채택한다. 세 개의 head는 디코더 head와 동일하다. 각 토큰의 분류 점수는 최상위 feature를 선택하기 위한 신뢰도로 간주하고, 이를 content query로 디코더에 공급한다. 선택된 feature는 박스를 회귀하며, 마스크를 예측하기 위해 고해상도 feature map과 내적한다. 예측된 박스와 마스크는 ground truth에 의해 supervise되며 디코더의 초기 anchor로 간주된다. Mask DINO에서는 content query와 anchor box query를 모두 초기화하는 반면 DINO는 anchor box query만 초기화한다.
Mask-enhanced anchor box initialization
Image segmentation은 픽셀 레벨 분류 task인 반면 object detection은 영역 레벨 위치 회귀 task이다. 따라서 detection에 비해 segmentation은 세분화되어 더 어려운 task이지만 초기 단계에서 학습하기가 더 쉽다. 예를 들어, 마스크는 픽셀당 semantic 유사성만 비교하면 되는 고해상도 feature map을 사용하여 query들의 내적을 통해 예측된다. 그러나 detection을 위해서는 이미지의 박스 좌표를 직접 회귀해야 한다. 따라서 통합 query selection 후 초기 단계에서는 박스 예측보다 마스크 예측이 훨씬 정확하다. 따라서 통합 query selection 후 디코더에 대한 더 나은 anchor box 초기화로 예측 마스크에서 박스를 파생한다. 이러한 효과적인 task 협력을 통해 향상된 박스 초기화는 detection 성능을 크게 향상시킬 수 있다.
6. Segmentation Micro Design
Unified denoising for mask
Object detection의 query denoising은 수렴을 가속화하고 성능을 향상시키는 데 효과적인 것으로 나타났다. 이는 ground truth 박스와 레이블에 noise를 추가하고 이를 noise가 있는 위치 query와 content query로 Transformer 디코더에 공급한다. 모델은 noise가 있는 버전을 고려하여 실제 객체를 재구성하도록 학습되었다. 또한 이 기술을 segmentation task로 확장한다. 마스크는 박스를 좀 더 세밀하게 표현한 것이라고 볼 수 있기 때문에 박스와 마스크는 자연스럽게 연결된다. 따라서 박스를 noise가 있는 마스크로 처리하고 denoising task로 박스에 주어진 마스크를 예측하도록 모델을 학습할 수 있다. 마스크 예측을 위해 주어진 박스에는 보다 효율적인 마스크 denoising 학습을 위해 랜덤 noise가 적용된다.
Hybrid matching
Mask DINO는 일부 기존 모델과 마찬가지로 느슨하게 결합된 방식의 두 개의 평행 head로 박스와 마스크를 예측한다. 따라서 두 head는 서로 일치하지 않는 박스와 마스크 쌍을 예측할 수 있다. 이 문제를 해결하기 위해 이분 매칭의 원래 box loss와 classification loss 외에도 마스크 예측 loss를 추가하여 하나의 query에 대해 보다 정확하고 일관된 매칭 결과를 장려한다. 따라서 매칭 비용은
\[\begin{equation} \lambda_\textrm{cls} \mathcal{L}_\textrm{cls} + \lambda_\textrm{box} \mathcal{L}_\textrm{box} + \lambda_\textrm{mask} \mathcal{L}_\textrm{mask} \end{equation}\]가 된다. 여기서 \(\textrm{L}_\textrm{cls}\), \(\mathcal{L}_\textrm{box}\), \(\mathcal{L}_\textrm{mask}\)는 각각 classification loss, box loss, mask loss이고 $\lambda$는 해당 가중치이다.
Decoupled box prediction
Panoptic segmentation task의 경우 “stuff” 카테고리에 대한 박스 예측은 불필요하고 직관적으로 비효율적이다. 예를 들어, 많은 “stuff” 카테고리는 “하늘”과 같은 배경이며, ground truth 마스크에서 파생된 박스는 매우 불규칙하고 종종 전체 이미지를 덮는다. 따라서 이러한 카테고리에 대한 박스 예측은 인스턴스 수준 detection과 segmentation을 오해할 수 있다. 이 문제를 해결하기 위해 “stuff” 카테고리에 대한 box loss와 박스 매칭을 제거한다. 보다 구체적으로, 박스 예측 파이프라인은 “stuff”에 대해 동일하게 유지되어 의미 있는 영역을 찾고 deformable attention으로 feature를 추출한다. 그러나 Mask DINO에서는 “stuff” 카테고리에 대한 박스 예측 loss를 계산하지 않는다. 하이브리드 매칭에서 “stuff”에 대한 box loss는 “stuff” 카테고리의 평균으로 설정된다. 이 분리된 디자인은 학습을 가속화하고 panoptic segmentation에 대한 추가 이득을 얻을 수 있다.
Experiments
- 데이터셋: COCO, ADE20K, Cityscapes
- 학습 디테일
- batch size: 16
- backbone: ResNet-50, SwinL
- 40GB 메모리의 A100 GPU 사용
1. Main Results
Instance segmentation and object detection
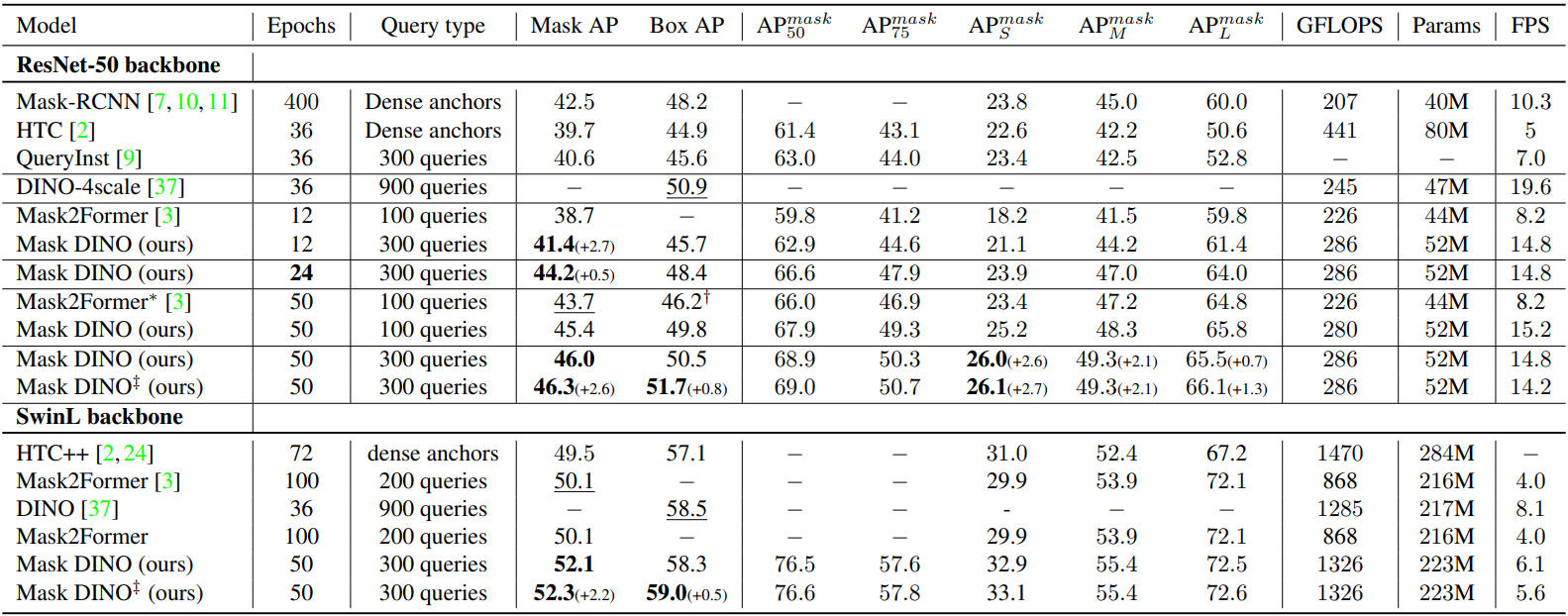
다음은 ResNet-50과 SwinL을 backbone으로 사용한 다른 모델들과 COCO val2017에서 object detection과 instance segmentation 결과를 비교한 표이다.
Panoptic segmentation
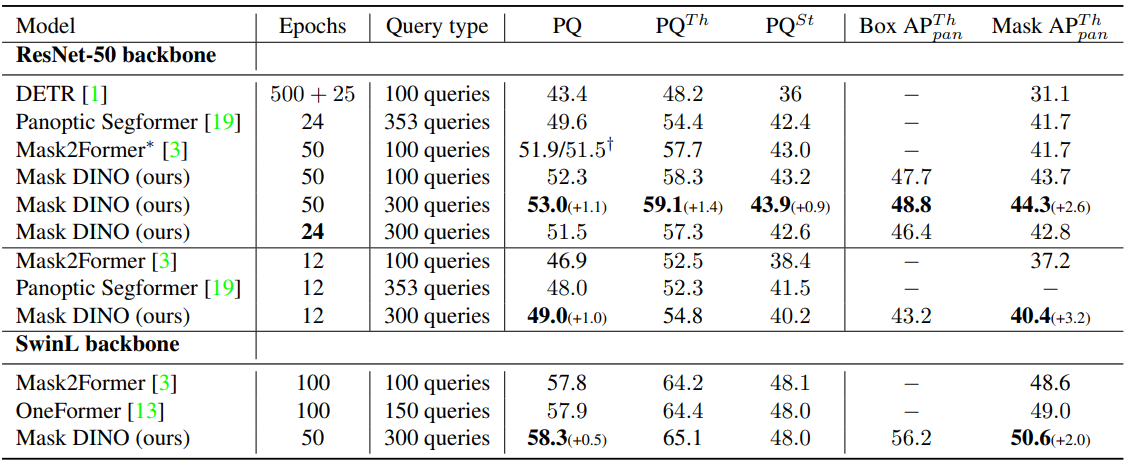
다음은 ResNet-50과 SwinL을 backbone으로 사용한 다른 모델들과 COCO val2017에서 panoptic segmentation 결과를 비교한 표이다.
Semantic segmentation
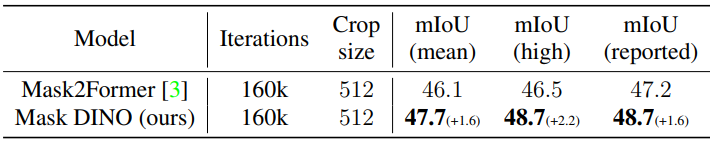
다음은 Mask2Former와 ADE20K val에서의 query 100개를 사용한 결과를 비교한 표이다.
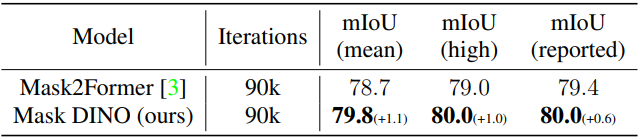
다음은 Mask2Former와 Cityscapes val에서의 query 100개를 사용한 결과를 비교한 표이다.
2. Comparison with SOTA Models
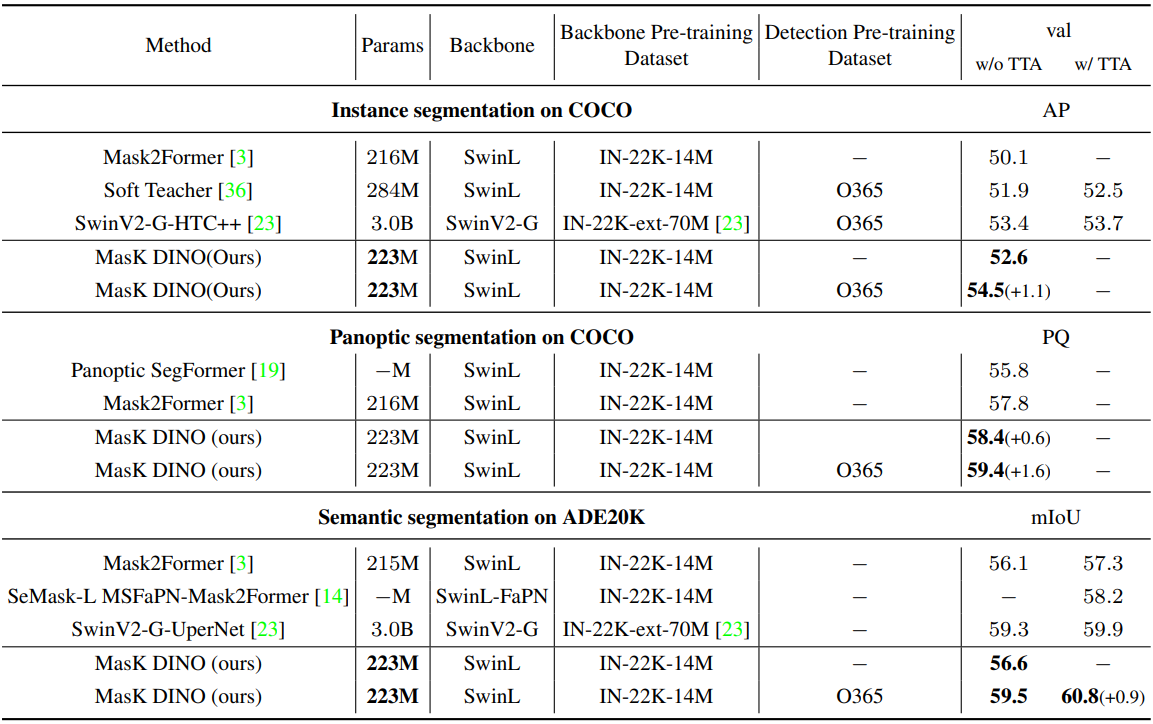
다음은 세 가지 segmentation task에서 SOTA 모델들과 비교한 표이다.
3. Ablation Studies
Query selection
다음은 마스크 초기화를 위한 query selection에 대한 효과를 나타낸 표이다.
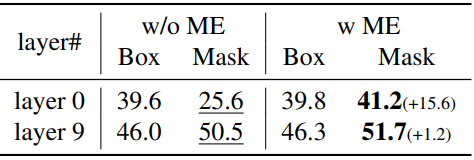
다음은 Mask-enhanced anchor box initialization (ME)의 유무에 따른 모델을 비교한 표이다.
Feature scales
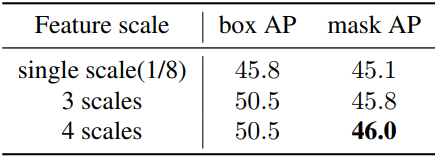
다음은 50 epoch 설정에서 Transformer 디코더의 여러 feature 스케일을 비교한 표이다.
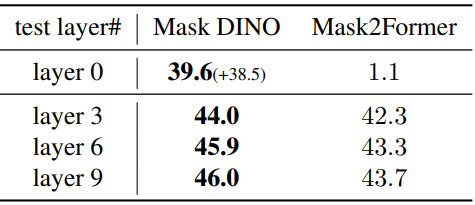
Object detection and segmentation help each other
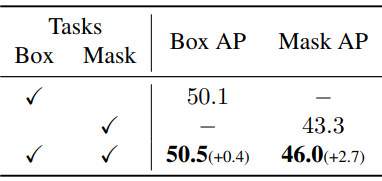
다음은 task 협력 여부를 확인하기 위하여 50 epoch 설정에서 task에 따른 성능을 비교한 표이다.
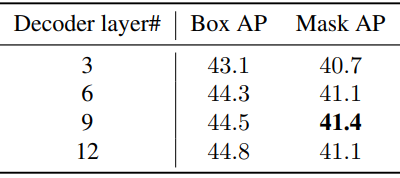
Decoder layer number
다음은 12 epoch 설정에서 디코더 레이어 수에 따른 성능을 비교한 표이다.
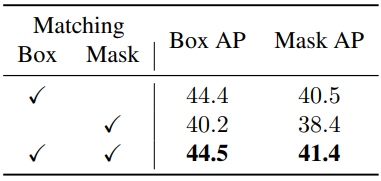
Matching
다음은 12 epoch 설정에서 매칭 방법에 따른 성능을 비교한 표이다.
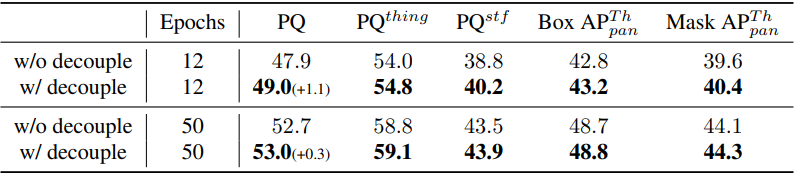
Decoupled box prediction
다음은 12 epoch 설정과 50 epoch 설정에서 panoptic segmentation를 위한 decoupled box prediction의 효과를 나타낸 표이다.
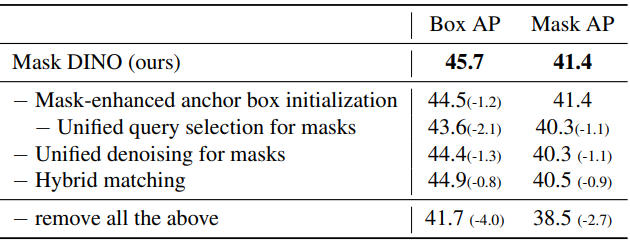
Effectiveness of the algorithm components
다음은 12 epoch 설정에서 제안된 구성 요소의 효과를 나타낸 표이다.