[논문리뷰] Mask-Adapter: The Devil is in the Masks for Open-Vocabulary Segmentation
CVPR 2025. [Paper] [Github]
Yongkang Li, Tianheng Cheng, Bin Feng, Wenyu Liu, Xinggang Wang
School of EIC, Huazhong University of Science & Technology
5 Dec 2024
Introduction
최근 연구에서는 대규모 이미지-텍스트 쌍에서 사전 학습되고 강력한 zero-shot 인식 능력이 있는 사전 학습된 VLM (ex. CLIP, ALIGN)을 활용하여 open-vocabulary segmentation을 다룬다. 특히 여러 방법들은 분할 후 인식 (segment-then-recognize) 패러다임을 따르며, 마스크 생성기로 이미지에서 마스크를 여러 개 예측한 다음 CLIP의 zero-shot 인식 능력으로 제안된 마스크들을 분류한다.
마스크 인식은 주로 CLIP 비전 인코더를 통해 마스크 임베딩을 추출하고 텍스트 임베딩과 매칭하여 달성된다. 일반적으로 마스크 임베딩은 두 가지 방법으로 얻을 수 있다.
- Mask cropping: 이미지에서 분할된 영역을 자르고 CLIP을 사용하여 이미지 임베딩을 추출
- Mask pooling: 제안된 마스크에 mask pooling을 사용하여 영역의 feature를 직접 집계. Mask cropping보다 효율적이고 end-to-end 최적화가 가능
그러나 이 두 가지 open-vocabulary segmentation 방법은 본질적으로 제한적이다. Mask cropping 방법은 마스킹된 이미지와 CLIP 사전 학습에 사용된 이미지 간의 차이를 고려하지 못한다. Mask pooling 방법은 feature 집계 중에 semantic 디테일과 맥락적 정보를 포착하지 못한다.

본 논문에서는 open-vocabulary segmentation의 한계점을 해결하는 간단하면서도 효과적인 방법인 Mask-Adapter를 제안하였다. 예측된 마스크를 직접 사용하여 마스크 임베딩을 추출하는 대신, 제안된 마스크와 CLIP feature에서 semantic activation map을 추출한다. 마스크 임베딩은 semantic 정보와 맥락적 정보를 모두 기반으로 집계된 후 마스크 인식을 위해 텍스트 임베딩과 매칭된다.
이전 방식과 달리 Mask-Adapter는 몇 가지 주요 이점을 제공한다.
- 배경을 무시하는 대신 전체 이미지에서 마스크 임베딩을 집계하여 맥락적 정보를 통합하여 feature 표현을 풍부하게 한다.
- 대상 영역의 위치 정보만 전달하는 mask pooling과 달리, semantic activation map은 인식과 관련된 정보가 풍부한 영역만 선택적으로 강조하여 feature 구별력을 향상시킨다.
- 학습 과정에서 CLIP의 일반화 능력을 유지하는 동시에 마스크 인식 성능을 향상시킨다.
저자들은 추가로 mask consistency loss를 도입하여 유사한 마스크들이 유사한 CLIP 마스크 임베딩을 얻도록 하였으며, 이를 통해 예측 마스크 변화에 대한 robustness를 향상시켰다. 또한 overfitting을 더욱 완화하기 위해, Hungarian matcher를 IoU-based matcher로 대체하여 모델이 더 광범위한 마스크들에 대해 학습할 수 있도록 했다. 또한, Mask-Adapter의 robustness를 높이고 open-vocabulary segmentation에서 성능을 향상시키는 혼합 마스크 학습 전략을 제안하였다.
Method
1. Problem Definition
Open-vocabulary segmentation은 미리 정의된 고정된 클래스 집합이 아닌, 임의의 텍스트 설명을 기반으로 이미지를 분할하는 것을 목표로 한다. 기존의 open-vocabulary segmentation 방법은 클래스 독립적인 마스크 생성기와 마스크 분류기로 구성된다. Mask2Former와 같은 마스크 생성기로 클래스 독립적인 마스크 $M_p \in \mathbb{R}^{N \times H \times W}$를 생성하고, 마스크 분류기로 텍스트 설명에 따라 이러한 마스크를 분류한다.
마스크 생성기에서 생성된 $N$개의 클래스 독립적인 마스크 $M_p$가 주어지면, 초기 방법들은 mask cropping을 활용하였다. 이는 이미지 $\mathcal{I}$에서 분할된 영역을 자르고 CLIP을 사용하여 마스크 임베딩을 추출한다.
\[\begin{equation} \mathbf{E}_\textrm{mask} = \textrm{CLIP} (\textrm{crop} (M_p, \mathcal{I})) \in \mathbb{R}^{N \times C} \end{equation}\]마스크 임베딩은 텍스트 임베딩과 매칭된다. 그러나 마스킹된 이미지와 실제 이미지 사이에 차이가 있기 때문에 open-vocabulary segmentation에 대한 성능이 제한된다.
Mask pooling을 사용하는 방법들은 제안된 마스크에 mask pooling을 사용하여 CLIP feature들을 집계하여, mask cropping보다 더 높은 효율성을 제공한다.
\[\begin{equation} \mathbf{E}_\textrm{mask} = M_p \cdot \mathcal{F}_\textrm{clip}^\top \end{equation}\]그러나 mask pooling 방식은 마스크 영역의 위치 정보만 포착할 뿐, 맥락적 feature와 semantic feature가 모두 부족하다.
2. Mask-Adapter
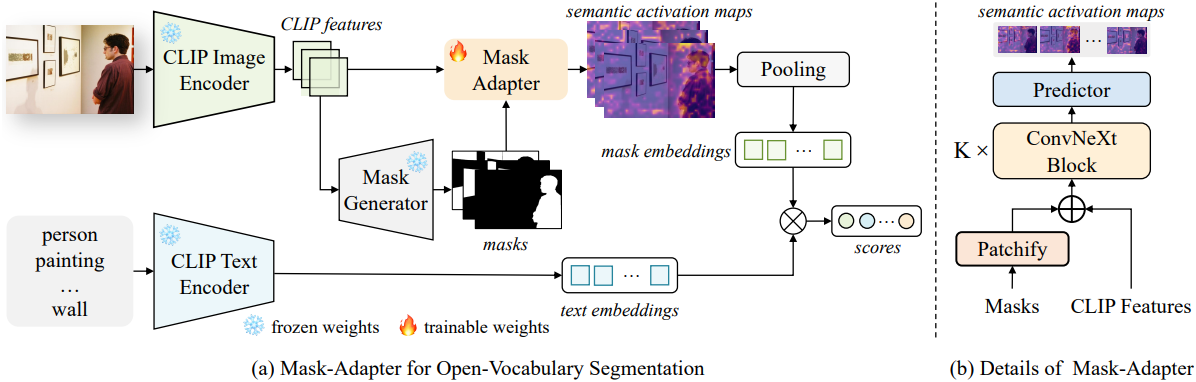
$N$개의 클래스 독립적인 마스크 $M_p$가 주어지면, 2개의 strided 3$\times$3 convolutional layer로 구성된 단순한 블록을 통해 바이너리 마스크를 patchify하여 CLIP feature외 동일한 해상도를 갖는 마스크 feature \(\mathcal{F}_m\)을 생성한다. 그런 다음 CLIP feature \(\mathcal{F}_\textrm{clip}\)과 마스크 feature \(\mathcal{F}_m\)을 융합하여 마스크 영역 표현 \(\textbf{A}_m\)을 얻는다.
그런 다음, \(\textbf{A}_m\)을 3개의 ConvNeXt 블록에 통과시켜 마스크 영역의 semantic 정보를 강화한다. 정제된 feature들은 최종 convolutional layer에서 처리되어 각 마스크에 대해 $K$개의 semantic activation map $\textbf{A}$를 생성한다.
\[\begin{equation} \textbf{A} = \textrm{Conv} (\textrm{ConvNeXt}^3 (\textbf{A}_m)) \end{equation}\]$K$개의 semantic activation map \(\bar{\textbf{A}}\)를 사용하여 CLIP feature \(\mathcal{F}_\textrm{clip}\)의 정보를 집계하고, 각 임베딩의 평균을 구하여 마스크 임베딩 $E_m$을 얻는다. 여기서 \(\bar{\textbf{A}}\)는 각 semantic map에 대해 1로 정규화된다.
\[\begin{equation} E_m = \frac{1}{K} \sum_{k=1}^K \bar{\textbf{A}}_k \cdot \mathcal{F}_\textrm{clip}^\top \in \mathbb{R}^{N \times C} \end{equation}\]생성된 마스크 임베딩은 $N$개 마스크에 대한 feature 표현으로 사용되며, 이후 마스크를 분류하기 위해 텍스트 임베딩과 매칭된다. Mask pooling 방식과 달리, 이 방법은 더욱 풍부한 semantic 정보를 통합하고 마스크 영역 밖의 맥락적 정보를 포함한다.
3. IoU-based Matcher
마스크 생성기에서 생성된 마스크 중 여러 마스크가 동일한 물체에 대응하지만 잘못 식별될 수 있다. 이전 방법들에서 사용된 Hungarian matcher는 일반적으로 GT 마스크와 예측 간의 최적의 매칭을 찾는데, 이는 이러한 잘못 분류된 샘플을 포착하지 못한다. 이는 Mask-Adapter 학습 중 overfitting으로 이어질 수 있다.
이를 해결하기 위해, 각 GT 마스크 $y_i$와 예측 마스크 \(\hat{y}_j\) 사이의 IoU를 계산하고, 미리 정의된 IoU threshold를 기반으로 마스크 쌍을 선택하는 IoU-based matcher를 사용한다.
\[\begin{equation} \mathcal{M} = \{ (i,j) \, \vert \, \textrm{IoU} (y_i , \hat{y}_j) \ge \textrm{IoU}_\textrm{threshold} \} \end{equation}\]이 접근 방식은 일대일 매칭보다 더 다양한 학습 샘플을 장려하며, 이전에 잘못 분류된 샘플을 통합하여 모델의 robustness를 향상시킨다.
4. Mask Consistency
학습 중에 본 적이 없는 클래스에 대해 feature 도메인에서 더 많은 공간을 할당하면 처음 보는 마스크의 인식이 향상된다. 그러나 Mask-Adapter를 학습시키기 위해 표준 classification loss를 직접 사용하면 feature space가 지나치게 혼잡해져 모델의 처음 보는 카테고리 인식 능력이 제한될 수 있다.
저자들은 학습에 사용되는 클래스에 대한 마스크 임베딩에 mask consistency loss를 적용하는 더 간단한 접근 방식을 채택하였다. Matcher에서 매칭된 예측 마스크와 GT 마스크가 주어지면, 이를 Mask-Adapter에 입력하여 각각의 마스크 임베딩 $e^\textrm{gt}$와 $e^\textrm{pred}$를 얻는다. 그런 다음, 두 임베딩 사이의 코사인 유사도 loss를 계산한다.
\[\begin{equation} \mathcal{L}_\textrm{cos} (e^\textrm{gt}, e^\textrm{pred}) = 1 - \textrm{cos} (e^\textrm{gt}, e^\textrm{pred}) \end{equation}\]Mask consistency loss는 제안된 마스크들이 유사한 IoU를 갖는 마스크와 유사한 CLIP 임베딩을 얻어, 처음 보는 마스크의 인식을 향상시키고 모델의 robustness를 향상시킨다.
5. Stable Mask-Text Alignment Training
마스크-텍스트 정렬 학습을 통해 CLIP의 open-vocabulary 인식 능력을 전달하는 것은 Mask-Adapter의 자연스러운 접근 방식이다. 그러나 예측된 마스크를 직접 사용하는 것은 overfitting과 학습 불안정성을 초래한다. 이 문제를 해결하기 위해, GT 마스크 warmup과 혼합 마스크 학습으로 구성된 2단계 학습 전략을 사용하였다.
GT 마스크 warmup
먼저, 저품질 예측 마스크를 피하기 위해 GT 마스크를 사용하여 Mask-Adapter를 학습시켜 안정적인 학습을 보장한다. 이 warmup 단계를 통해 Mask-Adapter는 강력한 일반화를 개발하여 GT 마스크와 예측 마스크 모두에 robust하게 동작한다.
혼합 마스크 학습
Warmup 학습 후, IoU-based matcher에서 예측된 마스크와 GT 마스크를 혼합하여 학습시킨다. 이 혼합 마스크 학습에는 품질이 낮고 잘못 분류된 마스크가 포함되어 Mask-Adapter의 robustness를 향상시키고 open-vocabulary segmentation 성능을 개선시킨다.
전체 학습 loss
마스크 분류에는 cross-entropy loss를, 마스크 일관성 강화에는 코사인 loss를 사용한다. 총 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \lambda_\textrm{ce} \cdot \mathcal{L}_\textrm{ce} + \lambda_\textrm{cos} \cdot \mathcal{L}_\textrm{cos} \end{equation}\]Experiments
- 데이터셋: COCO-Stuff, COCO-Panoptic
- 구현 디테일
- 해상도: 1024$\times$1024
- optimizer: AdamW
- learning rate = $1 \times 10^{-4}$
- weight decay = 0.05
- multi-step learning rate decay schedule
- GT 마스크 warmup
- epoch 20
- batch size: 8
- 혼합 마스크 학습
- epoch: 10
- batch size: 16
- IoU-based matcher threshold: \(\textrm{IoU}_\textrm{threshold} = 0.7\)
- loss 가중치: \(\lambda_\textrm{ce} = 2.0\), \(\lambda_\textrm{cos} = 5.0\)
- GPU: NVIDIA RTX 3090 GPU 4개
1. Main Results
다음은 다른 방법들과 open-vocabulary semantic segmentation 성능을 비교한 결과이다. (mIoU로 비교)
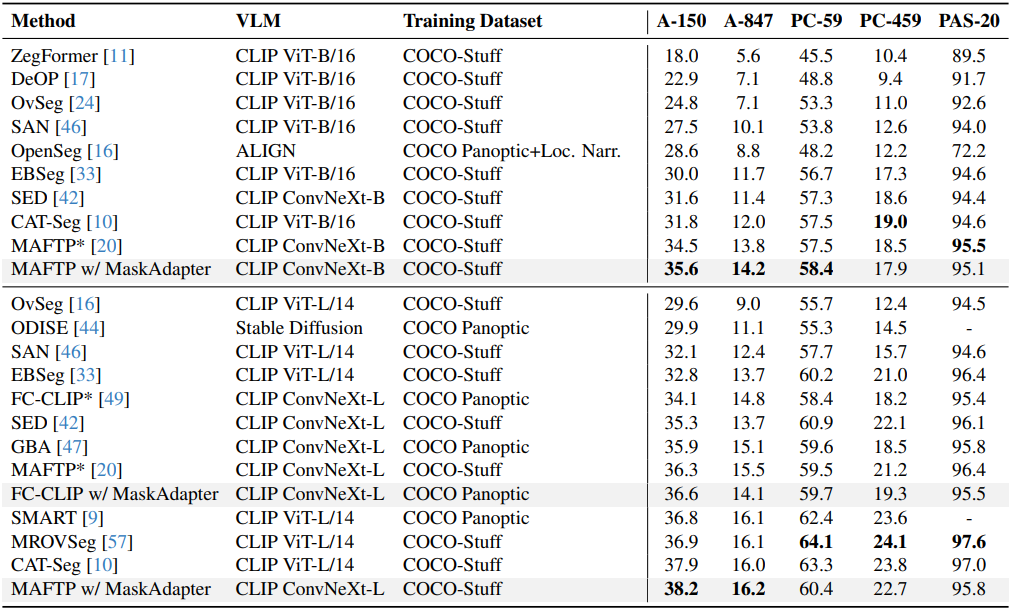
다음은 ADE20K에서 다른 방법들과 성능을 비교한 결과이다.
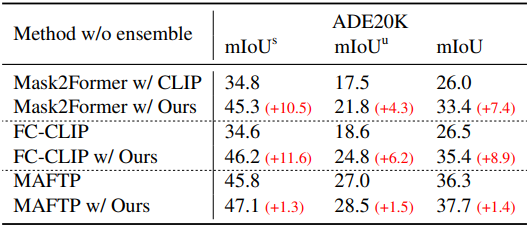
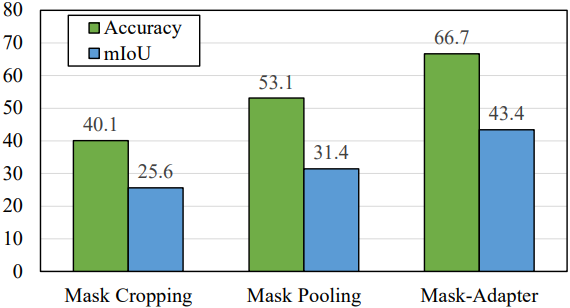
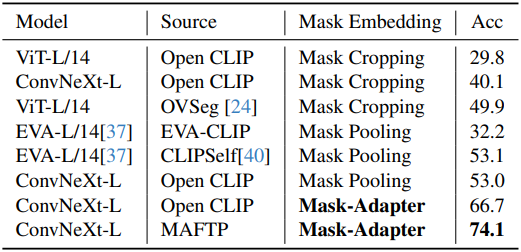
다음은 다른 마스크 임베딩 추출 방법과 마스크 분류 성능을 비교한 결과이다.
2. Ablation
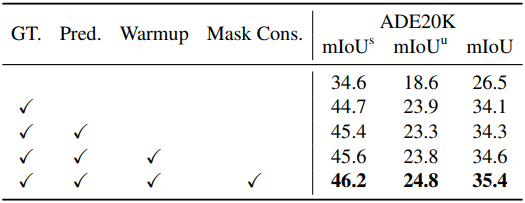
다음은 학습 전략 및 방법에 대한 ablation study 결과이다.
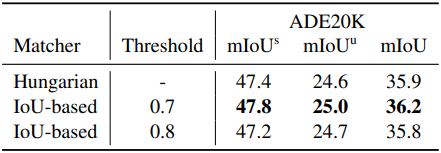
다음은 matcher와 IoU threshold에 대한 ablation study 결과이다.
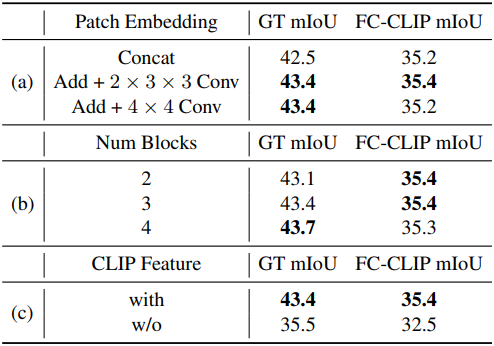
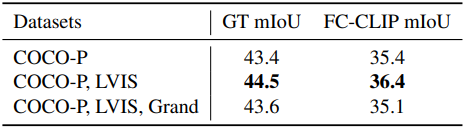
다음은 (왼쪽) Mask-Adapter 디자인과 (오른쪽) GT 마스크 warmup에 사용하는 학습 데이터에 대한 ablation study 결과이다.
3. Segment Anything with Mask-Adapter
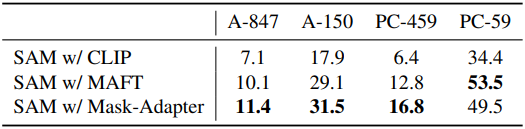
다음은 SAM에 Mask-Adapter를 적용하였을 때의 결과이다.