[논문리뷰] Matching Anything by Segmenting Anything
CVPR 2024. [Paper] [Page] [Github]
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
ETH Zürich | INSAIT
6 Jun 2024
Introduction
Multiple Object Tracking (MOT)는 컴퓨터 비전의 근본적인 문제 중 하나이다. 물체를 추적하려면 동영상에서 관심 물체를 감지하고 이를 프레임 전체에 연결해야 한다. 최근 모델의 발전으로 모든 물체에 대한 detection, segmentation, 깊이를 인식하는 뛰어난 능력이 입증되었지만 동영상에서 해당 물체를 연결하는 것은 여전히 어려운 일이다.
물체의 연결을 학습하려면 일반적으로 상당한 양의 주석이 달린 데이터가 필요하다. 다양한 이미지들에서 레이블을 수집하는 것은 힘든 일이지만, 동영상에서 추적 레이블을 얻는 것은 훨씬 더 어렵다. 결과적으로, 현재 MOT 데이터셋은 대부분 카테고리 수가 적거나 레이블이 있는 프레임 수가 제한된 특정 도메인의 물체에 중점을 둔다.
이러한 데이터셋에서의 학습은 추적 모델의 다양한 도메인과 새로운 물체에 대한 일반화 능력을 제한한다. 본 논문의 목표는 어떤 물체나 영역이라도 일치시킬 수 있는 방법을 개발하는 것이다. 이 일반화 가능한 추적 능력을 임의의 detection 및 segmentation 방법과 통합하여 탐지한 물체를 추적하는 데 도움을 주는 것을 목표로 한다. 주요 과제는 상당한 라벨링 비용을 들이지 않고 다양한 도메인의 물체에 대한 매칭 supervision을 확보하는 것이다.
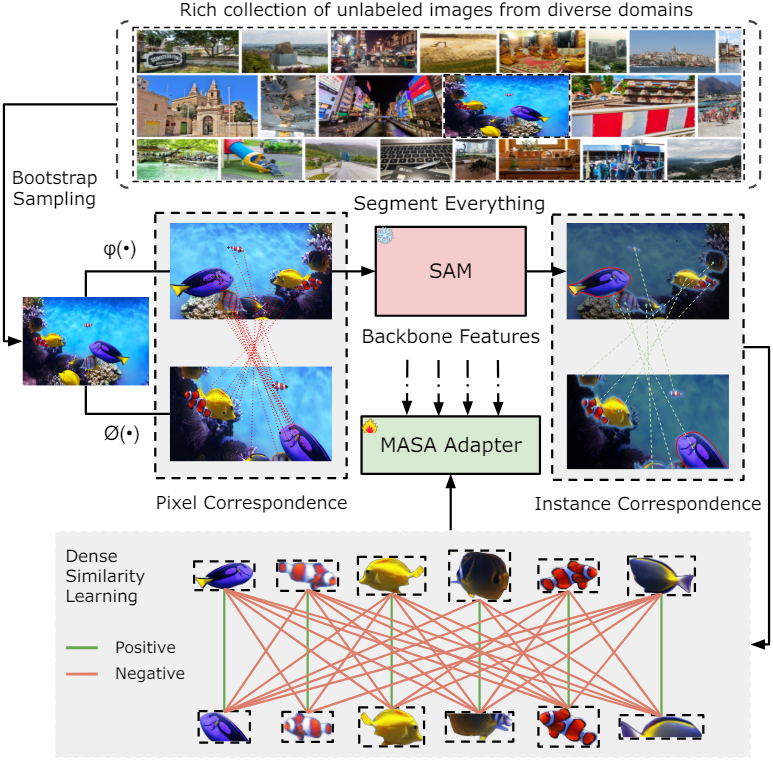
이를 위해 본 논문은 Matching Anything by Segmenting Anything (MASA) 파이프라인을 통해 모든 도메인의 레이블이 없는 이미지에서 물체 수준 연결을 학습하였다. 강력한 인스턴스 대응 관계를 구축하기 위해 광범위한 데이터 변환과 결합된 SAM에 의해 인코딩된 풍부한 개체 모양 및 모양 정보를 활용한다.
동일한 이미지에 서로 다른 기하학적 변환을 적용하면 동일한 이미지의 두 뷰에서 픽셀 수준의 대응 관계를 자동으로 얻을 수 있다. SAM을 사용하면 동일한 인스턴스의 픽셀을 자동으로 그룹화할 수 있어 픽셀 수준의 대응 관계를 인스턴스 수준의 대응 관계로 쉽게 변환할 수 있다. 이 프로세스는 뷰 쌍 간의 dense한 유사도 학습을 활용하여 물체 표현을 학습하기 위한 self-supervision 신호를 생성한다. 이러한 학습 전략을 통해 다양한 도메인의 풍부한 이미지들을 사용할 수 있으며, in-domain 동영상 주석에 의존하는 모델보다 뛰어난 zero-shot MOT 성능을 제공한다.
저자들은 범용 추적 어댑터인 MASA 어댑터를 추가로 구축하여 SAM, Detic, Grounding-DINO와 같은 기존 open-world segmentation 및 detection foundation model을 강화하여 탐지된 물체를 추적한다. 원래의 segmentation 및 detection 능력을 유지하기 위해 원래 backbone을 고정하고 MASA 어댑터를 그 위에 추가한다.
또한 본 논문은 detection 지식의 distillation과 인스턴스 유사도 학습을 공동으로 수행하는 multi-task 학습 파이프라인을 제안하였다. 이를 통해 SAM의 prior를 학습하고 contrastive learning 중에 실제 detection proposal을 시뮬레이션할 수 있다. 이 파이프라인은 tracking feature들의 일반화 능력을 더욱 향상시킨다. 또한 학습된 detection head를 사용하면 박스 프롬프트를 직접 제공하여 SAM의 everything mode 속도를 10배 가속할 수 있다.
Method
1. MASA Pipeline
인스턴스 수준의 대응 관계를 학습하기 위해 이전 연구들에서는 수동 레이블이 달린 in-domain 동영상 데이터에 크게 의존했다. 그러나 동영상 데이터셋들에는 제한된 범위의 카테고리만 포함되어 있다. 이러한 제한된 다양성으로 인해 특정 도메인에 맞춰진 appearance embedding을 학습하게 되어 보편적인 일반화에 어려움을 겪게 된다.
UniTrack은 이미지나 동영상의 contrastive self-supervised learning을 통해 보편적인 appearance feature를 학습할 수 있음을 보여주었다. 레이블이 없는 대량의 이미지의 다양성을 활용하는 이러한 표현은 다양한 도메인에 걸쳐 일반화될 수 있다. 그러나 ImageNet과 같은 깔끔한 물체 중심 이미지나 DAVIS17과 같은 동영상에 의존하고 프레임 수준 유사성에 초점을 맞추는 경우가 많다. 이로 인해 인스턴스 정보를 완전히 활용하지 못하게 되어 여러 인스턴스가 있는 복잡한 도메인에서 discriminative한 인스턴스 표현을 학습하는 데 어려움을 겪게 된다.
본 논문은 이러한 문제를 해결하기 위해 MASA 학습 파이프라인을 제안하였다. 핵심 아이디어는 이미지 다양성과 인스턴스 다양성의 학습이라는 두 가지 관점에서 다양성을 높이는 것이다. 도메인별 feature 학습을 방지하기 위해 다양한 도메인의 풍부한 이미지 컬렉션을 구성한다. 또한 이러한 이미지에는 복잡한 환경의 풍부한 인스턴스가 포함되어 인스턴스 다양성을 향상시킨다.
이미지 $I$가 주어지면 동일한 이미지에 두 가지 다른 augmentation $\psi$와 $\phi$를 적용하여 $I$의 두 가지 서로 다른 뷰 $V_1$과 $V_2$를 구성하고 자동으로 픽셀 수준 대응 관계를 얻는다.
이미지가 깨끗하고 ImageNet과 같이 하나의 인스턴스만 포함하는 경우 프레임 수준의 유사도를 적용할 수 있다. 그러나 인스턴스가 여러 개인 경우 이러한 이미지에 포함된 인스턴스 정보를 추가로 마이닝해야 한다. SAM은 이러한 능력을 가지고 있다. SAM은 동일한 인스턴스에 속한 픽셀을 자동으로 그룹화하고 감지된 인스턴스의 모양 및 경계 정보도 제공한다.
여러 인스턴스가 있는 이미지를 선택하여 데이터셋을 구성하기 때문에 SAM의 전체 이미지에 대한 segmentation은 자동으로 dense하고 다양한 인스턴스 컬렉션 $Q$를 생성한다. 픽셀 수준의 대응 관계를 아는 상태에서 동일한 $\psi$와 $\phi$를 $Q$에 적용하여 픽셀 수준 대응 관계를 dense한 인스턴스 수준 대응 관계로 전송한다. 이 self-supervision 신호를 사용하여 contrastive learning을 통해 contrastive embedding space를 학습한다.
\[\begin{equation} \mathcal{L}_C = - \sum_{q \in Q} \log \frac{\exp (\textrm{sim} (q, q^{+}) / \tau)}{\exp (\textrm{sim} (q, q^{+}) / \tau) + \sum_{q^{-} \in Q^{-}} \exp (\textrm{sim} (q, q^{-}) / \tau)} \end{equation}\]Positive sample $q^{+}$는 $q$와 다른 augmentation이 적용된 동일한 인스턴스이며, Negative sample $q^{-}$는 $q$가 아닌 다른 인스턴스에서 나온 것이다. $\textrm{sim}(\cdot)$은 cosine similarity이며 temperature $\tau$는 0.07로 설정된다.
이러한 contrastive learning을 통해 동일한 인스턴스에 속한 임베딩을 더 가깝게 하면서 다른 인스턴스의 임베딩을 멀리한다. 기존 연구들에서 알 수 있듯이 negative sample은 discriminative한 표현을 학습하는 데 중요하다. SAM에 의해 생성된 dense한 인스터스들은 자연스럽게 더 많은 negative sample을 제공하므로 더 나은 인스턴스 표현 학습을 향상시킨다.
2. MASA Adapter
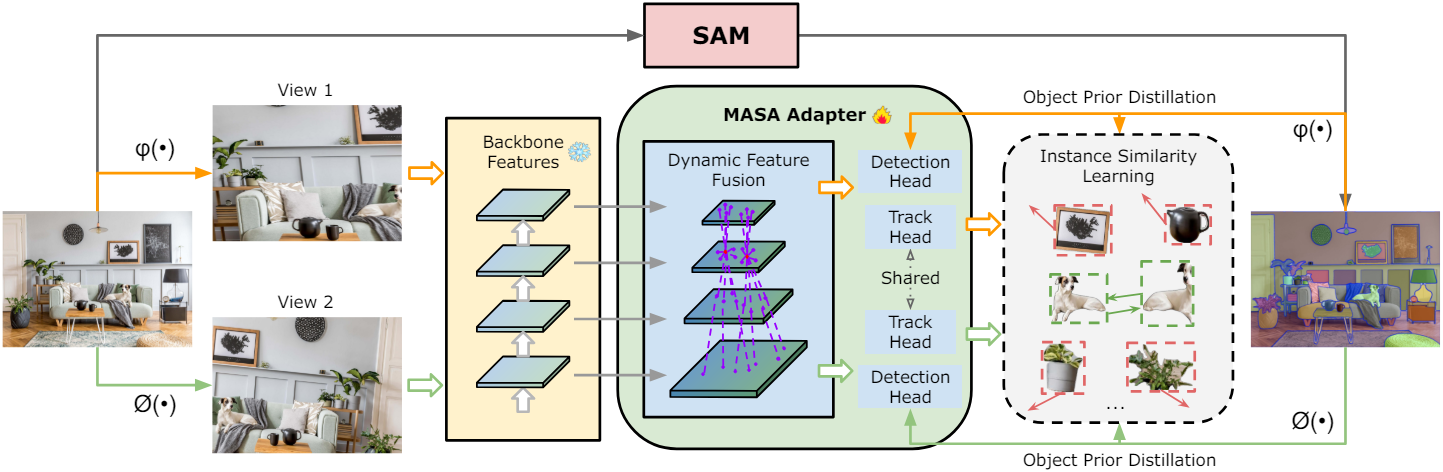
저자들은 Detic, Grounding DINO, SAM 등의 open-world segmentation 및 detection model을 확장하여 감지된 물체를 추적하도록 설계된 MASA 어댑터를 도입하였다. MASA 어댑터는 foundation model의 고정된 backbone feature와 함께 작동하여 원래의 detection 및 segmentation 능력이 보존되도록 한다. 그러나 사전 학습된 모든 feature가 본질적으로 물체 추적을 위한 것은 아니기 때문에 먼저 고정된 backbone feature를 물체 추적에 더 적합한 새로운 feature로 변환한다.
물체의 모양과 크기의 다양성을 고려하여 multi-scale feature pyramid를 구성한다. Swin Transformer와 같은 계층적 backbone을 사용하는 Detic과 Grounding DINO의 경우 FPN을 직접 사용한다. 일반 ViT backbone을 사용하는 SAM의 경우 Transpose Convolution과 MaxPooling을 사용하여 single-scale feature를 업샘플링 및 다운샘플링하여 스케일 비율이 1/4, 1/8, 1/16, 1/32인 계층적 feature를 생성한다.
다양한 인스턴스에 대한 식별 능력을 효과적으로 학습하려면 한 위치에 있는 물체가 다른 위치에 있는 인스턴스의 외형을 인식하는 것이 중요하다. 따라서 deformable convolution을 사용하여 dynamic offset을 생성하고 공간적 위치와 feature level에 걸쳐 정보를 집계한다.
\[\begin{equation} F(p) = \frac{1}{L} \sum_{j=1}^L \sum_{k=1}^K w_k \cdot F^j (p + p_k + \Delta p_k^j) \cdot \Delta m_k^j \end{equation}\]여기서 $L$은 feature level, $K$는 convolutional kernel의 샘플링 위치 수, $w_k$와 $p_k$는 각각 $k$번째 위치에 대한 가중치와 미리 정의된 offset, $\Delta p_k^j$와 $\Delta m_j^k$는 학습 가능한 offset 및 modulation factor이다.
SAM 기반 모델의 경우 정확한 자동 마스크 생성을 위해서는 detection 성능이 중요하므로 Dyhead의 task-aware attention과 scale-aware attention을 추가로 사용한다. 변환된 feature map을 획득한 후 feature $F$에 RoI-Align을 적용하여 인스턴스 레벨 feature을 추출한 다음 4개의 convolutional layer와 1개의 fully-connected layer로 구성된 track head로 처리하여 인스턴스 임베딩을 생성한다.
또한 학습 중 보조 task로 object prior distillation branch를 도입하였다. 이 branch에서는 RCNN detection head를 사용하여 각 인스턴스에 대한 SAM의 마스크 예측을 포함하는 bounding box를 학습한다. SAM에서 물체 위치 및 외형 지식을 효과적으로 학습하고 이 정보를 변환된 feature 표현으로 추출한다. 이 디자인은 MASA 어댑터의 feature를 강화하여 연결 성능을 향상시킬 뿐만 아니라 예측된 박스 프롬프트를 직접 제공하여 SAM의 everything mode를 가속화한다.
MASA 어댑터는 detection loss와 contrastive loss의 조합을 사용하여 최적화된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{det} + \mathcal{L}_C \end{equation}\]Detection loss \(\mathcal{L}_\textrm{det}\)는 Faster R–CNN과 동일하다.
3. Inference
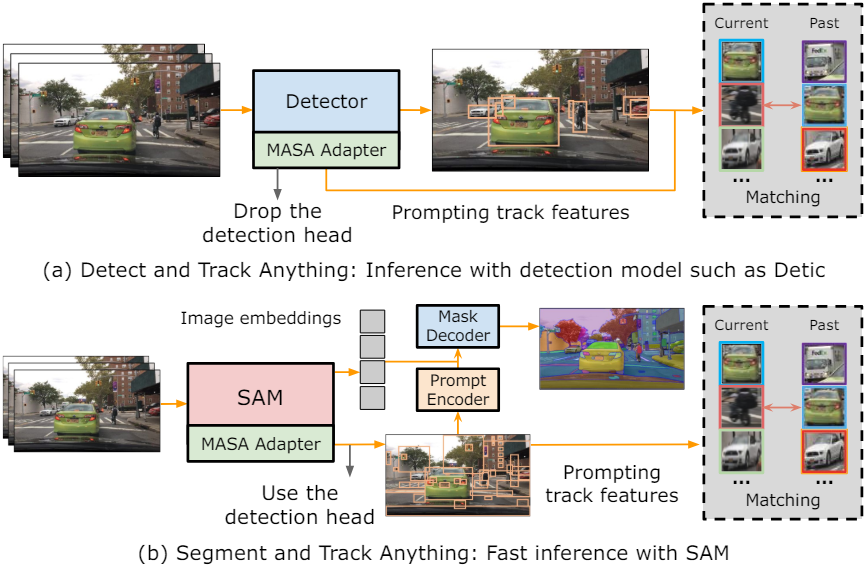
Detect and Track Anything
MASA 어댑터를 object detector와 통합할 때 학습된 MASA detection head를 제거한다. 그러면 MASA 어댑터는 추적기 역할만 한다. Detector가 bounding box를 예측하면 이 박스들은 MASA 어댑터에서 인스턴스 매칭을 위해 tracking feature를 검색하는데 프롬프트로 사용된다. 정확한 인스턴스 매칭을 위해 간단한 bi-softmax nearest neighbor search를 사용한다.
Segment and Track Anything
SAM을 사용하는 경우 detection head를 유지한다. Detection head가 장면 내의 모든 잠재적 물체를 예측하면, SAM 마스크 디코더와 MASA 어댑터에 프롬프트로 박스 예측을 전달한다. 예측된 박스 프롬프트는 원래 SAM의 everything mode에서 사용되는 무거운 후처리의 필요성을 생략하므로 SAM의 자동 마스크 생성 속도가 크게 향상된다.
Testing with Given Observations
MASA 어댑터가 구축된 소스가 아닌 다른 소스에서 detection 결과를 얻은 경우 MASA 어댑터는 tracking feature를 공급하는 역할을 한다. ROI-Align 연산을 통해 MASA 어댑터에서 tracking feature를 추출하기 위한 프롬프트로 제공된 bounding box를 직접 활용한다.
Experiments
- 데이터: SA-1B에서 이미지 50만 개를 샘플링하여 사용
- 구현 디테일
- backbone
- SAM: ViT-Base, ViT-Huge
- Detic, GroundingDINO: SwinB
- epoch: 20 (epoch당 20만 개의 이미지)
- batch size: 128
- optimizer: SGD
- 초기 learning rate: 0.04
- momentum: 0.9
- weight decay: $10^{-4}$
- data augmentation: random affine, MixUp, Large-scale Jittering, flipping, color jittering, random cropping
- backbone
1. State-of-the-Art Comparison
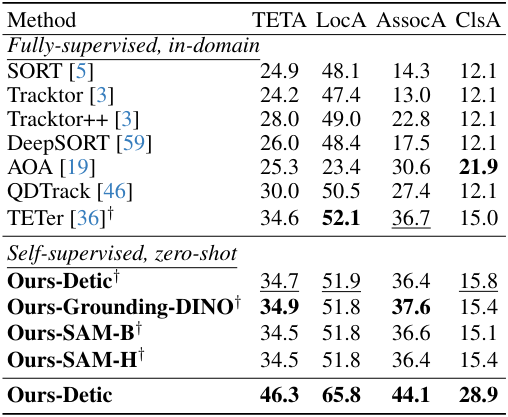
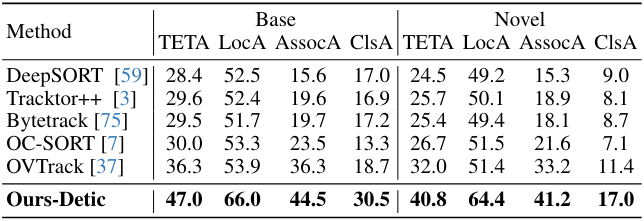
다음은 (왼쪽) TAO TETA 벤치마크와 (오른쪽) open-vocabulary MOT 벤치마크에서 SOTA와 비교한 결과이다.
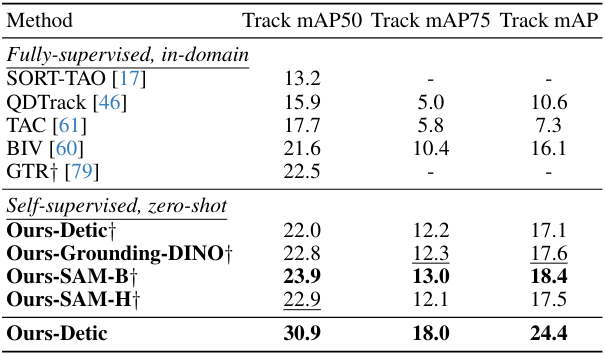
다음은 TAO Track mAP 벤치마크에서 SOTA와 비교한 결과이다.
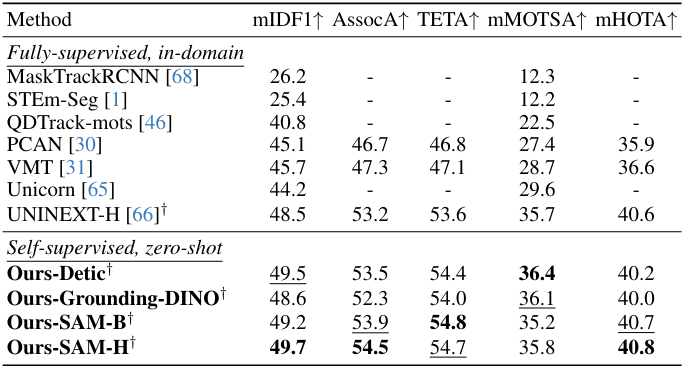
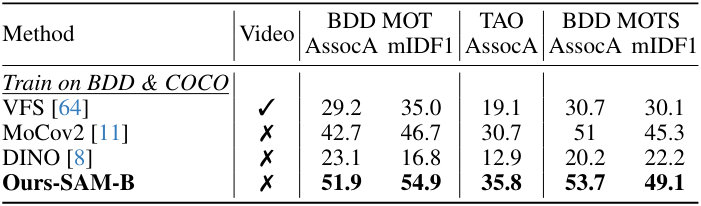
다음은 (왼쪽) BDD MOTS 벤치마크와 (오른쪽) BDD MOT 벤치마크에서 SOTA와 비교한 결과이다.
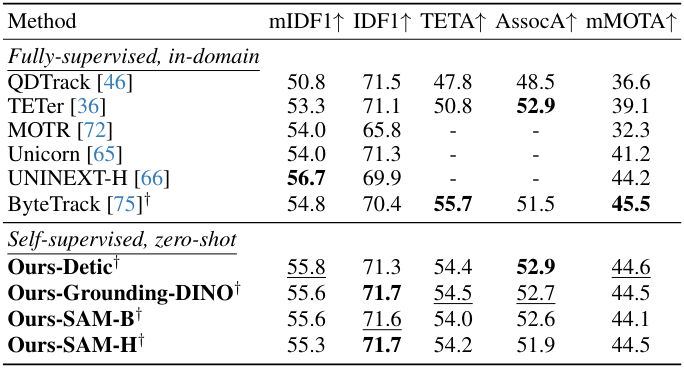
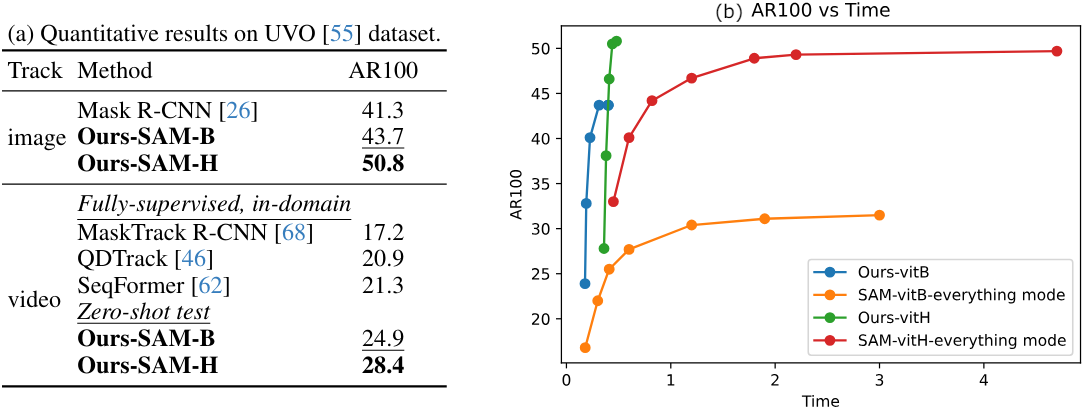
다음은 UVO 데이터셋에서 (왼쪽) object detection 및 동영상 물체 추적 결과와 (오른쪽) inference 시간을 비교한 결과이다.
다음은 VOS 방법들과 비교한 결과이다.

다음은 self-supervised 기반 방법들과 비교한 결과이다.
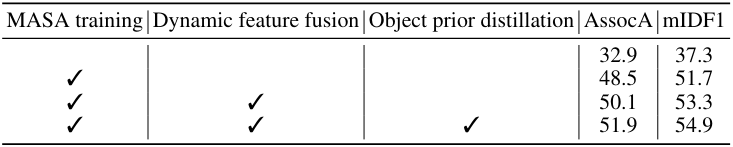
2. Ablation Study
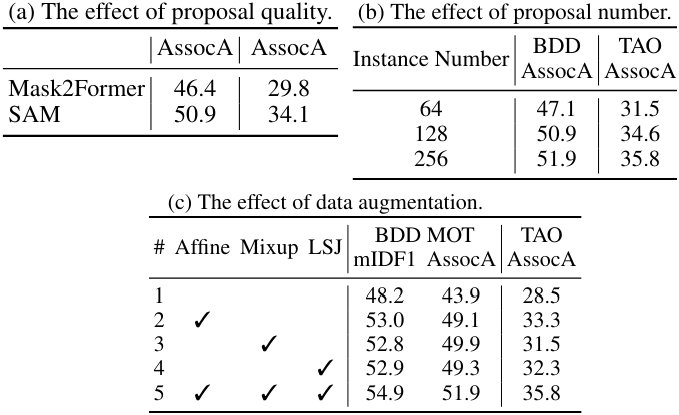
다음은 학습 전략과 모델 아키텍처에 대한 ablation 결과이다.
다음은 인스턴스 $Q$의 품질과 개수, 그리고 data augmentation에 대한 ablation 결과이다.