[논문리뷰] Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
ICCV 2023. [Paper] [Page] [Github]
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, Dong Chen
Shanghai Jiao Tong University | HKUST | Microsoft Research
24 Mar 2023

Introduction
인간은 세계에 대한 사전 지식을 바탕으로 3D 형상을 쉽게 상상하고 그림을 한 눈에 보는 새로운 시점의 모습을 상상하는 타고난 능력을 가지고 있다. 본 논문에서는 실제 또는 인위적으로 생성된 단일 이미지에서 고화질 3D 콘텐츠를 만드는 것을 목표로 한다. 이것은 Stable Diffusion과 같은 최첨단 2D 생성 모델로 만든 판타지 이미지에 3D 효과를 가져오는 것과 같이 예술적 표현과 창의성을 위한 새로운 길을 열어줄 것이다.
단일 이미지에서 3D 객체를 생성하는 것은 단일 시점에서 유추할 수 있는 제한된 정보로 인해 상당한 어려움이 있다. 연구의 한 카테고리는 이미지 기반 렌더링 또는 neural rendering을 사용한 단일 view 3D 재구성 방식으로 3D photo effect를 생성하는 것을 목표로 한다. 그러나 이러한 방법은 종종 세밀한 형상을 재구성하는 데 어려움을 겪고 큰 view에서 렌더링하기에는 부족하다. 또 다른 연구 라인은 사전 학습된 3D-aware 생성 네트워크의 latent space에 입력 이미지를 project한다. 인상적인 성능에도 불구하고 기존의 3D 생성 네트워크는 주로 특정 클래스의 객체를 모델링하므로 일반적인 3D 객체를 처리할 수 없다. 본 논문은 임의의 이미지에서 일반적인 3D 생성을 목표로 하지만 새로운 view를 추정하거나 일반 개체에 대한 강력한 3D 기반 모델을 구축하기 위해 충분히 크고 다양한 데이터셋을 구성하는 것은 여전히 극복할 수 없다.
3D 모델의 희소성과 달리 이미지는 훨씬 더 쉽게 사용할 수 있으며 diffusion model의 최근 발전으로 인해 2D 이미지 생성의 혁명이 일어났다. 흥미롭게도 잘 학습된 이미지 diffusion model은 다양한 시점에서 이미지를 생성할 수 있으며, 이는 이미 3D 지식을 통합했음을 의미한다. 이것은 3D 객체를 재구성하기 위해 2D diffusion model에서 사전 지식을 활용할 수 있는 가능성을 탐구하도록 했다. 본 논문은 diffusion prior과 함께 단 하나의 이미지에서 우수한 품질의 고충실도 3D 객체를 생성할 수 있는 2단계 3D 콘텐츠 제작 방법인 Make-It-3D를 제안한다.
첫 번째 단계에서는 Score Distillation Sampling (SDS)를 적용하여 Neural Radiance Field (NeRF)를 최적화하기 전에 diffusion을 활용하고 reference-view supervision으로 이 최적화를 제한한다. 기존의 text-to-3D 연구와 달리 이미지 기반의 3D 제작에 중점을 두어 레퍼런스 이미지에 대한 충실도를 우선시해야 한다. 그러나 SDS로 생성된 3D 모델은 텍스트 프롬프트와 잘 일치하지만 텍스트 설명이 개체의 모든 세부 정보를 캡처하지 않기 때문에 레퍼런스 이미지와 충실하게 일치하지 않는 경우가 많다. 이 문제를 해결하기 위해 diffusion model에 의해 denoise된 레퍼런스와 새로운 view 렌더링 간의 이미지 레벨 유사성을 동시에 최대화하여 SDS를 넘어선다. 또한 이미지는 본질적으로 텍스트 설명보다 더 많은 형상 관련 정보를 캡처하므로 NeRF 최적화의 모양 모호성을 완화하기 전에 레퍼런스 이미지의 깊이를 추가 형상으로 통합할 수 있다.
첫 번째 단계는 그럴듯한 형상을 가진 coarse model을 생성하지만 그 모양은 종종 레퍼런스 품질에서 벗어나 지나치게 부드러운 질감과 채도가 높은 색상을 나타낸다. 이로 인해 전반적인 사실성이 제한되었으며 coarse model과 레퍼런스 이미지 사이의 간격을 더 연결하는 것이 필수적이다. 텍스처는 고품질 렌더링의 맥락에서 인간의 인식에 형상보다 더 중요하기 때문에 첫 번째 단계에서 형상을 상속하면서 두 번째 단계에서 텍스처 향상을 우선시하도록 선택한다. 레퍼런스 이미지에서 관찰할 수 있는 영역에 대한 ground truth 텍스처의 가용성을 활용하여 모델을 개선한다. 이를 위해 coarse NeRF 모델을 텍스처 포인트 클라우드로 내보내고 레퍼런스 텍스처를 포인트 클라우드의 해당 영역에 project한다. 그런 다음 포인트 feature와 포인트 클라우드 렌더러를 공동으로 최적화하여 나머지 포인트의 텍스처를 향상시키기 전에 diffusion을 활용하여 생성된 3D 모델의 텍스처를 명확하게 개선했다.
Method
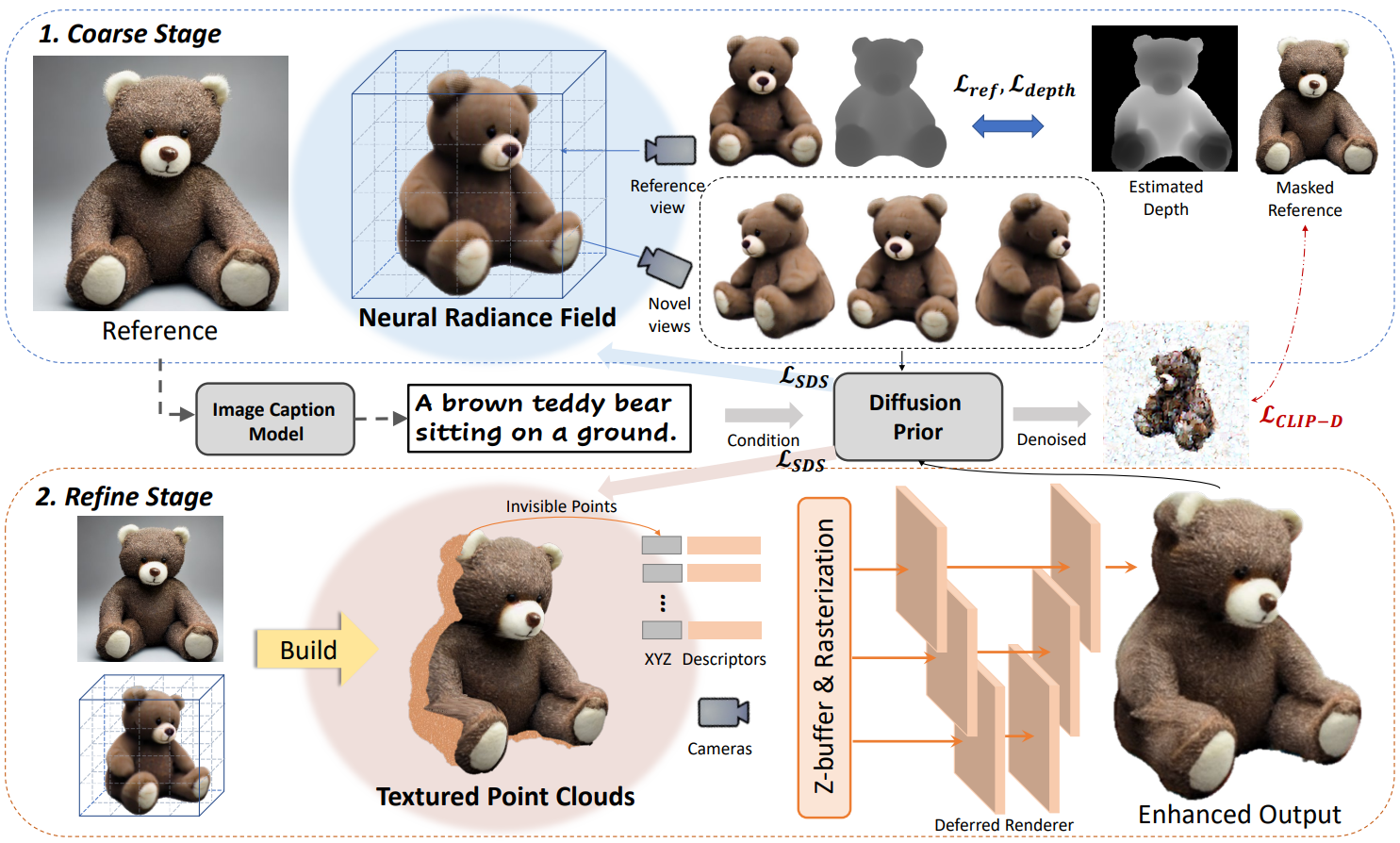
단 하나의 이미지에서 일반적인 장면이나 물체에 대한 새로운 view를 생성하는 것은 형상과 누락된 텍스처를 모두 추론하는 것이 어렵기 때문에 본질적으로 어렵다. 따라서 사전 학습된 2D diffusion model의 지식을 활용하여 이 문제를 해결한다. 구체적으로, 입력 이미지 $x$가 주어지면 먼저 기본 3D 표현인 NeRF를 상상한다. 이 필드의 렌더링은 사전 학습된 diffusion model에 그럴듯한 샘플로 나타나고, 레퍼런스 view에서 텍스처 및 깊이 supervision으로 이 최적화 프로세스를 제한한다. 렌더링 사실감을 더욱 향상시키기 위해 학습된 형상을 유지하고 레퍼런스 이미지로 텍스처를 향상시킨다. 이와 같이 두 번째 단계에서는 입력 이미지를 질감이 있는 포인트 클라우드로 만들고 레퍼런스 view에서 가려진 포인트의 색상을 다듬는 데 중점을 둔다.
두 단계 모두에 대해 text-to-image 생성 모델과 text-image contrastive model에 대한 사전 지식을 활용한다. 이러한 방식으로 복원된 고충실도 텍스처와 형상으로 입력 이미지의 충실한 3D 표현을 달성한다. 제안된 2단계 3D 학습 프레임워크는 위 그림에 설명되어 있다.
1. Preliminaries
최근 연구 결과에 따르면 사전 학습된 2D 생성 모델은 2D 생성 샘플에 대한 풍부한 3D 형상 지식을 제공한다. 특히 DreamFusion은 text-to-image diffusion model을 사용하여 3D 표현의 최적화를 가이드한다. $\mathcal{G}_\theta (\beta)$를 주어진 시점 $\beta$에서 렌더링된 이미지라고 하자. 여기서 $\mathcal{G}$는 $\theta$로 parameterize된 3D 표현에 대한 differentiable rendering function이며 선택이 가능하다. DreamFusion은 멀티뷰 렌더링이 고정 diffusion model의 고품질 샘플처럼 보이도록 NeRF를 최적화한다.
구체적으로, diffusion model $\phi$는 다른 timestep $t$에서 렌더링된 이미지 $x_0 := \mathcal{G}_\theta (\beta)$에 랜덤한 양의 noise를 도입한다.
\[\begin{equation} x_t = \alpha_t x_0 + \sigma_t \epsilon, \quad \epsilon \sim \mathcal{N} (0, I) \end{equation}\]$\alpha_t$와 $\sigma_t$는 log signal-to-noise $\lambda_t = \log [\alpha_t^2 / \sigma_t^2]$가 timestep $t$에 따라 선형적으로 감소하는 noise schedule을 정의한다. 사전 학습된 텍스트 조건부 diffusion model은 텍스트 임베딩 $y$가 주어지면 이 noising process를 역전시키도록 학습된다. 3D 표현 파라미터를 최적화하여 이미지를 양호한 생성 샘플에 가깝게 렌더링하기 위해 Score Distillation Sampling (SDS) loss \(\mathcal{L}_\textrm{SDS}\)를 도입하여 렌더링된 이미지를 텍스트 임베딩에 따라 더 높은 밀도 영역으로 민다. 구체적으로 \(\mathcal{L}_\textrm{SDS}\)는 장면 파라미터를 업데이트하는 데 사용되는 픽셀별 기울기로 예측된 noise와 추가된 noise의 차이를 계산한다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{SDS} (\phi, \mathcal{G}_\theta) = \mathbb{E}_{t, \epsilon} \bigg[ w(t) (\epsilon_\phi (x_t; y, t) - \epsilon) \frac{\partial x}{\partial \theta} \bigg] \end{equation}\]여기서 $w(t)$는 다양한 noise level의 가중치 함수이다. 이 loss는 본질적으로 이미지와 텍스트 프롬프트 간의 유사성을 측정한다. Diffusion model은 비평가 역할을 하며 \(\mathcal{L}_\textrm{SDS}\)의 기울기는 diffusion network를 통해 역전파되지 않으므로 효율적인 계산이 가능하다. 학습이 진행됨에 따라 NeRF 파라미터가 업데이트되며 그 동안 3D 객체는 텍스처와 형상을 점차적으로 드러낸다. 실제로 강력한 classifier-free guidance 강도의 모델을 사용하면 더 높은 품질의 3D 샘플이 생성된다.
DreamFusion은 Imagen을 사용하여 픽셀 레벨에서 noising process를 역전시키는 반면, 본 논문은 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$로 VQ-VAE의 latent space를 모델링하는 Stable Diffusion을 사용한다. 따라서 사용된 diffusion model은 latent $z_0 := \mathcal{E} (\mathcal{G}_\theta (\beta))$를 소화하고 재구성된 latent \(\hat{z}_0\)는 \(\hat{x} = \mathcal{D} (\hat{z}_0)\)을 통해 이미지 space에 매핑될 수 있다.
2. Coarse Stage: Single-view 3D Reconstruction

첫 번째 단계로 새로운 view를 제한하는 diffusion prior를 사용하여 단일 레퍼런스 이미지 $x$에서 coarse NeRF를 재구성한다. 최적화는 다음 요구 사항을 동시에 충족할 것으로 예상된다.
- 최적화된 3D 표현은 레퍼런스 view에서 입력 관찰 $x$의 렌더링 모양과 매우 유사해야 한다.
- 새로운 view 렌더링은 입력과 일관된 semantic을 보여야 하며 가능한 한 그럴듯하게 나타나야 한다.
- 생성된 3D 모델은 매력적인 형상을 보여야 한다.
이를 고려하여 레퍼런스 view 주변의 카메라 포즈를 랜덤하게 샘플링하고 레퍼런스 view와 보지 못한 view 모두에 대해 렌더링된 이미지 \(\mathcal{G}_\theta\)에 제약을 적용한다.
Reference view per-pixel loss
입력 이미지와 일관된 모양을 유지하기 위해 레퍼런스 view $\beta_\textrm{ref}$에서 렌더링과 입력 이미지 간의 픽셀별 차이에 페널티를 부여한다.
\[\begin{equation} \mathcal{L}_\textrm{ref} = \| x \odot m - \mathcal{G}_\theta (\beta_\textrm{ref}) \|_1 \end{equation}\]여기에서 전경 matting mask $m$을 적용하여 전경을 분할한다. 이는 형상 재구성을 용이하게 한다.
Diffusion prior
앞서 언급한 loss로 최적화하는 것은 불안정할 수 있으며 문제의 잘못된 특성으로 인해 믿을 수 없는 결과를 초래할 수 있다. 의미론적으로 타당한 결과를 장려하기 위해 새로운 view 렌더링에 추가적인 제약이 필요하다. 이 문제를 해결하기 위해 diffusion prior에 의지한다. Text-to-3D 적용 \(\mathcal{L}_\textrm{SDS}\)에 대한 이전 연구는 텍스트 조건부 diffusion model을 3D-aware prior로 활용한다. 본 논문의 경우 \(\mathcal{L}_\textrm{SDS}\)를 활용하기 위해 이미지 캡션 모델을 사용하여 레퍼런스 이미지에 대한 자세한 텍스트 설명 $y$를 생성한다. 텍스트 프롬프트 $y$를 사용하여 Stable Diffusion의 latent space에서 SDS를 수행할 수 있다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{SDS} (\phi, \mathcal{G}_\theta) = \mathbb{E}_{t, \epsilon} \bigg[ w(t) (\epsilon_\phi (z_t; y, t) - \epsilon) \frac{\partial z}{\partial x} \frac{\partial x}{\partial \theta} \bigg] \end{equation}\]여기서 noisy latent $z_t$는 Stable Diffusion 인코더에 의해 $x$를 렌더링하는 새로운 view에서 얻는다.
그러나 앞에서 설명한 것처럼 \(\mathcal{L}_\textrm{SDS}\)는 기본적으로 이미지와 주어진 텍스트 프롬프트 간의 유사성을 측정한다. \(\mathcal{L}_\textrm{SDS}\)는 텍스트 프롬프트에 충실한 3D 모델을 생성할 수 있지만 텍스트 프롬프트가 개체의 모든 디테일을 캡처할 수 없기 때문에 레퍼런스 이미지와 완벽하게 일치하지 않는다. 본 논문은 diffusion CLIP loss \(\mathcal{L}_\textrm{CLIP-D}\)로 이를 넘어섰다. 이 loss는 레퍼런스 이미지와 일치하도록 생성된 모델을 추가로 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{CLIP-D} (\mathcal{X}, \mathcal{G}_\theta (\beta)) = - \mathcal{E}_\textrm{CLIP} (\mathcal{X}) \cdot \mathcal{E}_\textrm{CLIP} (\hat{\mathcal{X}}_0 (\beta, t)) \end{equation}\]여기서 \(\mathcal{E}_\textrm{CLIP}\)은 CLIP 이미지 인코더이다. 렌더링된 이미지 \(\mathcal{G}_\theta (\beta)\)에서 CLIP loss를 직접 측정하는 대신 \(\mathcal{G}_\theta (\beta)\)를 noisy latent $z_t$로 렌더링한 다음 2D diffusion을 사용하여 깨끗한 이미지 \(\hat{\mathcal{X}}_0 (\beta, t)\)로 denoise한다. Diffusion model에서 샘플링된 denoise된 이미지에 유사성 loss를 부과함으로써 고정된 diffusion의 고품질 샘플과 유사하면서 렌더링이 레퍼런스 이미지와 일치하도록 권장한다.
구체적으로 \(\mathcal{L}_\textrm{CLIP-D}\)와 \(\mathcal{L}_\textrm{SDS}\)을 동시에 최적화하지 않는다. 작은 timestep에서 \(\mathcal{L}_\textrm{CLIP-D}\)를 사용하고 큰 timestep에서 \(\mathcal{L}_\textrm{SDS}\)로 전환한다. \(\mathcal{L}_\textrm{CLIP-D}\)와 \(\mathcal{L}_\textrm{SDS}\)를 결합한 diffusion prior는 3D 모델이 시각적으로 매력적이고 그럴듯하게 보이면서도 주어진 이미지와 일치하도록 한다.
Depth prior
그럼에도 불구하고 렌더링된 이미지가 diffusion model에 의미 있게 나타나더라도 움푹 들어간 면, 지나치게 편평한 형상 또는 깊이 모호성과 같은 문제를 일으키는 모양 모호성이 여전히 존재한다. 풍부한 외부 이미지에서 학습한 깊이 prior를 활용하고 3D에서 supervision을 직접 시행하여 이를 완화한다. 구체적으로, 입력 이미지의 깊이 $d$를 추정하기 위해 기존 single-view depth estimator를 사용한다. 추정된 깊이는 형상 디테일을 정확하게 특성화하지 못할 수 있지만 그럴듯한 형상을 보장하고 대부분의 모호성을 해결하는 데 충분하다. $d$의 부정확성과 스케일 불일치를 설명하기 위해 추정된 깊이와 레퍼런스 시점에서 NeRF에 의해 모델링된 깊이 $d(\beta_\textrm{ref})$ 사이의 음의 Pearson 상관 관계를 정규화한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = - \frac{\textrm{Cov} (d(\beta_\textrm{ref}), d)}{\textrm{Var} (d (\beta_\textrm{ref})) \textrm{Var} (d)} \end{equation}\]여기서 $\textrm{Cov}(\cdot)$는 공분산을 나타내고 $\textrm{Var}(\cdot)$는 표준 편차를 계산한다. 이 정규화를 통해 NeRF 깊이 추정은 깊이 prior와 선형적으로 상관되도록 권장된다.
Overall training
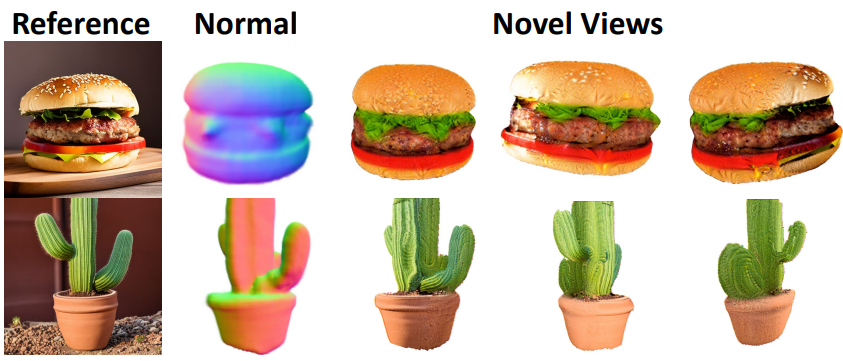
전체 loss는 \(\mathcal{L}_\textrm{ref}\), \(\mathcal{L}_\textrm{SDS}\), \(\mathcal{L}_\textrm{CLIP-D}\), \(\mathcal{L}_\textrm{depth}\)의 조합으로 공식화할 수 있다. 최적화 프로세스를 안정화하기 위해 학습 중에 레퍼런스 view 근처의 좁은 범위의 view에서 시작하여 점진적으로 범위를 확장하는 점진적 학습 전략을 채택한다. 점진적인 학습을 통해 아래 그림과 같이 물체를 360도로 재구성할 수 있다.
3. Refine Stage: Neural Texture Enhancement
Coarse stage 후에 그럴듯한 형상을 가진 3D 모델을 얻었지만 전체 품질을 저하하는 coarse한 텍스처가 자주 나타난다. 따라서 고충실도 3D 모델에 대한 추가 개선이 필요하다. 형상보다 텍스처 품질에 관해서 인간이 더 분별력이 있다는 점을 감안할 때 coarse model의 형상을 유지하면서 텍스처 향상을 우선시한다.
텍스처 향상에 대한 핵심 통찰력은 새로운 view의 경우 새로운 view와 레퍼런스 view 모두에서 특정 픽셀을 관찰할 수 있다는 것이다. 결과적으로 레퍼런스 이미지의 고품질 텍스처를 3D 표현의 해당 영역에 투영하기 위해 이 중첩을 이용할 수 있다. 그런 다음 레퍼런스 view에서 가려진 영역의 텍스처를 향상시키는 데 중점을 둔다.
NeRF는 토폴로지 변화를 지속적으로 처리할 수 있으므로 coarse stage에서 적합한 표현이지만 레퍼런스 이미지를 여기에 투영하는 것은 어렵다. 따라서 저자들은 NeRF를 명시적 표현, 특히 포인트 클라우드로 내보내도록 선택하였다. Marching cube에서 내보낸 noisy mesh와 비교할 때 포인트 클라우드는 더 깨끗하고 직관적인 projection을 제공한다.
Textured point cloud building
포인트 클라우드를 구축하는 순진한 시도는 NeRF에서 multi-view RGBD 이미지를 렌더링하고 3D 공간의 텍스처 포인트로 만드는 것이다. 그러나 이 간단한 방법은 서로 다른 view 간의 충돌로 인해 잡음이 많은 포인트 클라우드로 이어진다. 3D 포인트는 서로 다른 view에서 NeRF 렌더링에서 서로 다른 RGB 색상을 가질 수 있다. 따라서 저자들은 multi-view 관찰에서 깨끗한 포인트 클라우드를 구축하기 위한 반복 전략을 제안한다.
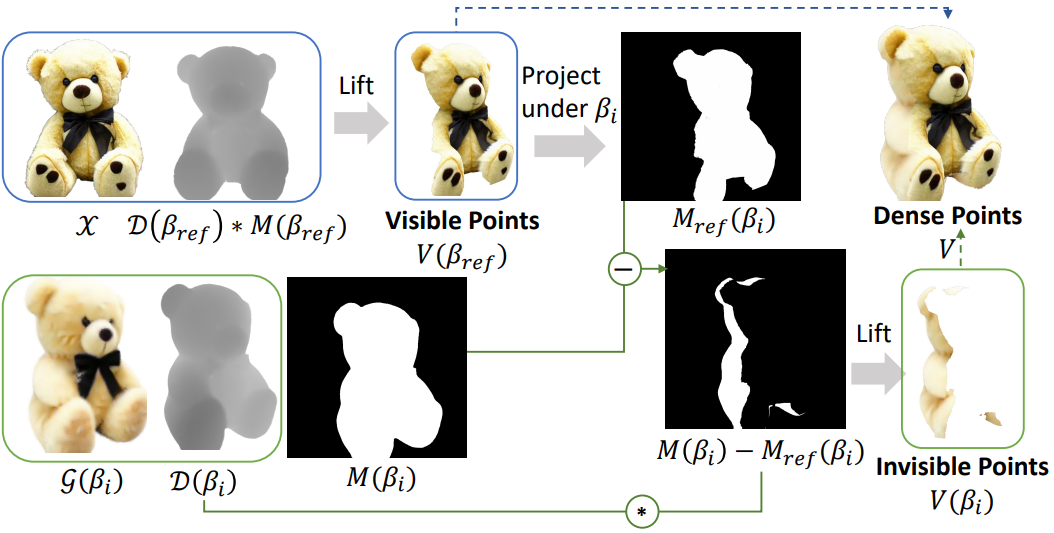
위 그림에서와 같이 먼저 NeRF의 렌더링된 깊이 \(\mathcal{D} (\beta_\textrm{ref})\)와 알파 마스크 $M(\beta_\textrm{ref})$에 따라 레퍼런스 view $\beta_\textrm{ref}$에서 포인트 클라우드를 구축한다.
여기서 $R_\textrm{ref}$와 $K$는 카메라의 extrinsic matrix와 intrinsic matrix이고 $\mathcal{P}$는 depth-to-point projection을 나타낸다. 이러한 포인트는 레퍼런스 view 아래에서 볼 수 있으므로 ground-truth 텍스처로 색상이 지정된다. 나머지 view $\beta_i$의 projection을 위해 기존 포인트와 겹치지만 색상이 충돌하는 포인트를 도입하지 않는 것이 중요하다. 이를 위해 기존 포인트 $V(\beta_\textrm{ref})$를 새로운 view $\beta_i$에 project하여 기존 포인트의 존재를 나타내는 마스크를 생성한다. 이 마스크를 guidance로 사용하여 위 그림과 같이 아직 관찰되지 않은 포인트 $V(\beta_i)$만 만든다. 그런 다음 이러한 보이지 않는 포인트는 $\mathcal{G} (\beta_i)$를 렌더링하는 NeRF의 coarse한 텍스처로 초기화되고 조밀한 포인트 클라우드로 통합된다.
Deferred point cloud rendering
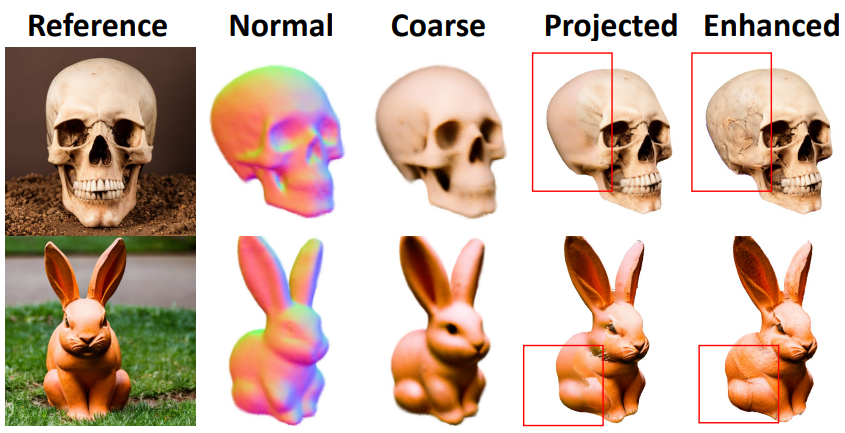
지금까지 텍스처 포인트 클라우드 집합 \(V = \{V(\beta_\textrm{ref}), V(\beta_1), \ldots, V(\beta_N)\}\)을 구축했다. \(V(\beta_\textrm{ref})\)에는 이미 레퍼런스 이미지에서 project된 고충실도 텍스처가 있지만 레퍼런스 view에서 가려진 다른 포인트는 위 그림과 같이 corase NeRF로 인해 여전히 부드러운 텍스처를 겪는다. 텍스처를 향상시키기 위해 다른 점의 텍스처 및 diffusion prior로 새로운 view 렌더링을 제한한다. 특히 각 포인트에 대해 19차원 descriptor $F$를 최적화한다. 처음 3차원은 초기 RGB 색상으로 초기화된다. Noisy한 색상과 번지는 아티팩트를 방지하기 위해 멀티스케일 deferred rendering 체계를 채택한다. 특히 새로운 view $\beta$가 주어지면 포인트 클라우드 $V$를 $K$번 rasterize하여 크기가 다양한 $K$개의 feature와 map $I_i$를 얻는다. 그런 다음 이러한 feature와 map이 concat되어 이미지 $I$로 렌더링된다.
여기서 $\mathcal{S}$는 differentiable point rasterizer이다. 텍스처 향상 프로세스의 목적은 형성 생성의 목적과 유사하지만 최적화된 텍스처와 초기 텍스처 간의 큰 차이에 페널티를 부과하는 정규화 항을 추가로 포함한다.
Experiments
- 구현 디테일
- NeRF 렌더링
- Instant-NGP의 멀티스케일 해시 인코딩을 사용하여 coarse stage에서 NeRF 표현을 구현
- Instant-NGP와 마찬가지로 점유 그리드를 유지하여 빈 공간을 스킵하여 효율적인 광선 샘플링을 가능하게 함
- 또한 렌더링된 이미지에 Lambertian 및 normal shading과 같은 여러 가지 shading augmentation을 채택
- 포인트 클라우드 렌더링
- Deferred rendering의 경우 gated convolution이 있는 2D U-Net 아키텍처를 사용
- 포인트 descriptor는 19차원이며 처음 3차원은 RGB 색상으로 초기화되고 나머지 차원은 랜덤으로 초기화됨
- 배경에 대한 학습 가능한 descriptor를 설정
- 카메라 세팅
- 75% 확률로 새로운 view를 무작위로 샘플링하고 25% 확률로 사전 정의된 레퍼런스 view를 샘플링
- NeRF로 렌더링할 때 FOV를 무작위로 확대
- Score Distillation Sampling (SDS)
- 200 ~ 600에서 랜덤하게 $t$를 샘플링
- $w(t)$를 $t$에 따라 균일한 가중치로 설정
- 가중치 $\omega = 10$으로 classifier-free guidance를 사용
- 학습 속도
- 두 stage 모두 learning rate가 0.001, 5천 iteration
- 렌더링 해상도는 coarse stage와 refine stage에서 각각 100$\times$100, 800$\times$800
- 전체 학습은 Tesla 32GB V100 GPU 1개에서 2시간 소요
- NeRF 렌더링
1. Comparisons with the State of the Arts
Qualitative comparison
다음은 DreamFusion, Point-E와 정성적으로 3D 생성 결과를 비교한 것이다.

다음은 DTU에서 SOTA 방법들과 새로운 view 합성 결과를 비교한 것이다.

Quantitative comparison
다음은 DTU에서의 정량적 비교 결과이다.
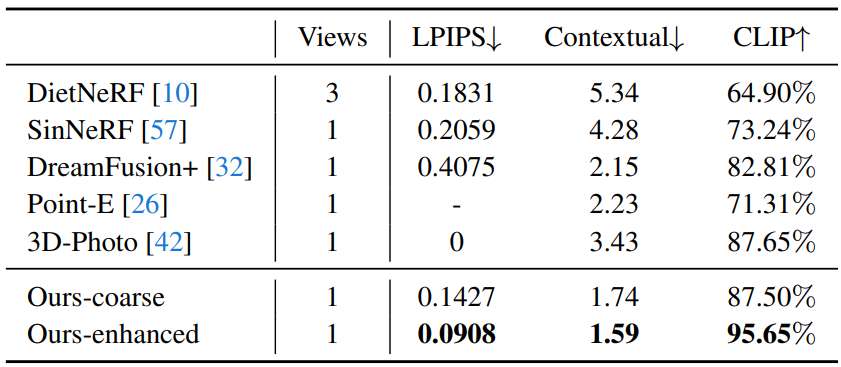
다음은 테스트 벤치마크에서의 정량적 비교 결과이다.
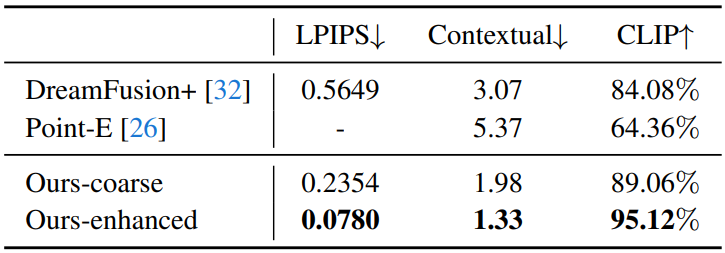
2. Applications
Real scene modeling
다음은 실제 복잡한 장면에 대한 Make-It-3D의 3D 생성 결과이다.

High-quality text-to-3D generation with diversity
다음은 주어진 텍스트 설명에 대한 Make-It-3D의 생성 결과이다.

3D-aware texture modification
다음은 텍스처 수정 예시이다.
