[논문리뷰] Language Model Beats Diffusion - Tokenizer is Key to Visual Generation (MAGVIT-v2)
ICLR 2024. [Paper] [Page]
Lijun Yu, José Lezama, Nitesh B. Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G. Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A. Ross, Lu Jiang
Google | Carnegie Mellon University
9 Oct 2023
Introduction
언어 모델(LM)은 이미지와 동영상을 생성할 수 있다. 이를 위해 이미지 픽셀은 visual tokenizer에 의해 일련의 이산적인 토큰으로 매핑된다. 그런 다음 이러한 토큰은 생성 모델링을 위해 마치 vocabulary 단어인 것처럼 LM transformer에 공급된다. 시각적 생성을 위해 LM을 사용하는 데 있어 눈에 띄는 발전에도 불구하고 LM은 여전히 diffusion model만큼 성능을 발휘하지 못한다. 예를 들어, 이미지 생성을 위한 최고의 표준 벤치마크인 ImageNet 데이터셋을 평가할 때 최고의 언어 모델은 diffusion model보다 상당한 48%의 차이로 성능이 저하된다 (256$\times$256 해상도에서 이미지를 생성할 때 FID 3.41 vs. 1.79).
시각적 생성에서 언어 모델이 diffusion model보다 뒤처지는 이유는 무엇일까? 저자들은 주된 이유가 시각적 세계를 효과적으로 모델링하기 위한 자연어 시스템과 유사한 좋은 시각적 표현이 부족하기 때문이라고 가정하였다. 이 가설을 입증하기 위해 본 논문에서는 마스킹된 언어 모델이 동일한 학습 데이터와 비슷한 모델 크기 및 학습 예산이 주어졌을 때 좋은 visual tokenizer를 활용하면 이미지와 동영상 벤치마크 전반에 걸쳐 생성 충실도와 효율성 측면에서 SOTA diffusion model을 능가한다는 것을 보여주었다. 이는 언어 모델이 ImageNet 벤치마크에서 diffusion model을 처음으로 능가한 것이다.
Diffusion model과 LLM의 근본적인 차이점은 LLM이 이산적인 latent 형식, 즉 visual tokenizer에서 얻은 토큰을 활용한다는 것이다. 다음과 같은 뚜렷한 장점이 있기 때문에 이러한 이산적인 시각적 토큰의 가치를 간과해서는 안 된다.
- LLM과의 호환성: 토큰 표현의 주요 장점은 언어 토큰과 동일한 형식을 공유하므로 LLM을 위해 수년 동안 개발된 최적화를 쉽게 활용할 수 있다는 것이다. 여기에는 더욱 빠른 학습 및 inference 속도, 모델 인프라의 발전, 모델 확장을 위한 학습 방법, GPU/TPU 최적화 등의 혁신이 포함된다. 동일한 토큰 공간으로 비전과 언어를 통합하면 시각적 환경 내에서 이해하고, 생성하고, 추론할 수 있는 진정한 멀티모달 LLM의 기반을 마련할 수 있다.
- 압축된 표현: 이산적인 토큰은 동영상 압축에 대한 새로운 관점을 제공할 수 있다. 시각적 토큰은 인터넷 전송 중에 디스크 저장 공간과 대역폭을 줄이기 위한 새로운 동영상 압축 형식으로 사용될 수 있다. 압축된 RGB 픽셀과 달리 이러한 토큰은 기존의 압축 해제 단계와 latent 인코딩 단계를 우회하여 생성 모델에 직접 공급될 수 있다. 이를 통해 더 빠른 처리가 가능하며 특히 엣지 컴퓨팅에 유용하다. 3, 시각적 이해의 이점: BEiT와 BEVT에서 논의된 것처럼 이산적인 토큰은 self-supervised 표현 학습의 사전 학습 대상으로 가치가 있는 것으로 나타났다. 또한 토큰을 모델 입력으로 사용하면 견고성과 일반화가 향상된다.
본 논문에서는 동영상과 이미지를 컴팩트한 이산적인 토큰으로 매핑하도록 설계된 동영상 토크나이저인 MAGVIT-v2를 소개한다. MAGVIT-v2는 VQ-VAE 프레임워크를 사용하는 SOTA 동영상 토크나이저인 MAGVIT를 기반으로 구축되었다. 본 논문은 두 가지 새로운 기술을 제안한다.
- 새로운 조회 없는 quantization 방법을 사용하면 언어 모델의 생성 품질을 향상시킬 수 있는 대규모 vocabulary 학습이 가능해진다.
- 생성 품질을 향상시킬 뿐만 아니라 공유 vocabulary를 사용한 이미지와 동영상 모두의 토큰화가 가능하도록 토크나이저를 수정하였다.
MAGVIT-v2는 MAGVIT의 생성 품질을 크게 향상시켜 공통 이미지 및 동영상 벤치마크에 대한 SOTA 기술을 확립했다. 또한 압축 품질이 MAGVIT과 현재 동영상 압축 표준인 HEVC보다 뛰어나며 차세대 동영상 코덱인 VVC와 동등한 수준이다. 마지막으로, 새로운 토큰은 MAGVIT에 비해 동영상 이해에 더 강력하다.
Method
1. Lookup-Free Quantizer
VQ-VAE 개발에 큰 진전이 있었지만 재구성 품질 개선과 생성 품질 간의 관계는 아직 잘 이해되지 않았다. 일반적인 오해는 재구성을 개선하는 것이 언어 모델 생성을 개선하는 것과 같다는 것이다. 예를 들어, vocabulary를 확대하면 재구성 품질이 향상될 수 있다. 그러나 이러한 개선은 vocabulary 크기가 작은 생성에만 적용되며, vocabulary가 너무 많으면 실제로 언어 모델의 성능이 저하될 수 있다.
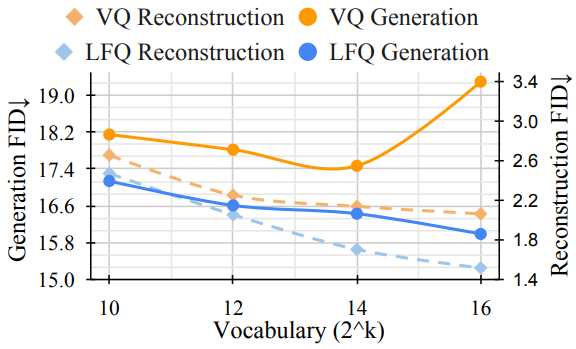
위 그래프에 점선으로 표시된 것처럼 재구성 FID(오른쪽 $y$축)는 vocabulary 크기($x$축)가 증가함에 따라 향상된다. 주황색 실선은 LM의 생성 품질(왼쪽 $y$축)을 나타낸다. 생성 FID는 처음에는 개선되지만 vocabulary가 많아지면 악화된다. 이는 시각적 생성을 위한 대부분의 언어 모델의 vocabulary 크기가 1,024~8,096인 이유이며, 이는 자연어 vocabulary의 크기(20만 이상)보다 훨씬 작다.
더 큰 코드북을 학습하는 간단한 방법은 vocabulary 크기를 늘릴 때 코드 임베딩 차원을 줄이는 것이다. 이 트릭은 이산적인 토큰의 표현 용량을 제한하여 대규모 vocabulary의 분포에 대한 학습을 촉진시킨다.
Lookup-Free Quantization (LFQ)
위의 관찰에 동기를 부여하여 VQ-VAE 코드북의 임베딩 차원을 0으로 줄인다. 코드북 $C \in \mathbb{R}^{K \times d}$는 크기가 $K$인 정수 집합 $\mathbb{C}$로 대체된다. VQ-VAE 모델에서 quantizer는 인코더 출력에 가장 가까운 코드북 entry를 계산할 때 코드북에서 모든 $K$개의 $d$차원 임베딩을 찾아야 한다. 여기서 $d$는 일반적으로 256이다. 이 새로운 디자인은 이러한 임베딩 조회의 필요성을 완전히 없애므로 이를 lookup-free quantization (LFQ)라고 부른다. LFQ는 언어 모델의 생성 품질에 도움이 되는 방식으로 vocabulary 크기를 늘릴 수 있다. 위 그래프의 파란색 곡선에서 볼 수 있듯이 vocabulary 크기가 증가함에 따라 재구성 FID와 생성 FID 모두 지속적으로 향상된다. 이는 현재 VQ-VAE 방법에서는 관찰되지 않는 속성이다.
다양한 LFQ 방법을 사용할 수 있지만 본 논문에서는 독립적인 코드북 차원과 binary latent를 가정하는 간단한 변형에 대해 설명한다. 구체적으로, LFQ의 latent space는 1차원 변수의 곱집합(Cartesian product)으로 분해된다.
\[\begin{equation} \mathbb{C} = {\times}_{i=1}^{\log_2 K} C_i \end{equation}\]주어진 feature 벡터 $z \in \mathbb{R}^{\log_2 K}$에 대하여 양자화된 표현 $q(z)$의 각 차원은 다음과 같이 얻는다.
\[\begin{equation} q(z_i) = C_{i, j}, \quad \textrm{where} \; j = \underset{k}{\arg \min} \| z_i - C_{i,k} \| \end{equation}\]여기서 $C_{i,j}$는 $C_i$의 $j$번째 값이다. \(C_i = \{-1, 1\}\)이면 argmin을 sign function으로 계산할 수 있다.
\[\begin{equation} q(z_i) = \textrm{sign} (z_i) = - \unicode{x1D7D9} \{z_i \le 0\} + \unicode{x1D7D9} \{ z_i > 0 \} \end{equation}\]LFQ를 사용하면 $q(z)$의 토큰 인덱스는 다음과 같다.
\[\begin{equation} \textrm{Index} (z) = \sum_{i=1}^{\log_2 K} \underset{k}{\arg \min} \| z_i - C_{i,k} \| \prod_{b=0}^{i-1} \vert C_b \vert = \sum_{i=1}^{\log_2 K} 2^{i-1} \unicode{x1D7D9} \{z_i > 0\} \end{equation}\]여기서 $\vert C_0 \vert = 1$은 가상의 기저(basis)를 설정한다.
저자들은 코드북 활용을 장려하기 위해 학습 중에 엔트로피 페널티를 추가하였다.
\[\begin{equation} \mathcal{L}_\textrm{entropy} = \mathbb{E} [H (q (z))] - H [\mathbb{E} (q (z))] \end{equation}\]이 페널티는 이미지 VQGAN 모델에 사용된 유사한 loss에서 영감을 얻었다. LFQ에서는 차원 간의 독립성을 고려하여
\[\begin{equation} H (q (z)) = \sum_{i=1}^{\log_2 K} H (q (z_i)) \end{equation}\]로 쓸 수 있다. $K > 2^{18}$인 경우 $H [\mathbb{E} (q (z))]$ 항은 직접 추정하면 메모리 제한에 걸릴 수 있으므로 차원의 sub-group으로 근사화될 수 있다.
2. Visual Tokenizer Model Improvement
이미지-동영상 공동 토큰화
시각적 토큰화의 바람직한 기능은 공유 코드북을 사용하여 이미지와 동영상을 토큰화하는 것이다. 그러나 3D CNN을 활용하는 MAGVIT 토크나이저는 시간적 receptive field로 인해 이미지를 토큰화하는 데 어려움을 겪는다.
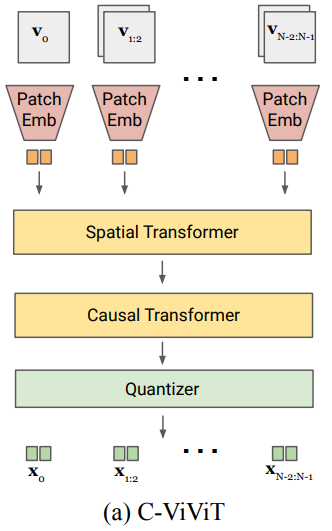
공동 이미지-동영상 토크나이저를 구축하려면 새로운 디자인이 필요하다. 저자들은 C-ViViT를 재검토하였다. 위 그림에서 볼 수 있듯이 C-ViViT는 causal temporal transformer block과 결합된 spatial transformer block을 사용한다. 이 접근 방식은 상당히 잘 수행되지만 두 가지 단점이 있다.
- CNN과 달리 위치 임베딩은 학습 중에 보지 못한 공간 해상도를 토큰화하기 어렵게 만든다.
- 3D CNN은 spatial transformer보다 더 나은 성능을 발휘하고 해당 패치의 더 나은 공간적 인과성을 갖는 토큰을 생성한다.
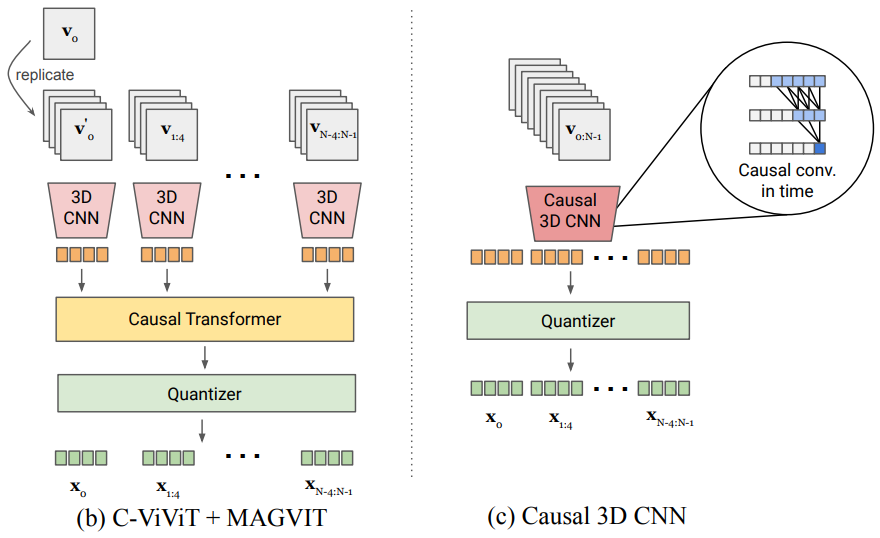
이러한 단점을 해결하기 위해 저자들은 두 가지 그럴듯한 디자인을 살펴보았다. 왼쪽 그림은 C-ViViT와 MAGVIT를 결합한 것이다. 시간 압축 비율을 4로 가정하면 3D CNN은 causal transformer 전에 프레임 4개의 블록을 처리한다. 오른쪽 그림은 일반적인 3D CNN을 대체하기 위해 시간적으로 인과적인 casual 3D CNN을 사용한 것이다. 구체적으로, 커널 크기가 $(k_t, k_h, k_w)$인 일반 3D convolution layer에 대한 시간 패딩 방식은 입력 프레임 이전의 $\lfloor \frac{k_t - 1}{2} \rfloor$개의 프레임과 이후의 $\lfloor \frac{k_t}{2} \rfloor$개의 프레임을 포함한다. 반면, causal 3D convolution layer는 입력 이전의 $k_t - 1$개의 프레임을 채우고 이후에는 아무것도 채우지 않으므로 각 프레임의 출력은 이전 프레임에만 의존한다. 결과적으로 첫 번째 프레임은 항상 다른 프레임과 독립적이므로 모델이 단일 이미지를 토큰화할 수 있다.
Stride $s$를 사용한 시간적 서브샘플링은 $1 + st$개의 프레임을 $1 + t$개의 프레임으로 매핑하여 $s \times$ 다운샘플링에 충분하다. 일반적인 $s \times$ 업샘플링 후에 처음 $s - 1$개의 결과 프레임을 삭제하여 $1 + t$개의 프레임을 $1 + st$개의 프레임에 매핑하고 단일 이미지의 토큰화를 허용한다.
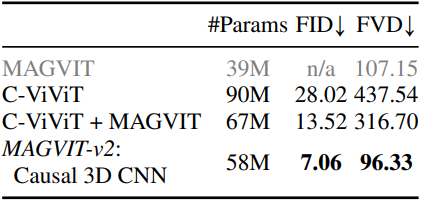
위 표는 UCF-101에서 디자인들을 비교한 표이며, causal 3D CNN이 가장 성능이 좋은 것으로 나타났다.
아키텍처 수정
저자들은 causal 3D CNN을 사용하는 것 외에도 MAGVIT 모델을 개선하기 위해 몇 가지 다른 아키텍처 수정을 수행했다.
- 학습된 커널을 활용하기 위해 인코더 다운샘플러를 average-pooling에서 stride convolution으로 변경하고 디코더 업샘플러를 nearest resizing 후 depth-to-space 연산자를 사용한 convolution으로 교체한다.
- 처음 몇 개의 인코더 블록에서 마지막 인코더 블록까지 시간적 다운샘플링을 연기한다.
- Discriminator의 다운샘플링 레이어는 3D blur pooling을 활용하여 shift invariance를 장려한다.
- 디코더의 각 해상도에서 residual block 앞에 adaptive group normalization layer 하나를 추가하여 양자화된 latent를 제어 신호로 전달한다.
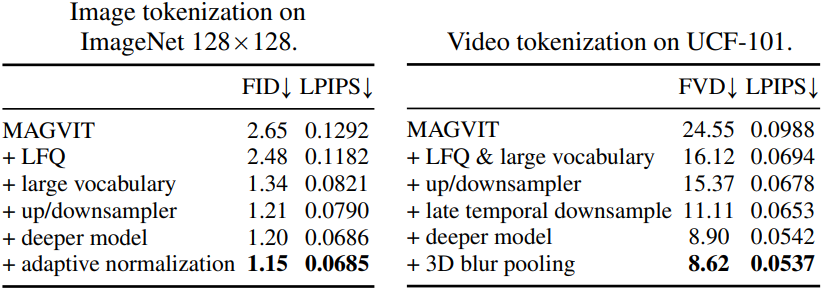
위 표는 아키텍처 수정 사항에 대한 ablation study 결과이다.
효율적인 예측을 위한 token factorization
출력 토큰을 언어 모델에 공급하여 동영상을 생성할 수 있다. 대규모 vocabulary에서 예측하는 소규모 transformer를 지원하기 위해 LFQ 토큰의 latent space를 동일한 subspace로 분해할 수 있다. 예를 들어, 크기 $2^{18}$의 코드북을 사용하여 예측하는 대신 크기가 각각 $2^9$인 두 개의 연결된 코드북에서 예측할 수 있다. 각 subspace 토큰을 별도로 임베딩하고 임베딩의 합을 transformer 입력에 대한 토큰 임베딩으로 사용한다. 가중치 묶음이 있는 출력 레이어의 경우 각 subspace에 대한 임베딩 행렬을 사용하여 별도의 예측 헤드로 logit을 얻는다.
Experiments
- 데이터셋
- 동영상 생성: Kinetics-600 (K600), UCF-101
- 이미지 생성: ImageNet
- 구현 디테일
- MAGVIT의 토크나이저 학습 세팅과 hyperparameter를 따름
- 기존 코드북 임베딩을 제거하고 $K = 2^{18}$ 크기의 코드북으로 LFQ를 사용
다음은 이전 연구들과 MAGVIT-v2의 재구성 품질을 시각적으로 비교한 것이다.

1. Visual Generation
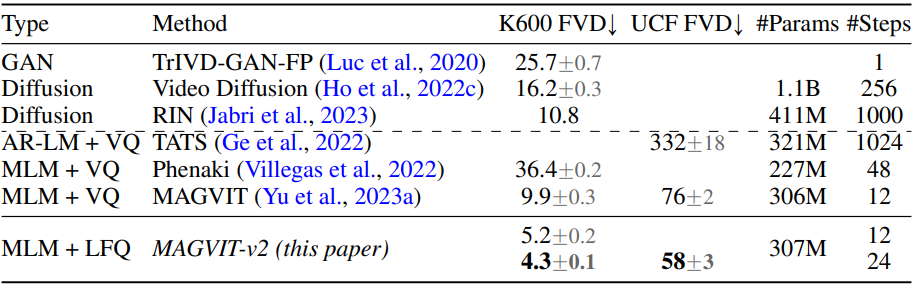
다음은 동영상 생성 결과를 비교한 표이다.
다음은 Kinetics-600에서의 프레임 예측 샘플들이다.

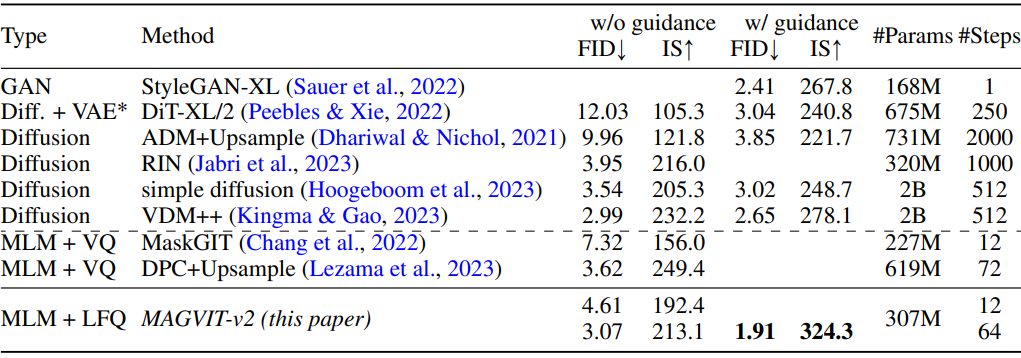
다음은 이미지 생성 결과를 비교한 표이다.
다음은 ImageNet 512$\times$512에서의 클래스 조건부 생성 샘플들이다.

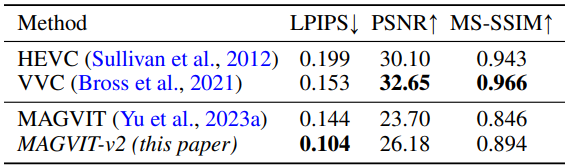
2. Video Compression
다음은 동영상 압축 성능을 비교한 표이다.
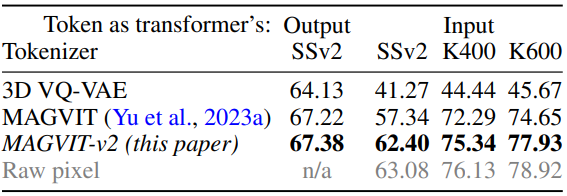
3. Video Understanding
다음은 동영상 인식 성능을 비교한 표이다. (분류 정확도 $\times 100$)