[논문리뷰] MAGVIT: Masked Generative Video Transformer
CVPR 2023. [Paper] [Page] [Github]
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, Lu Jiang
Carnegie Mellon University | Google Research | Georgia Institute of Technology
10 Dec 2022
Introduction
최근 몇 년 동안 GAN, diffusion model에서 ViT에 이르는 학습 프레임워크를 기반으로 이미지 및 동영상 콘텐츠 제작이 크게 발전했다. 본 논문은 최근 DALL·E와 같은 생성적 이미지 transformer의 성공과 기타 접근 방식에 영감을 받아 masked token modeling과 multi-task learning습을 활용하여 효율적이고 효과적인 동영상 생성 모델을 제안한다.
본 논문은 multi-task 동영상 생성을 위한 MAsked Generative VIdeo Transformer (MAGVIT)를 소개한다. 구체적으로 단일 MAGVIT 모델을 구축하고 학습하여 다양한 동영상 생성 task를 수행하고 SOTA 접근 방식에 대한 모델의 효율성, 효과, 유연성을 입증하였다.
MAGVIT는 동영상을 latent space의 시각적 토큰 시퀀스로 모델링하고 BERT로 마스킹된 토큰을 예측하는 방법을 학습한다. 제안된 프레임워크에는 두 가지 주요 모듈이 있다. 첫째, 3D quantization 모델을 설계하여 충실도가 높은 동영상을 저차원 공간적-시간적 매니폴드로 토큰화한다. 둘째, multi-task 동영상 생성을 위해 효과적인 masked token modeling (MTM) 기법을 제안한다. 이미지 이해나 이미지/동영상 합성에서 기존의 MTM과 달리 다변량 마스크를 사용하여 동영상 조건을 모델링하는 임베딩 방법을 제시하고 학습에서 그 효능을 보여준다.
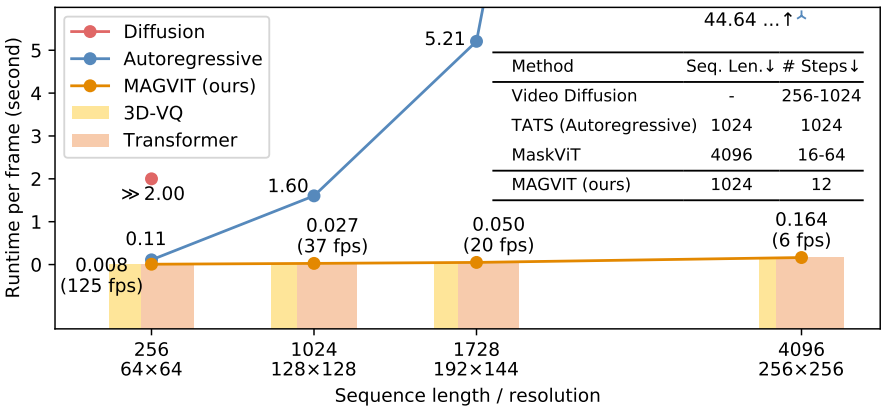
시각적 품질 외에도 MAGVIT의 동영상 합성은 매우 효율적이다. 예를 들어 MAGVIT는 12 step으로 16프레임 128$\times$128 동영상 클립을 생성하며 단일 TPUv4i 기기에서 0.25초가 걸린다. V100 GPU에서 MAGVIT의 기본 변형은 128$\times$128 해상도에서 37fps으로 실행된다. 동일한 해상도에서 비교할 때 MAGVIT는 video diffusion model보다 두 배 더 빠르다. 또한 MAGVIT는 autoregressive video transformer보다 60배 빠르고 최신 non-autoregressive video transformer보다 4-16배 더 효율적이다.
MAGVIT은 프레임 보간, 클래스 조건부 프레임 예측, inpainting, outpainting 등을 포함하여 단일 학습된 모델로 여러 동영상 생성 task에 유연하고 강력하다. 또한, MAGVIT은 객체를 이용한 동작, 자율주행, 다중 시점의 객체 중심 영상 등 다양하고 뚜렷한 시각적 도메인의 복잡한 장면과 모션 콘텐츠를 합성하는 방법을 학습한다.
Masked Generative Video Transformer
본 논문의 목표는 높은 품질과 inference 효율성을 갖춘 multi-task 동영상 생성 모델을 설계하는 것이며, masked token modeling (MTM)과 multi-task learning을 활용하는 ViT 프레임워크인 MAsked Generative VIdeo Transformer (MAGVIT)를 제안한다. MAGVIT는 프레임, 부분적으로 관찰된 동영상 볼륨, 클래스 identifier와 같은 task별 조건 입력에서 동영상을 생성한다.
프레임워크는 두 단계로 구성된다. 먼저 동영상을 이산 토큰으로 quantize하는 3D vector-quantized (VQ) 오토인코더를 학습한다. 두 번째 단계에서는 multi-task masked token modeling을 통해 동영상 transformer를 학습한다.
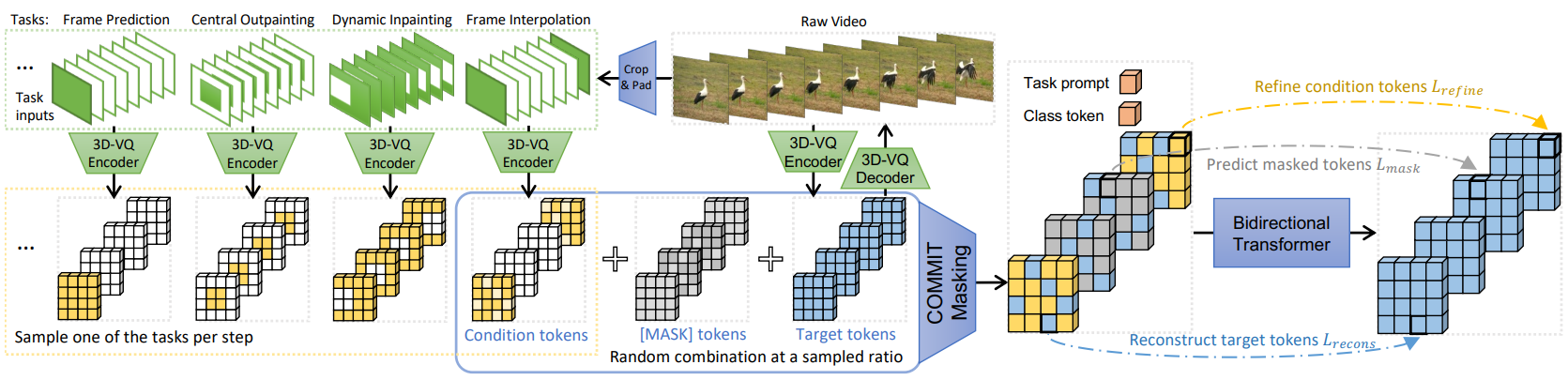
위 그림은 두 번째 단계의 학습을 보여준다. 각 학습 단계에서는 프롬프트 토큰으로 task 중 하나를 샘플링하고 task별 조건부 마스크를 얻고 주어진 마스킹된 입력의 모든 타겟 토큰을 예측하도록 transformer를 최적화한다. Inference하는 동안 task별 입력에 조건부로 토큰을 생성하기 위해 non-autoregressive 디코딩 방법을 적용한다.
1. Spatial-Temporal Tokenization
동영상 VQ 오토인코더는 이미지 VQGAN를 기반으로 한다. $V \in \mathbb{R}^{T \times H \times W \times 3}$을 $T$ 프레임의 동영상 클립이라고 하자. VQ 인코더는 동영상을 $f_{\mathcal{T}} : V \mapsto z \in \mathbb{Z}^N$으로 토큰화한다. 여기서 $\mathbb{Z}$는 코드북이다. 디코더 $f_\mathcal{T}^{-1}$는 latent 토큰을 다시 동영상 픽셀로 매핑한다.
VQ 오토인코더는 생성에 대한 품질 한계를 설정할 뿐만 아니라 토큰 시퀀스 길이를 결정하여 생성 효율성에 영향을 미치기 때문에 중요한 모듈이다. 기존 방법은 각 프레임에 독립적으로 (2D-VQ) 또는 supervoxel (3D-VQ)에 VQ 인코더를 적용한다. MAGVIT이 다른 동영상용 VQ 모델에 비해 유리한 성능을 발휘할 수 있도록 다양한 설계를 제안한다.
3D architecture
저자들은 다음과 같이 시간 역학을 모델링하기 위해 3D-VQ 네트워크 아키텍처를 설계하였다. VQGAN의 인코더와 디코더는 다운샘플링 (average pooling)과 업샘플링 (resize + convolution) 레이어에 의해 인터리브된 cascaded residual block으로 구성된다. 모든 2D convolution을 시간축을 사용하여 3D convolution으로 확장한다. 전체 다운샘플링 속도는 일반적으로 시간 차원과 공간 차원 간에 다르기 때문에 3D 다운샘플링 레이어는 인코더의 더 얕은 레이어에 나타나는 3D 및 2D 다운샘플링 레이어를 모두 사용한다. 디코더는 처음 몇 블록에서 2D 업샘플링 레이어를 사용하여 인코더를 미러링한 다음 3D 레이어를 미러링한다. 토큰은 해당 supervoxel과 상관관계가 있을 뿐만 아니라 non-local receptive field로 인해 다른 패치에 의존한다.
Inflation and padding
학습된 공간 관계를 전송하기 위해 매칭 아키텍처에서 2D-VQ의 가중치로 3D-VQ를 초기화하며, 이를 3D inflation이라고 한다. UCF-101과 같은 작은 데이터셋에 3D inflation을 사용한다. Convolution layer에 중앙 inflation 방법을 사용한다. 여기서 해당 2D 커널은 0으로 채워진 3D 커널의 시간적으로 중앙의 조각을 채운다. 다른 레이어의 파라미터는 직접 복사된다. 서로 다른 위치에서 동일한 콘텐츠에 대한 토큰 일관성을 개선하기 위해 convolution layer의 same (zero) 패딩을 0이 아닌 값으로 패딩하는 reflect 패딩으로 대체한다.
Training
각 프레임에 이미지 perceptual loss를 적용한다. 학습 안정성을 향상시키기 위해 LeCam regularization이 GAN loss에 추가되었다. StyleGAN의 discriminator 아키텍처를 채택하고 이를 3D로 확장한다. 이러한 구성 요소를 사용하면 VQGAN과 달리 본 논문의 모델은 처음부터 GAN loss로 안정적으로 학습된다.
2. Multi-Task Masked Token Modeling
MAGVIT에서는 다양한 조건의 동영상 생성 task에 대한 학습을 용이하게 하기 위해 다양한 마스킹 체계를 채택한다. 조건은 inpainting/outpainting을 위한 공간 영역이거나 프레임 예측/보간을 위한 몇 프레임일 수 있다. 이러한 부분적으로 관찰된 동영상 조건을 내부 조건 (interior condition)이라고 한다.
저자들은 내부 조건의 영역에 해당하는 토큰을 직접 마스크 해제하는 것이 최선이 아니라고 주장한다. Tokenizer의 non-local receptive field는 ground-truth 정보를 마스킹되지 않은 토큰으로 유출하여 문제가 있는 비인과적 마스킹과 잘못된 일반화로 이어질 수 있다.
본 논문은 COnditional Masked Modeling by Interior Tokens (COMMIT)이라는 방법을 제안하여 손상된 시각적 토큰 내부에 내부 조건을 포함시킨다.
Training
각 학습 예제에는 동영상 $V$와 선택적 클래스 주석 $c$가 포함된다. 타겟 시각적 토큰은 3D-VQ에서 $z = f_\mathcal{T} (V)$로 가져온다. 각 단계에서 task 프롬프트 $\rho$를 샘플링하고 task별 내부 조건 픽셀을 얻고 $V$와 동일한 모양으로 $\tilde{V}$에 패딩하고 조건 토큰 $\tilde{z} = f_\mathcal (\tilde{V})$를 얻는다.
샘플링된 마스킹 비율에서, 타겟 토큰 $z_i$를 무작위로 대체한다. $z_i$의 해당 supervoxel에 조건 픽셀이 포함된 경우 조건 토큰 \(\tilde{z}_i\)로 대체하고, 포함되지 않은 경우 특수 토큰 [MASK]로 대체한다. 다변량 조건부 마스크 $m(\cdot \vert \tilde{z})$를 다음과 같이 계산한다.
\[\begin{equation} m (z_i \vert \tilde{z}_i) = \begin{cases} \tilde{z}_i & \quad \textrm{if} \; s_i \le s^\ast \wedge \neg \textrm{ispad} (\tilde{z}_i) \\ [\textrm{MASK}] & \quad \textrm{if} \; s_i \le s^\ast \wedge \textrm{ispad} (\tilde{z}_i) \\ z_i & \quad \textrm{if} \; s_i > s^\ast \end{cases} \end{equation}\]여기서 $s_i$와 $s^\ast$는 토큰별 마스크 점수와 cut-off 점수이다. \(\textrm{ispad} (\tilde{z}_i)\)는 $\tilde{V}$에서 \(\tilde{z}_i\)의 해당 supervoxel에 패딩만 포함되어 있는지 여부를 반환한다.
위 식은 COMMIT가 내부 조건을 손상된 시각적 토큰으로 binary mask에 대한 prior $p_{\mathcal{U}}$ 대신 새로운 분포 $p_{\mathcal{M}}$을 따르는 다변량 마스크 $m$에 포함함을 나타낸다. 손상된 토큰 시퀀스 $\bar{z} = m(z \vert \tilde{z})$를 입력으로 사용하면 multi-task 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} (V; \theta) = \mathbb{E}_{\rho, \hat{V}, m \sim p_\mathcal{M}} [\sum_i -\log p_\theta (z_i \vert [\rho, c, \bar{z}])] \end{equation}\]위 식의 loss를 세 부분으로 분해할 수 있다.
- \(\mathcal{L}_\textrm{refine}\): Task별 조건 토큰을 정제
- \(\mathcal{L}_\textrm{mask}\): 마스킹된 토큰을 예측
- \(\mathcal{L}_\textrm{recons}\): 타겟 토큰을 재구성
간단하게 하기 위해 $\bar{c} = [\rho, c, \bar{z}]$라고 하면 목적 함수는 다음과 같이 분해할 수 있다.
\[\begin{equation} \sum_i -\log p_\theta (z_i \vert [\rho, c, \bar{z}]) = \underbrace{\sum_{\bar{z}_i = \tilde{z}_i} - \log p_\theta (z_i \vert \bar{c})}_{\mathcal{L}_\textrm{refine}} + \underbrace{\sum_{\bar{z}_i = [\textrm{MASK}]} - \log p_\theta (z_i \vert \bar{c})}_{\mathcal{L}_\textrm{mask}} + \underbrace{\sum_{\bar{z}_i = z_i} - \log p_\theta (z_i \vert \bar{c})}_{\mathcal{L}_\textrm{recons}} \end{equation}\]\(\mathcal{L}_\textrm{mask}\)는 BERT의 MTM loss와 동일하다. \(\mathcal{L}_\textrm{recons}\)는 때때로 regularizer로 사용되며 \(\mathcal{L}_\textrm{refine}\)은 COMMIT에서 도입한 새로운 성분이다.
COMMIT 방법은 세 가지 측면에서 multi-task 동영상 생성을 용이하게 한다.
- 모든 내부 조건에 대해 올바른 인과적 마스킹을 제공한다.
- 임의의 영역 볼륨의 다양한 조건에 대해 고정 길이 시퀀스를 생성하여 패딩 토큰이 필요하지 않기 때문에 학습 및 메모리 효율성을 향상시킨다.
- SOTA multi-task 동영상 생성 결과를 달성한다.
Video generation tasks
저자들은 각 task가 다른 내부 조건과 마스크를 갖는 multi-task 동영상 생성을 위하여 10가지 task를 고려하였다.
- 프레임 예측 (FP)
- 프레임 보간 (FI)
- 중앙 outpainting (OPC)
- 세로 outpainting (OPV)
- 가로 outpainting (OPH)
- 동적 outpainting (OPD)
- 중앙 inpainting (IPC)
- 동적 inpainting (IPD)
- 클래스 조건부 생성 (CG)
- 클래스 조건부 프레임 예측 (CFP)
Inference

Non-autoregressive 디코딩 방법을 사용하여 $K$ step (ex. 12)으로 입력 조건에서 동영상 토큰을 생성한다. 각 디코딩 단계는 마스킹 비율이 점진적으로 감소하는 COMMIT 마스킹을 따른다. Algorithm 1은 inference 절차를 설명한다.
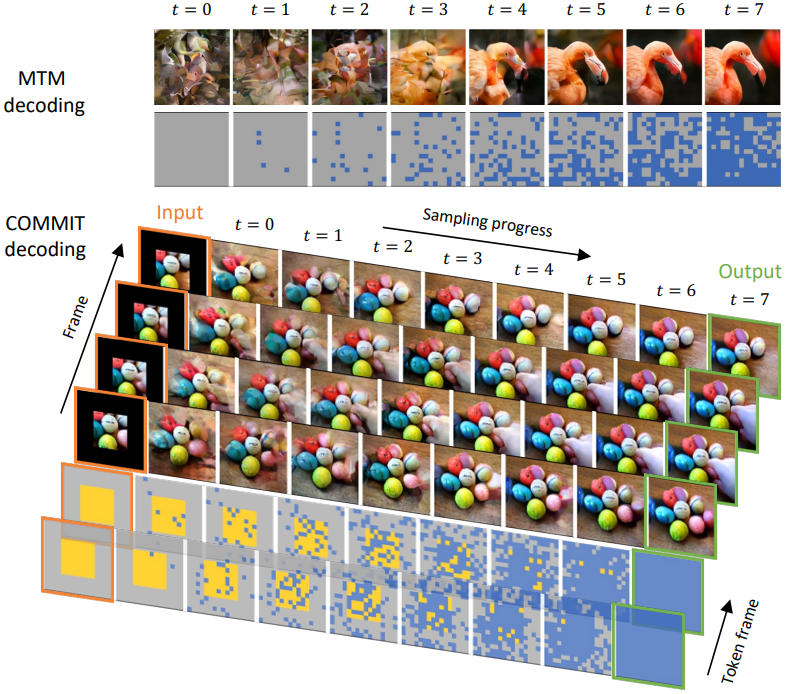
위 그림은 non-autoregressive 이미지 디코딩과 본 논문의 동영상 디코딩 절차를 비교한다. 모든 [MASK]에서 denoising을 수행하는 MTM 디코딩과 달리 COMMIT 디코딩은 내부 조건을 포함하는 다변량 마스크에서 시작된다. 이 마스크에 따라 Algorithm 1은 각 step에서 새로 생성된 토큰의 일부를 교체하여 출력 토큰에 대한 조건부 전환 프로세스를 수행한다. 결국 내부 조건 토큰이 정제되는 모든 토큰이 예측된다.
Experimental Results
- 데이터셋: UCF-101, BAIR Robot Pushing, Kinetics-600, SSV2
- 구현 디테일
- 128$\times$128 해상도의 16프레임 동영상을 생성 (BAIR은 64$\times$64)
- 3D-VQ 모델은 동영상을 4$\times$16$\times$16으로 quantize, 코드북 크기는 1024
- BERT transformer로 토큰 시퀀스 모델링 (task 프롬프트 1개, 클래스 토큰 1개, 시각적 토큰 1024개)
- 2가지 변형: 파라미터가 1.28억 개인 base (B) 모델, 파라미터가 4.64억 개인 large (L) 모델
1. Single-Task Video Generation
다음은 UCF-101에서의 생성 성능을 비교한 표이다.
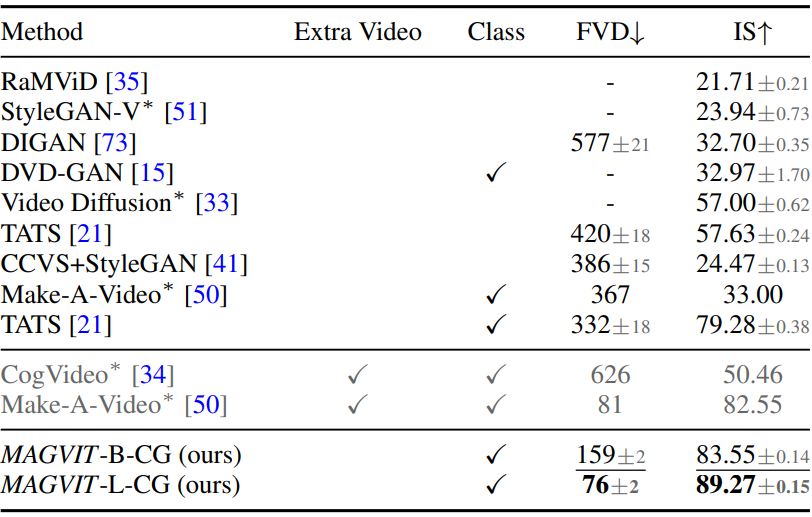
다음은 UCF-101에서의 클래스 조건부 생성 샘플들을 비교한 것이다.

다음은 BAIR과 Kinetics-600에서 프레임 예측 성능을 비교한 표이다.
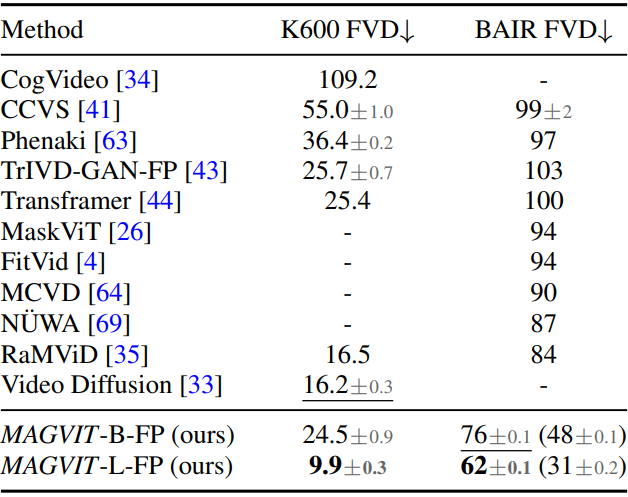
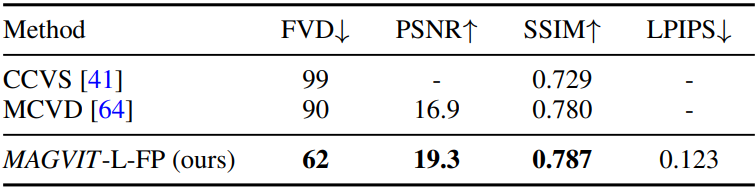
다음은 BAIR 프레임 예측에 대한 이미지 품질을 비교한 표이다.
2. Inference-Time Generation Efficiency
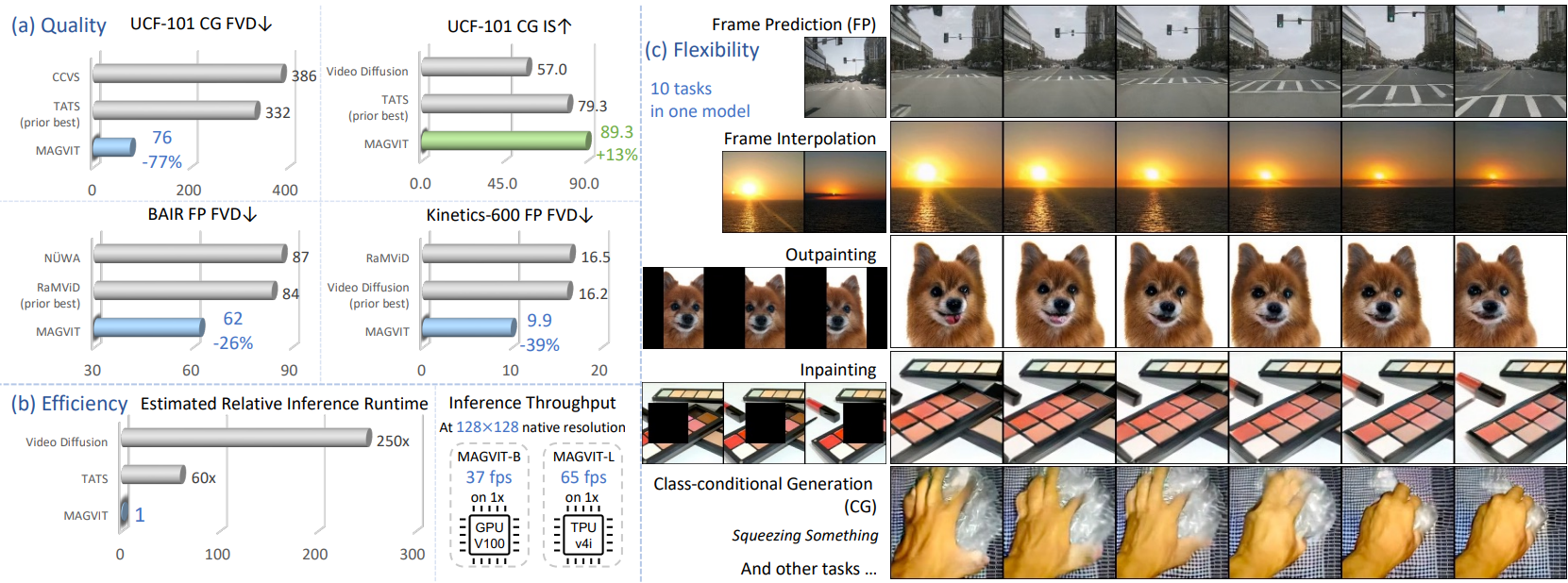
다음은 inference 시의 생성 효율성을 비교한 그래프이다.
3. Multi-task Video Generation
다음은 BAIR과 SSV2에서 FVD를 측정하여 multi-task 생성 성능을 비교한 표이다.

다음은 SSv2, nuScenes, Objectron, 웹 동영상에서 multi-task 생성 샘플들을 비교한 것이다.

4. Ablation Study
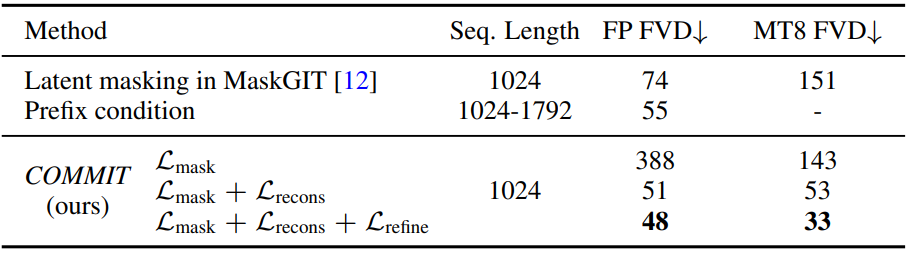
다음은 조건부 masked token modeling을 비교한 표이다.
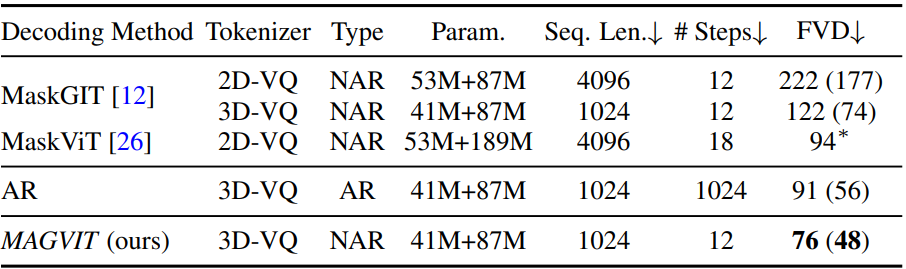
다음은 디코딩 방법들을 비교한 표이다.
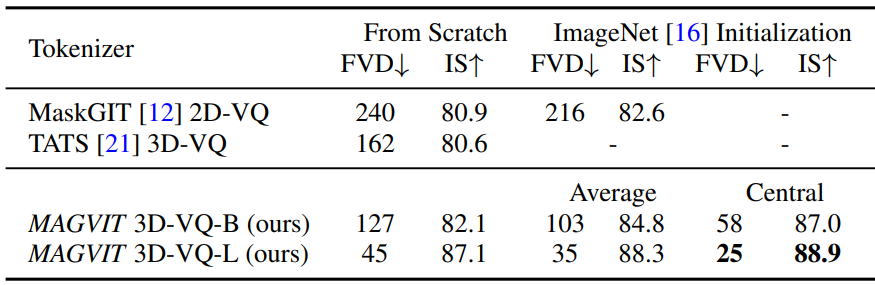
다음은 tokenizer 아키텍처와 초기화 방법들을 비교한 표이다.