[논문리뷰] MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
CVPR 2023. [Paper] [Github]
Tianhong Li, Huiwen Chang, Shlok Kumar Mishra, Han Zhang, Dina Katabi, Dilip Krishnan
MIT CSAIL | University of Maryland | Google Research
16 Nov 2022

Introduction
최근 몇 년 동안 우리는 생성 모델과 시각적 데이터의 표현 학습 모두에서 급속한 발전을 보았다. 생성 모델은 사실적인 이미지를 생성하는 데 있어 점점 더 뛰어난 성능을 보여주고 있으며, SOTA self-supervised 방법은 높은 semantic 수준에서 표현을 추출하여 linear probing 및 few-shot transfer과 같은 다양한 다운스트림 task에서 뛰어난 성능을 달성할 수 있다.
현재 이 두 가지 모델 계열은 일반적으로 독립적으로 학습된다. 직관적으로 생성 및 인식 task에는 데이터에 대한 시각적, 의미적 이해가 모두 필요하므로 단일 프레임워크에 결합하면 상호 보완적이어야 한다. 생성은 높은 수준의 semantic과 낮은 수준의 시각적 디테일을 모두 캡처되도록 하여 표현에 이점을 준다. 반대로 표현은 풍부한 semantic guidance를 제공하여 생성에 이점을 준다. 자연어 처리 연구자들은 이러한 시너지 효과를 관찰했다. BERT와 같은 프레임워크는 고품질 텍스트 생성과 feature 추출을 모두 갖추고 있다. 또 다른 예는 DALLE-2로, 사전 학습된 CLIP 표현을 기반으로 컨디셔닝된 latent를 사용하여 고품질 text-to-image 생성을 달성한다.
그러나 컴퓨터 비전에서는 현재 동일한 프레임워크에서 이미지 생성과 표현 학습을 통합하는 널리 채택된 모델이 없다. 이러한 통합은 이러한 task들 간의 구조적 차이로 인해 자명한 것이 아니다. 생성 모델링에서는 클래스 레이블, 텍스트 임베딩, 랜덤 noise와 같은 저차원 입력을 조건으로 고차원 데이터를 출력한다. 표현 학습에서는 고차원 이미지를 입력하고 다운스트림 task에 유용한 저차원의 컴팩트한 임베딩을 생성한다.
최근 많은 논문에서 masked image modeling (MIM)을 기반으로 한 표현 학습 프레임워크가 종종 매우 높은 마스킹 비율 (ex. 75%)을 사용하여 고품질 표현을 얻을 수 있음을 보여주었다. NLP에서 영감을 받은 이러한 방법은 입력에서 일부 패치를 마스킹하고 사전 학습 task는 이러한 마스킹된 패치를 예측하여 원본 이미지를 재구성하는 것이다. 사전 학습 후 task별 head를 인코더에 추가하여 linear probing 또는 fine-tuning을 수행할 수 있다.
본 연구의 주요 통찰력은 생성이 100% 마스킹된 이미지를 “재구성”하는 것으로 간주되는 반면 표현 학습은 0% 마스킹된 이미지를 “인코딩”하는 것으로 간주된다는 것이다. 따라서 MIM 사전 학습 중에 가변 마스킹 비율을 사용하여 통합 아키텍처를 활성화할 수 있다. 본 논문의 모델은 생성을 가능하게 하는 높은 마스킹 비율과 표현 학습을 가능하게 하는 낮은 마스킹 비율을 포괄하는 광범위한 마스킹 비율에 걸쳐 재구성하도록 학습되었다. 이 간단하지만 매우 효과적인 접근 방식을 사용하면 동일한 프레임워크, 즉 동일한 아키텍처, 학습 방식, loss function에서 생성 학습과 표현 학습을 원활하게 결합할 수 있다.
그러나 기존 MIM 방법과 가변 마스킹 비율을 직접 결합하는 것은 고품질 생성에 충분하지 않다. 왜냐하면 이러한 방법은 일반적으로 픽셀에 대한 단순 재구성 loss를 사용하여 출력이 흐릿해지기 때문이다. 예를 들어, 이러한 방법의 대표로서 MAE의 재구성 품질이 좋지 않다. 미세한 디테일과 질감이 누락된다. 다른 많은 MIM 방법에도 비슷한 문제가 존재한다.

본 논문에서는 이러한 격차를 해소하는 데 중점을 두었다. 본 논문은 사실적인 이미지를 생성하고 이미지에서 고품질 표현을 추출할 수 있는 프레임워크인 MAGE를 제안하였다. 사전 학습 중에 가변 마스킹 비율을 사용하는 것 외에도 입력이 픽셀인 이전 MIM 방법과 달리 MAGE의 입력과 재구성 대상은 모두 semantic 토큰이다. 이 디자인은 위에서 설명한 문제를 극복하여 생성 및 표현 학습을 모두 개선한다. 생성의 경우 위 그림과 같이 토큰 공간에서 연산하면 MAGE가 이미지 생성 작업을 반복적으로 수행할 수 있을 뿐만 아니라 MAGE가 가능한 모든 마스킹된 픽셀의 평균 대신 마스킹된 토큰의 확률 분포를 학습할 수 있어 다양한 생성 결과로 이어진다. 표현 학습의 경우 토큰을 입력 및 출력으로 사용하면 네트워크가 낮은 수준의 디테일을 잃지 않고 높은 semantic 수준에서 작동할 수 있으므로 기존 MIM 방법보다 훨씬 더 높은 linear probing 성능을 얻을 수 있다.
Method
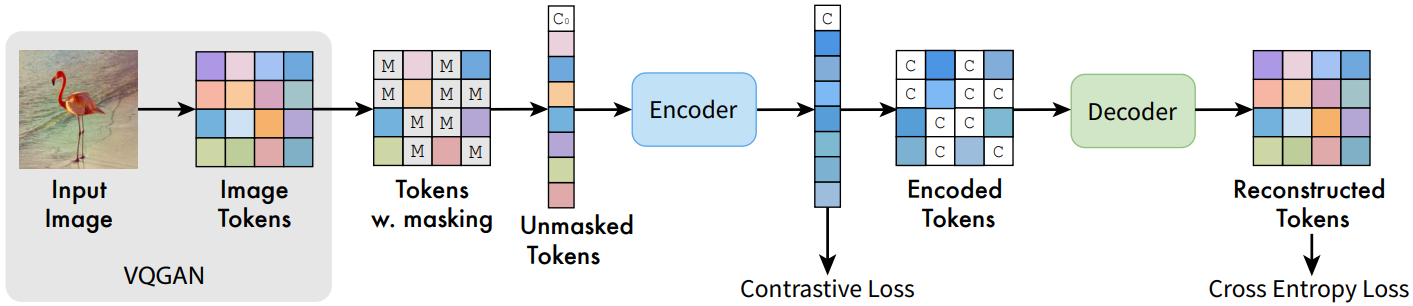
MAGE는 생성 task와 표현 학습을 위한 통합 프레임워크이다. 이러한 통합을 위해 먼저 사전 학습된 VQGAN 모델을 사용하여 입력 이미지를 semantic 토큰으로 양자화한다. 그런 다음 0.5~1 범위의 가변 마스킹 비율을 사용하여 일부 입력 토큰을 무작위로 마스킹하고 마스킹되지 않은 나머지 토큰에 인코더-디코더 transformer 아키텍처를 적용하여 마스킹된 토큰을 예측한다. 인코더의 출력에 SimCLR과 유사한 간단하면서도 효과적인 contrastive loss를 추가하여 학습된 표현의 분리성을 더욱 향상시킬 수 있다 (MAGE-C).
1. Pre-training
Tokenization
먼저 토크나이저를 사용하여 입력 이미지를 일련의 semantic 토큰으로 토큰화한다. 토크나이저는 VQGAN 모델의 첫 번째 단계와 동일한 설정을 사용한다. 이 토큰화 단계를 통해 모델은 픽셀 대신 semantic 토큰에서 작동할 수 있으며, 이는 생성 및 표현 학습 모두에 유용하다.
Masking Strategy
생성 모델링과 표현 학습 간의 격차를 더욱 해소하기 위해 가변 마스킹 비율을 사용하는 마스킹 전략을 채택한다. 구체적으로 먼저 중앙이 0.55이고 왼쪽이 0.5로, 오른쪽이 1로 잘린 가우시안 분포에서 마스킹 비율 $m_r$을 무작위로 샘플링한다. 토큰의 입력 시퀀스 길이가 $l$인 경우 $m_r \cdot l$개의 토큰을 무작위로 마스킹한다. 학습 가능한 마스크 토큰으로 교체한다. $m_r \ge 0.5$이므로 마스킹된 토큰에서 $0.5 \cdot l$개의 토큰을 무작위로 삭제한다. 마스킹된 토큰의 상당 부분을 삭제하면 전체 사전 학습 시간과 메모리 소비가 크게 줄어들면서 생성 및 표현 성능 모두에 도움이 된다. 이는 표현 성능에 대한 MAE의 결과와 일치한다.
Encoder-Decoder Design
입력 토큰을 마스킹하고 삭제한 후 학습 가능한 “가짜” 클래스 토큰 $[C_0]$를 입력 시퀀스에 concat한다. 그런 다음 concat된 시퀀스는 ViT 인코더-디코더 구조에 공급된다. 특히 ViT 인코더는 마스킹 및 삭제 후 토큰 시퀀스를 입력으로 가져와 이를 latent feature space로 인코딩한다. 디코딩하기 전에 먼저 인코더가 학습한 클래스 토큰 feature $[C]$를 사용하여 인코더의 출력을 전체 입력 길이로 패딩한다. MAE에서와 같이 클래스 토큰 위치는 입력 이미지의 글로벌 feature를 요약할 수 있다. 따라서 서로 다른 이미지에서 공유되는 학습 가능한 마스킹 토큰을 사용하는 대신 각 이미지에 특정한 토큰을 사용하여 인코더 출력을 채운다. 그런 다음 디코더는 패딩된 feature를 사용하여 원래 토큰을 재구성한다.
Reconstructive Training
\(Y = [y_i]_{i=1}^N\)을 토크나이저에서 얻은 latent 토큰이라 하자. 여기서 $N$은 토큰 시퀀스 길이다. \(M = [m_i]_{i=1}^N\)을 어떤 토큰이 마스킹되어야 하는지 결정하는 이진 마스크라 하자. 목적 함수는 마스킹되지 않은 토큰에서 마스킹된 토큰을 재구성하는 것이다. 따라서 ground-truth one-hot 토큰과 디코더의 출력 사이에 cross-entropy loss를 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{reconstructive} = - \mathbb{E}_{Y \in \mathcal{D}} (\sum_{\forall i, m_i = 1} \log p(y_i \vert Y_M)) \end{equation}\]여기서 $Y_M$은 $Y$의 마스킹되지 않은 토큰이고 $p(y_i \vert Y_M)$은 마스킹되지 않은 토큰을 조건으로 인코더-디코더 네트워크에서 예측한 확률이다. MAE를 따라 마스킹된 토큰의 loss만 최적화한다. 모든 토큰의 loss를 최적화하면 생성 및 표현 학습 성능이 모두 감소한다.
Contrastive Co-training
MIM 방법에 contrastive loss를 추가하면 표현 학습 성능이 더욱 향상될 수 있다. MAGE 프레임워크에서는 학습된 feature space의 linear probing을 향상시키기 위해 contrastive loss를 추가할 수도 있다. SimCLR과 유사하게 인코더 출력을 글로벌하게 average pooling하여 얻은 feature 위에 2-layer MLP를 추가한다. 그런 다음 MLP head의 출력에 InfoNCE loss를 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{contrastive} = - \frac{1}{B} \sum_{i=1}^B \log \frac{\exp(z_i^\top \cdot z_i^{+} / \tau)}{\sum_{j=1}^B \exp(z_i^\top \cdot z_j / \tau)} \end{equation}\]여기서 $z$는 2-layer MLP 이후의 정규화된 feature이고, $B$는 batch size이다. $\tau$는 temperature이다. Positive 쌍 $z_i$, $z_i^{+}$는 동일한 이미지의 두 augmented view에서 가져온 것이며 negative 샘플 $z_j$는 모두 동일한 batch에 있는 다른 샘플이다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{reconstructive} + \lambda \mathcal{L}_\textrm{contrastive} \end{equation}\]여기서 $\lambda = 0.1$은 두 loss 스케일의 균형을 맞춘다. 저자들은 color jitter, random grey scale, gaussian noise와 같이 contrastive learning에 일반적으로 사용되는 광범위한 augmentation을 사용하지 않았다. 이는 재구성 loss가 인코더가 지름길 솔루션을 학습하는 것을 방지하는 정규화 역할을 하기 때문이다. 본 논문의 접근 방식은 contrastive loss 없이도 생성 task와 표현 학습 모두에서 우수한 성능을 달성하며, contrastive loss를 통해 표현 학습 성능을 더욱 향상시킬 수 있다.
2. Post-training Evaluation
생성 모델 평가를 위한 이미지를 생성하기 위해 MaskGIT와 유사한 반복 디코딩 전략을 사용한다. 모든 토큰이 마스킹된 빈 이미지에서 시작한다. 각 iteration에서 모델은 먼저 나머지 마스킹된 토큰에 대한 토큰을 예측한다. 그런 다음 예측된 토큰 중 일부를 샘플링하고 해당 마스킹된 토큰을 이러한 샘플링된 예측 토큰으로 대체한다. 이 떄, 예측 확률이 더 높은 토큰은 샘플링될 확률이 더 높다. 각 iteration에서 교체될 마스킹된 토큰의 수는 코사인 함수를 따른다. 즉, 초기 반복에서는 더 적은 수의 마스킹된 토큰을 교체하고 이후 반복에서는 더 많은 마스킹된 토큰을 교체한다. 저자들은 이미지를 생성하기 위해 총 20 step을 사용하였다. 표현 학습의 경우 ViT 인코더에서 출력된 feature를 글로벌하게 average pooling된 feature를 분류 head의 입력 feature로 사용한다.
Results
- 데이터셋: ImageNet-1K
- 구현 디테일
- 이미지 해상도: 256$\times$256
- 토큰 시퀀스 길이: 16$\times$16 = 256
- Augmentation: 강한 random crop과 resize (0.2 ~ 1), random flipping
- backbone: ViT-B, ViT-L
- optimizer: AdamW ($\beta_1$ = 0.9, $\beta_2$ = 0.95)
- weight decay: 0.05
- epochs: 1600
- batch size: ViT-B는 2048, ViT-L은 4096
- learning rate: $1.5 \times 10^{-4}$, cosine schedule (80-epoch warmup)
- dropout: 0.1
1. Image Generation
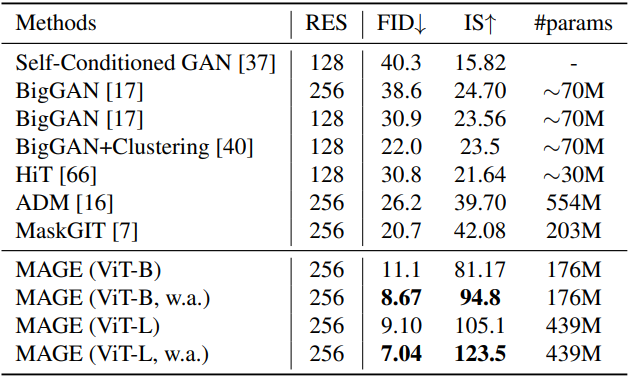
다음은 클래스 조건부 생성에 대하여 SOTA 생성 모델들과 비교한 표이다. (ImageNet 256$\times$256)
다음은 MAGE (ViT-L)에 의해 생성된 이미지들이다.

2. Image Classification
Linear Probing
다음은 ImageNet-1K에서의 linear probing의 top-1 정확도를 비교한 표이다.
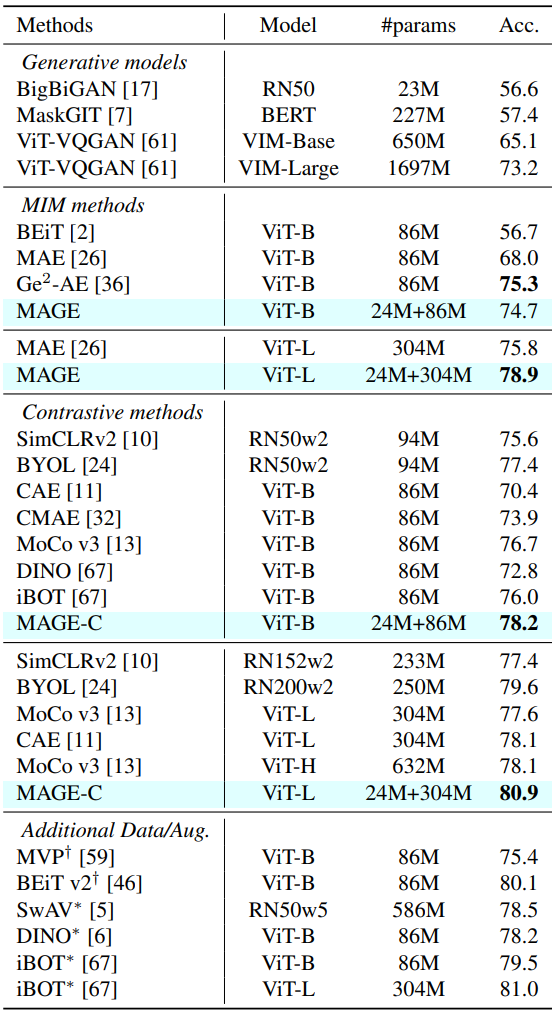
Linear Probing
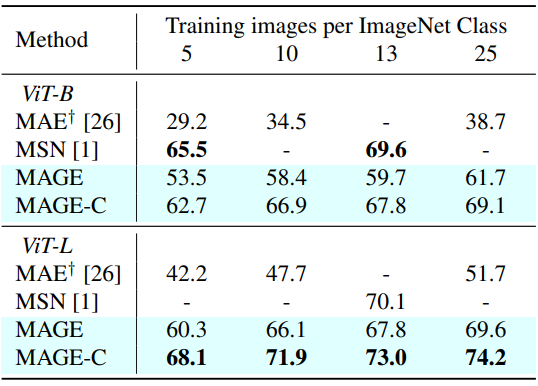
다음은 ImageNet-1K에서의 few-shot 성능을 비교한 표이다.
Transfer Learning
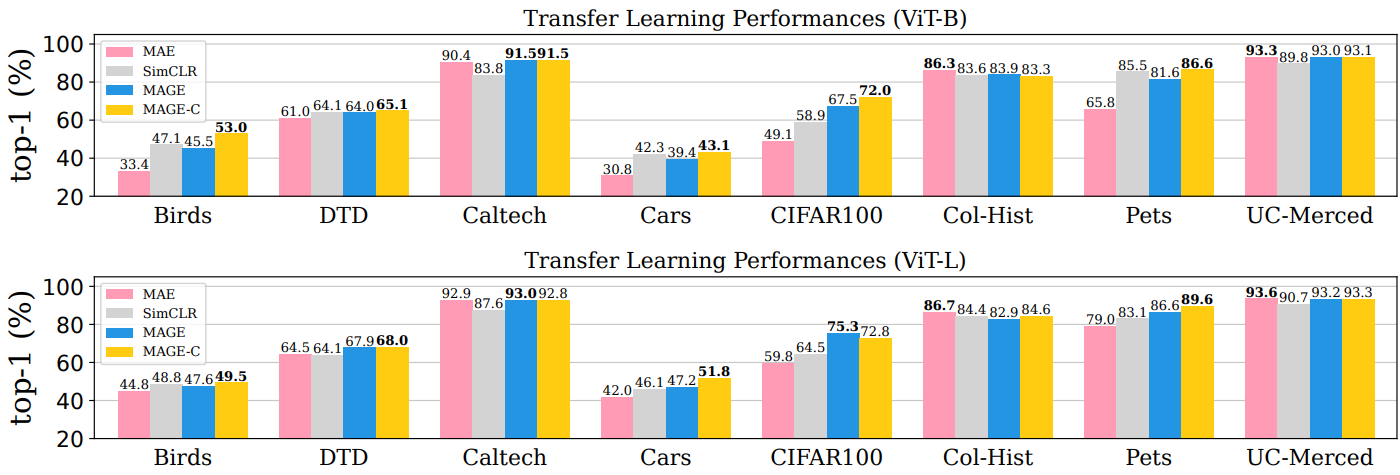
다음은 ImageNet-1K에서의 transfer learning 성능을 비교한 표이다.
Fine-tuning
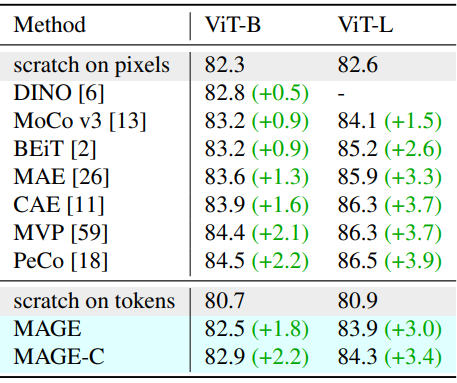
다음은 ImageNet-1K에서의 fine-tuning 성능을 비교한 표이다.
3. Analysis
Masking Design
다음은 MAGE의 linear probing의 top-1 정확도와 클래스 조건부 생성 FID를 다양한 마스킹 비율 분포에서 비교한 표이다.

Tokenization
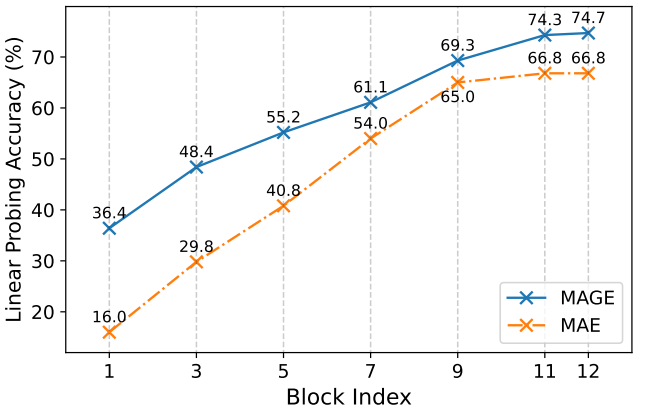
다음은 ViT-B의 여러 transformer 블록에서 MAE와 MAGE의 linear probe 정확도를 비교한 그래프이다.
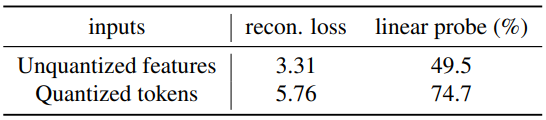
다음은 양자화되지 않은 feature와 양자화된 토큰을 입력으로 받을 때의 reconstruction loss와 linear probe 정확도를 비교한 표이다.