[논문리뷰] Masked Autoencoders Are Scalable Vision Learners (MAE)
arXiv 2021. [Paper] [Github]
Kaiming He | Xinlei Chen | Saining Xie | Yanghao Li | Piotr Dollar | Ross Girshick
Facebook AI Research (FAIR)
11 Nov 2021
Introduction
하드웨어의 급속한 발전에 힘입어 오늘날의 모델은 백만 개의 이미지를 쉽게 overfitting할 수 있으며 수억 개의 레이블이 지정된 이미지를 요구하기 시작하였다. 이러한 데이터에 대한 욕구는 self-supervised 사전 학습을 통해 자연어 처리에서 성공적으로 해결되었다. GPT의 autoregressive 언어 모델링과 BERT의 masked autoencoding을 기반으로 하는 솔루션은 데이터의 일부를 제거하고 제거된 콘텐츠를 예측하는 방법을 학습한다. 이러한 방법을 통해 이제 천억 개 이상의 파라미터가 포함된 일반화 가능한 NLP 모델을 학습할 수 있다.
보다 일반적인 denoising autoencoder의 한 형태인 masked autoencoder의 아이디어는 자연스럽고 컴퓨터 비전에도 적용할 수 있다. 실제로 비전과 밀접하게 관련된 연구는 BERT보다 앞서 있었다. 그러나 BERT의 성공 이후 이 아이디어에 대한 상당한 관심에도 불구하고 비전의 오토인코딩 방법의 발전은 NLP에 뒤쳐져 있다. 저자들은 다음과 같이 질문한다.
Masked autoencoder이 비전과 언어 사이에 다른 점은 무엇인가?
저자들은 다음과 같은 관점에서 이 질문에 답하려고 한다.
- 최근까지 아키텍처가 달랐다. 비전에서 CNN은 지난 10년 동안 지배적이었다. Convolution은 일반적으로 일반 그리드에서 작동하며 마스크 토큰 또는 위치 임베딩과 같은 ‘indicator’를 CNN에 통합하는 것은 간단하지 않다. 그러나 이 아키텍처 간극은 Vision Transformers (ViT)의 도입으로 해결되었으며 더 이상 장애가 되지 않는다.
- 정보 밀도는 언어와 비전 사이에 다릅다. 언어는 매우 의미론적이고 정보 밀도가 높은 인간이 생성한 신호이다. 문장당 몇 개의 누락된 단어만 예측하도록 모델을 학습할 때 이 task는 정교한 언어 이해를 유도하는 것으로 보인다. 반대로 이미지는 공간 중복성이 큰 자연 신호이다. 예를 들어 누락된 패치는 개체나 장면에 대한 높은 수준의 이해가 거의 없는 인접 패치에서 복구할 수 있다. 이 차이를 극복하고 유용한 feature 학습을 장려하기 위해 컴퓨터 비전에서 랜덤 패치의 매우 많은 부분을 마스킹하는 간단한 전략이 잘 작동한다. 이 전략은 중복성을 크게 줄이고 낮은 수준의 이미지 통계를 넘어 전체적인 이해가 필요한 까다로운 self-supervisory task를 생성한다.
- Latent 표현을 다시 입력으로 매핑하는 오토인코더의 디코더는 텍스트와 이미지를 재구성하는 사이에서 다른 역할을 한다. 비전에서 디코더는 픽셀을 재구성하므로 그 출력은 일반적인 인식 작업보다 의미 수준이 낮다. 이는 디코더가 풍부한 의미론적 정보를 포함하는 누락된 단어를 예측하는 언어와 대조된다. BERT에서 디코더는 사소할 수 있지만 이미지의 경우 디코더 설계가 학습된 latent 표현의 의미론적 수준을 결정하는 데 중요한 역할을 한다.
본 논문은 이 분석을 기반으로 시각적 표현 학습을 위한 간단하고 효과적이며 확장 가능한 형태의 Mmasked Autoencoder (MAE)를 제시한다. MAE는 입력 이미지에서 랜덤 패치를 마스킹하고 픽셀 공간에서 누락된 패치를 재구성한다. MAE는 비대칭 인코더-디코더 디자인을 가지고 있다. 인코더는 (마스크 토큰 없이) 보이는 패치의 부분집합에서만 작동하며, 디코더는 가볍고 마스크 토큰과 함께 latent 표현에서 입력을 재구성한다. 비대칭 인코더-디코더에서 마스크 토큰을 작은 디코더로 이동시키면 계산이 크게 줄어든다. 이 디자인에서 매우 높은 마스킹 비율 (ex. 75%)은 인코더가 패치의 작은 부분 (ex. 25%)만 처리하도록 허용하면서 정확도를 최적화한다. 이를 통해 전체 사전 학습 시간을 3배 이상 단축하고 마찬가지로 메모리 소비를 줄여 MAE를 대형 모델로 쉽게 확장할 수 있다.
Approach
Masked Autoencoder (MAE)는 부분 관찰을 통해 원래 신호를 재구성하는 간단한 오토인코딩 접근 방식이다. 모든 오토인코더와 마찬가지로 관찰된 신호를 latent 표현으로 매핑하는 인코더와 latent 표현에서 원래 신호를 재구성하는 디코더가 있다. 기존의 오토인코더와 달리 인코더가 관찰된 부분 신호 (마스크 토큰 없음)에서만 작동할 수 있도록 하는 비대칭 설계와 latent 표현과 마스크 토큰에서 전체 신호를 재구성하는 경량 디코더를 채택한다. 아래 그림은 본 논문의 아이디어를 보여준다.
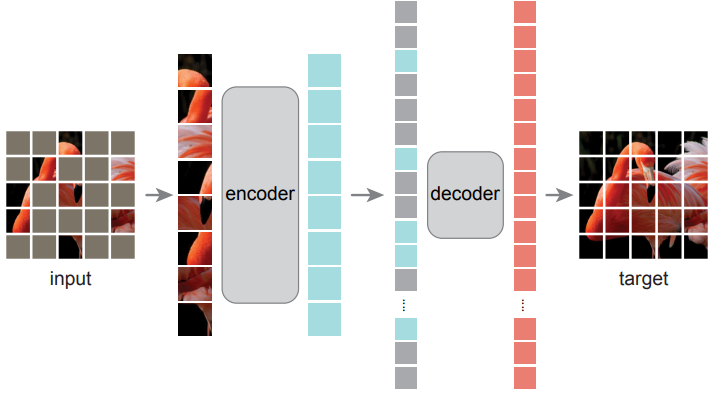
Masking
ViT에 따라 이미지를 겹치지 않는 패치로 나눈다. 그런 다음 패치의 부분집합을 샘플링하고 나머지 패치를 마스킹, 즉 제거한다. 샘플링 전략은 간단하다. 균일한 분포에 따라 교체 없이 랜덤 패치를 샘플링한다. 이를 단순히 “랜덤 샘플링”이라고 부른다.
마스킹 비율 (즉, 제거된 패치의 비율)이 높은 랜덤 샘플링은 중복성을 크게 제거하므로 눈에 보이는 인접 패치에서 외삽으로 쉽게 해결할 수 없는 task를 생성한다. 균일한 분포는 잠재적인 중심 편향 (즉, 이미지 중심 근처에 마스킹된 패치가 더 많음)을 방지한다. 마지막으로 매우 희박한 입력은 효율적인 인코더를 설계할 수 있는 기회를 제공한다.
MAE encoder
인코더는 ViT이지만 가려지지 않은 패치에만 적용된다. 표준 ViT에서와 마찬가지로 인코더는 위치 임베딩이 추가된 linear projection으로 패치를 포함하고 일련의 Transformer 블록을 통해 결과 집합을 처리한다. 그러나 인코더는 전체 집합의 작은 부분집합 (ex. 25%)에서만 작동한다. 마스킹된 패치는 제거되며, 마스크 토큰이 사용되지 않는다. 이를 통해 컴퓨팅과 메모리의 일부만으로 매우 큰 인코더를 학습할 수 있다. 전체 세트는 경량 디코더에 의해 처리된다.
MAE decoder
MAE 디코더에 대한 입력은 ‘
- 인코딩된 보이는 패치
- 마스크 토큰
으로 구성된 전체 토큰 집합이다. 각 마스크 토큰은 예측할 누락된 패치의 존재를 나타내는 공유되고 학습된 벡터이다. 이 전체 세트의 모든 토큰에 위치 임베딩을 추가한다. 위치 임베딩이 없으면 마스크 토큰은 이미지에서 자신의 위치에 대한 정보를 갖지 못한다. 디코더에는 또 다른 일련의 Transformer 블록이 있다.
MAE 디코더는 이미지 재구성 task를 수행하기 위해 사전 학습 중에만 사용된다. 이미지 표현을 생성하는 데는 인코더만 사용된다. 따라서 디코더 아키텍처는 인코더 디자인과 독립적인 방식으로 유연하게 설계될 수 있다. 저자들은 인코더보다 더 좁고 얕은 아주 작은 디코더로 실험하였다. 예를 들어, 기본 디코더는 인코더에 비해 토큰당 계산이 10% 미만이다. 이 비대칭 설계를 통해 전체 토큰 세트는 경량 디코더에서만 처리되므로 사전 학습 시간이 크게 단축된다.
Reconstruction target
MAE는 각 마스킹된 패치의 픽셀 값을 예측하여 입력을 재구성한다. 디코더 출력의 각 요소는 패치를 나타내는 픽셀 값의 벡터이다. 디코더의 마지막 레이어는 출력 채널 수가 패치의 픽셀 값 수와 동일한 linear projection이다. 디코더의 출력은 재구성된 이미지를 형성하도록 재구성된다. Loss function은 픽셀 공간에서 재구성된 이미지와 원래 이미지 사이의 평균 제곱 오차(MSE)를 계산한다. BERT와 유사하게 마스킹된 패치에서만 loss를 계산한다.
또한 저자들은 재구성 대상이 각 마스킹된 패치의 정규화된 픽셀 값인 버전도 연구하였다. 구체적으로, 패치에 있는 모든 픽셀의 평균과 표준편차를 계산하고 이를 사용하여 이 패치를 정규화한다. 재구성 대상으로 정규화 된 픽셀을 사용하면 실험에서 표현 품질이 향상된다.
Simple implementation
MAE 사전 학습은 효율적으로 구현될 수 있으며 중요한 것은 특수한 sparse 연산이 필요하지 않다는 것이다. 먼저 모든 입력 패치에 대한 토큰을 생성한다. 다음으로 토큰 목록을 임의로 섞고 마스킹 비율에 따라 목록의 마지막 부분을 제거한다. 이 프로세스는 인코더에 대한 토큰의 작은 부분집합을 생성하며 교체 없이 샘플링 패치와 동일하다. 인코딩 후 마스크 토큰 목록을 인코딩된 패치 목록에 추가하고 이 전체 목록을 언셔플링 (랜덤 셔플의 역 연산)하여 모든 토큰을 대상에 맞춘다. 디코더는 이 전체 목록에 적용된다 (위치 임베딩이 추가됨). 이 간단한 구현은 셔플링과 언셔플링 연산이 빠르기 때문에 무시할 수 있는 오버헤드를 도입한다.
Qualitative Results
다음은 ImageNet validation 이미지에 대한 결과이다. 왼쪽은 마스킹된 이미지, 중간은 MAE 재구성 결과, 오른쪽은 ground-truth이다.

다음은 COCO validation 이미지에 대한 결과이다.

다음은 ImageNet validation 이미지에 대하여 마스킹 비율에 따른 결과이다.

ImageNet Experiments
1. Main Properties
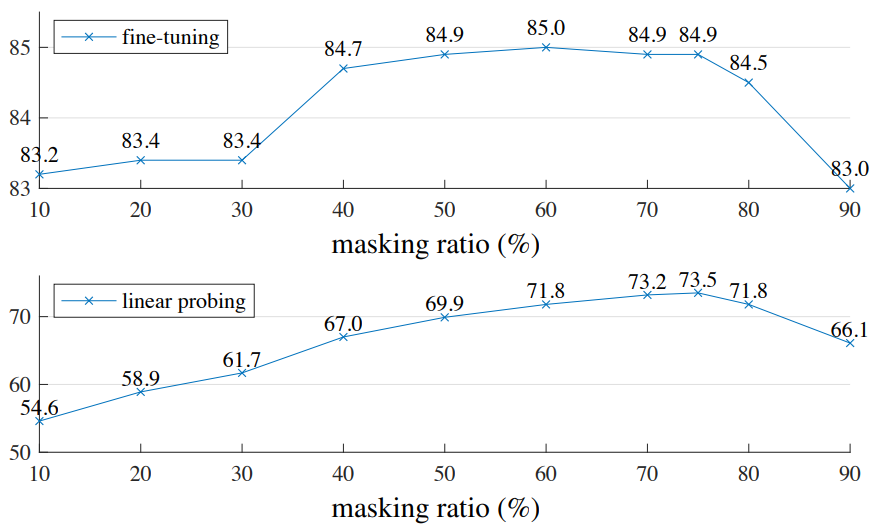
Masking ratio
다음은 마스킹 비율에 따른 fine-tuning 성능과 linear probing 성능이다.
Decoder design
다음은 디코더의 깊이(왼쪽)와 디코더 너비(오른쪽)에 따른 성능을 나타낸 표이다.
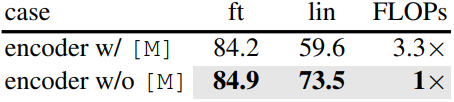
Mask token
다음은 마스크 토큰 유무에 따른 성능을 비교한 표이다.
Reconstruction target
다음은 재구성 대상에 따른 성능을 비교한 표이다.

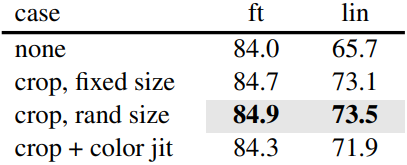
Data augmentation
다음은 data augmentation 방법에 따른 성능을 비교한 표이다.
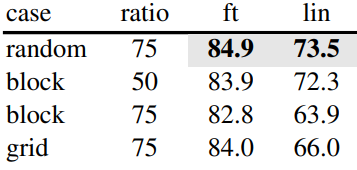
Mask sampling strategy
다음은 마스크 샘플링 전략에 따른 결과이다.

Training schedule
다음은 학습이 진행됨에 따라 fine-tuning 성능과 linear probing 성능의 변화를 나타낸 그래프이다.

2. Comparisons with Previous Results
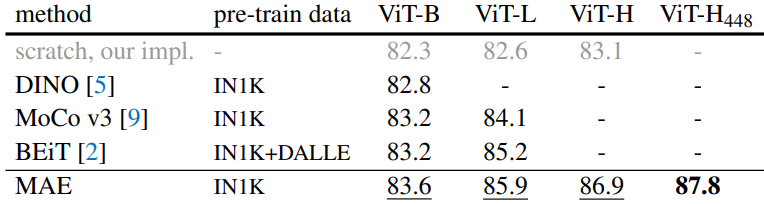
Comparisons with self-supervised methods
다음은 이전 방법들과 비교한 표이다.
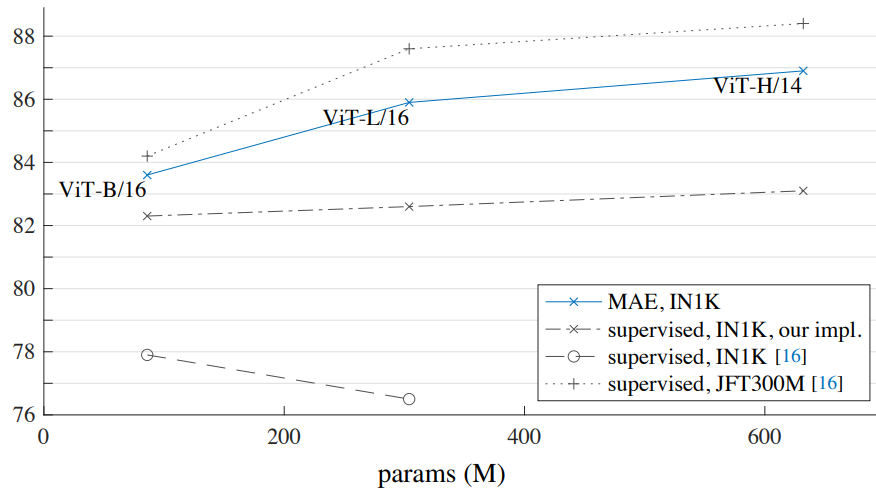
Comparisons with supervised pre-training
다음은 MAE 사전 학습과 supervised 사전 학습의 성능을 비교한 그래프이다.
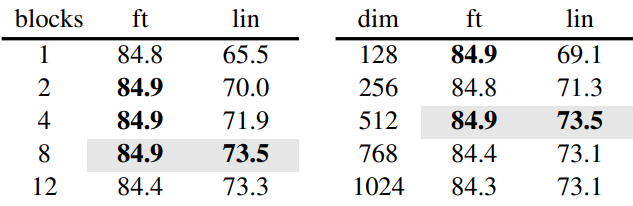
3. Partial Fine-tuning
다음은 fine-tuning한 Transformer 블록 수에 따른 결과이다.

Transfer Learning Experiments
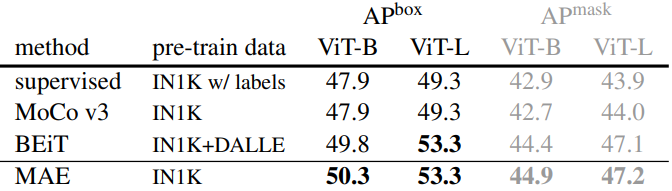
Object detection and segmentation
다음은 COCO 데이터셋에서의 object detection 및 segmentation 결과이다.
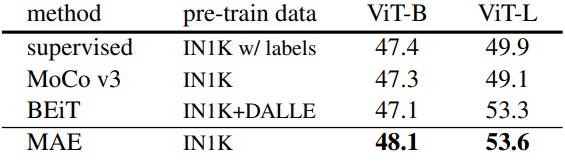
Semantic segmentation
다음은 ADE20K 데이터셋에서의 semantic segmentation 결과이다.
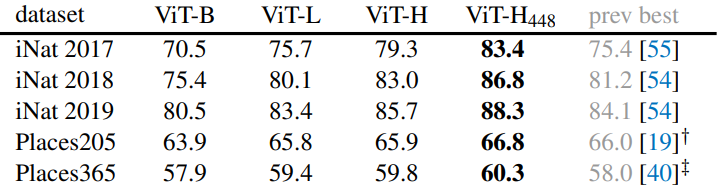
Classification tasks
다음은 iNaturalists와 Places 데이터셋에서의 classification 결과이다.
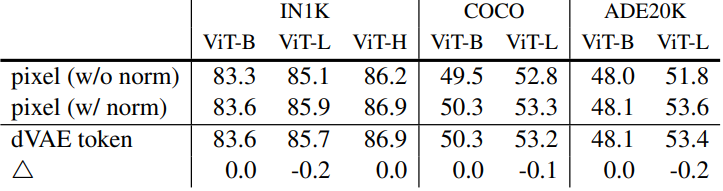
Pixels vs. tokens
다음은 MAE 재구성 대상으로 픽셀을 사용할 때와 토큰을 사용할 때의 결과이다. $\triangle$은 dVAE 토큰과 정규화된 픽셀의 결과 사이의 차이이다.