[논문리뷰] MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
CVPR 2024. [Paper] [Page] [Github]
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
University of Maryland, College Park | Meta | University of Central Florida
8 Apr 2024
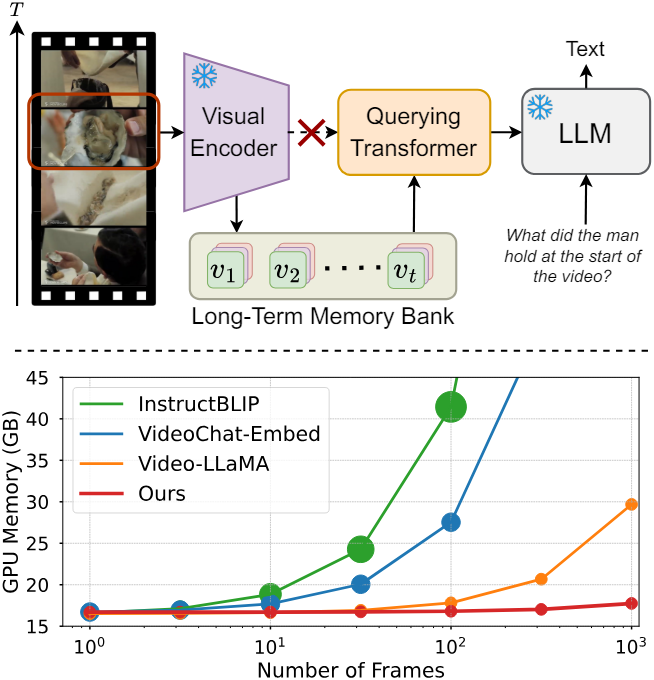
Introduction
최근에는 멀티모달 task에 LLM을 활용하는 데 대한 관심이 높아지고 있다. LLM을 비전 인코더와 통합함으로써 이미지와 동영상을 입력으로 사용할 수 있으며 captioning, 질문 답변, 분류, detection, segmentation과 같은 다양한 시각적 이해 task에서 놀라운 능력을 보여줄 수 있다.
동영상 입력을 처리하기 위해 기존 Large Multimodal Model (LMM)은 시간 축을 따라 concatenate된 각 프레임의 query 임베딩을 LLM에 직접 공급했다. 그러나 LLM의 제한된 컨텍스트 길이와 GPU 메모리 소비로 인해 처리할 수 있는 동영상 프레임 수가 제한된다. 예를 들어 LLaMA의 컨텍스트 길이 제한은 2048인 반면, LLaVA, BLIP-2와 같은 LMM은 이미지당 각각 256개, 32개의 토큰을 사용한다. 따라서 이 디자인은 동영상 길이가 훨씬 더 긴 경우 실용적이지 않으며 실현 가능하지 않다.
이러한 문제를 해결하기 위한 간단한 해결책은 Video-ChatGPT와 같이 시간 축을 따라 average pooling을 적용하는 것이다. 그러나 이는 명시적인 시간 모델링이 부족하여 성능이 저하된다. 다른 방법은 시간적 역학을 캡처하기 위해 동영상 모델링 구성 요소를 추가하는 것이다. 예를 들어, Video-LLaMA는 동영상 query transformer (Q-Former)를 추가로 사용한다. 그러나 이 디자인은 모델 복잡도를 추가하고 학습 파라미터를 증가시키며 온라인 동영상 분석에 적합하지 않다.
본 논문은 효율적이고 효과적인 long-term 동영상 모델링을 목표로 하는 Memory-Augmented Large Multimodal Model (MA-LMM)을 소개한다. MA-LMM은 visual feature를 추출하는 비전 인코더, 비전-텍스트 임베딩 공간을 정렬하는 Q-Former, 그리고 LLM으로 구성된 기존 LMM과 유사한 구조를 채택한다. 비전 인코더 출력을 Q-Former에 직접 공급하는 대신 동영상 프레임을 순차적으로 가져와 제안된 long-term memory bank에 동영상 feature를 저장하는 온라인 처리 접근 방식을 선택하였다. Memory bank는 긴 동영상 시퀀스에 대한 GPU 메모리 공간을 크게 줄이며, LLM의 제한된 컨텍스트 길이로 인해 발생하는 제약 조건을 효과적으로 해결한다.
본 논문의 핵심 기여는 과거 동영상 정보를 캡처하고 집계하는 long-term memory bank를 도입하는 것이다. Memory bank는 autoregressive 방식으로 과거 동영상 feature를 집계하며, 이는 후속 동영상 시퀀스 처리 중에 참조될 수 있다. 또한 memory bank는 Q-Former와 호환되도록 설계되어 long-term 모델링을 위한 attention 연산의 핵심이자 value 역할을 한다. 결과적으로 기존 LMM에 원활하게 통합되어 동영상의 long-term 모델링 능력을 활성화할 수 있다.
추가로 저자들은 효율성을 더욱 향상시키기 위해 입력 동영상 길이에 대해 memory bank의 길이를 일정하게 유지하는 memory bank 압축 방법을 제안하였다. 가장 유사한 인접 프레임의 feature를 선택하고 평균화함으로써 긴 동영상의 시간적 중복성을 크게 줄이면서 모든 시간적 정보를 보존할 수 있다.
Method
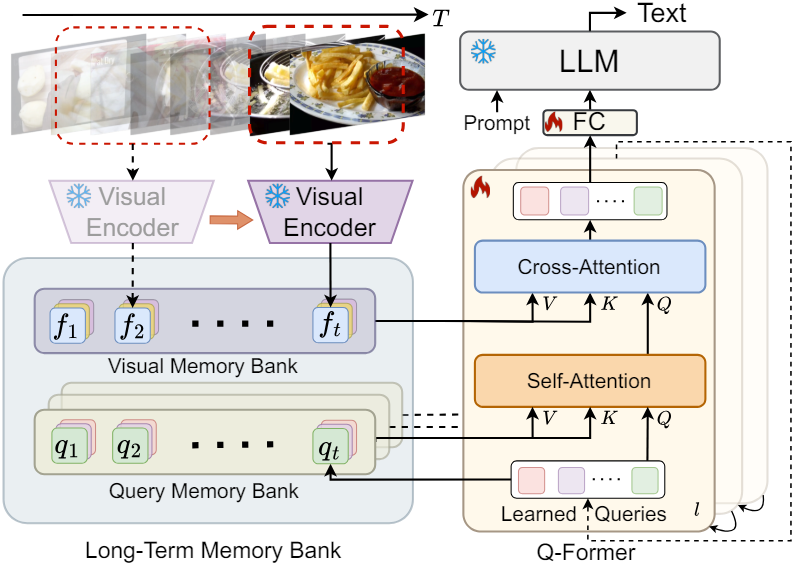
대부분의 동영상 이해 방법처럼 더 많은 프레임을 동시에 처리하는 대신 온라인 방식으로 동영상 프레임을 autoregressive하게 처리한다. 전체 모델 아키텍처는 세 부분으로 나눌 수 있다.
- 고정된 비전 인코더를 사용한 visual feature 추출
- 비전-텍스트 임베딩 공간을 정렬하기 위한 학습 가능한 Q-Former를 사용한 long-term 시간 모델링
- 고정된 LLM을 사용하여 텍스트를 디코딩
1. Visual Feature Extraction
이 디자인은 인간이 장기적인 시각적 정보를 처리하는 데 사용하는 인지 과정에서 영감을 얻었다. 인간은 광범위한 신호를 동시에 처리하는 대신 순차적 방식으로 신호를 처리하고, 이해를 위해 현재 시각적 입력을 과거 기억과 연관시키고, 나중을 위해 중요한 정보를 선택적으로 유지한다.
마찬가지로 MA-LMM은 동영상 프레임을 순차적으로 처리하여 새로운 프레임 입력을 long-term memory bank에 저장된 기록 데이터와 동적으로 연결하여 나중에 사용할 수 있도록 다른 정보들과 구별되는 정보만 보존한다. 이러한 선택적 보존은 동영상 이해에 대한 보다 지속 가능하고 효율적인 접근 방식을 촉진하며, 이를 통해 온라인 동영상 추론을 자동으로 지원할 수 있다.
$T$개의 동영상 프레임 시퀀스가 주어지면 각 동영상 프레임을 사전 학습된 비전 인코더에 전달하고 visual feature
\[\begin{equation} V = [v_1, \ldots, v_T], \quad v_t \in \mathbb{R}^{P \times C} \end{equation}\]를 얻는다. $P$는 각 프레임에 대한 패치 수이고 $C$는 추출된 프레임 feature에 대한 채널 차원이다. 그런 다음 position embedding layer $\textrm{PE}$를 통해 프레임 수준의 feature에 시간 순서 정보를 주입한다.
\[\begin{equation} f_t = v_t + \textrm{PE} (t), \quad f_t \in \mathbb{R}^{P \times C} \end{equation}\]2. Long-term Temporal Modeling
비전 임베딩을 텍스트 임베딩 공간에 맞추기 위해 BLIP-2의 Q-Former와 동일한 아키텍처를 사용한다. Q-Former는 학습된 query $z \in \mathbb{R}^{N \times C}$를 사용하여 동영상 시간 정보를 캡처한다. $N$은 학습된 query 수이고 $C$는 채널 차원이다. Q-Former는 각 이미지에 대해 32개의 토큰을 출력하는데, 이는 256개의 토큰을 생성하는 LLaVA보다 더 효율적이다. 각 Q-Former 블록은 두 개의 attention layer로 구성된다.
- Cross-attention layer: 고정된 비전 인코더에서 추출된 비전 임베딩과 상호 작용한다.
- Self-attention layer: 입력 query 내의 상호 작용을 모델링한다.
현재 프레임의 임베딩에만 관여하는 BLIP-2의 원래 Q-Former와 달리, 저자들은 과거 동영상 정보를 축적하고 두 attention layer에 대한 입력을 augmentation시키는 visual memory bank와 query memory bank로 구성된 long-term memory bank를 설계하였다.
Visual Memory Bank
Visual memory bank는 고정된 비전 인코더에서 추출된 각 프레임의 visual feature를 저장한다. 현재 timestep $t$에 대해 visual memory bank에는 과거 visual feature의 목록
\[\begin{equation} F_t = \textrm{Concat}[f_1, \ldots, f_t], \quad F_t \in \mathbb{R}^{tP \times C} \end{equation}\]가 포함된다. 입력 query $z_t$가 주어지면 visual memory bank는 key와 value로 작동한다.
\[\begin{equation} Q = z_t W_Q, \quad K = F_t W_K, \quad V = F_t W_V \end{equation}\]그런 다음 cross-attention 연산을 다음과 같이 적용한다.
\[\begin{equation} O = \textrm{Attn} (Q, K, V) = \textrm{Softmax} \bigg( \frac{QK^\top}{\sqrt{C}} \bigg) V \end{equation}\]이런 방식으로 캐싱된 visual memory bank를 통해 과거의 시각적 정보에 명시적으로 attention 계산을 할 수 있다. Q-Former의 모든 cross-attention layer는 동일한 visual feature를 다루기 때문에 모든 Q-Former 블록에서 공유되는 visual memory bank는 하나만 있다.
Query Memory Bank
정적인 visual feature를 저장하는 고정 visual memory bank와 달리 query memory bank는 각 timestep의 입력 query를 축적한다.
\[\begin{equation} Z_t = \textrm{Concat}[z_1, \ldots, z_t], \quad Z_t \in \mathbb{R}^{tN \times C} \end{equation}\]이러한 query를 저장함으로써 Q-Former를 통해 현재 timestep까지 모델의 각 프레임 이해 및 처리에 대한 동적인 메모리를 유지한다. Query memory bank는 key와 value 역할도 한다.
\[\begin{equation} Q = z_t W_Q, \quad K = Z_t W_K, \quad V = Z_t W_V \end{equation}\]그런 다음 visual memory bank와 동일하게 attention 연산을 적용한다. 각 timestep $t$에서 $z_t$는 현재 timestep까지 각 동영상에 대해 학습된 중요한 정보를 포함한다. 정적인 visual memory bank와 달리, 입력 query는 모델 학습 중에 cascaded Q-Former 블록을 통해 진화하여 고유한 동영상 개념과 패턴을 캡처한다. 결과적으로 각 self-attention 레이어에는 고유한 query memory bank가 있으며, 여기에 포함된 입력 query는 학습하는 동안 업데이트된다.
Memory Bank Compression
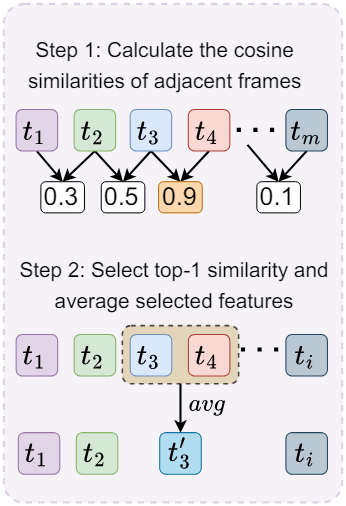
모델이 과거 동영상 정보를 memory bank에 직접 저장한다는 점을 고려하면 GPU 메모리와 계산량은 과거 동영상 프레임 수에 따라 선형적으로 증가한다. 이는 긴 동영상의 경우 특히 까다롭기 때문에 memory bank를 더 작은 크기로 압축하는 것이 필수적이다.
시간 순서를 관리하는 일반적인 방식 중 하나는 FIFO queue를 사용하는 것이다. 즉, memory bank가 미리 정의된 한계에 도달하면 가장 빠른 timestep의 feature가 제거되는 방식이다. 그러나 새로운 프레임이 추가되고 오래된 feature가 제거되면서 이전 기록 정보가 손실된다. MeMViT는 학습 가능한 pooling 연산자를 사용하여 memory bank에 저장된 feature의 시공간 크기를 압축하였다.
본 논문은 동영상에 내재된 시간적 중복성을 활용하기 위해 새로운 Memory Bank Compression (MBC) 기술을 도입하였다. 제안된 방법은 인접한 feature 간의 유사성을 활용하여 시간이 지남에 따라 동영상 정보를 집계하고 압축함으로써 초기 기록 정보를 유지한다. 이 방식은 다른 feature와 구별되는 feature를 유지하면서 memory bank 내에서 반복되는 정보를 효과적으로 압축한다.
Memory bank의 현재 길이가 미리 정의된 임계값 $M$을 초과하는 경우 각 autoregressive step에서 압축 알고리즘을 적용한다. Visual memory bank $[f_1, \ldots, f_M]$이 주어지면, 새로운 프레임 feature $f_{M+1}$이 들어오면 길이를 1씩 줄여 memory bank를 압축해야 한다. 각 공간적 위치 $i$에서 먼저 시간적으로 인접한 모든 토큰 간의 코사인 유사도를 계산한다.
\[\begin{equation} s_t^i = \cos (f_t^i, f_{t+1}^i), \quad t \in [1,M], \; i \in [1,P] \end{equation}\]그런 다음 시간에 따라 가장 높은 유사도를 선택한다. 이는 시간적으로 가장 중복되는 feature로 해석될 수 있다.
\[\begin{equation} k = \underset{t}{\arg \max} \; s_t^i \end{equation}\]다음으로, memory bank 길이를 1만큼 줄이기 위해 모든 공간 위치에서 선택된 토큰 feature의 평균을 낸다.
\[\begin{equation} \hat{f}_k^i = \frac{f_k^i + f_{k+1}^i}{2} \end{equation}\]이러한 방식으로 그림 2(b)에 표시된 대로 시간 순서를 변경하지 않고 유지하면서 가장 구별되는 특징을 계속 보존할 수 있다. Query memory bank를 압축하는 데에도 동일한 절차가 채택된다.
3. Text Decoding
Autoregressive 방식으로 동영상 프레임을 처리할 때 최종 timestep의 Q-Former 출력에는 모든 기록 정보가 포함되어 LLM에 입력된다. 따라서 입력 텍스트 토큰의 수를 $NT$에서 $N$으로 크게 줄여 현재 LLM의 컨텍스트 길이 제한을 해결하고 GPU 메모리 요구량을 실질적으로 완화할 수 있다. 학습 중에 동영상과 텍스트 쌍으로 구성된 데이터셋이 주어지면 모델은 다음과 같이 cross-entropy loss를 사용하여 학습된다.
\[\begin{equation} \mathcal{L} = - \frac{1}{S} \sum_{i=1}^S \log P (w_i \vert w_{<i}, V) \end{equation}\]여기서 $V$는 입력 동영상이고 $w_i$는 $i$번째 GT 텍스트 토큰이다. 학습 시 비전 인코더와 언어 모델의 가중치를 고정된 상태로 유지하면서 Q-Former의 파라미터를 업데이트한다.
Experiments
- 구현 디테일
- 비전 인코더: EVA-CLIP의 사전 학습된 CLIP 이미지 인코더 ViT-G/14
- Q-Former: InstructBLIP의 사전 학습된 가중치로 초기화
- LLM: Vicuna-7B
- GPU: A100 GPU 4개
1. Main Results
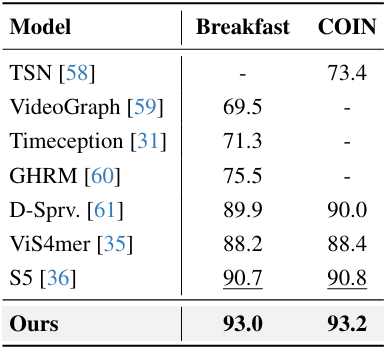
다음은 장기적인 동영상 이해 성능을 기존 SOTA 방법들과 비교한 표이다.
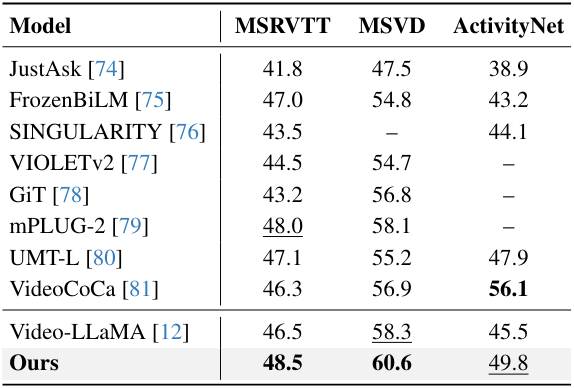
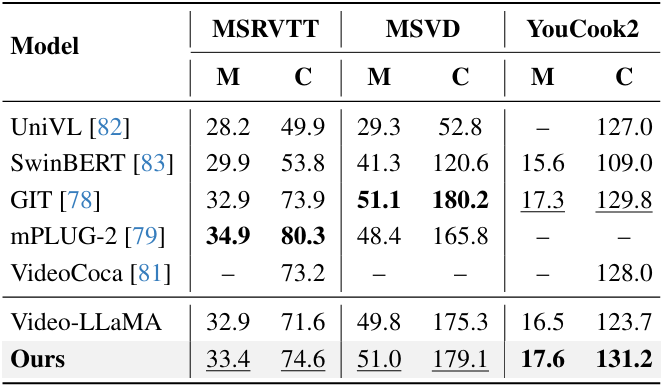
다음은 (왼쪽) 동영상 QA 성능과 (오른쪽) video captioning 성능을 기존 SOTA 방법들과 비교한 표이다.
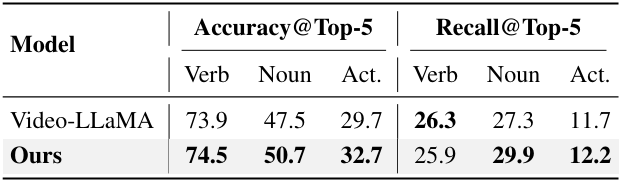
다음은 EpicKitchens-100에서 행동 예측 결과를 Video-LLaMA와 비교한 표이다.
2. Ablation Studies
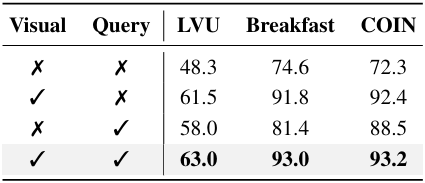
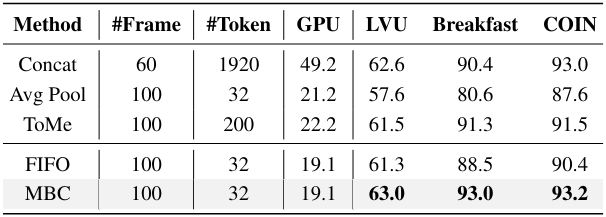
다음은 (왼쪽) 모델의 각 구성요소와 시간 모델링 방법에 대한 ablation 결과이다.
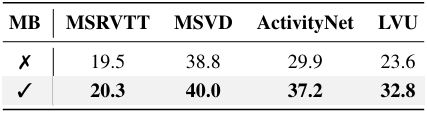
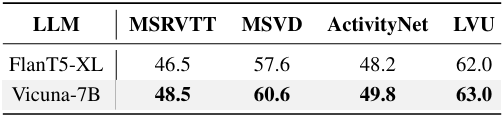
다음은 (왼쪽) long-term memory bank (MB)와 (오른쪽) LLM에 대한 ablation 결과이다.
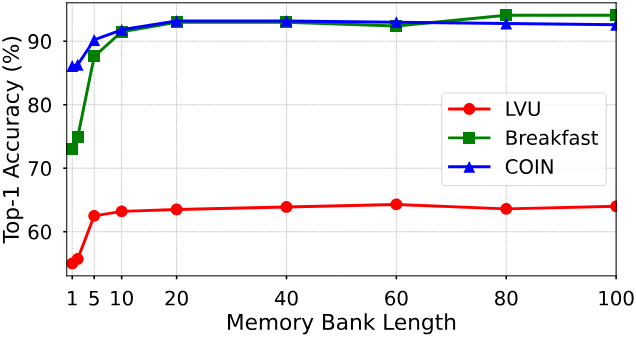
다음은 memory bank 길이에 대한 성능을 비교한 그래프이다.
3. Visualization
다음은 동영상 QA task에 대한 결과를 시각화한 것이다.

다음은 압축된 visual memory bank를 시각화한 것이다.
