[논문리뷰] M3: 3D-Spatial MultiModal Memory
ICLR 2025. [Paper] [Page] [Github]
Xueyan Zou, Yuchen Song, Ri-Zhao Qiu, Xuanbin Peng, Jianglong Ye, Sifei Liu, Xiaolong Wang
UC San Diego | NVIDIA
20 Mar 2025
Introduction
F-3DGS와 같은 기존 feature splatting 방법은 foundation model에서 얻은 2D feature map을 미분 가능한 렌더링을 통해 3D Gaussian으로 직접 추출했다. 여기에는 두 가지 주요 문제점이 있다.
- 계산상의 한계로 인해 Gaussian의 feature 벡터 차원이 원본 2D feature map에 비해 크게 감소하여 정보 병목 현상을 유발할 가능성이 있다. (16-64 vs 1024)
- 원본 feature map은 본질적으로 3D 일관성을 갖지 않을 수 있지만, Gaussian에 3D 일관성을 적용하면 원본 feature와 추출된 feature 간의 정렬 불일치가 발생할 수 있다.
결과적으로, 추출된 feature는 foundation model에 내장된 지식을 정확하게 포착하지 못할 수 있다.
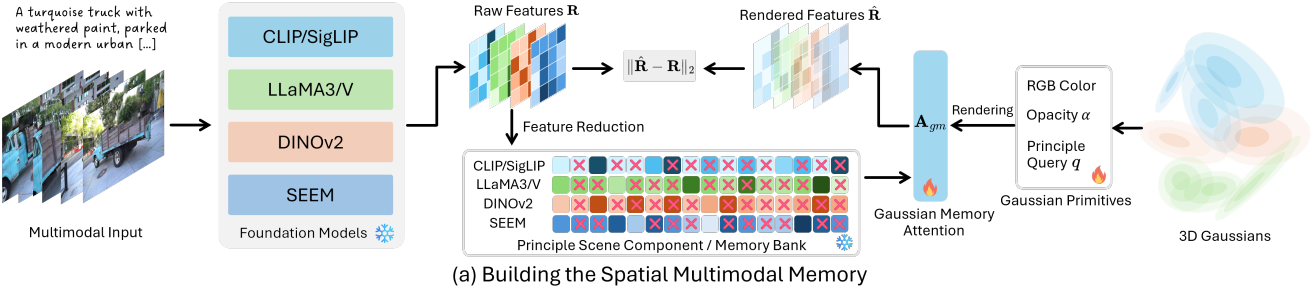
이러한 문제를 해결하기 위해, Gaussian splatting과 멀티모달 foundation model을 더욱 효과적으로 통합한 MultiModal Memory (M3)를 제안하였다. 이 메모리는 표현력이 풍부한 멀티모달 메모리를 Gaussian 구조로 효율적으로 저장하여 공간적 질의를 용이하게 한다. 구체적으로, 원본 고차원 2D feature map을 principal scene component (PSC)라고 부르는 메모리 뱅크에 저장하고, 3D Gaussian에서 추출한 저차원 principal query들을 인덱스로 사용한다. 2D feature를 3D 임베딩으로 직접 정제하는 대신, PSC와 principal query 사이에 Gaussian memory attention을 적용하여 foundation model 임베딩을 3D 장면에 렌더링한다.
이러한 방식으로, foundation model과 Gaussian splatting의 장점을 결합한다. 원본 foundation model feature map의 높은 표현력을 유지하면서도 장면의 3차원 일관성을 유지하는 저차원 Gaussian 구조를 유지한다. 또한, 저자들은 동영상 스트림에서 feature를 줄여 메모리 뱅크의 중복성을 최소화하는 휴리스틱 알고리즘을 설계하였다.
M3는 낮은 계산 비용을 유지하면서도 기억 및 다운스트림 task 모두에서 기존 방법들을 능가하는 성능을 보였다. 또한, 저자들은 M3를 4족 로봇 플랫폼에 적용하여 grasping을 실제 일반화에 대한 잠재력을 보여주었다.
Method
1. M3 Preliminaries
Visual Granularity
Visual Granularity $\mathcal{VG}$는 일반적으로 이미지의 클러스터링 픽셀 범위를 나타내며, 이는 Semantic-SAM에서 도입된 개념이다. 장면 $\textbf{V}$에서 뷰 \(\textbf{V}_\ast \in \mathbb{R}^{hw \times 3}\)이 주어지면 개별 픽셀에서 전체 뷰에 이르는 다중 세분성 세그먼트로 구성된다. 이는 \(\textbf{V}_\ast = \{V_\ast^1, \ldots, V_\ast^m\}\)로 표현되며, \(V_\ast^i \in $\mathbb{R}^{p \times 3}\)은 뷰 \(\textbf{V}_\ast\)의 $i$번째 세분성, $p$는 픽셀 수, $m$은 총 세분성 수를 나타낸다.
Knowledge Space
서로 다른 foundation model $\textbf{F}$는 지식의 다양한 측면에 초점을 맞춘다. 예를 들어, CLIP과 SigLIP은 이미지 수준 인식에 집중하고, Semantic-SAM은 part-level visual grouping을 강조하며, LLaMA3와 LLaMAv는 로컬 attention과 글로벌 attention 메커니즘을 모두 통합하였다. 이러한 모델에서 생성된 feature들은 서로 다른 knowledge space를 차지한다.
Principle Scene Components (PSC) & Principle Query
각 foundation model \(\textbf{F}_\ast\)에 대해 각 뷰에 대한 foundation model feature \(\textbf{F}_\ast (\textbf{V}) = \{\textbf{E}_1^\ast, \ldots, \textbf{E}_n^\ast\}\)를 추출한다. 그러나 서로 다른 뷰는 종종 중복되고 유사한 feature를 포함한다. 저자들은 PCA에서 영감을 얻어 장면을 구성하는 주요 feature를 Principle Scene Component (PSC)로 정의하였다. PSC는 각 Gaussian에서 학습 가능한 파라미터인 principal query \(\textbf{Q}_p\)로 인덱싱된다.
3. Spatial Multimodal Memory
3D Gaussian으로 장면 구조 구축
저자들은 M3의 입력을 프레임이 있는 동영상 시퀀스로 정의하였다. 각 프레임은 뷰 \(\textbf{V}_\ast\)에 해당한다. 3D Gaussian splatting이 장면을 재구성하는데 사용되었으며, 각 뷰는 Gaussian rasterizer로 렌더링된다. PSC를 모델링하기 위해 다양한 foundation model을 수용할 수 있는 유연한 차원을 가진 추가 최적화 가능한 속성인 principal query $q \in \mathbb{R}^l$을 각 Gaussian마다 도입하였다. 각 foundation model은 \(\textbf{Q}_p \in \mathbb{R}^l\)에서 $s$ degree를 활용한다. 이러한 degree는 Gaussian 파라미터와 함께 렌더링되어 \(\textbf{Q}_p^{\textbf{V}_\ast} \in \mathbb{R}^{H \times W \times l}\)을 생성한다.
\[\begin{equation} \textbf{Q}_p = \sum_{i \in N} q_i \alpha_i T_i, \quad \textrm{where} \; T_i = \prod_{j=1}^{i-1} (1 - \alpha_j) \end{equation}\]여러 세분성의 장면 지식 추출

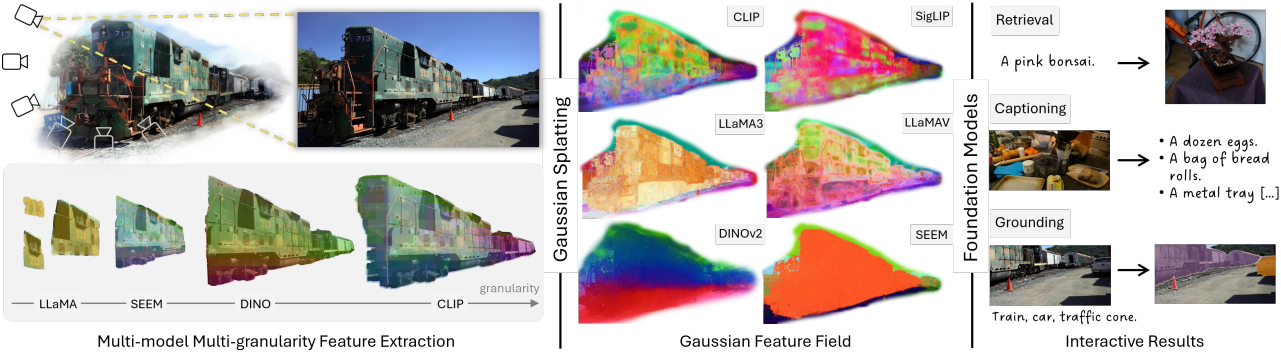
Foundation model을 통해 여러 세분성의 장면 지식을 추출한다. Foundation model들은 knowledge projection과 세분성의 각기 다른 측면에 초점을 맞춘다. 본 논문에서는 foundation model 집합 \(\textbf{F}\)로 CLIP, SigLIP, DINOv2, LLaMA3, LLaMAv, SEEM을 사용한다. 각 뷰에 대해 foundation model 임베딩 \(\textbf{F}(\textbf{V}_\ast) = \mathbb{E} \in \mathbb{R}^{hw \times d}\)를 추출한다.
저자들은 LLaMA3의 언어 임베딩과 SEEM의 비주얼 프롬프트를 픽셀 레벨 feature에 projection하기 위한 특정 알고리즘을 구현하였다. LLaMA3의 경우, 먼저 SoM과 Semantic-SAM을 사용하여 각 영역에 대한 언어 설명 $\textbf{T} \in \mathbb{R}^{l_1 \times d}$를 추출한다. SEEM의 경우, 각 영역에 해당하는 비주얼 프롬프트 \(\textbf{O} \in \mathbb{R}^{l_2 \times d}\)를 활용한다. 그런 다음, 각 마스크 영역 내에서 프롬프트를 복제하여 feature를 픽셀 레벨까지 분산시킨다. 그 결과, $\textbf{T}$와 $\textbf{O}$는 $\mathbb{R}^{hw \times d}$이 된다.
Feature 추출 후, 각 foundation model 내 $n$개의 뷰를 포함하는 전체 장면에 대한 feature $\textbf{R} \in \mathbb{R}^{n \times hw \times d}$를 얻는다. 이러한 feature들은 다양한 세분성과 knowledge space에 걸쳐 있어, 장면에 대한 포괄적인 멀티모달 이해를 제공한다. 가장 작은 세분성은 픽셀 레벨에 있으며, 가장 낮은 수준의 knowledge projection은 RGB 색상 값이다.
장면 지식을 메모리로 압축
Foundation model들 $\textbf{F}$에서 장면 지식 $\textbf{R} \in \mathbb{R}^{n \times hw \times d}$를 추출하고 나면, 차원이 너무 높아서 각 장면에 저장하고 렌더링할 수 없다. 이전 방법들은 feature distillation을 통해 이 문제를 해결했다. 그러나 feature distillation은 두 가지 주요 문제가 있되다.
- Distillation된 feature는 feature 압축으로 인해 원래 feature와 비교하여 정보 손실이 발생한다. (1000 차원 이상에서 16~64 차원으로 압축)
- 업샘플링된 feature는 foundation model의 원래 knowledge space와 정렬이 맞지 않아 원래 $\textbf{F}$에서 디코딩하기 어려울 수 있다.
이러한 문제를 해결하기 위해 먼저 feature $\textbf{R}$을 $\mathbb{R}^{nhw \times d}$로 flatten한 다음 Algorithm 1을 사용하여 첫 번째 차원에서 similarity reduction을 수행한다. 축소된 feature는 PSC 또는 메모리 뱅크라 하며 장면의 필수 표현 역할을 한다. PSC는 차원이 $\mathbb{R}^{t \times d}$이며, $t$는 설정한 similarity threshold에 따라 달라진다. 이러한 축소는 한 뷰 내 인접 공간 픽셀에 중복된 feature가 많거나, 뷰 간에 중복된 영역이 존재하기 때문에 효과적이다.

Gaussian Memory Attention

Gaussian으로 래스터화된 뷰 기반 principal query들 \(\textbf{Q}_p^{\textbf{V}_\ast} \in \mathbb{R}^{H \times W \times n}\)와 $\textbf{PSC} \in \mathbb{R}^{l \times d}$가 주어지면, foundation model과 일치하는 렌더링된 feature를 얻기 위해 Gaussian memory attention \(\textbf{A}_\textrm{gm}\)을 수행한다. 학습 가능한 랜덤 초기화된 메모리 projection \(\textbf{W}_m \in \mathbb{R}^{n \times d}\)를 사용하여 다음과 같이 Gaussian memory attention을 수행한다.
이를 통해, \(\textbf{Q}_p\)를 $\textbf{PSC}$와 연결하여 해당 foundation model의 knowledge space에 projection한다.
장면 렌더링 및 사용
각 foundation model에 대해 렌더링된 feature $\hat{\textbf{R}}$이 해당 foundation model space와 일치한다고 가정하면, foundation model의 강력한 기능들과 다시 연결될 수 있다. CLIP, SigLIP, SEEM과 같은 모델의 경우, 렌더링된 feature가 검색 및 grounding과 같은 비전-언어 기반 task에 직접 사용될 수 있다. LLaMA3, LLaMAv와 같은 생성 기반 모델의 경우, 해당 feature가 캡션 작성이나 간단한 VQA task에 직접 사용될 수 있다.
Experiments
1. Quantitative Results
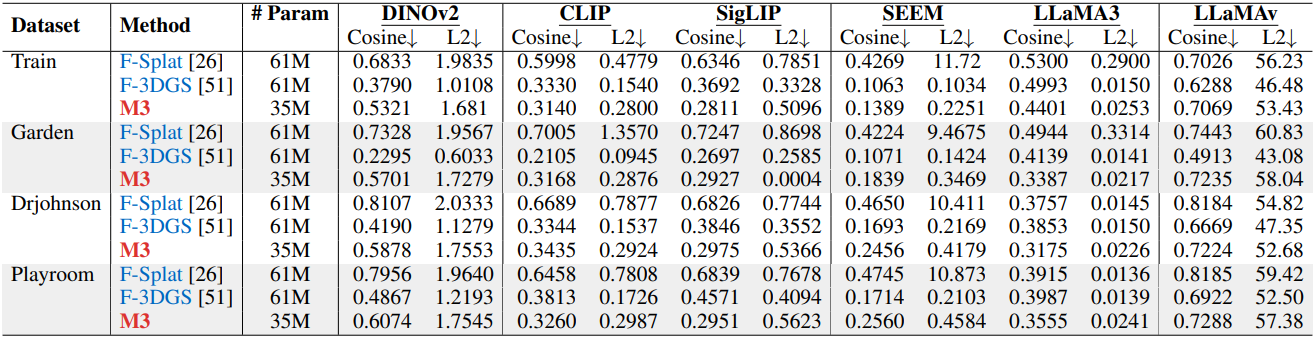
다음은 feature 거리를 distillation 방법들과 비교한 결과이다.
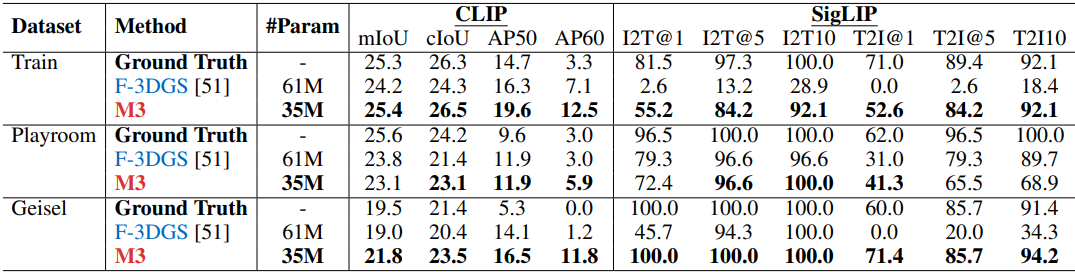
다음은 feature/RGB metric을 비교한 결과이다.
2. Ablation Results
다음은 foundation model 수에 대한 ablation 결과이다.

다음은 차원과 distillation에 대한 ablation 결과이다.

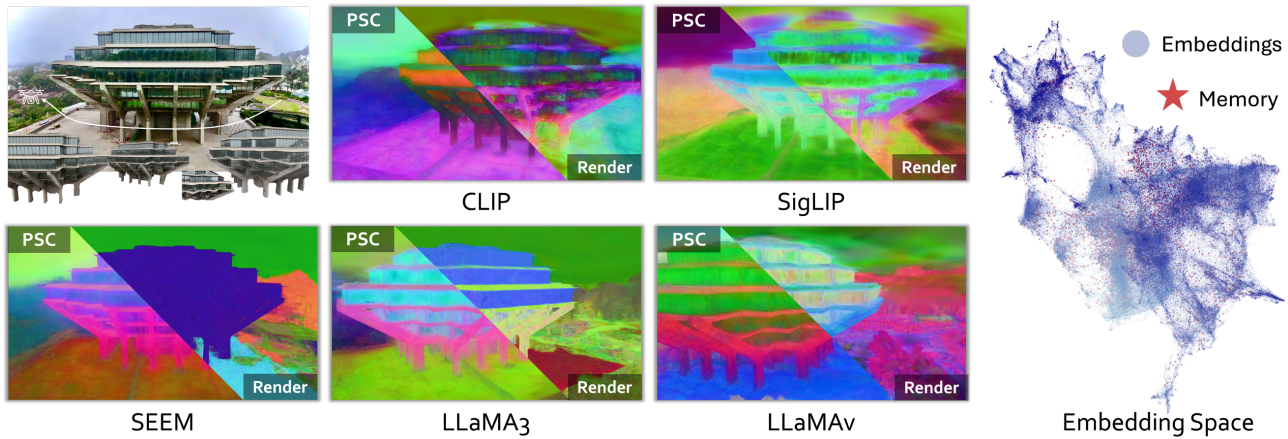
3. Qualitative Results
다음은 렌더링된 feature를 시각화한 것이다.

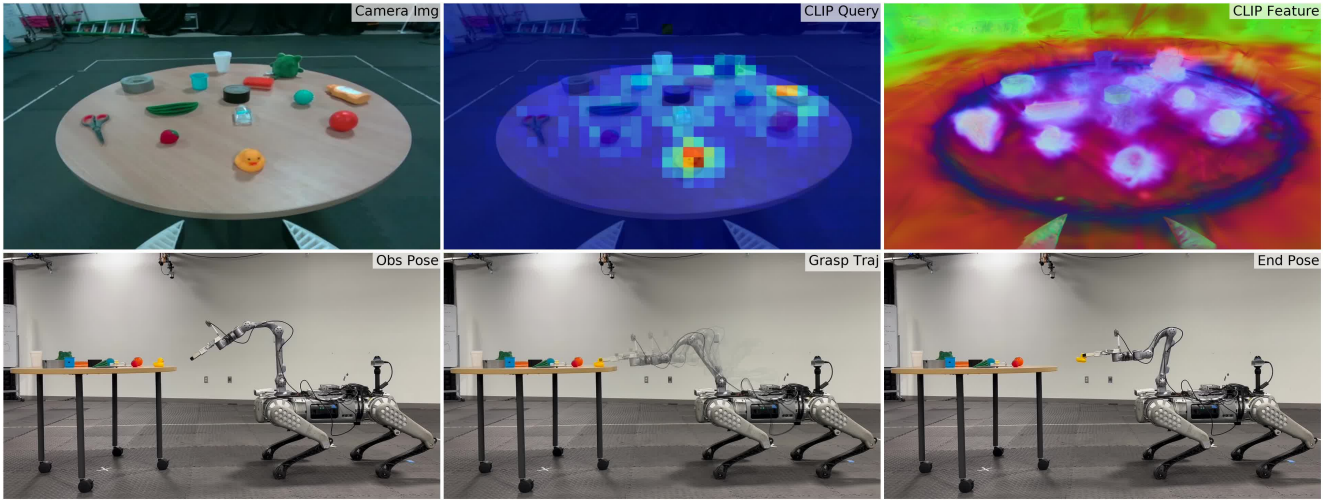
4. Demonstration Results
다음은 M3를 4족 로봇 플랫폼에 적용하여 grasping을 수행한 예시이다. (query: yellow bath duck)