[논문리뷰] LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
ICLR 2025 (Oral). [Paper] [Page]
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, Zexiang Xu
Cornell University | The University of Texas at Austin | Adobe Research | MIT
22 Oct 2024
Introduction
최근, large reconstruction model (LRM)은 대형 transformer를 활용하여 아키텍처 레벨의 inductive bias를 제거하는 데 상당한 진전을 이루었으며 SOTA novel view synthesis 품질을 달성했다. 그러나 이러한 발전에도 불구하고 LRM은 여전히 NeRF, 메쉬, 3DGS와 같은 표현 레벨의 inductive bias와 해당 렌더링 방정식에 의존하여 일반화 및 확장성을 제한한다.
본 논문에서는 3D inductive bias들을 최소화하고 완전히 데이터 중심적인 접근 방식으로 novel view synthesis의 경계를 넓히는 것을 목표로 한다. 저자들은 사전 정의된 렌더링 방정식이나 3D 구조 없이 포즈를 아는 sparse한 뷰 입력에서 새로운 뷰 이미지를 합성하는 새로운 transformer 기반 프레임워크인 Large View Synthesis Model (LVSM)을 제안하여 사실적인 품질로 정확하고 효율적이며 스케일링 가능한 novel view synthesis를 가능하게 하였다.
이를 위해 먼저 encoder-decoder LVSM을 도입하여 3D 표현과 렌더링 방정식을 제거한다. 인코더 transformer를 사용하여 patchify된 입력 멀티뷰 이미지 토큰을 입력 뷰 수와 관계없이 고정된 수의 1D latent 토큰으로 매핑한다. 그런 다음 이러한 latent 토큰은 디코더 transformer에서 처리되며, 디코더 transformer는 타겟 뷰의 Plücker ray를 위치 임베딩으로 사용하여 타겟 뷰의 이미지 토큰을 생성하고 궁극적으로 최종 linaer layer에서 출력 픽셀 색상을 예측한다. Encoder-decoder LVSM은 reconstructor (인코더), 장면 표현 (latent 토큰), 렌더러 (디코더)를 데이터에서 직접 공동으로 학습한다. 렌더링 및 표현에서 미리 정의된 inductive bias의 필요성을 제거함으로써 NeRF나 3DGS 기반 접근 방식에 비해 향상된 일반화를 제공하고 더 높은 품질을 달성하였다.
그러나 encoder-decoder LVSM은 완전히 학습된 중간 장면 표현이 필요하다 inductive bias를 여전히 유지한다. 경계를 더욱 넓히기 위해, 저자들은 단일 스트림 transformer를 채택하여 입력 멀티뷰 토큰을 타겟 뷰 토큰으로 직접 변환하고 중간 표현을 사용하지 않는 decoder-only LVSM을 제안하였다. Decoder-only LVSM은 novel view synthesis 프로세스를 데이터 기반 프레임워크에 통합하여 최소한의 3D inductive bias로 완전히 implicit한 방식으로 장면 재구성과 렌더링을 동시에 달성하였다.
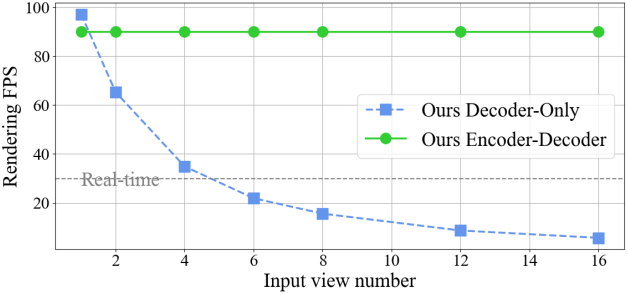
2-4개의 입력 뷰에서 학습된 모델은 1개의 입력에서 10개 이상에 이르기까지 처음 보는 뷰들에 대해 강력한 zero-shot 일반화를 보여준다. 최소한의 inductive bias 덕분에 decoder-only 모델은 다양한 수의 입력 뷰에서 품질, 확장성, zero-shot 능력 측면에서 encoder-decoder 모델보다 지속적으로 우수한 성능을 보인다. 반면, encoder-decoder 모델은 고정 길이의 latent 장면 표현을 사용하기 때문에 훨씬 빠른 inference 속도를 달성하였다. 3D inductive bias가 감소한 두 모델 모두 이전 방법보다 우수한 성능을 보이며 여러 데이터셋에서 SOTA novel view synthesis 품질을 달성하였다. 최종 모델은 데이터 유형과 모델 아키텍처에 따라 3~7일 동안 64개의 A100 GPU에서 학습되었지만, 학습에 1~2개의 A100 GPU만 사용하더라도 동일하거나 더 많은 컴퓨팅 리소스로 학습한 모든 이전 방법보다 성능이 우수하다.
Method
1. Overview
카메라 포즈와 intrinsic을 알고 있는 $N$개의 sparse한 입력 이미지 \(\{(\mathbf{I}_i, \mathbf{E}_i, \mathbf{K}_i)\}_{i=1}^N\)이 주어지면, LVSM은 타겟 이미지 \(\mathbf{I}^t\)를 새로운 타겟 카메라의 extrinsic $\mathbf{E}^t$와 intrinsic $\mathbf{K}^t$와 합성한다. 각 입력 이미지는 $\mathbb{R}^{H \times W \times 3}$ 모양을 가진다.
Framework
LVSM은 end-to-end transformer 모델을 사용하여 타겟 이미지를 직접 렌더링한다. LVSM은 입력 이미지를 tokenize하는 것으로 시작한다. 먼저 카메라 포즈와 intrinsic을 사용하여 각 입력 뷰에 대한 픽셀별 Plücker ray 임베딩 \(\{\mathbf{P}_i \in \mathbb{R}^{H \times W \times 6}\}_{i=1}^N\)을 계산한다. ViT의 이미지 tokenization layer를 따라 RGB 이미지와 Plücker ray 임베딩을 각각 \(\{\mathbf{I}_{ij} \in \mathbb{R}^{p \times p \times 3}\}_{j=1}^{HW/p^2}\)와 \(\{\mathbf{P}_{ij} \in \mathbb{R}^{p \times p \times 6}\}_{j=1}^{HW/p^2}\)로 patchify한다. 각 패치에 대해 이미지 패치와 Plücker ray 임베딩 패치를 concat하고, 1D 벡터로 reshape한 뒤, linaer layer를 사용하여 입력 패치 토큰 \(\mathbf{x}_{ij}\)에 매핑한다.
($d$는 latent 크기, $[\cdot, \cdot]$은 concatenation)
마찬가지로 합성할 타겟 포즈를 주어진 타겟 extrinsic $\mathbf{E}^t$와 intrinsic $\mathbf{K}^t$에서 Plücker ray 임베딩 \(\mathbf{P}_j^t \in \mathbb{R}^{H \times W \times 6}\)를 계산한다. 동일한 patchify 방법과 또 다른 linear layer를 사용하여 타겟 뷰의 Plücker ray 토큰에 매핑한다.
\[\begin{equation} \textbf{q}_j = \textrm{Linear}_\textrm{target}(\textbf{P}_j^t) \in \mathbb{R}^d \end{equation}\](\(\textbf{P}_j^t\)는 타겟 뷰의 $j$번째 패치의 Plücker ray 임베딩)
입력 토큰 \(\mathbf{x}_{ij}\)를 1D 토큰 시퀀스 $x_1, \ldots, x_{l_x}$로 flatten하고, 타겟 쿼리 토큰 \(\textbf{q}_j\)를 $q_1, \ldots, q_{l_q}$로 flatten한다. 여기서 $l_x = NHW/p^2$는 입력 이미지 토큰의 시퀀스 길이이며, $l_q = HW/p^2$는 쿼리 토큰의 시퀀스 길이이다.
LVSM은 full transformer 모델 $M$을 사용하여 입력 뷰 토큰을 조건으로 새로운 뷰를 합성한다.
\[\begin{equation} y_1, \ldots, y_{l_q} = M (q_1, \ldots, q_{l_q} \vert x_1, \ldots, x_{l_x}) \end{equation}\]구체적으로, 출력 토큰 $y_j$는 $q_j$의 업데이트된 버전으로, 타겟 뷰의 $j$번째 패치의 픽셀 RGB 값을 예측하는 정보를 담고 있다.
Flatten 연산의 역연산을 사용하여 출력 토큰의 공간 구조를 복구한다. 타겟 패치의 RGB 값을 예측하기 위해 linear layer를 사용한 다음 Sigmoid 함수를 사용한다.
\[\begin{equation} \hat{\textbf{I}}_j^t = \textrm{Sigmoid}(\textrm{Linear}_\textrm{out} (y_j)) \in \mathbb{R}^{3p^2} \end{equation}\]예측된 RGB 값을 $\mathbb{R}^{p \times p \times 3}$의 2D 패치로 reshape한 다음, 모든 타겟 패치에서 독립적으로 동일한 연산을 수행하여 합성된 새로운 뷰 \(\hat{\mathbf{I}}^t\)를 얻는다.
Loss Function
LRM을 따라, photometric novel view rendering loss로 LVSM을 학습시킨다.
\[\begin{equation} \mathcal{L} = \textrm{MSE} (\hat{\textbf{I}}^t, \textbf{I}^t) + \lambda \cdot \textrm{Perceptual} (\hat{\textbf{I}}^t, \textbf{I}^t) \end{equation}\]2. Transformer-Based Model Architecture
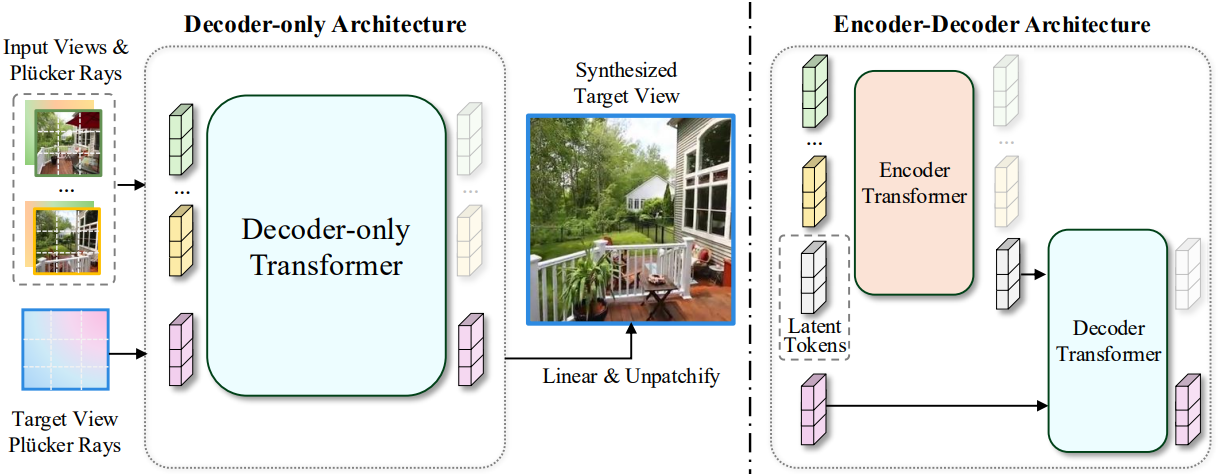
본 논문에서는 3D inductive bias를 최소화하도록 설계된 두 가지 LVSM 아키텍처가 제안되었다. Encoder-decoder LVSM은 최종 이미지 색상을 디코딩하기 전에 먼저 입력 이미지를 latent 표현으로 변환하는 반면, decoder-only LVSM은 중간 표현 없이 타겟 뷰를 직접 출력하여 inductive bias를 최소화하였다.
중요한 점은 ‘인코더’와 ‘디코더’의 명명이 출력 특성에 기반한다는 것이다. 즉, 인코더는 latent를 출력하고 디코더는 타겟을 출력하며, 사용하는 transformer 아키텍처와는 무관하다. 예를 들어, encoder-decoder 모델에서 디코더는 self-attention이 있는 여러 transformer layer로 구성되며, 원래 transformer 논문에서는 인코더라 부르지만 주요 기능이 결과를 출력하는 것이기 때문에 디코더라 부른다. 특히, inductive bias를 최소화한다는 철학에 따라 attention mask를 도입하지 않고 두 모델의 모든 transformer block에 있는 모든 토큰에 self-attention을 적용한다.
Encoder-Decoder Architecture
Encoder-decoder LVSM은 NeRF, 3DGS 및 기타 표현을 사용하지 않고 뷰 합성을 위한 학습된 latent 장면 표현과 함께 제공된다. 인코더는 먼저 입력 토큰을 장면 표현으로 기능하는 중간 latent 토큰에 매핑한다. 그런 다음 디코더는 latent 토큰과 타겟 포즈를 조건으로 출력을 예측한다.
입력 토큰 \(\{x_i\}\)에서 정보를 집계하기 위해 $l$개의 학습 가능한 latent 토큰 \(\{e_k \in \mathbb{R}^d\}_{k=1}^l\)을 사용한다. 인코더는 self-attention이 있는 여러 개의 transformer layer를 사용한다. \(\{x_i\}\)와 \(\{e_k\}\)를 concat하여 인코더에 입력하고, 인코더는 이들 간의 정보 집계를 수행하여 \(\{e_k\}\)를 업데이트한다. Latent 토큰에 해당하는 출력 토큰 \(\{z_k\}\)는 중간 latent 장면 표현으로 사용된다. \(\{x_i\}\)에서 업데이트된 \(\{x_i^\prime\}\)은 사용되지 않고 버려진다.
디코더는 self-attention을 가진 여러 개의 transformer layer를 사용한다. Latent 토큰 \(\{z_k\}\)와 타겟 뷰의 쿼리 토큰 \(\{q_j\}\)를 concat하여 입력으로 사용한다. 입력 토큰에 self-attention transformer layer를 적용하면 입력과 동일한 시퀀스 길이를 가진 출력 토큰을 얻는다. 타겟 토큰 \(\{q_j\}\)에 해당하는 출력 토큰은 최종 출력 \(\{y_j\}\)로 처리되고, \(\{z_i\}\)에서 업데이트된 \(\{z_i^\prime\}\)은 사용되지 않는다.
\[\begin{aligned} x_1^\prime, \ldots, x_{l_x}^\prime, z_1, \ldots, z_l &= \textrm{Transformer}_\textrm{Enc} (x_1, \ldots, x_{l_x}, e_1, \ldots, e_l) \\ z_1^\prime, \ldots, z_l^\prime, y_1, \ldots, y_{l_q} &= \textrm{Transformer}_\textrm{Dec} (z_1, \ldots, z_l, q_1, \ldots, q_{l_q}) \end{aligned}\]Decoder-Only Architecture
Decoder-only 모델은 중간 장면 표현의 필요성을 더욱 제거한다. 아키텍처는 encoder-decoder 아키텍처의 디코더와 유사하지만 입력과 모델 크기가 다르다. 두 개의 입력 토큰 \(\{x_i\}\)과 타겟 토큰 \(\{q_j\}\) 시퀀스를 concat하여 입력으로 사용한다. 최종 출력 \(\{y_j\}\)는 타겟 토큰 \(\{q_j\}\)에 해당하는 디코더의 출력이다. \(\{x_i\}\)에서 업데이트된 \(\{x_i^\prime\}\)은 사용되지 않고 버려진다.
\[\begin{equation} x_1^\prime, \ldots, x_{l_x}^\prime, y_1, \ldots, y_{l_q} = \textrm{Transformer}_\textrm{Dec-only} (x_1, \ldots, x_{l_x}, q_1, \ldots, q_{l_q}) \end{equation}\]\(\textrm{Transformer}_\textrm{Dec-only}\)는 여러 개의 full self-attention transformer layer들로 구성된다.
Experiments
- 데이터셋
- Object-level: Objaverse
- Scene-level: RealEstate10K
- 학습 디테일
- gradient exploding을 억제하기 위해 QK-Norm을 사용
- 학습을 가속하기 위해 FlashAttention-v2, gradient checkpointing, mixed-precision training (Bfloat16)을 사용
- GPU: NVIDIA A100 64개
- batch size: GPU당 8 (총 512)
- learning rate: cosine schedule (peak $4 \times 10^{-4}$, warmup 2500)
- 패치 크기: $p$ = 8
- 토큰 차원: $d$ = 768
- transformer layer 수: 24개 (encoder-decoder 모델은 인코더 12개, 디코더 12개)
- 256$\times$256에서 먼저 학습 후 512$\times$512에서 fine-tuning
- object-level
- iteration: 8만
- 입력 뷰 4개, 타겟 뷰 8개
- fine-tuning: iteration = 1만 / learning rate = $4 \times 10^{-5}$ / batch size = 128
- perceptual loss 가중치: $\lambda$ = 1.0
- scene-level
- iteration: 10만
- 입력 뷰 2개, 타겟 뷰 6개
- fine-tuning: iteration = 2만 / learning rate = $1 \times 10^{-4}$ / batch size = 128
- perceptual loss 가중치: $\lambda$ = 0.5
1. Evaluation against Baselines
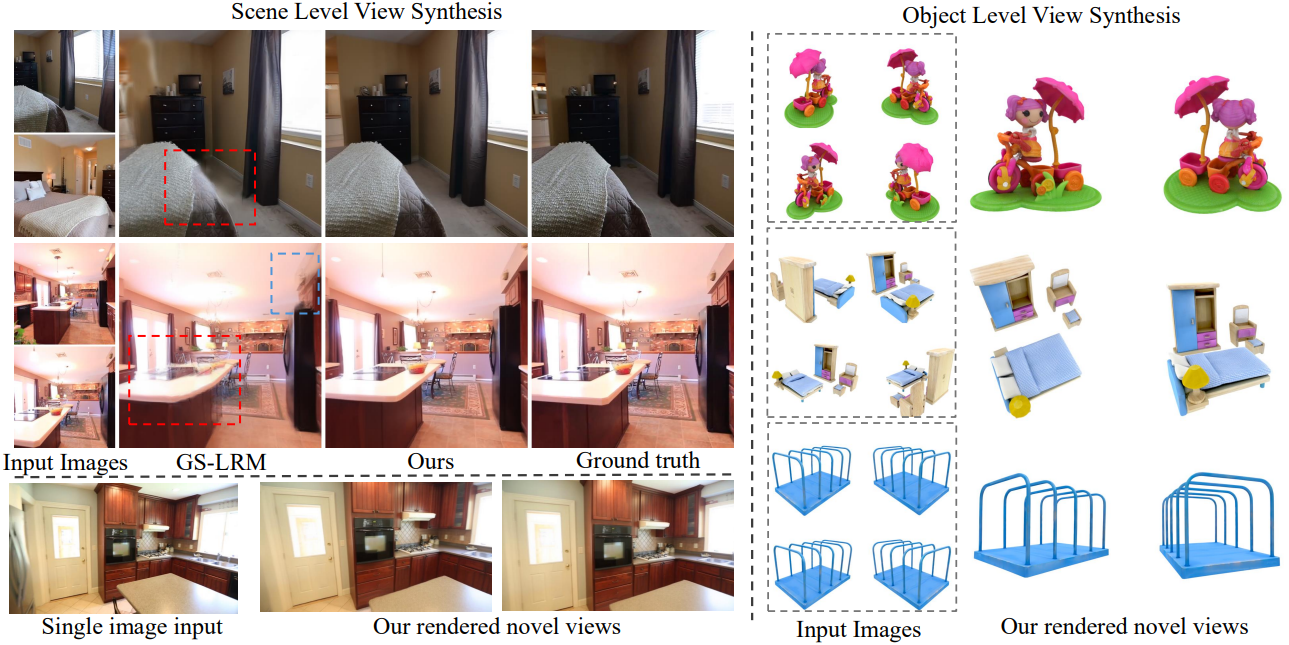
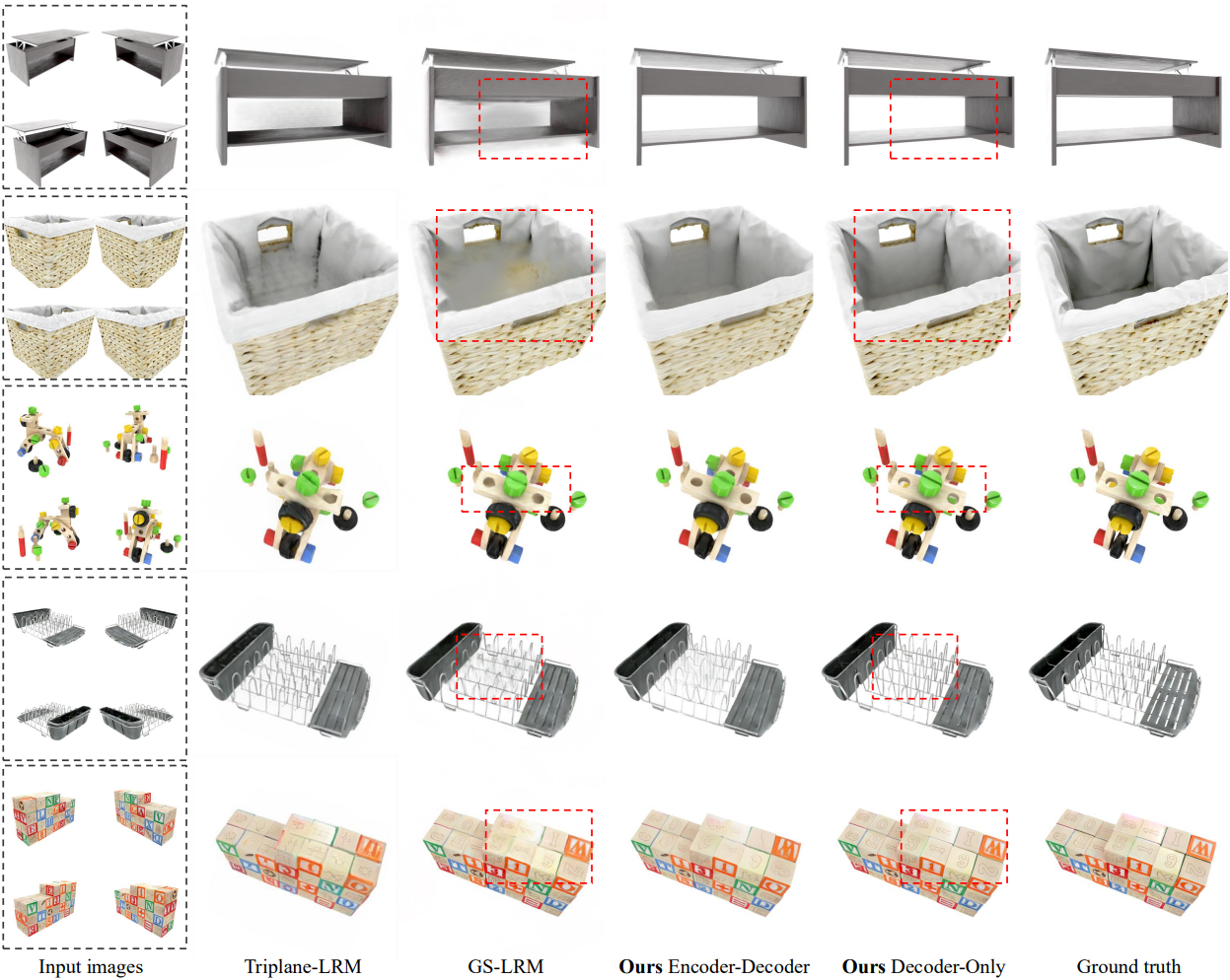
다음은 object-level에 대한 비교 결과이다.

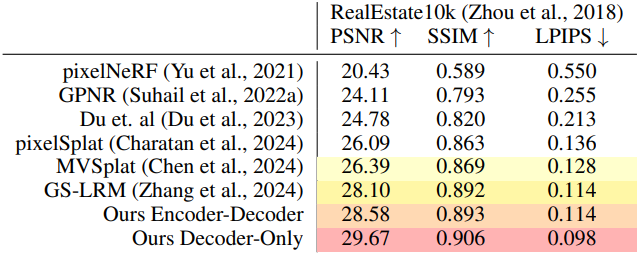
다음은 scene-level에 대한 비교 결과이다.

2. Ablation Studies
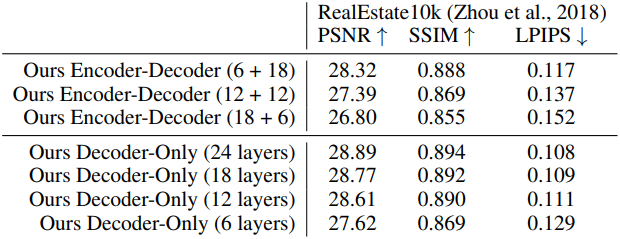
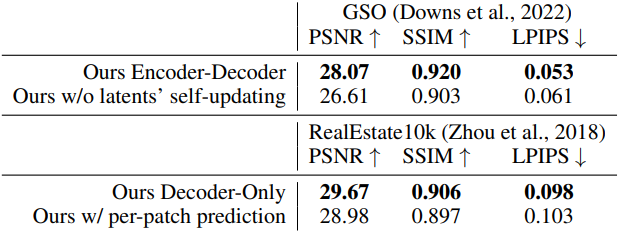
다음은 (왼쪽) 모델 크기와 (오른쪽) 모델 attention 아키텍처에 대한 ablation 결과이다.
3. Discussions
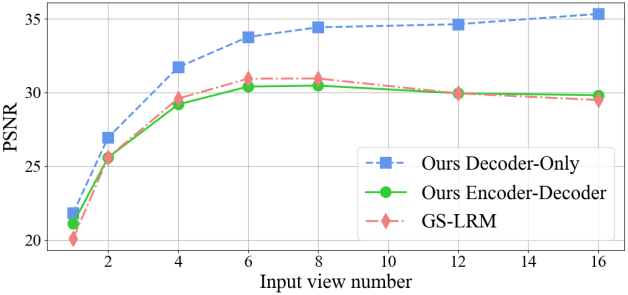
다음은 입력 이미지 수에 따른 zero-shot 일반화 성능을 나타낸 그래프이다.
다음은 입력 이미지 수에 따른 렌더링(디코딩) FPS를 나타낸 그래프이다.