[논문리뷰] LuxDiT: Lighting Estimation with Video Diffusion Transformer
NeurIPS 2025. [Paper] [Page]
Ruofan Liang, Kai He, Zan Gojcic, Igor Gilitschenski, Sanja Fidler, Nandita Vijaykumar, Zian Wang
NVIDIA | University of Toronto | Vector Institute
3 Sep 2025

Introduction
본 논문에서는 lighting 추정을 조건부 생성 task로 생각하고, 합성 데이터로 학습되어 실제 장면에도 적용 가능한 신경망 기반 lighting predictor인 LuxDiT를 제안하였다. LuxDiT는 이미지 또는 동영상을 조건으로 DiT를 fine-tuning하여 noise로부터 HDR 파노라마 이미지를 생성한다. 픽셀 단위의 task와 달리, lighting 추정은 장면 컨텍스트에 대한 글로벌한 추론을 요구한다. DiT의 attention 기반 아키텍처는 글로벌 컨텍스트 집계를 지원하며, generative prior는 음영 및 반사와 같은 간접적인 단서로부터의 추론을 용이하게 한다.
이러한 모델을 학습시키려면 다양한 lighting 데이터가 필요하다. 실제 HDR lighting 데이터의 부족을 극복하기 위해, 저자들은 무작위로 생성된 geometry, material, lighting 조건을 가진 대규모 합성 데이터셋을 구축했다. 이 데이터셋을 이용한 학습을 통해 모델은 빛의 방향과 강도에 대한 물리적으로 타당한 단서를 학습할 수 있다. 이는 일반적인 lighting 정보를 제공하지만, 합성 데이터만으로 학습된 모델은 데이터셋의 lighting을 잘못 예측하는 경우가 있어, 입력 장면과 semantic하게 일치하지 않는 environment map을 생성할 수 있다. 이러한 문제를 해결하기 위해, 저자들은 엄선된 실제 HDR 파노라마 이미지 데이터셋에 LoRA를 적용하여 예측된 조명과 장면 semantic 간의 일치도를 향상시켰다.
Method
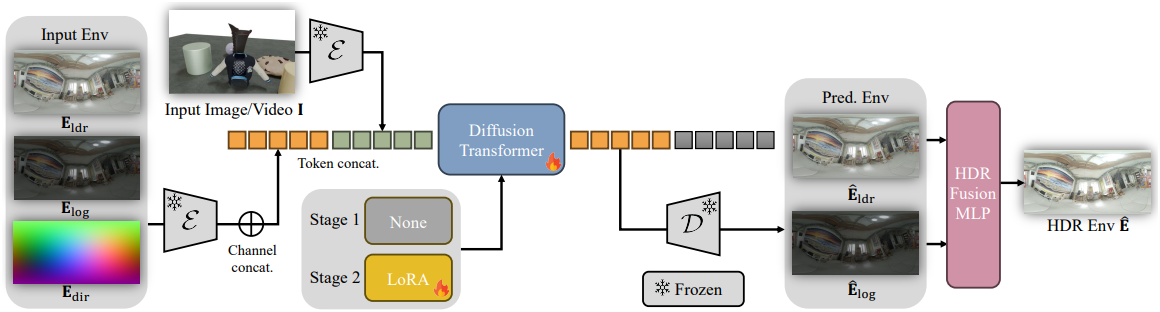
본 논문에서는 단일 이미지 또는 동영상으로부터 HDR environment map을 추정하는 diffusion 기반 생성 프레임워크인 LuxDiT를 제안하였다. Video diffusion transformer인 Cogvideox 아키텍처를 lighting 추정에 맞게 조정하여, self-attention layer를 통해 denoising 대상인 lighting과 조건인 LDR 입력 이미지를 동시에 처리한다.
1. Model Design
본 논문에서는 HDR environment map 추정을 조건부 denoising task로 생각한다. $L$개의 프레임으로 구성된 입력 동영상 $\textbf{I} \in \mathbb{R}^{L \times H \times W \times 3}$이 주어졌을 때 (이미지는 $L = 1$), 모델은 이에 대응하는 360° HDR 파노라마 시퀀스 \(\textbf{E} \in \mathbb{R}^{L \times H_e \times W_e \times 3}\)을 생성한다.
두 가지 핵심적인 과제가 발생한다.
- Latent diffusion model에 사용되는 표준 VAE는 LDR 이미지로 학습되었기 때문에 HDR 콘텐츠를 정확하게 인코딩할 수 없다.
- 출력 파노라마가 입력과 공간적으로 정렬되지 않아 유연한 컨디셔닝 메커니즘이 필요하다.
본 논문에서는 tonemapping된 HDR 표현, 토큰 기반 컨디셔닝, 두 가지 latent 표현을 동시에 denoising하는 통합 transformer 아키텍처를 사용하여 이러한 과제를 해결하였다.
HDR lighting representation
사실적인 lighting에는 태양이나 인공 광원과 같은 intensity가 높은 요소가 포함되며, radiance 값은 종종 100 또는 1,000을 초과한다. 이러한 범위를 latent space에 표현하는 것은 간단하지 않다. 표준 VAE는 $[0, 1]$로 정규화된 LDR 이미지로 학습되었기 때문에 이러한 동적 콘텐츠를 재구성할 수 없으며, HDR 데이터로 재학습하는 것은 데이터 부족으로 인해 현실적으로 불가능하다.
저자들은 각 HDR 파노라마 $\textbf{E}$를 두 개의 상호 보완적인 tonemapping 표현을 사용하여 나타낸다.
\[\begin{equation} \textbf{E}_\textrm{ldr} = \frac{\textbf{E}}{1 + \textbf{E}} \cdot \left( 1 + \frac{\textbf{E}}{M_\textrm{ldr}^2} \right), \quad \textbf{E}_\textrm{log} = \frac{\log (1 + \textbf{E})}{\log (1 + M_\textrm{log})} \end{equation}\](\(\textbf{E}_\textrm{ldr}\)은 표준 Reinhard tonemapping, \(\textbf{E}_\textrm{log}\)는 정규화된 log-space intensity, \(M_\textrm{ldr} = 16\), \(M_\textrm{log} = 10000\))
Inference 시에는 가벼운 MLP $\psi$를 사용하여 HDR environment map을 재구성한다.
\[\begin{equation} \hat{\textbf{E}} = \psi (\textbf{E}_\textrm{ldr}, \textbf{E}_\textrm{log}) \end{equation}\]Diffusion latents
본 모델은 입력 동영상으로부터 HDR environment map을 예측하도록 변형된 diffusion model \(\mu_\theta\)를 기반으로 한다. 이 모델은 latent space에서 작동하며 HDR 조명의 두 가지 tonemapping 표현을 동시에 denoising한다.
Tonemapping된 입력 \(\textbf{E}_\textrm{ldr}\)과 \(\textbf{E}_\textrm{log}\)는 사전 학습된 VAE에 의해 $\mathbb{R}^{l \times h_e \times w_e \times C}$의 latent 텐서로 인코딩된다. 이 텐서들은 채널 차원을 따라 concat되어 diffusion target $\textbf{z} = [\textbf{z}^\textrm{ldr}, \textbf{z}^\textrm{log}] \in \mathbb{R}^{l \times h_e \times w_e \times 2C}$를 형성한다. Diffusion model \(\mu_\theta\)의 입력 및 출력 projection layer는 증가된 채널 차원을 수용하도록 확장된다.
DiT에서 비전 입력 컨디셔닝
정확한 lighting 추정을 위해서는 모델이 입력에서 그림자 방향, 표면 반사, 반사광과 같은 세밀한 음영 단서를 추출해야 한다. Noise가 포함된 latent에 조건을 연결하면 성능이 저하된다. 이는 보다 유연한 컨디셔닝 메커니즘이 필요함을 시사한다.
이를 위해 입력 동영상 조건에 대해 full attention 기반 아키텍처를 채택하였다. 구체적으로, 입력 동영상 \(\textbf{I} \in \mathbb{R}^{L \times H \times W \times 3}\)를 사전 학습된 VAE 인코더를 사용하여 latent 텐서 \(\mathcal{E}(\textbf{I}) \in \mathbb{R}^{l \times h \times w \times C}\)로 인코딩하고, 이를 토큰 시퀀스 \(\textbf{c} \in \mathbb{R}^{lhw \times C}\)로 flatten한다. 모델이 조건 토큰과 denoising 대상 토큰을 구분할 수 있도록, 각 transformer block에서 각 토큰 유형에 대해 별도의 AdaLN 모듈을 적용한다.
방향 임베딩
예측된 파노라마 이미지의 각도 연속성을 향상시키기 위해 모델에 방향 정보를 주입한다. 구체적으로, 카메라 좌표계에서 픽셀별 lighting 방향을 인코딩하는 단위 벡터 direction map \(\textbf{E}_\textrm{dir}\)을 구성한다. Direction map은 동일한 VAE 인코더 $\mathcal{E}$를 통과한 후, transformer block 이전에 채널별 concat을 통해 noise 토큰에 projection 및 융합된다. 학습 과정에서 회전 등분산성과 robust한 방향 인코딩을 유도하기 위해 \(\textbf{E}_\textrm{dir}\)에 랜덤 수평 회전을 적용한다.
Denoising process
각 denoising timestep $t$에서 모델은 noise가 포함된 latent \(\textbf{z}_t = [\textbf{z}_t^\textrm{ldr}, \textbf{z}_t^\textrm{log}]\)를 입력받아 비전 입력에 따라 denoise된 latent를 예측한다. 이러한 transformer 기반 설계는 그림자나 반사와 같은 간접 조명 단서를 global self-attention 메커니즘을 통해 전달할 수 있게 하여, 장면과 일관성이 있으면서도 방향적으로 정확한 lighting 예측을 가능하게 한다.
2. Data Strategy
본 모델의 학습에는 \((\textbf{I}, \textbf{E}_\textrm{ldr}, \textbf{E}_\textrm{log})\) 형식의 데이터가 필요하다. 실제 HDR 어노테이션의 부족 문제를 해결하기 위해, 본 논문에서는 합성 렌더링, HDR 파노라마 이미지, LDR 파노라마 동영상이라는 세 가지 상호 보완적인 데이터 소스를 활용하였다.
합성 렌더링 데이터
물리적으로 정확한 시각적 단서를 사용하기 위해, HDR environment map으로 조명된 무작위 3D 장면을 렌더링하여 합성 데이터를 생성한다. 각 장면은
- 무작위로 할당된 PBR material이 있는 지면
- Objaverse에서 샘플링된 3D object
- 다양한 material이 적용된 구, 정육면체, 원기둥과 같은 단순한 primitive
로 구성된다. 랜덤한 카메라 궤적과 environment map 회전을 사용하여 장면당 여러 프레임을 렌더링한다. 이러한 장면은 단순해 보이지만, 그림자, 반사광, 상호 반사 등 다양한 조명 효과를 보여주며, 모두 실제 HDR lighting과 함께 제공된다. 이러한 데이터는 모델이 정확한 음영 단서와 광원 위치를 학습하는 데 매우 중요하다.
HDR 파노라마 이미지
본 논문에서는 data augmentation을 통해 HDR environment map에서 perspective crop을 추출하여 학습 쌍을 생성한다. 구체적으로, 파노라마 이미지가 주어지면 방위각, 고도, 시야각, 노출 배율을 포함한 카메라 파라미터를 랜덤하게 추출한다. 이러한 파라미터는 가상의 핀홀 카메라를 정의하며, 이 카메라를 사용하여 파노라마 이미지를 LDR 이미지 $\textbf{I}$로 projection한다. 이때 해당 HDR environment map은 GT lighting $\textbf{E}$로 사용된다. 저자들은 카메라 포즈를 시간에 따라 부드럽게 변화시켜 다중 프레임 시퀀스를 생성하는 방식으로 이 절차를 확장하였다.
LDR 파노라마 동영상
동적 파노라마 environment map 생성을 위해 LDR 파노라마 동영상에서 추출한 학습 데이터를 활용했다. 이 데이터 소스에 대한 HDR environment map 원본은 없지만, \((\textbf{I}, \textbf{E}_\textrm{ldr}, \varnothing)\) 형태로 사용했다. 여기서 \(\textbf{E}_\textrm{ldr}\)은 tonemapping을 통해 생성되었고, $\varnothing$는 log-space intensity가 없음을 나타낸다. 파노라마 동영상은 위와 동일한 절차에 따라 랜덤한 카메라 파라미터를 사용하여 동영상으로 변환된다. HDR intensity가 없음에도 불구하고, 이 데이터는 모델을 자연스러운 이미지 통계, 모션 패턴 및 다양한 실제 lighting 조건에 노출시켜 robustness와 시간적 일관성을 향상시킨다. 저자들은 WEB360 데이터셋의 2,000개의 파노라마 동영상을 학습에 사용하였으며, 그중 114개를 평가에 사용했다.
3. Training Scheme
본 논문에서는 모델의 역량을 점진적으로 구축하고 일반화 성능을 향상시키기 위해 2단계 학습 전략을 채택했다. 첫 번째 단계에서는 합성 데이터를 활용하여 물리적으로 타당한 lighting 단서를 학습시킨다. 두 번째 단계에서는 LoRA 기반 fine-tuning을 통해 모델을 실제 환경의 분포에 맞게 조정한다.
Stage I: Synthetic supervised training
먼저 합성 렌더링 데이터셋을 사용하여 모델을 학습시킨다. 이 단계를 통해 모델은 이미지 기반 음영 단서와 HDR lighting 간의 기본적인 관계를 학습할 수 있다.
\[\begin{equation} \mathcal{L}_{I} (\theta) = \mathbb{E}_{\textbf{z}_0, \epsilon \sim \mathcal{N}(0,I), t \sim \mathcal{U}(T)} \left[ \| \epsilon - \mu_\theta (\textbf{z}_t, \textbf{c}, t) \|_2^2 \right] \end{equation}\](\(\bar{z}_0 = [\textbf{z}^\textrm{ldr}, \textbf{z}^\textrm{log}]\)은 깨끗한 latent, $\textbf{c}$는 입력 동영상의 latent)
학습 과정에서 tone mapping 표현이 누락된 경우에 대한 robustness를 높이기 위해 0.1의 확률로 \(\textbf{z}^\textrm{ldr}\) 또는 \(\textbf{z}^\textrm{log}\) 중 하나를 무작위로 제거한다.
Stage II: Semantic adaptation
두 번째 단계에서는 입력 이미지와 예측된 HDR environment map 간의 semantic 일치도를 향상시키기 위해 모델을 fine-tuning한다.
이 단계에서는 HDR 파노라마 및 LDR 파노라마 동영상을 포함한 실제 데이터 소스를 사용한다. LDR 파노라마 동영상은 HDR GT가 없으므로 LDR의 tonemapping된 구성 요소만 학습시킨다. Overfitting을 방지하고 사전 학습된 모델의 용량을 유지하기 위해 LoRA fine-tuning을 적용하여 transformer layer에 주입된 작은 크기의 파라미터 \(\Delta \theta\)를 최적화시킨다.
\[\begin{equation} \mathcal{L}_{II} (\Delta \theta) = \mathbb{E}_{\textbf{z}_0, \epsilon \sim \mathcal{N}(0,I), t \sim \mathcal{U}(T)} \left[ \| \epsilon - \mu_{\theta + \Delta \theta} (\textbf{z}_t, \textbf{c}, t) \|_2^2 \right] \end{equation}\]Experiments
- 구현 디테일
- GPU: NVIDIA A100 16개
- 입력 해상도: 512$\times$512 ~ 480$\times$720
- 출력 해상도: 128$\times$256 ~ 256$\times$512
- 동영상 프레임 수: 9, 17, 25
- batch size: 48
- iteration: 12,000 / 5,000
- LoRA rank: 64
1. Image Lighting Estimation
다음은 이미지에서의 lighting 추정 결과이다.

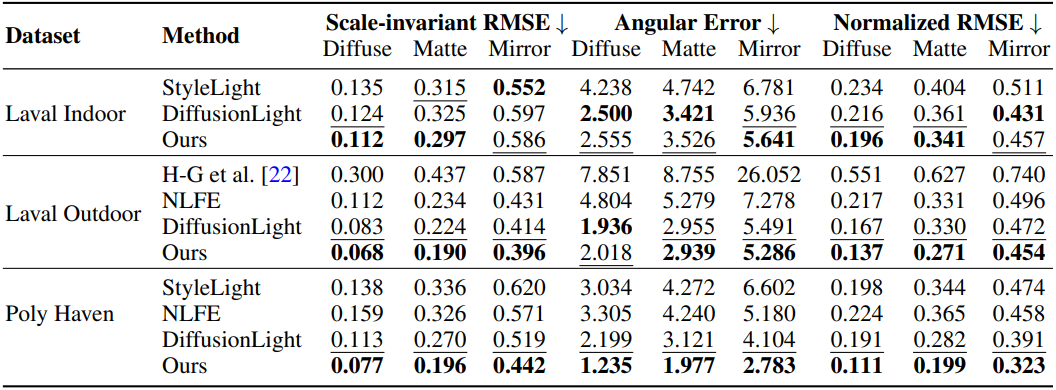
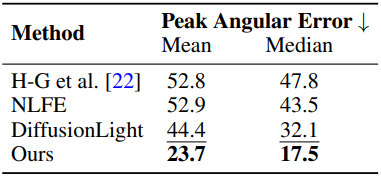
다음은 최대 luminance 방향의 각도 오차이다. (Laval Outdoor sunny)
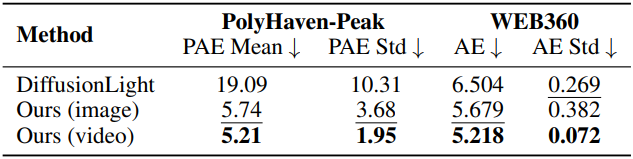
2. Video Lighting Estimation
다음은 동영상에서의 lighting 추정 결과이다.

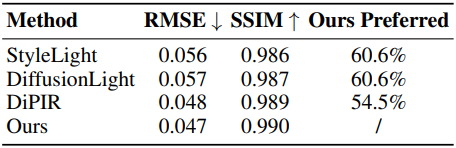
3. Virtual Object Insertion
다음은 virtual object insertion 결과이다.

4. Ablation Study
다음은 디자인 선택과 학습 데이터에 대한 ablation study 결과이다.

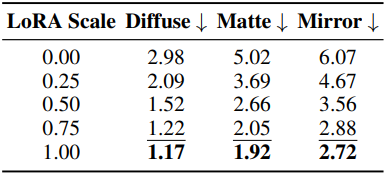
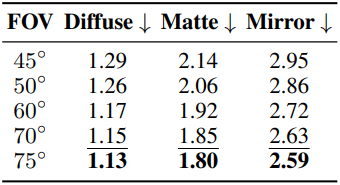
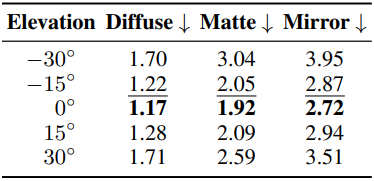
다음은 LoRA scale, 카메라 FOV, 카메라 고도에 대한 ablation study 결과이다.