[논문리뷰] Lumiere: A Space-Time Diffusion Model for Video Generation
arXiv 2024. [Paper] [Page] [Video]
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, Yuanzhen Li, Michael Rubinstein, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, Inbar Mosseri
Google Research | Weizmann Institute | Tel-Aviv University | Technion
23 Jan 2024

Introduction
이미지 생성 모델은 최근 몇 년간 엄청난 발전을 이루었다. SOTA text-to-image(T2I) diffusion model은 이제 복잡한 텍스트 프롬프트를 준수하는 고해상도의 사실적인 이미지를 합성할 수 있으며 광범위한 이미지 편집 및 기타 다운스트림 작업이 가능하다. 그러나 대규모 text-to-video(T2V) 기반 모델을 학습시키는 것은 모션으로 인한 추가 복잡성으로 인해 여전히 해결되지 않은 과제로 남아 있다. 자연스러운 움직임을 모델링할 때 오차에 민감할 뿐만 아니라 추가된 시간 데이터 차원으로 인해 메모리 및 컴퓨팅 요구 사항은 물론 이러한 보다 복잡한 분포를 학습하는 데 필요한 학습 데이터의 규모 측면에서 심각한 문제가 발생한다. 결과적으로 T2V 모델이 빠르게 개선되고 있지만, 기존 모델들은 동영상 길이, 전반적인 시각적 품질, 생성할 수 있는 사실적인 모션의 정도 측면에서 여전히 제한적이다.
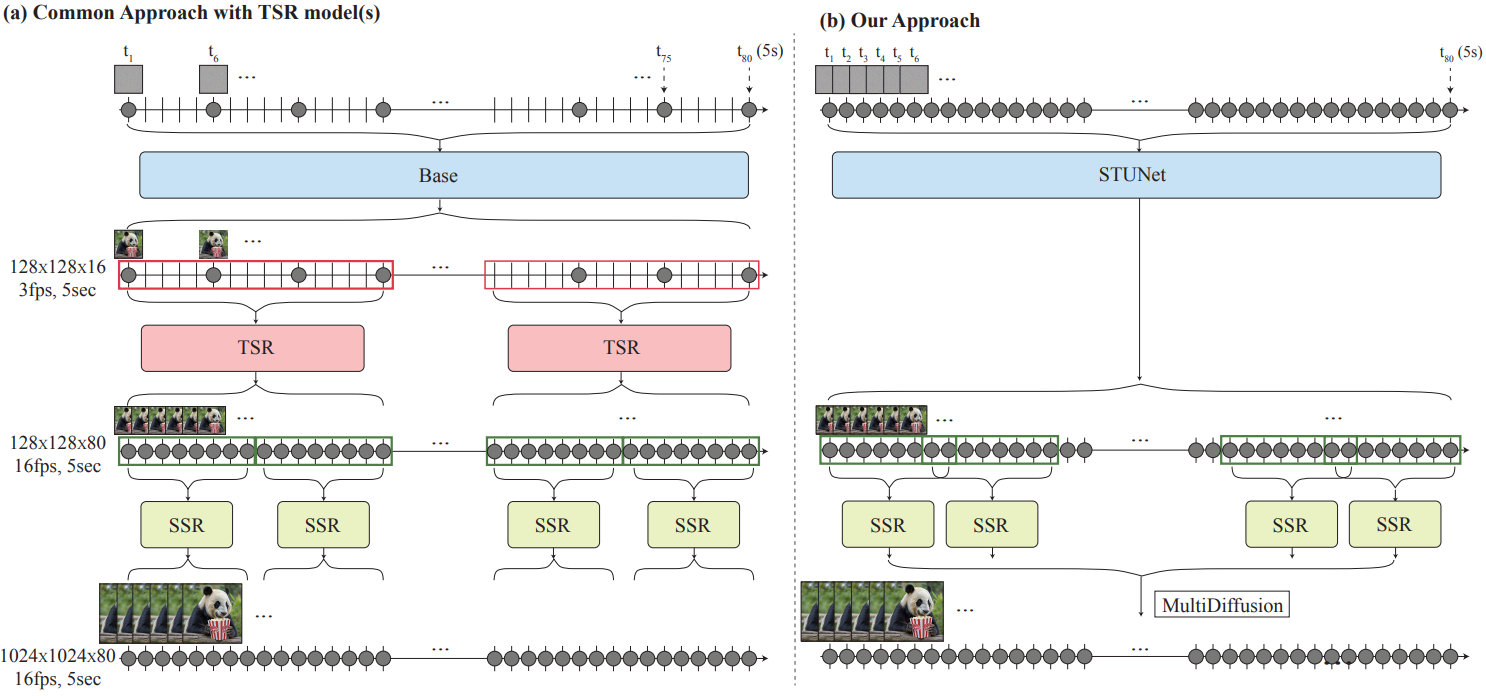
기존 T2V 모델 중 널리 사용되는 접근 방식은 base model이 먼 키프레임을 생성하고 이후에 temporal super-resolution(TSR) 모델이 키프레임 사이에 누락된 데이터를 생성하는 계단식 디자인을 채택하는 것이다. 메모리는 효율적이지만 글로벌하게 일관된 모션을 생성하는 능력은 본질적으로 다음과 같은 이유로 제한된다.
- Base model은 공격적으로 서브샘플링된 키프레임 세트를 생성한다. 여기서 빠른 모션은 일시적으로 앨리어싱되어 모호해진다.
- TSR 모듈은 작고 고정된 시간적 context window으로 제한되므로 전체 동영상에서 앨리어싱 모호성을 일관되게 해결할 수 없다 (ex. 걷기와 같은 주기적인 동작을 합성하는 경우).
- 계단식 학습 방식은 일반적으로 도메인 차이를 겪는다. TSR 모델은 실제 다운샘플링된 동영상 프레임에 대해 학습되지만 inference 시 생성된 프레임을 보간하는 데 사용되어 오차가 누적된다.
본 논문은 동영상 전체를 한 번에 생성하는 새로운 T2V diffusion 프레임워크를 도입하여 다른 접근 방식을 취하였다. 공간과 시간 모두에서 신호를 다운샘플링하는 방법을 학습하고 대부분의 계산을 컴팩트한 시공간 표현으로 수행하는 Space-Time U-Net (STUNet) 아키텍처를 사용하여 이를 달성하였다. 이 접근 방식을 사용하면 16fps의 80프레임(5초)을 생성할 수 있다. 이는 하나의 base model을 사용하는 대부분 방법의 평균 길이보다 길기 때문에 전반적으로 일관된 모션을 얻을 수 있다. 놀랍게도 이 디자인 선택은 아키텍처에 공간적 다운샘플링 및 업샘플링 연산만 포함하고 네트워크 전체에서 고정된 시간 해상도를 유지하는 규칙을 따르는 이전 T2V 모델에서는 간과되었다.
저자들은 T2I 모델의 강력한 generative prior를 활용하기 위해 사전 학습된 T2I 모델 위에 Lumiere를 구축하는 트렌드를 따랐다. T2I 모델은 픽셀 공간에서 작동하며 base model과 spatial super-resolution (SSR) 네트워크의 계단식 구조로 구성된다. SSR 네트워크는 높은 공간 해상도에서 작동하기 때문에 동영상 전체에 적용하는 것은 메모리 요구 사항 측면에서 불가능하다. 일반적인 SSR은 동영상을 겹치지 않는 세그먼트로 분할하고 결과를 함께 연결하는 temporal windowing 접근 방식을 사용한다. 그러나 이로 인해 window 사이의 경계에서 결과가 일관되지 않을 수 있다. 저자들은 파노라마 이미지 생성에서 글로벌 연속성을 위해 제안된 접근 방식인 Multidiffusion을 시간 도메인으로 확장하여 temporal window에서 SSR을 계산하고 결과를 전체 동영상 클립에 대해 글로벌하게 일관되게 집계하는 것을 제안하였다.
Lumiere
본 논문은 생성적 접근 방식으로 diffusion model을 활용하였다. 이러한 모델은 일련의 denoising model을 통해 데이터 분포(본 논문의 경우 동영상에 대한 분포)를 근사화하도록 학습되었다. Diffusion model은 Gaussian noise에서 시작해서 근사된 타겟 분포에서 추출된 깨끗한 샘플에 도달할 때까지 점차적으로 noise를 제거한다. Diffusion model은 텍스트 임베딩 또는 공간적 컨디셔닝(ex. depth map)과 같은 추가 guidance 신호를 통합하여 조건부 분포를 학습할 수 있다.
Lumiere의 프레임워크는 base model과 spatial super-resolution(SSR) 모델로 구성된다. Base model은 coarse한 공간 해상도에서 전체 클립을 생성한다. Base model의 출력은 SSR 모델을 사용하여 공간적으로 업샘플링되어 고해상도 동영상을 생성한다.
1. Space-Time U-Net (STUnet)
문제를 계산하기 쉽게 만들기 위해 입력 신호를 공간적, 시간적으로 다운샘플링하고 대부분의 계산을 이 컴팩트한 시공간 표현에서 수행하는 Space-Time U-Net (STUnet)을 사용한다. 저자들은 생체 의학 데이터의 효율적인 처리를 위해 3D pooling 연산을 포함하도록 U-Net 아키텍처를 일반화한 3D U-Net으로부터 영감을 얻었다.
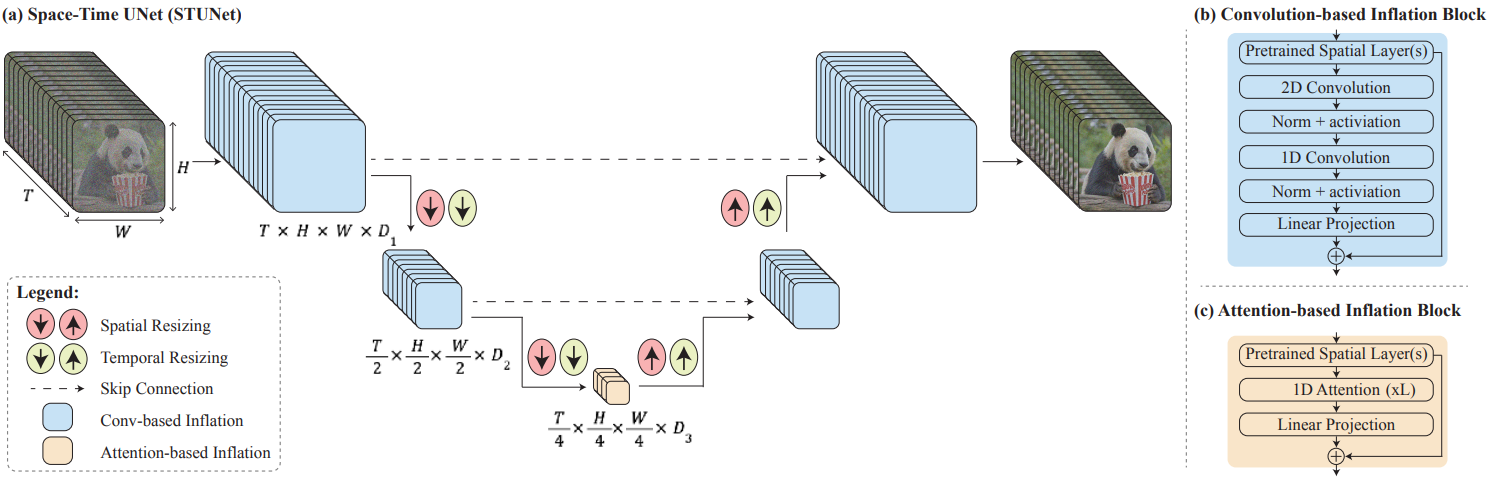
STUnet의 아키텍처는 위 그림에 설명되어 있다. T2I 아키텍처에서 temporal block을 인터리브하고 사전 학습된 각 spatial resizeing 모듈 뒤에 시간적 다운샘플링 모듈과 업샘플링 모듈을 삽입한다. Temporal block에는 temporal convolution과 temporal attention이 포함된다. 구체적으로, 가장 coarse한 레벨을 제외한 모든 레벨에서 full-3D convolution에 비해 네트워크의 비선형성을 증가시키면서 계산 비용을 줄이고 1D convolution에 비해 표현력을 높이는 factorized space-time convolution을 삽입하였다. Temporal attention의 계산 요구량은 프레임 수의 제곱에 비례하므로 동영상의 시공간 압축 표현을 포함하는 가장 coarse한 해상도에만 temporal attention을 통합한다. 저차원 feature map에서 연산하면 제한된 계산 오버헤드로 여러 개의 temporal attention block을 쌓을 수 있다.
Video LDM, AnimateDiff과 유사하게 새로 추가된 파라미터를 학습시키고 사전 학습된 T2I의 가중치를 고정된 상태로 유지한다. 특히, 일반적인 inflation 접근 방식은 초기화 시 T2V 모델이 사전 학습된 T2I 모델과 동일함을 보장한다. 즉, 독립적인 이미지 샘플 컬렉션으로 동영상을 생성한다. 그러나 Lumiere의 경우 시간적 다운샘플링 모듈과 업샘플링 모듈로 인해 이 속성을 만족하는 것이 불가능하다. 저자들은 nearest-neighbor 다운샘플링 및 업샘플링 연산을 수행하도록 모듈을 초기화하는 것이 좋은 시작점이 된다는 것을 경험적으로 발견했다.
2. Multidiffusion for Spatial-Super Resolution
메모리 제약으로 인해 확장된 SSR 네트워크는 동영상의 짧은 세그먼트에서만 작동할 수 있다. 시간적 경계에서 발생하는 아티팩트를 방지하기 위해 시간 축을 따라 Multidiffusion을 사용하여 시간 세그먼트 간의 원활한 전환을 달성한다. 각 생성 step에서 noisy한 입력 동영상 $J \in \mathbb{R}^{H \times W \times T \times 3}$를 겹치는 세그먼트들의 집합 \(\{J_i\}_{i=1}^N\)로 분할한다. 여기서 $J_i \in \mathbb{R}^{H \times W \times T^\prime \times 3}$은 $i$번째 세그먼트이며, 길이가 $T^\prime < T$이다. 세그먼트별 SSR 예측 \(\{\Phi (J_i)\}_{i=1}^N\)을 조정하기 위해 denoising step의 결과를 다음과 같은 최적화 문제의 해로 정의한다.
\[\begin{equation} \underset{J^\prime}{\arg \min} \sum_{i=1}^n \| J^\prime - \Phi (J_i) \|^2 \end{equation}\]이 문제에 대한 해는 겹치는 window에 대한 예측의 선형 결합이다.
Evaluation and Comparisons
- 데이터셋: 텍스트 캡션이 포함된 3,000만 개의 동영상 (80프레임, 5초)
- 해상도: Base model은 128$\times$128로 학습, SSR은 1024$\times$1024를 출력
다음은 동영상 생성 결과들이다.

1. Qualitative Evaluation
다음은 T2V diffusion model들과 생성 결과를 비교한 것이다.

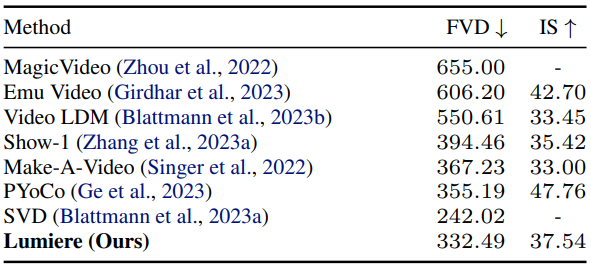
2. Quantitative Evaluation
다음은 UCF101에서 zero-shot T2V 생성 결과를 정량적으로 비교한 표이다.
다음은 user study 결과이다.

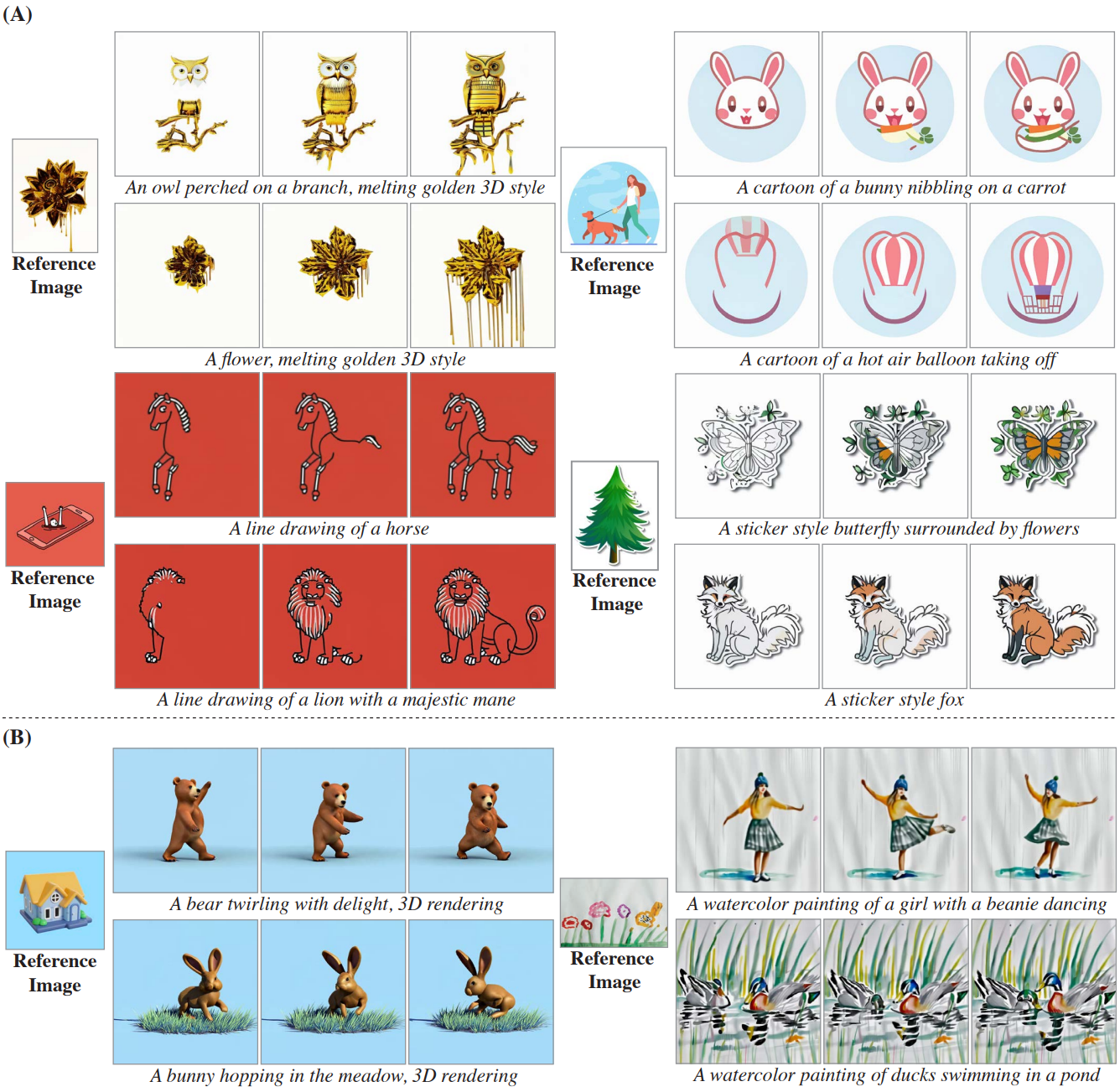
3. Applications
Stylized Generation
Inpainting

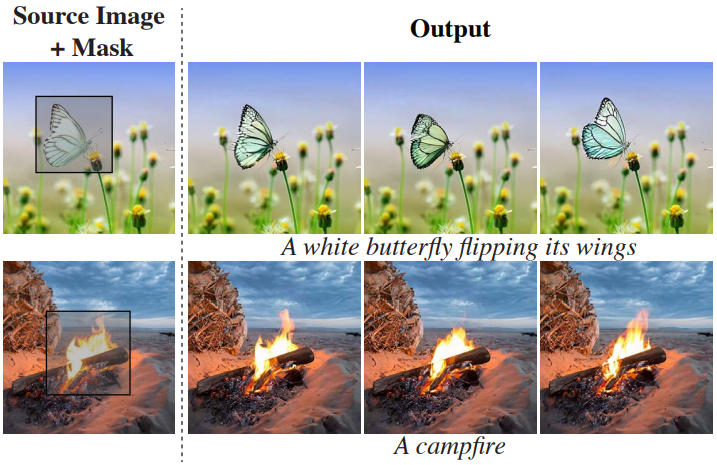
Cinemagraphs
Video-to-video via SDEdit
