[논문리뷰] LT3SD: Latent Trees for 3D Scene Diffusion
CVPR 2025. [Paper] [Page]
Quan Meng, Lei Li, Matthias Nießner, Angela Dai
Technical University of Munich
12 Sep 2024
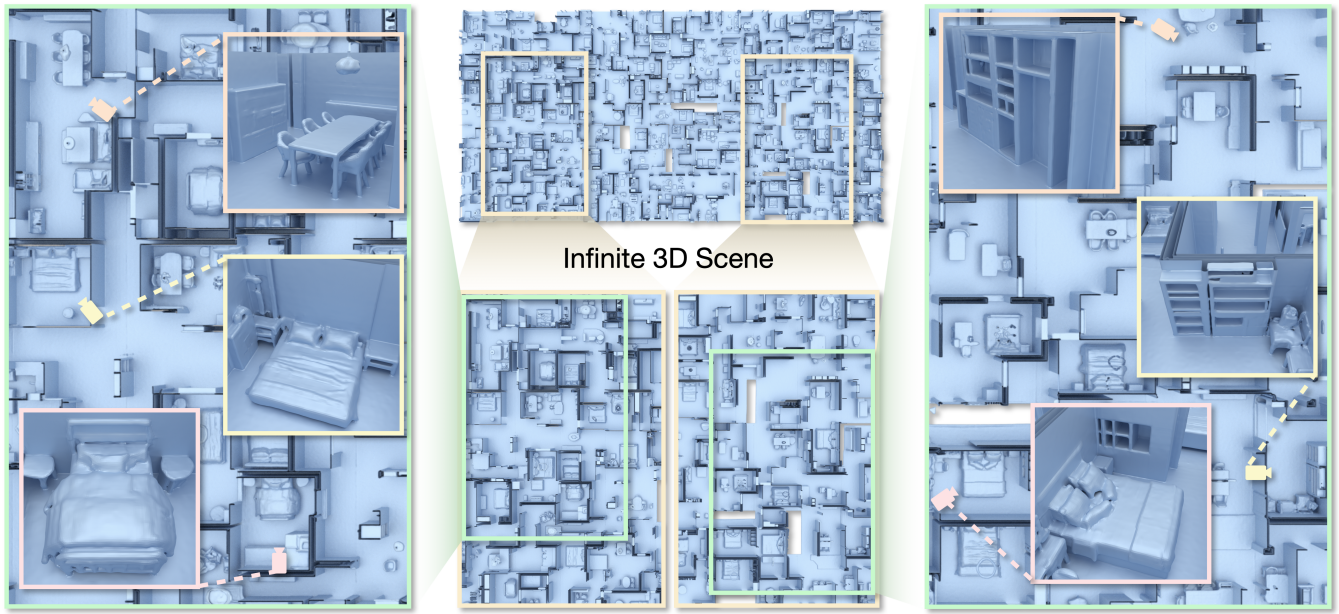
Introduction
본 논문은 고품질의 대규모 임의 크기의 3D 장면을 생성하는 새로운 확률론적 모델인 LT3SD를 제안하였다. LT3SD의 핵심은 3D 장면을 fine한 해상도에서 coarse한 해상도까지 점진적으로 트리 구조로 분해하는 새로운 latent tree 표현이다. 이 latent tree 표현은 3D 장면을 저주파의 형상 볼륨과 고주파의 latent feature 볼륨으로 효율적으로 분해하여 diffusion을 위한 더욱 간결하고 효과적인 표현을 가능하게 한다. 그런 다음, latent tree 분해를 역으로 수행하여 coarse한 해상도에서 fine한 해상도로, 패치별로 3D 장면을 합성한다.
저자들은 동일 트리 레벨에서 해당 형상 볼륨을 조건으로 latent feature 볼륨을 생성하는 latent tree 기반 diffusion model을 도입하였다. 장면 디테일에 대한 이러한 조건부 학습은 3D 장면 분포 모델링의 복잡성을 줄이는 데 도움이 된다. 3D 장면은 크기가 상당히 다양할 수 있으므로, 본 연구에서는 장면 패치 레벨에서 학습하도록 diffusion model을 설계했다. 이 전략은 복잡하고 정렬되지 않은 3D 장면에서 공유 유사도가 더 높은 로컬 구조로 학습 초점을 전환하는 데 도움이 된다.
결과적으로, LT3SD는 latent tree를 패치 단위로 coarse-to-fine하게 구성함으로써 대규모, 심지어 무한대 규모의 3D 장면을 생성할 수 있다. 본 방법은 가장 coarse한 레벨에서 시작하여 패치 단위로 작동하여 기하학적 일관성에 중요한 3D 장면의 전체 구조를 생성한다. 그런 다음, coarse-to-fine 방식으로 조건부로 latent feature 볼륨을 생성한다. 이 볼륨은 각 상위 레벨의 디테일을 나타내며, 최종 3D 장면은 latent tree 분해의 역과정을 통해 생성된다. LT3SD는 3D 장면 생성 task에서 FID 점수를 70% 향상시켰다.
Method
1. Latent Tree Representation for 3D Scenes
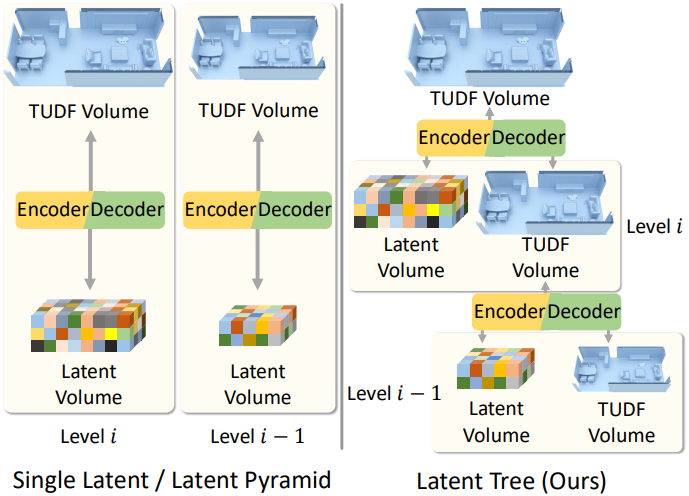
본 논문에서는 고품질의 3D 장면 생성을 위해, 3D 장면을 latent tree 표현으로 변환하는 것을 제안하였다. 계층의 각 레벨은 해당 해상도에서 장면의 형상 구조와 latent feature로 구성된다. 저주파의 형상 구조는 truncated unsigned distance field (TUDF) 그리드로 인코딩되며, 고주파의 장면 디테일은 latent feature 그리드로 인코딩된다.
Latent tree 표현은 다음과 같은 장점을 제공한다.
- 공유된 로컬 구조를 잘 표현하지 못하는 단일 latent tree와 달리, 복잡한 장면 형상 구조를 coarse-to-fine하게 생성할 수 있다.
- Latent pyramid와 비교할 때, latent tree는 더 높은 재구성 품질로 3D 장면을 더 잘 인코딩한다.
구성
Latent tree 표현을 구성하기 위해 먼저 3D 장면에 대한 UDF를 계산한다. UDF는 다양한 토폴로지를 가진 임의의 3D 장면 형상 구조를 쉽게 인코딩할 수 있다. 표면 형상 구조 영역에 집중하고 데이터 분포 복잡도를 줄이기 위해, 지정된 threshold $\tau$를 초과하는 거리를 잘라내어 TUDF 복셀 격자를 얻는다.
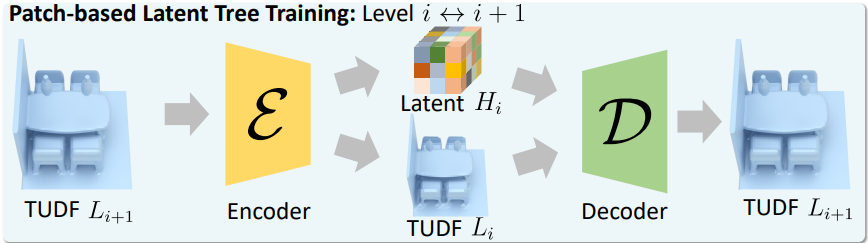
구체적으로, 3D 장면의 TUDF 그리드를 $N$ 레벨의 latent tree로 분해한다. 각 장면 해상도 레벨 $i \in [1, N-1]$은 TUDF 그리드 $L_i^s$와 latent feature 그리드 $H_i^s$로 구성된다. 트리의 루트, 즉 가장 높은 해상도는 $L_N^s$이다. 계산 효율성을 위해 장면 그리드 $L_{i+1}^s$에서 임의로 잘라낸 고정 크기 패치 $L_{i+1}$을 사용하여 이 분해 과정을 학습시킨다. 모든 장면 레벨은 패치 기반 학습을 통해 병렬로 학습할 수 있다.
해상도 레벨 $i+1$에서 인코더 \(\mathcal{E}_{i+1}\)을 사용하여 TUDF 패치 $L_{i+1}$을 더 낮은 해상도의 TUDF 패치 $L_i$와 latent feature 패치 $H_i$로 분해한다.
\[\begin{aligned} &\mathcal{E}_{i+1} (L_{i+1}) \; \Rightarrow \; [L_i, H_i] \\ &\textrm{where} \; L_i \in \mathbb{R}^{1 \times D_i \times H_i \times W_i}, \; H_i \in \mathbb{R}^{C \times D_i \times H_i \times W_i} \end{aligned}\]실제로 $L_i$는 average pooling으로 $L_{i+1}$을 downsampling하여 계산하고, $H_i$는 3D CNN으로 예측한다.
그런 다음, 분해된 그리드 $L_i$와 $H_i$를 결합하여 TUDF 패치 $L_{i+1}$을 재구성하기 위해 디코더 네트워크 \(\mathcal{D}_{i+1}\)을 학습시킨다.
\[\begin{equation} \mathcal{D}_{i+1} ([L_i, H_i]) \; \Rightarrow \; L_{i+1} \end{equation}\]디코더 \(\mathcal{D}_{i+1}\)도 3D CNN으로 구현된다.
학습
인코더와 디코더를 학습시키기 위해, loss는 재구성된 TUDF와 실제 TUDF 사이의 $\ell_2$ error로 계산된다.
\[\begin{equation} \mathcal{L}_\textrm{latent} = \left( L_{i+1} - \mathcal{D}_{i+1} \left( \mathcal{E}_{i+1} (L_{i+1}) \right) \right)^2 \end{equation}\]학습된 인코더가 주어지면 고해상도, 임의 크기의 3D 장면을 점진적으로 컴팩트한 latent tree \(\{L_1^s, H_1^s, \cdots, L_{N-1}^s, H_{N-1}^s\}\)로 분해할 수 있다.
2. Patch-Based Latent Scene Diffusion
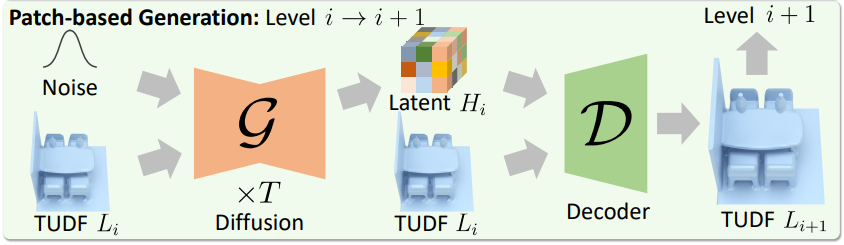
Latent tree의 각 해상도 레벨 $i$에 대해 diffusion model \(\mathcal{G}_i\)를 학습시켜 충실도가 높은 3D 장면을 생성한다. Latent tree의 명시적 분해를 활용하여 \(\mathcal{G}_i\)를 학습시켜 형상 그리드 $L_i^s$에 조건부로 latent feature 그리드 $H_i^s$를 생성한다. 3D 장면은 일반적으로 공통된 유사성을 가진 로컬 구조로 구성되므로, diffusion model은 장면 그리드에서 무작위로 잘라낸 장면 패치를 기반으로 학습된다.
Diffusion model \(\mathcal{G}_i (z_t, t, c)\)는 조건 $c$에 따라 각 timestep $t$에서 noise가 추가된 latent 패치 $z_t$의 noise를 제거한다. 각 학습 단계에서 동일한 크기의 Gaussian noise 패치 $\epsilon \sim \mathcal{N}(0,1)$와 timestep $t \in [1, T]$을 무작위로 샘플링하고, latent 패치 $z$에 적용하여 $z_t$를 얻는다.
레벨 $i > 1$에서 \(\mathcal{G}_i\)를 학습시켜 coarse한 형상 패치 $L_i$를 조건으로 대응되는 latent feature 패치 $H_i$를 예측한다. 즉, $z = H_i$이고 $c = L_i$이다. 레벨 $i = 1$에서 \(\mathcal{G}_1\)은 $L_i$와 $H_i$ 두 그리드를 조건 없이 생성한다. 즉, $z = [L_i, H_i]$이고 $c = \varnothing$이다. Diffusion model \(\mathcal{G}_i\)는 다음과 같은 학습 loss를 사용하여 $z_t$의 noise를 제거하는 방법을 학습한다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \mathbb{E}_{z, c, \epsilon, t} [ \| \epsilon - \mathcal{G}_i (z_t, t, c) \|_2^2 ] \end{equation}\]Diffusion model \(\{\mathcal{G}_i\}\)는 3D UNet 백본을 기반으로 구축된다. 패치별 학습 전략은 data augmentation 역할도 수행하여, 모델이 overfitting을 피하고 여러 장면에서 공유되는 로컬 구조를 학습하는 데 도움을 준다. 조건부 diffusion 모델링은 3D 장면을 각 해상도 수준에서 상호 보완적인 형상 그리드와 latent feature 그리드로 분해하여 저주파 구조와 고주파 디테일을 모두 포착할 수 있다. Diffusion model은 패치별로 장면을 생성하여 임의 크기의 3D 장면 출력을 합성할 수 있다.
3. Large-Scale Scene Generation
Inference 시에 대규모 3D 장면 생성은 계층적 latent tree 표현과 장면 패치에서 학습된 diffusion model을 통해 가능하다. 생성 과정은 latent tree 분해를 역으로 진행하여 coarse한 레벨에서 fine한 레벨로 계층 구조를 구축한다. 각 해상도 레벨에서 장면은 패치 단위로 합성되어 임의의 크기의 3D 출력을 제공한다.
패치별 장면 생성
Latent tree를 처음부터 구축하기 위해, 먼저 학습된 \(\mathcal{G}_1\)을 사용하여 가장 낮은 해상도 레벨 $i = 1$에서 coarse한 장면 구조를 생성한다. 즉, 랜덤 Gaussian noise에서 시작하여 \(\mathcal{G}_1\)을 적용하여 장면의 형상 그리드 $L_1^s$와 latent feature 그리드 $H_1^s$를 조건 없이 생성한다. 추가 네트워크 없이 간단한 인페인팅 기반 패치 생성 알고리즘을 사용하면 매끄럽고 매끄러운 3D 장면을 생성하는 데 효과적이다.
$L_1^s$와 $H_1^s$의 패치는 $xy$ 평면에서 autoregressive하게 합성된다. 너비 우선 패치 순서 체계를 채택한다. 알려진 각 패치 $z_0$에서 먼저 $x$ 방향으로 인접한 패치를 생성한 다음 $y$ 방향으로 생성한다. 이 과정은 장면 생성 프로세스에서 반복된다. 패치 간의 원활한 전환을 보장하기 위해 \(\mathcal{G}_1\)에 의해 생성되는 각 패치는 기존 패치와 부분적으로 겹치도록 생성된다. 모든 해상도 레벨에서 동일한 크기로 패치를 겹친다.
구체적으로, LDM을 따르고, autoregressive한 Stable Inpainting 체계를 채택하였다.
\[\begin{equation} z_{t-1} = m \odot z_{t-1}^\textrm{known} + (1-m) \odot z_{t-1}^\textrm{unknown} \end{equation}\]여기서 \(z_{t-1}^\textrm{known}\)은 기존 패치 $z_0$에서 샘플링되고, \(z_{t-1}^\textrm{unknown}\)은 이전 denoising 과정 $z_t$에서 샘플링된다. 이 두 샘플은 인페인팅 마스크 $m$을 사용하여 결합되어 새로운 샘플 $z_{t−1}$을 형성하며, 알려진 영역은 변경되지 않는다.
Coarse-to-Fine 정제
그런 다음, 생성된 coarse한 장면을 고해상도 레벨에서 fine-tuning한다. 각 레벨 $i > 1$에서, 먼저 \(L_i^s\)를 \(L_{i-1}^s\)와 $H_{i-1}^s$로부터 학습된 디코더 \(\mathcal{D}_i\)를 사용하여 재구성한다. 다음으로, \(\mathcal{G}_i\)는 패치 레벨에서 \(L_i^s\)를 기반으로 중첩되는 \(H_i^s\)를 생성한다.
그러나 고해상도 레벨에서 패치를 순차적으로 생성하거나 패치가 훨씬 더 많은 무한한 장면을 생성하는 것은 매우 시간이 많이 걸릴 수 있다. Inference 속도를 높이기 위해 MultiDiffusion의 denoising fusion 방식을 채택하여 모든 패치에 대해 각 denoising step을 동시에 수행한다.
먼저, 생성된 coarse한 3D 장면을 이전 레벨과 동일한 중첩 크기를 갖는 $n$개의 패치로 나눈다. 그런 다음, \(\mathcal{G}_i\)는 \(L_i^s\)의 형상 패치를 조건으로 noise가 추가된 장면 그리드 $z_t^s$의 모든 패치에 대해 병렬로 denoising step을 수행한다. 마지막으로, 집계 단계 $\mathcal{A}$는 중첩 영역의 예측을 평균화하여 패치를 혼합하여 패치 간 부드러운 전환을 보장하고 매끄러운 3D 장면을 생성한다.
구체적으로, 장면 해상도 레벨 $i$에서 각 denoising step $t$는 다음과 같다.
\[\begin{aligned} z_{t-1}^j &= \mathcal{G}_i \left( F_j (z_t^s), t, F_j (L_i^s) \right) \\ z_{t-1}^s &= \mathcal{A} \left( \{ z_{t-1}^j \}_{j=1}^n \right) \end{aligned}\]$F_j$는 장면 그리드 $z_t^s$와 $L_i^s$에서 각각 $j$번째 패치를 잘라내는 연산이다. 장면의 latent feature 볼륨 $H_i^s$는 모든 denoising step을 완료한 후에 얻어진다 (즉, $H_i^s = z_0^s$).
그런 다음, 디코더 \(\mathcal{D}_i\)와 diffusion model \(\mathcal{G}_i\)를 교대로 적용하여 최상위 레벨 $N$의 장면 형상 구조 $L_N^s$가 최종 출력으로 합성될 때까지 진행한다.
Experiments
- 데이터셋: 3D-FRONT
- 구현 디테일
- GPU: RTX A6000 2개
- latent tree 레벨: $N = 3$
- optimizer: Adam
- 인코더-디코더 학습
- batch size: 4
- learning rate: $10^{-4}$
- 학습에 트리 레벨에 따라 5시간에서 1일 소요
- Diffusion model 학습
- batch size: 8
- learning rate: $10^{-4}$
- 학습에 약 6일 소요
1. 3D Scene Generation
다음은 정성적 비교 결과이다.

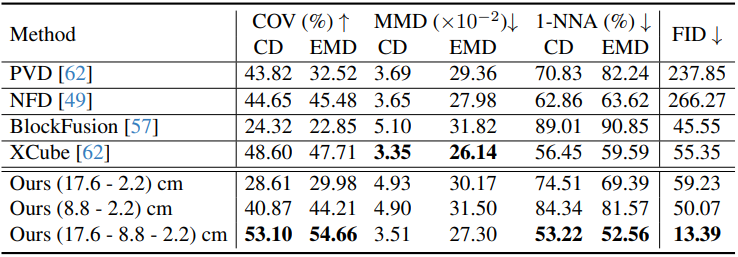
다음은 다른 방법들과의 정량적 비교 결과이다.
2. Ablation Study
다음은 latent 표현에 대한 ablation 결과이다.

3. Novelty of Generated Scene Patches
다음은 생성된 패치와 비슷한 학습 패치 4개를 Chamfer distance로 검색하여 비교한 결과이다.

4. Probabilistic Scene Completion
다음은 장면 완성 예시들이다.
