[논문리뷰] Language-driven Semantic Segmentation (LSeg)
ICLR 2022. [Paper] [Github]
Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, René Ranftl
Cornell University | University of Copenhagen | Apple | Intel Labs
10 Jan 2022
Introduction
Semantic segmentation을 위한 대부분의 기존 방법은 잠재적으로 픽셀에 할당될 수 있는 제한된 semantic 클래스 레이블 집합을 가정하였다. 클래스 레이블 수는 학습 데이터셋에 따라 결정되며 일반적으로 수십에서 수백 개의 카테고리에 이른다. 영어는 수십만 개의 명사를 정의하므로 레이블 집합의 제한된 크기로 인해 기존 semantic segmentation 모델의 잠재적인 성능이 심각하게 저하될 가능성이 높다.
기존 방법에서 제한된 레이블 집합을 사용하는 주된 이유는 충분한 학습 데이터를 생성하기 위해 이미지에 주석을 추가하는 데 드는 비용 때문이다. 학습 데이터셋을 생성하려면 사람이 직접 수천 개의 이미지에 있는 모든 픽셀을 semantic 클래스 레이블과 연결해야 한다. 이는 매우 노동 집약적이고 비용이 많이 드는 작업이다. 사람이 세밀하게 후보 레이블을 인식해야 하므로 레이블 수가 증가함에 따라 주석의 복잡성이 크게 증가한다. 또한 여러 가지 설명에 적합하거나 레이블 계층의 적용을 받는 이미지에 개체가 있는 경우 사람 간의 일관성이 문제가 발생한다.
이 문제에 대한 잠재적인 해결책으로 zero-shot 및 few-shot semantic segmentation 방법이 제안되었다. Zero-shot 방법은 일반적으로 단어 임베딩을 활용하여 추가 주석 없이 알고 있는 클래스와 처음 보는 클래스 간의 관련된 feature들을 검색하거나 생성한다. 기존 zero-shot 연구들은 표준 단어 임베딩을 사용하고 이미지 인코더에 중점을 두었다.
본 논문에서는 언어 모델을 활용하여 semantic segmentation 모델의 유연성과 일반성을 높이는 간단한 접근 방식을 제시한다. 고용량 이미지와 텍스트 인코더를 결합하여 강력한 zero-shot classifier를 생성하는 이미지 분류용 CLIP 모델에서 영감을 받았다. CLIP과 같은 시각적 데이터에 대해 공동 학습된 SOTA 텍스트 인코더를 사용하여 학습 세트의 레이블을 임베딩하고 이미지 인코더를 학습시켜 픽셀별 임베딩을 생성한다. 텍스트 인코더는 관련된 개념에 가깝게 임베딩되도록 학습되었기 때문에 제한된 레이블들에 대한 학습만으로 텍스트 인코더의 유연성을 이미지 인코더로 이전할 수 있다.
LSeg를 사용하면 zero-shot semantic segmentation 모델을 합성할 수 있다. 즉, 사용자는 테스트 시 모든 이미지에 설정된 레이블을 임의로 확장, 축소 또는 재정렬할 수 있다. 이러한 유연성을 유지하면서 예측을 공간적으로 정규화할 수 있는 출력 모듈을 추가로 도입하였다. LSeg는 제공된 레이블들을 기반으로 다양한 segmentation map을 출력할 수 있다. LSeg는 zero-shot 설정에서 기존 방법보다 성능이 뛰어나며 여러 few-shot 벤치마크에서 경쟁력이 있다. 또한 SOTA 방법들과 달리 추가 학습 샘플이 필요하지 않다.
Language-driven Semantic Segmentation
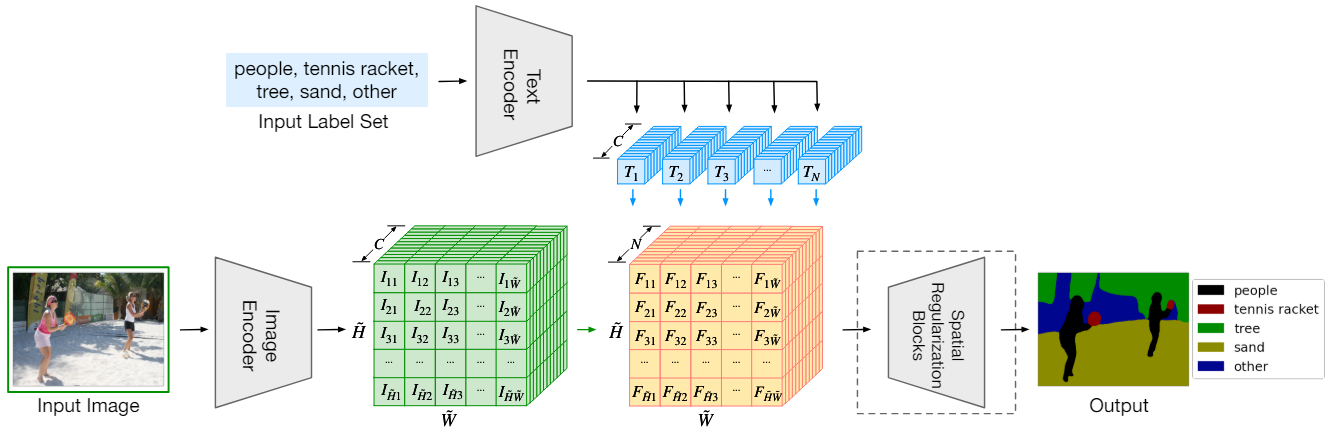
LSeg는 텍스트 레이블과 이미지 픽셀을 공통 공간에 임베딩하고 각 픽셀에 가장 가까운 레이블을 할당한다. 위 그림은 LSeg의 프레임워크이다.
Text encoder
텍스트 인코더는 $N$개의 잠재적 레이블들을 연속 벡터 공간 $\mathbb{R}^C$에 삽입하여 N개의 벡터 $T_1, \ldots, T_n \in \mathbb{R}^C$를 출력으로 생성한다 (파란색 벡터). 여러 아키텍처가 가능하며 사전 학습된 CLIP을 사용한다. 설계상 출력 벡터들은 입력 레이블의 순서에 영향을 받지 않으며 $N$이 자유롭게 변경될 수 있다.
Image encoder
이미지 인코더는 모든 입력 픽셀에 대해 임베딩 벡터를 생성한다. Dense Prediction Transformer (DPT)를 기본 아키텍처로 활용한다. $H \times W$가 입력 이미지 크기이고 $s = 2$가 downsampling factor라고 하면, $\tilde{H} = H / s, \tilde{W} = W / s$로 정의한다. 출력은 dense한 임베딩 $I \in \mathbb{R}^{\tilde{H} \times \tilde{W} \times C}$ (녹색 텐서)이다. 픽셀 $(i, j)$의 임베딩을 $I_{ij}$라고 한다.
Word-pixel correlation tensor
이미지와 레이블이 임베딩된 후 내적으로 상관 관계를 지정하여 다음과 같이 $\tilde{H} \times \tilde{W} \times N$ 크기의 텐서 (주황색 텐서)를 생성한다.
\[\begin{equation} f_{ijk} = I_{ij} \cdot T_k \end{equation}\]픽셀 $(i, j)$와 모든 $N$개의 단어 임베딩 사이의 내적의 N차원 벡터를 $F_{ij} \in \mathbb{R}^N$이라 하자. 여기서 $F_{ij} = (f_{ij1}, f_{ij2}, \ldots, f_{ijk})^\top$이다. 학습 중에 이미지 인코더가 ground-truth 클래스의 텍스트 임베딩에 가까운 픽셀 임베딩을 제공하도록 한다. 구체적으로, $N$개의 레이블의 텍스트 임베딩 $T_k \mathbb{R}^C$와 픽셀 $(i, j)$의 이미지 임베딩 $I_{ij} \in \mathbb{R}^C$가 주어지면 픽셀 $(i, j)$의 ground-truth 레이블 $k = y_{ij}$에 해당하는 내적 $f_{ijk}$를 최대화하는 것을 목표로 한다. 전체 이미지에 대해 픽셀별 softmax로 목적 함수를 정의한다.
\[\begin{equation} \sum_{i,j=1}^{H,W} \textrm{softmax}_{y_{ij}} \bigg( \frac{F_{ij}}{t} \bigg) \end{equation}\]여기서 $t$는 $t = 0.07$로 설정한 temperature 파라미터이다. 학습 중에는 semantic segmentation의 표준에 따라 cross-entropy loss를 사용하여 픽셀별 softmax를 최소화한다.
실제로 Pytorch의 nn.CrossEntropyLoss를 사용
Spatial regularization
메모리 제약으로 인해 이미지 인코더는 입력 이미지 해상도보다 낮은 해상도에서 픽셀 임베딩을 예측한다. 따라서 예측을 원래 입력 해상도로 공간적으로 정규화하고 업샘플링하는 추가 후처리 모듈을 사용한다. 이 프로세스 동안 모든 연산이 레이블과 관련하여 동등하게 유지되도록 해야 한다. 즉, 입력 채널 사이에는 상호 작용이 없어야 하며, 그 순서는 단어의 순서에 따라 정의되므로 임의적일 수 있다.
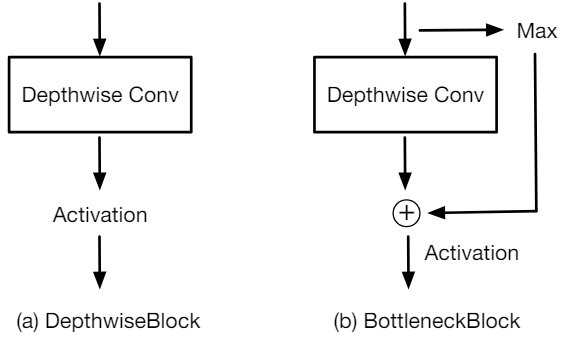
저자들은 이 속성을 충족하는 두 가지 함수를 평가하였다.
- DepthwiseBlock: 여러 depth-wise convolution 후 비선형 activation
- BottleneckBlock: max-pooling 연산의 결과로 depth-wise convolution을 추가로 augment
마지막 단계에서는 bilinear interpolation을 사용하여 원래 해상도에서 예측을 복구한다. 이러한 함수를 spatial regularization blocks라고 한다.
Training details
ViT 또는 ResNet의 공식 ImageNet 사전 학습 가중치를 사용하여 이미지 인코더의 backbone을 초기화하고 DPT 디코더를 랜덤으로 초기화한다. 학습 중에는 텍스트 인코더를 고정하고 이미지 인코더의 가중치만 업데이트한다. 각 학습 세트에 의해 정의된 전체 레이블들을 각 이미지의 텍스트 인코더에 제공한다.
LSeg는 모든 semantic segmentation 데이터셋에 대해 학습할 수 있으며 텍스트 인코더를 통해 여러 데이터셋의 유연한 혼합을 지원한다. 기존 semantic segmentation 모델은 픽셀이 해당 클래스일 확률을 나타내기 위해 출력에 고정 채널을 할당하였다. 이와 대조적으로 LSeg는 길이, 내용, 순서가 다양한 레이블 집합을 동적으로 처리할 수 있다. 이 속성을 사용하면 텍스트 인코더에 제공되는 레이블을 간단히 변경하여 임의의 zero-shot semantic segmentation 모델을 합성할 수 있다.
Experiments
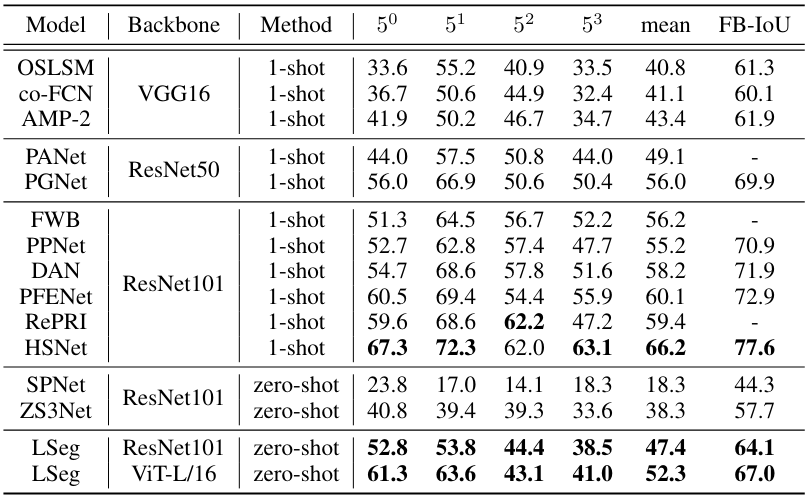
1. PASCAL-$5^i$ & COCO-$20^i$
다음은 PASCAL-$5^i$에서 다른 방법들과 성능을 비교한 표이다.
다음은 COCO-$20^i$에서 다른 방법들과 성능을 비교한 표이다.
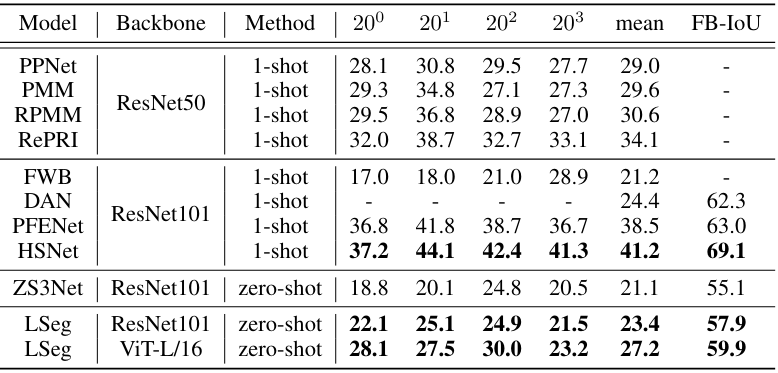
2. FSS-1000
다음은 FSS-1000에서의 mIoU를 다른 방법들과 비교한 표이다.
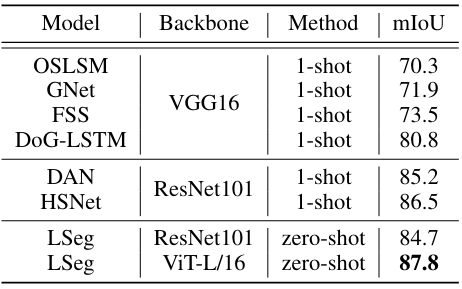
다음은 FSS-1000에서의 zero-shot semantic segmentation 결과들이다.
3. Ablation Studies
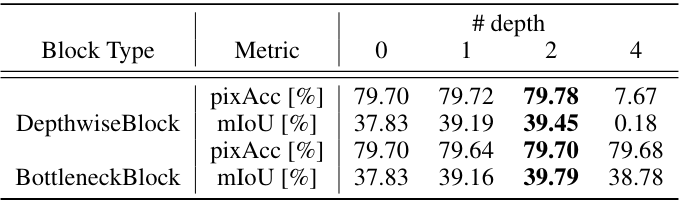
다음은 DepthwiseBlock과 BottleneckBlock의 깊이에 따른 성능을 비교한 표이다.
다음은 텍스트 인코더에 대한 ablation 결과이다. 모두 CLIP으로 사전 학습된 모델들이다.

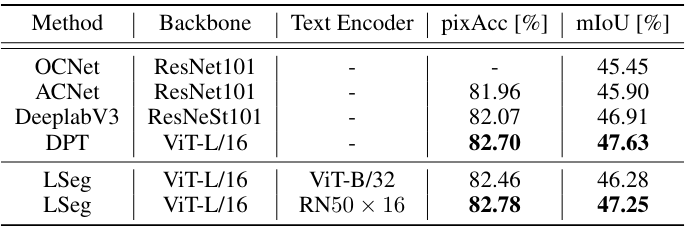
다음은 ADE20K validation set에서의 semantic segmentation 결과를 비교한 표이다.
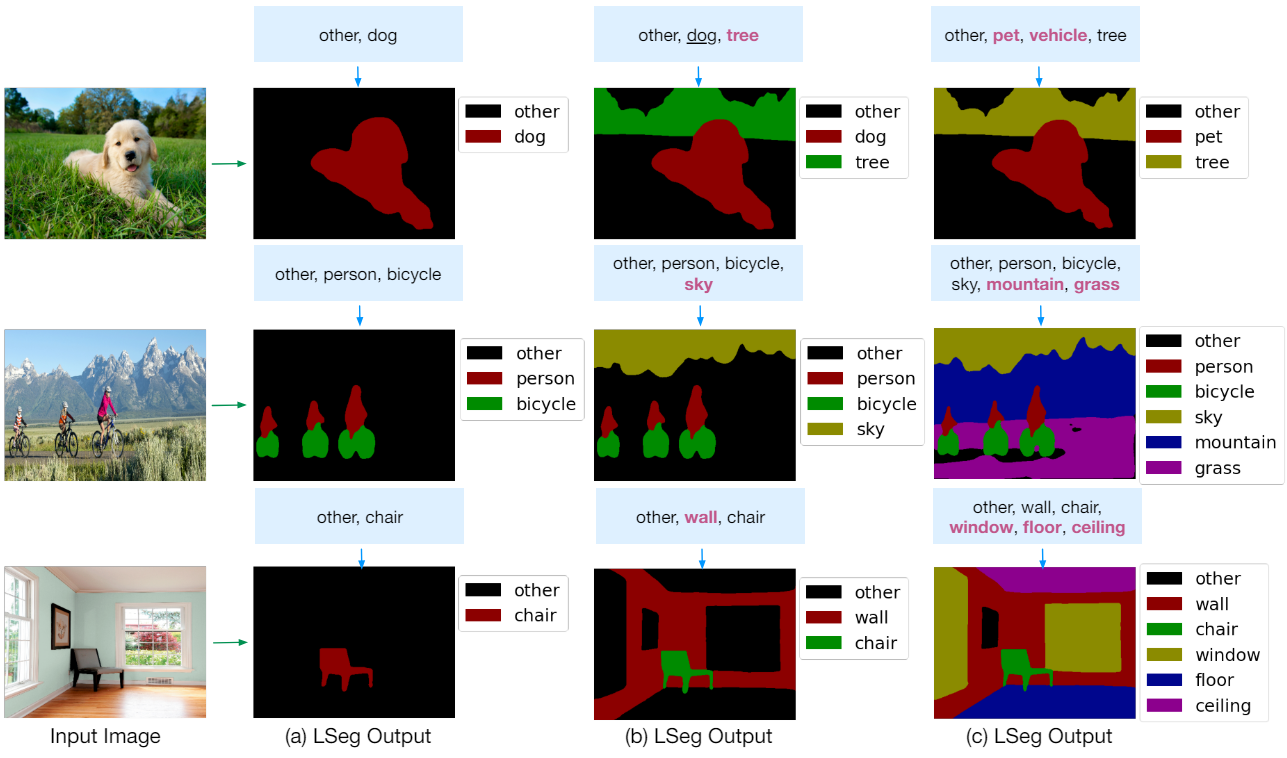
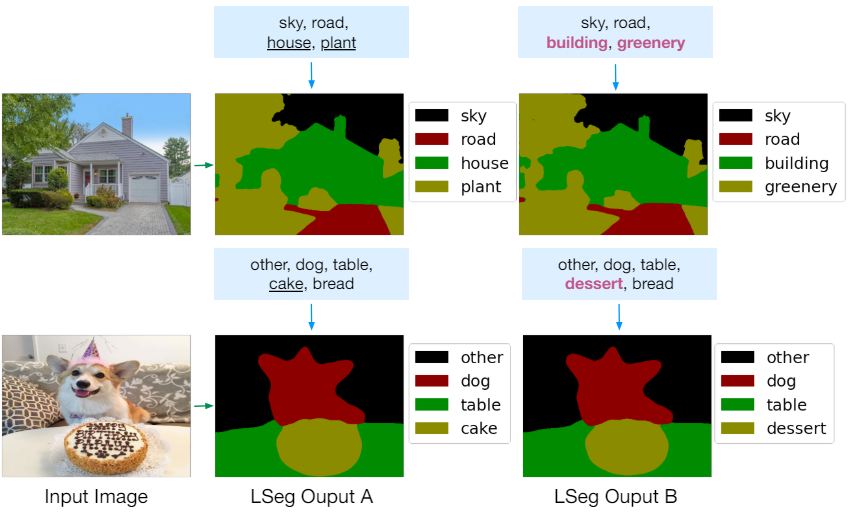
4. Qualitative Findings
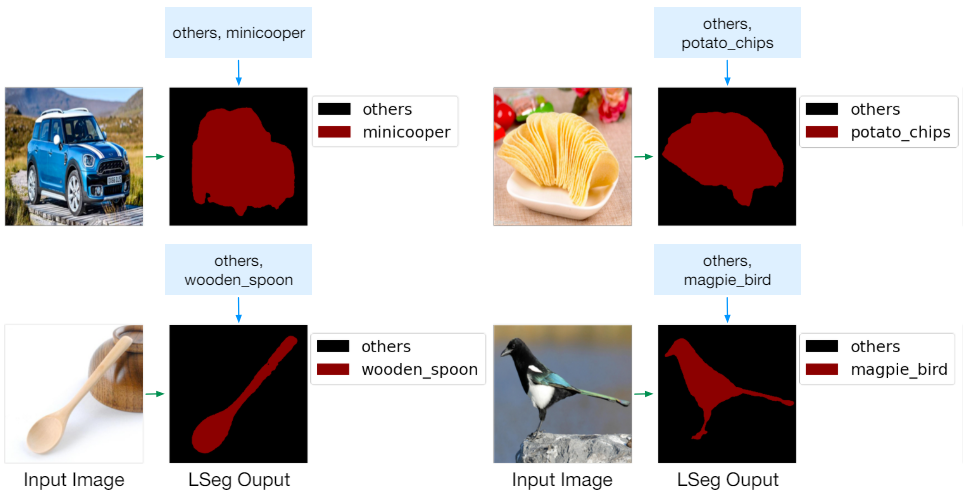
다음은 관련되었지만 처음 보는 레이블들에 대한 결과이다.
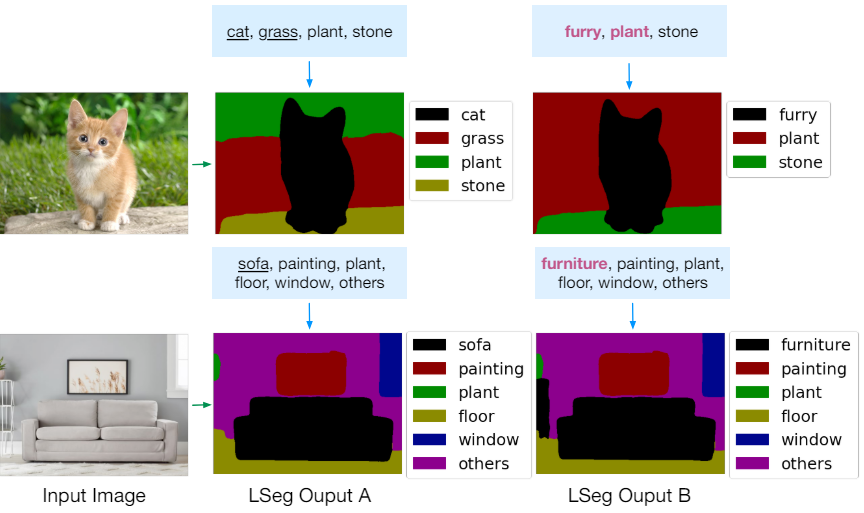
다음은 계층적인 관계를 가지는 처음 보는 레이블들에 대한 결과이다.
다음은 failure case들이다.

- 테스트 시 입력 레이블에 정답이 없다면 모델은 임베딩 공간에서 가장 가까운 레이블을 할당한다. (개에 toy를 할당)
- 모델은 여러 설명이 레이블 집합과 일치할 때 가장 가능성이 높은 하나의 객체에 초점을 맞춘다. (window 대신 house를 할당)