[논문리뷰] LoRA: Low-Rank Adaptation of Large Language Models
arXiv 2021. [Paper] [Github]
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen
Microsoft Corporation
17 Jun 2021
Introduction
자연어 처리의 많은 애플리케이션은 하나의 대규모 사전 학습된 언어 모델을 여러 다운스트림 애플리케이션에 적용하는 데 의존한다. 이러한 adaptation은 일반적으로 사전 학습된 모델의 모든 파라미터를 업데이트하는 fine-tuning을 통해 수행된다. Fine-tuning의 주요 단점은 새 모델에 원래 모델만큼 많은 파라미터가 포함된다는 것이다. 특히 더 큰 모델이 몇 달마다 학습됨에 따라, 이는 GPT-2나 RoBERTa large에서는 대한 단순한 불편함이었지만, 1,750억 개의 학습 가능한 파라미터가 있는 GPT-3에서는 중요한 배포 문제로 바뀌게 된다.
많은 사람들이 일부 파라미터만 조정하거나 새로운 task를 위한 외부 모듈을 학습하여 이를 완화하려고 했다. 이렇게 하면 각 task에 대해 사전 학습된 모델 외에 소수의 task별 파라미터만 저장하고 로드하면 되므로 배포 시 운영 효율성이 크게 향상된다. 그러나 기존 기술은 모델 깊이를 확장하거나 모델의 사용 가능한 시퀀스 길이를 줄임으로써 inference latency를 도입한다. 더 중요한 것은 이러한 방법이 fine-tuning baseline과 일치하지 않는 경우가 많기 때문에 효율성과 모델 품질 사이에 trade-off가 발생한다는 것이다.
저자들은 학습된 over-parametrized model이 실제로 낮은 고유 차원에 있음을 보여주는 두 논문(1, 2)에서 영감을 얻었다. 저자들은 모델 adaptation 중 가중치의 변화도 intrinsic rank가 낮으므로 제안된 Low-Rank Adaptation (LoRA) 접근 방식으로 이어진다는 가설을 세웠다. LoRA를 사용하면 사전 학습된 가중치를 고정된 상태로 유지하면서 대신 adaptation 중에 레이어의 변화에 대한 rank decomposition matrix들을 최적화하여 신경망의 일부 레이어를 간접적으로 학습할 수 있다. GPT-3 175B를 예를 들어 전체 rank가 12,288만큼 높은 경우에도 매우 낮은 rank인 1 또는 2로 충분하여 LoRA가 스토리지 및 컴퓨팅 효율성을 모두 높일 수 있음을 보여준다.
Terminologies
본 논문은 Transformer 아키텍처를 자주 참조하고 크기에 대해 기존 용어를 사용한다.
- $d_\textrm{model}$: Transformer 레이어의 입력 및 출력 차원 크기
- $W_q$, $W_k$, $W_v$, $W_o$: self-attention 모듈에서 query, key, value, output projection 행렬
- $W$ 또는 $W_0$: 사전 학습된 가중치 행렬
- $\Delta W$: Adaptation 중에 누적된 기울기 업데이트
- $r$: LoRA 모듈의 rank
Problem Statement
$\Phi$로 parameterize된 사전 학습된 autoregressive model $P_\Phi (y \vert x)$가 주어졌다고 가정하자. 예를 들어 $P_\Phi (y \vert x)$는 Transformer 아키텍처를 기반으로 하는 GPT와 같은 일반적인 multi-task learner일 수 있다. 요약, 기계 독해(MRC), SQL에 대한 자연어(NL2SQL)와 같은 다운스트림 조건부 텍스트 생성 task에 사전 학습된 이 모델을 적용하는 것을 고려하자. 각 다운스트림 task는 context-target 쌍의 학습 데이터셋으로 표시된다.
\[\begin{equation} \mathcal{Z} = \{(x_i, y_i)\}_{i=1,\cdots,N} \end{equation}\]여기서 $x_i$와 $y_i$는 모두 토큰 시퀀스이다. 예를 들어 NL2SQL에서 $x_i$는 자연어 쿼리이고 $y_i$는 해당 SQL 명령어다. 요약의 경우 $x_i$는 기사의 내용이고 $y_i$는 기사의 요약이다.
전체 fine-tuning 중에 모델은 사전 학습된 가중치 $\Phi_0$로 초기화되고, 조건부 언어 모델링 목적 함수를 최대화하기 위해 반복적으로 기울기를 따라 $\Phi_0 + \Delta \Phi$로 업데이트된다.
\[\begin{equation} \max_{\Phi} \sum_{(x,y) \in \mathcal{Z}} \sum_{t = 1}^{|y|} \log (P_\Phi (y_t \vert x, y{<t})) \end{equation}\]전체 fine-tuning의 주요 단점 중 하나는 각 다운스트림 task에 대해 차원 $\vert \Delta \Phi \vert$과 $\vert \Phi_0 \vert$가 같다는 것이다. 따라서 사전 학습된 모델이 큰 경우 (ex. GPT-3의 경우 $\vert \Phi_0 \vert \approx$ 1750억) fine-tuning된 모델의 많은 독립적인 인스턴스를 저장하고 배포하는 것은 가능하더라도 어려울 수 있다.
본 논문에서는 task별 $\Delta \Phi = \Delta \Phi (\Theta)$가 $\vert \Theta \vert \ll \vert \Phi_0 \vert$인 파라미터 $\Theta$로 인코딩되는 더 파라미터 효율적인 접근 방식을 채택한다. 따라서 $\Delta \Phi$를 찾는 작업은 $\Theta$에 대해 최적화된다.
\[\begin{equation} \max_\Theta \sum_{(x,y) \in \mathcal{Z}} \sum_{t = 1}^{|y|} \log (P_{\Phi_0 + \Delta \Phi (\Theta)} (y_t \vert x, y{<t})) \end{equation}\]본 논문은 low-rank 표현을 사용하여 계산 및 메모리 효율적인 $\Delta \Phi$를 인코딩할 것을 제안한다. 사전 학습된 모델이 GPT-3 175B인 경우 학습 가능한 파라미터의 수 $\vert \Theta \vert$는 $\vert \Phi_0 \vert$의 0.01% 정도로 작을 수 있다.
Aren’t Existing Solutions Good Enough?
본 논문이 해결하려는 문제는 결코 새로운 것이 아니다. Transfer learning이 시작된 이래 수십 개의 연구들이 모델 adaptation을 보다 파라미터 및 계산 효율적으로 만들기 위해 노력했다. 예를 들어 언어 모델링을 사용하면 효율적인 adaptation과 관련하여 두 가지 주요 전략이 있다.
- Adapter layer 추가
- 입력 레이어 activation의 일부 형식 최적화
그러나 두 전략 모두 특히 대규모 모델이나 latency에 민감한 시나리오에서 한계가 있다.
Adapter layer들은 inference latency를 도입한다.
다양한 adapter 변형이 있다. 본 논문은 다음 2가지 디자인에 중점을 둔다.
- Transformer 블록당 두 개의 adapter layer가 있는 원래 디자인
- 블록당 하나만 있지만 추가 LayerNorm이 있는 최신 디자인
레이어를 정리하거나 멀티태스킹 설정을 활용하여 전체 latency를 줄일 수 있지만 adapter layer의 추가 컴퓨팅을 우회하는 직접적인 방법은 없다. 이는 adapter layer가 추가할 수 있는 FLOP를 제한하는 작은 bottlenek 차원을 가짐으로써 소수의 파라미터(원래 모델의 1% 미만)를 갖도록 설계되었기 때문에 문제가 아닌 것처럼 보인다.
그러나 대규모 신경망은 latency를 낮게 유지하기 위해 하드웨어 병렬 처리에 의존하며 adapter layer는 순차적으로 처리되어야 한다. 이는 배치 크기가 일반적으로 1만큼 작은 온라인 inference 설정에서 차이를 만든다. 단일 GPU의 GPT-2에서 inference를 실행하는 것과 같이 모델 병렬 처리가 없는 일반적인 시나리오에서는 bottleneck 차원이 매우 작은 경우에도 adapter를 사용할 때 latency가 눈에 띄게 증가하는 것을 볼 수 있다.
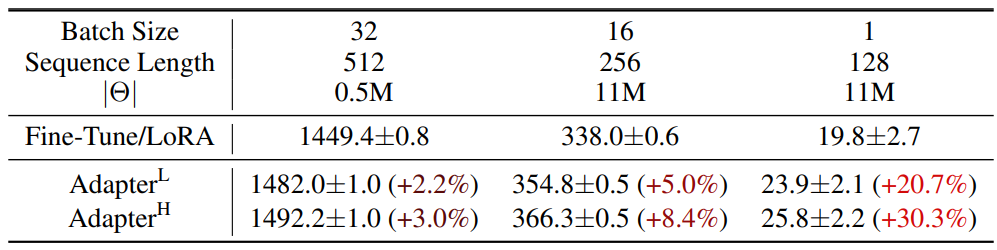
모델을 샤딩(sharding)해야 할 때 이 문제는 더욱 악화된다. Adapter 파라미터를 여러 번 중복 저장하지 않는 한 추가 깊이에는 더 많은 synchronous GPU 연산이 필요하기 때문이다.
프롬프트를 직접 최적화하는 것은 어렵다.
Prefix tuning 등의 다른 방향은 다른 문제에 직면해 있다. Prefix tuning은 최적화하기 어렵고 그 성능이 학습 가능한 파라미터에서 단조적이지 않게 변한다. 더 근본적으로, adaptation을 위해 시퀀스 길이의 일부를 사용하면 다운스트림 task를 처리하는 데 사용할 수 있는 시퀀스 길이가 필연적으로 줄어들어 다른 방법에 비해 프롬프트 튜닝 성능이 떨어진다.
Method
1. Low-Rank-Parametrized Update Matrices
신경망에는 행렬 곱셈을 수행하는 많은 레이어가 포함되어 있다. 이러한 레이어의 가중치 행렬은 일반적으로 full-rank를 갖는다. 특정 task에 적응할 때, 사전 학습된 언어 모델은 더 작은 subspace로의 랜덤 projection에도 불구하고 여전히 효율적으로 학습할 수 있으며, 낮은 내재적 차원 (instrisic dimension)을 가진다. 이에 영감을 받아 가중치에 대한 업데이트도 adaptation 중에 낮은 instrisic rank를 갖는다고 가정한다. 사전 학습된 가중치 행렬 $W_0 \in \mathbb{R}^{d \times k}$의 경우,
\[\begin{equation} W_0 + \Delta W = W^0 + BA \\ \textrm{where} \quad B \in \mathbb{R}^{d \times r}, \quad A \in \mathbb{R}^{r \times k}, \quad r \ll \min (d, k) \end{equation}\]로 표현하여 업데이트를 제한한다. 여기서 $r$은 rank이다. 학습하는 동안 $W_0$는 고정되고 기울기 업데이트를 받지 않는 반면 $A$와 $B$는 학습 가능한 파라미터를 포함한다. $W_0$와 $\Delta W = BA$는 모두 동일한 입력으로 곱해지고 각각의 출력 벡터는 좌표 방향으로 합산된다. $h = W_0 x$인 경우 수정된 forward pass는 다음과 같다.
\[\begin{equation} h = w_0 x + \Delta x = W_0 x + BAx \end{equation}\]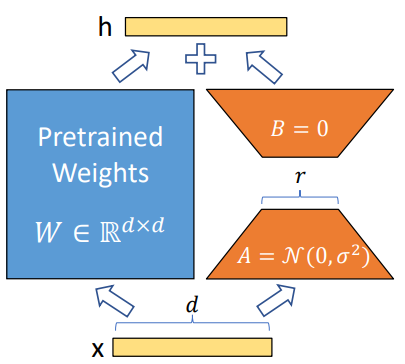
위 그림에서 reparameterization을 설명한다. $A$에는 랜덤 가우시안 초기화를 사용하고 $B$에는 0을 사용하므로 학습 시작 시 $BA = 0$이다. 그런 다음 $\nabla W x$를 $\alpha / r$로 스케일링한다. 여기서 $\alpha$는 $r$의 상수이다. Adam으로 최적화할 때 $\alpha$를 튜닝하는 것은 초기화를 적절하게 튜닝하는 경우 learning rate를 튜닝하는 것과 대략 동일하다. 결과적으로 단순히 $\alpha$를 저자들이 시도한 첫 번째 $r$로 설정하고 튜닝하지 않는다. 이 스케일링은 $r$을 변경할 때 hyperparameter를 다시 튜닝해야 할 필요성을 줄이는 데 도움이 된다.
전체 fine-tuning의 일반화
보다 일반적인 형태의 fine-tuning을 통해 사전 학습된 파라미터의 부분집합을 학습할 수 있다. LoRA는 한 단계 더 나아가 adaptation 중에 full-rank를 갖기 위해 가중치 행렬에 대한 누적 기울기 업데이트가 필요하지 않다. 즉, 모든 가중치 행렬에 LoRA를 적용하고 모든 바이어스를 학습할 때 LoRA rank $r$을 사전 학습된 가중치 행렬의 rank로 설정하여 전체 fine-tuning의 표현력을 대략적으로 복구한다. 즉, 학습 가능한 파라미터의 수가 증가함에 따라 LoRA 학습은 대략적으로 원래 모델 학습으로 수렴되는 반면 어댑터 기반 방법은 MLP로, prefix 기반 방법은 긴 입력 시퀀스를 취할 수 없는 모델로 수렴된다.
추가적인 inference latency 없음
프로덕션 환경에 배포할 때, $W = W_0 + BA$를 명시적으로 계산 및 저장하고 평소와 같이 inference를 수행할 수 있다. $W_0$과 $BA$는 모두 $\mathbb{R}^{d \times k}$이다. 다른 다운스트림 task로 전환해야 하는 경우 $BA$를 뺀 다음 다른 $B_0 A_0$을 추가하여 $W_0$을 복구할 수 있이며, 메모리 오버헤드가 거의 없는 빠른 연산이다. 결정적으로 이것은 fine-tuning된 모델과 비교하여 inference 중에 추가 latency를 도입하지 않도록 보장한다.
2. Applying LoRA to Transformer
학습 가능한 파라미터의 수를 줄이기 위해 신경망에서 가중치 행렬의 모든 부분집합에 LoRA를 적용할 수 있다. Transformer 아키텍처에는 self-attention 모듈에 4개의 가중치 매트릭스 $W_q$, $W_k$, $W_v$, $W_o$가 있고 MLP 모듈에는 2개가 있다. $W_q$ (또는 $W_k$, $W_v$)를 차원 $d_\textrm{model} \times d_\textrm{model}$의 단일 행렬로 취급한다. 출력 차원은 일반적으로 attention head로 분할된다. 저자들은 단순성과 파라미터 효율성을 위해 다운스트림 task에 대한 attention 가중치만 튜닝하고 MLP 모듈을 고정하는 것으로 연구를 제한하였다.
실질적인 이점과 한계
가장 중요한 이점은 메모리와 스토리지 사용량 감소이다. Adam으로 학습된 대형 Transformer의 경우 고정 파라미터에 대한 optimizer 상태를 저장할 필요가 없으므로 $r \ll d_\textrm{model}$인 경우 VRAM 사용량을 최대 2/3까지 줄인다. GPT-3 175B의 경우 학습 중 VRAM 소비를 1.2TB에서 350GB로 줄인다. $r = 4$이고 query와 key projection 행렬만 튜닝되면 체크포인트 크기가 약 10,000배 (350GB에서 35MB로) 감소한다. 이를 통해 훨씬 적은 수의 GPU로 학습하고 입출력 병목 현상을 피할 수 있다.
또 다른 이점은 모든 파라미터가 아닌 LoRA 가중치만 교환함으로써 훨씬 저렴한 비용으로 배포 중에 task 사이를 전환할 수 있다는 것이다. 이를 통해 사전 학습된 가중치를 VRAM에 저장하는 시스템에서 즉석에서 교환할 수 있는 많은 맞춤형 모델을 생성할 수 있다. 또한 대부분의 파라미터에 대한 기울기를 계산할 필요가 없기 때문에 전체 fine-tuning에 비해 GPT-3 175B에서 학습하는 동안 25% 속도 향상을 보인다.
LoRA에도 한계점이 있다. 예를 들어 추가 inference latency를 제거하기 위해 $A$와 $B$를 $W$로 흡수하기로 선택한 경우 단일 forward pass에서 $A$와 $B$가 다른 여러 task에 대한 입력을 일괄 처리하는 것은 간단하지 않다. 가중치를 병합하지 않고 latency가 중요하지 않은 시나리오의 경우 배치에서 샘플에 사용할 LoRA 모듈을 동적으로 선택할 수 있다.
Empirical Experiments
1. Baseline
- FT: Fine-Tuning
- FTTop2: 마지막 두 레이어만 튜닝
- BitFit
- AdapH: 오리지널 adapter tuning
- AdapL: MLP 모듈 뒤와 LayerNorm 뒤에만 adapter layer 적용 (논문)
- AdapP: AdapterFusion (AdapL과 유사)
- AdapD: AdapterDrop (몇몇 adapter layer를 drop)
2. Result
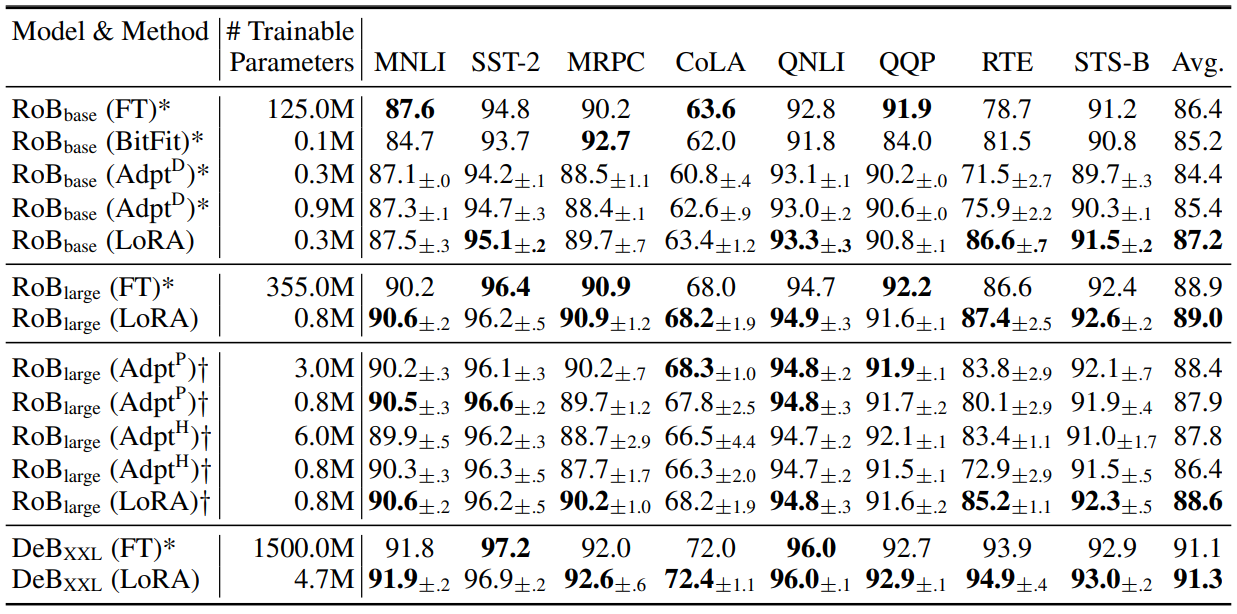
다음은 다양한 adaptation 방법을 적용한 RoBERTabase, RoBERTalarge, DeBERTaXXL에 대한 GLUE 벤치마크이다.
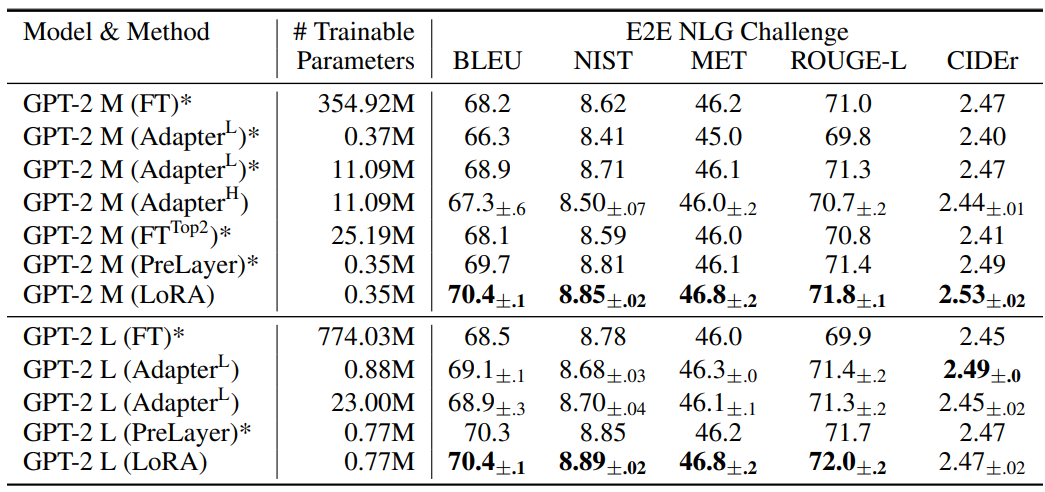
다음은 E2E NLG Challenge에서 다양한 adaptation 방법을 적용한 GPT-2 medium (M)과 GPT-2 large (L)에 대한 비교 결과이다.
다음은 다양한 adaptation 방법을 적용한 GPT-3 175B의 성능 비교 결과이다.
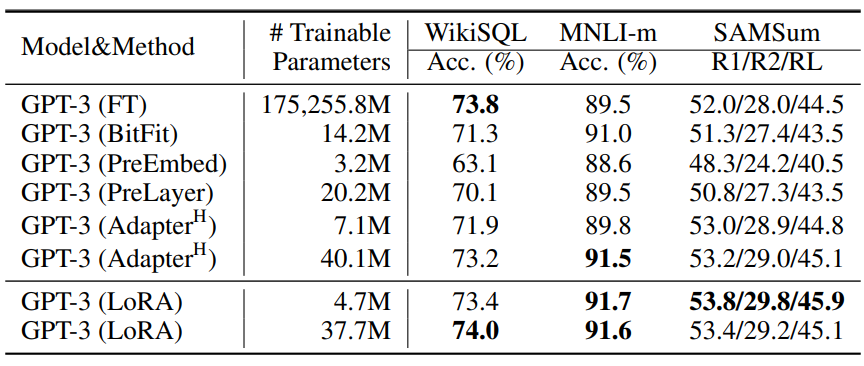
다음은 다양한 adaptation 방법을 적용한 GPT-3 175B의 정확도와 파라미터 개수에 대한 그래프이다.
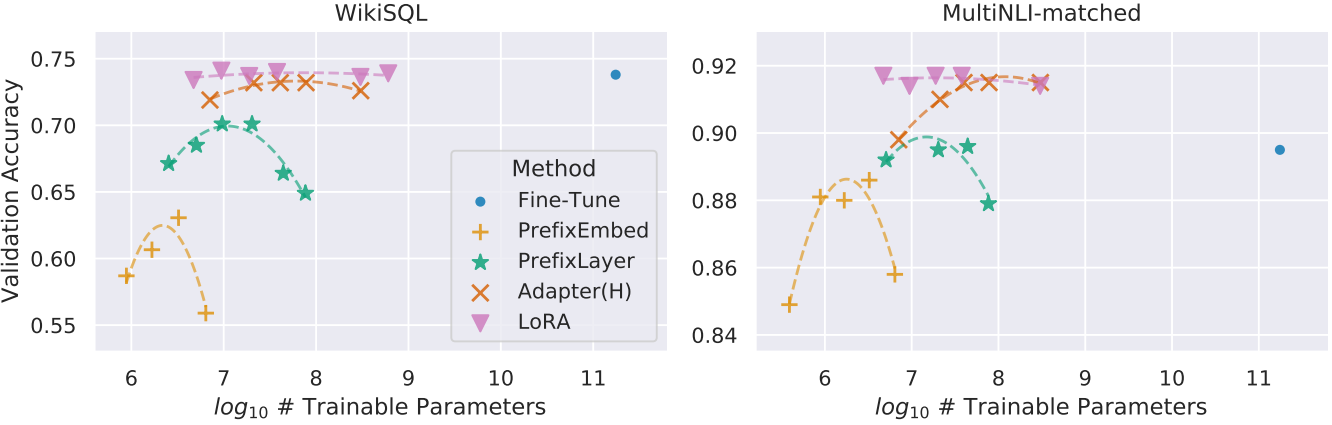
Understanding the Low-Rank Updates
Low-rank 구조는 여러 실험을 병렬로 실행할 수 있도록 하드웨어 진입 장벽을 낮출 뿐만 아니라 업데이트 가중치가 사전 학습된 가중치와 어떻게 상관되는지에 대한 더 나은 해석성을 제공한다. 저자들은 GPT-3 175B에 대한 연구에 집중하여 task 수행에 부정적인 영향을 미치지 않으면서 학습 가능한 파라미터를 가장 많이 줄였다 (최대 10,000배).
저자들은 다음 질문에 답하기 위해 일련의 경험적 연구를 수행하였다.
- 파라미터 예산에 대한 제약 조건이 주어지면 다운스트림 성능을 최대화하기 위해 사전 학습된 Transformer에서 가중치 행렬의 어떤 부분집합을 튜닝해야 하는가?
- 최적의 adaptation 행렬 $\Delta W$가 정말 rank가 부족한가? 그렇다면 실제로 사용하기 좋은 rank는 무엇인가?
- $\Delta W$와 $W$ 사이의 관계는 무엇인가? $\Delta W$는 $W$와 높은 상관관계가 있는가? $\Delta W$는 $W$에 비해 얼마나 큰가?
1. Transformer의 어떤 가중치 행렬에 LoRA를 적용해야 하는가?
다음은 GPT-3의 가중치 행렬 종류에 대한 정확도이다.

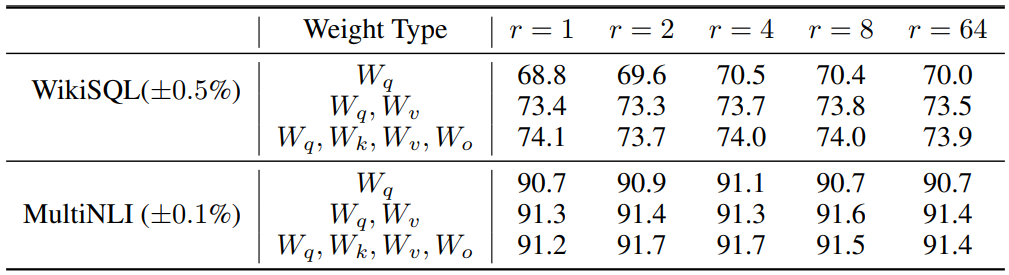
2. LoRA를 위한 최적의 rank $r$은 무엇인가?
다음은 다양한 rank $r$에 대한 정확도이다.
저자들은 Grassmann distance를 기반으로 다음과 같이 두 subspace의 유사도를 측정하였다.
여기서 $U_A^i$는 top $i$ singular vector에 해당하는 $U_A$의 열이다. $\phi(\cdot)$가 1이면 subspace들이 완전히 겹친다는 것을 의미하며, 0이면 완전한 분리를 의미한다.
다음은 서로 다른 $r$ 사이의 subspace 유사도이다.
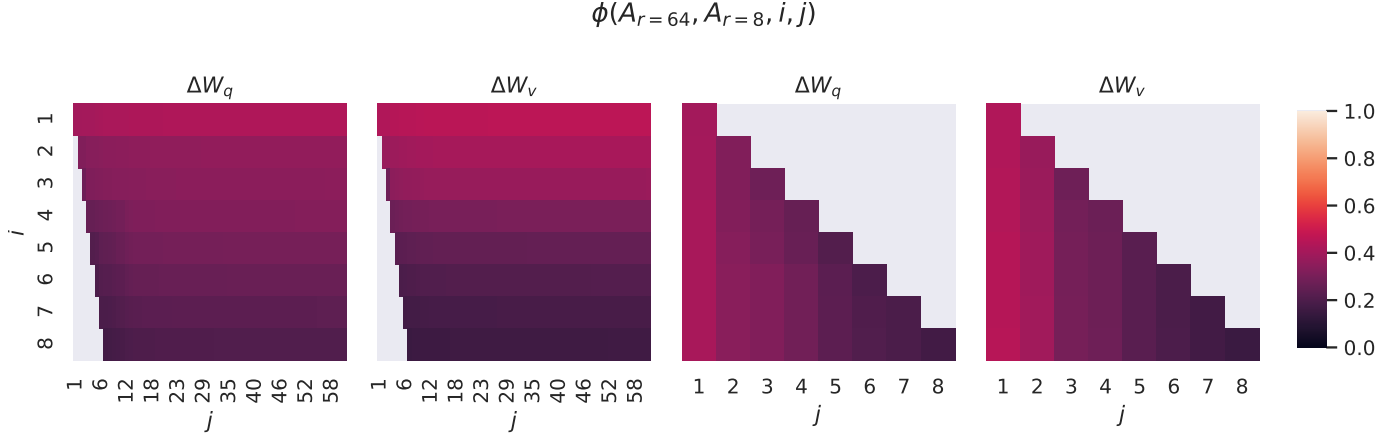
위의 singular vector에 해당하는 방향은 $A_{r=8}$과 $A_{r=64}$ 사이에서 상당히 겹치지만 다른 방향은 그렇지 않다. 특히, $A_{r=8}$와 $A_{r=64}$의 $\Delta W_v$와 $\Delta W_v$는 유사도가 0.5보다 크게 차원 1의 subspace를 공유하므로 GPT-3에 대한 다운스트림 task에서 $r = 1$이 매우 잘 수행되는 이유를 설명할 수 있다.
다음은 서로 다른 random seed 사이의 subspace 유사도이다.
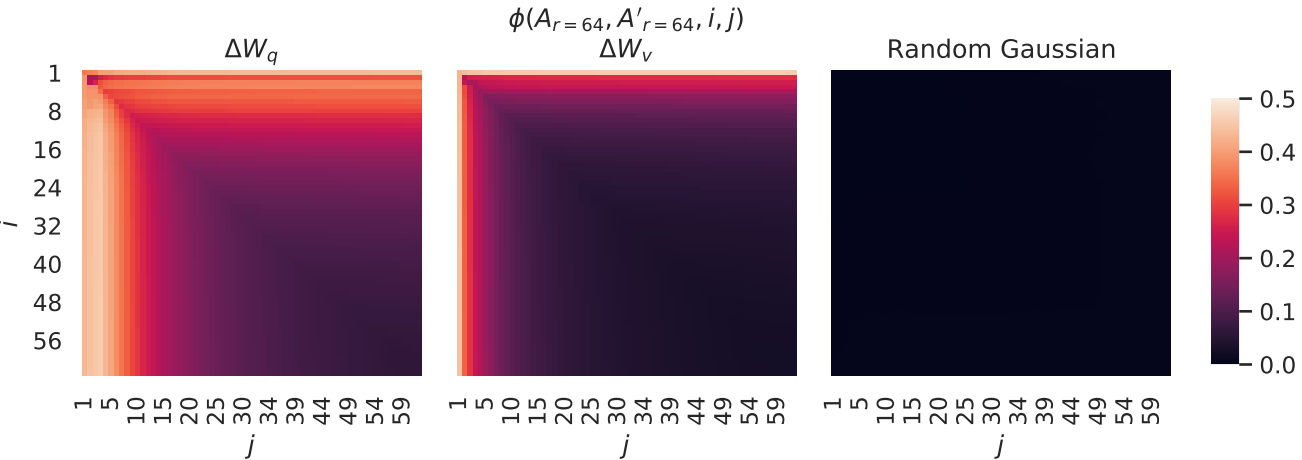
$\Delta W_q$는 $\Delta W_v$보다 intrinsic rank가 더 높은 것으로 보인다.
3. Adaptation 행렬 $\Delta W$는 $W$와 어떻게 비교되는가?
$U^\top W V^\top$를 계산하여 $W$를 $\Delta W$의 $r$차원 subspace에 project한다. 여기서 $U$와 $V$는 $\Delta W$의 왼쪽과 오른쪽 singular vector 행렬이다. 그런 다음 $|| U^\top W V^\top ||_F$와 $|| W ||$ 사이의 Frobenius norm을 비교한다. 비교를 위해 $U$, $V$를 $W$의 top $r$ singular vector 또는 랜덤 행렬로 대체하여 $|| U^\top W V^\top ||_F$도 계산한다.

위 결과에서 다음과 같은 결론을 내릴 수 있다.
- $\Delta W$는 랜덤 행렬에 비해 $W$와 더 강한 상관관계를 가지며, 이는 $\Delta W$가 이미 $W$에 있는 일부 feature를 증폭함을 나타낸다.
- $\Delta W$는 $W$의 top singular 방향을 반복하는 대신 강조되지 않은 방향만 증폭한다.
- 증폭 계수는 다소 크다. $r = 4$인 경우 $21.5 \approx 6.91 / 0.32$이다.