[논문리뷰] LONG3R: Long Sequence Streaming 3D Reconstruction
ICCV 2025. [Paper] [Page]
Zhuoguang Chen, Minghui Qin, Tianyuan Yuan, Zhe Liu, Hang Zhao
Shanghai AI Lab | Tsinghua University | Shanghai Qi Zhi Institute
24 Jul 2025
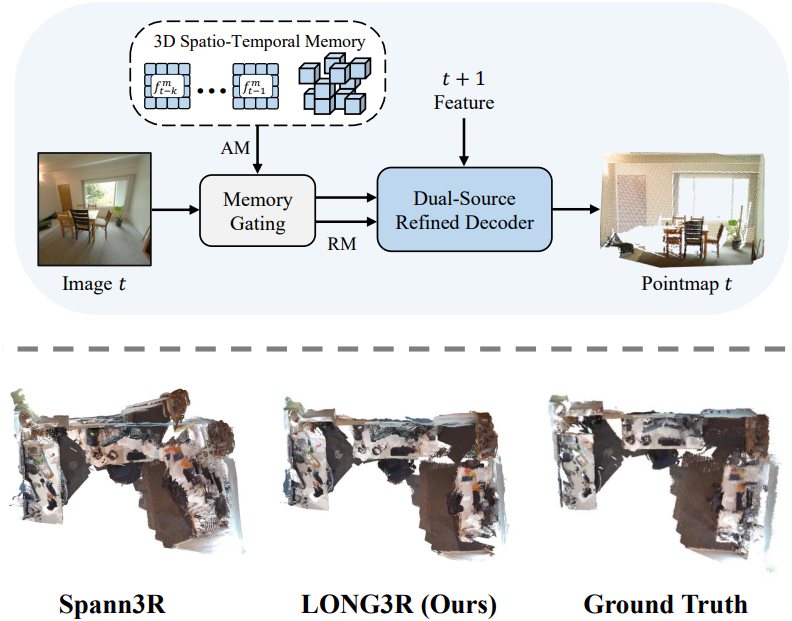
Introduction
DUSt3R와 MASt3R는 이미지 쌍에서 3D pointmap을 직접 예측하여 간단하면서도 일반화가 가능한 접근 방식을 제공한다. 특히 유망한 방향은 이 패러다임을 스트리밍 입력 이미지의 온라인 처리로 확장하는 것이다. 예를 들어 Spann3R는 스트리밍 입력 이미지를 실시간으로 처리하기 위해 메모리가 있는 recurrent model을 도입하여 다양한 실용적 적용을 가능하게 했다. 그러나 효율성에도 불구하고 Spann3R은 세 가지 주요 문제로 인해 긴 입력 시퀀스를 처리하는 데 어려움을 겪는다.
- 메모리는 iteration당 한 번만 처리되므로 효과적인 재사용이 불가능하다.
- 이미지가 누적됨에 따라 메모리가 공간적으로 중복된다.
- 학습 전략이 긴 시퀀스에 대한 적응을 지원하지 않는다.
본 논문에서는 긴 시퀀스에 대한 멀티뷰 3D 장면 재구성을 스트리밍하도록 설계된 새로운 모델인 LONG3R를 제안하였다. 본 논문에서는 긴 시퀀스 재구성을 거의 일정한 메모리 요구량을 갖는 수십에서 수백 개의 프레임을 실시간으로 처리하는 것으로 정의하였다. Spann3R과 마찬가지로, 본 접근법은 시공간 3D 메모리 뱅크를 가진 recurrent network를 사용하여 스트리밍 이미지 시퀀스를 처리한다. 새로운 관측치가 주어지면, 모델은 관련 메모리를 검색하고, 현재 시점과 상호 작용하여 해당 시점의 pointmap을 예측하고, 그에 따라 메모리를 업데이트한다. 긴 시퀀스 처리를 향상시키기 위해 세 가지 주요 혁신을 도입하였다.
- Memory Gating & Dual-Source Refined Decoder: 현재 관측치와 관련된 메모리를 선택적으로 유지하는 memory gating 메커니즘을 도입하고, 관측치와 메모리 간의 coarse-to-fine 상호작용을 가능하게 하는 Dual-Source Refined Decoder를 도입하였다.
- 3D 시공간 메모리: 중복 메모리를 자동으로 제거하고 장면 규모에 맞춰 해상도를 조정하는 동적 3D 메모리 모듈을 제안하여 메모리 효율성과 재구성 정확도의 균형을 유지하였다.
- 2단계 커리큘럼 학습: 시퀀스 길이를 점진적으로 증가시키는 2단계 커리큘럼 학습 전략을 채택하여 점점 더 복잡해지는 메모리 상호작용을 처리하는 모델의 능력을 향상시켰다.
Method
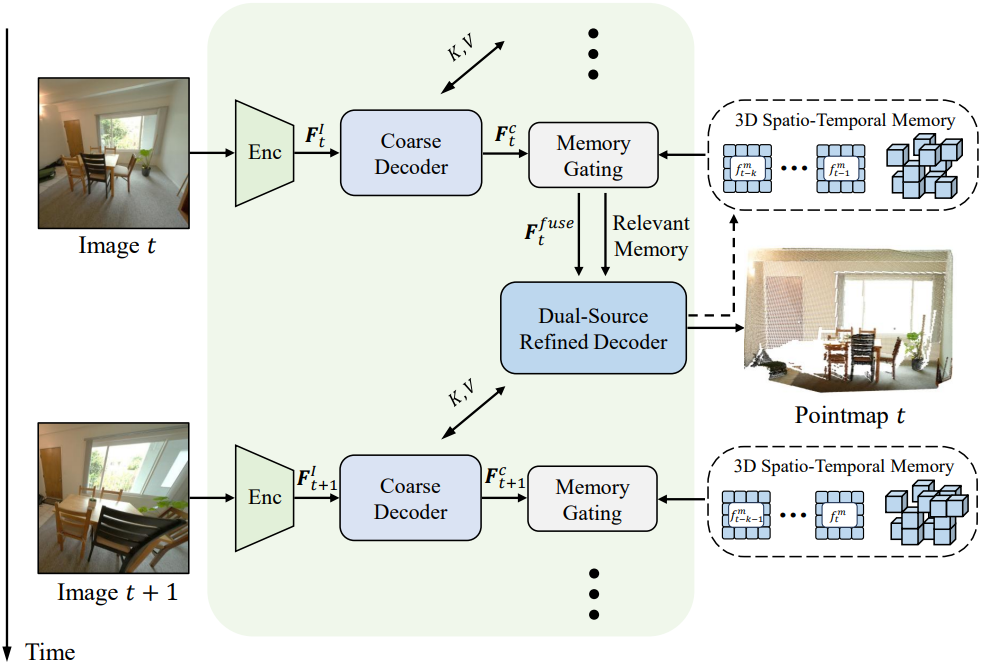
1. Feature Encoding and Coarse Decoding
DUSt3R를 따라, 입력 이미지는 ViT 인코더에 의해 처리되어 패치로 분할되고 visual feature 토큰으로 linear projection된다.
\[\begin{equation} \textbf{F}_t^I = \textrm{Encoder}(\textbf{I}_t) \end{equation}\]이러한 토큰은 $B$개의 PairwiseBlock으로 구성된 일반 transformer로 구현된 Coarse Decoder로 전달된다. Self-attention, cross-attention, MLP로 구성된 각 PairwiseBlock은 다음과 같이 사용된다.
\[\begin{equation} \textbf{F}_{t,i}^c = \textrm{PairwiseBlock}_i^c (\textbf{F}_{t,i-1}^c, \textbf{F}_{t-1,i-1}^r) \\ \textrm{where} \quad i = 1, \ldots, B, \quad \textbf{F}_{t,0}^c = \textbf{F}_t^I \end{equation}\](\(\textbf{F}_{t-1,i-1}^r\)은 $(t−1)$번째 프레임에 대해 Refined Decoder의 해당 블록에서 생성된 정제된 토큰)
Coarse decoder는 이전 프레임의 temporal feature와 효율적으로 상호 작용하여 후속 처리의 기반이 되는 coarse한 표현을 생성한다.
2. Attention-based Memory Gating
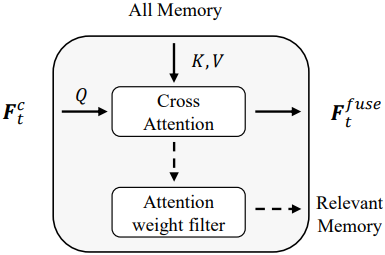
Memory gating 메커니즘은 두 가지 주요 기능을 수행한다.
- 모든 메모리 엔트리에서 정보를 집계
- 관련 없는 메모리 토큰을 필터링하여 후속 정제된 디코더의 계산 부하를 줄임
최종 PairwiseBlock 출력 \(\textbf{F}_{t,B}^c\)는 cross-attention을 통해 메모리 key \(\textbf{F}_\textrm{mem}^K\)와 메모리 value \(\textbf{F}_\textrm{mem}^V\)에 의해 처리된다.
\[\begin{equation} W_t = \textrm{Softmax} \left( \frac{\textbf{F}_{t,B}^c (\textbf{F}_\textrm{mem}^K)^\top}{\sqrt{C}} \right) \\ \textbf{F}_t^\textrm{fuse} = W_t \textbf{F}_\textrm{mem}^V \end{equation}\]($W_t \in \mathbb{R}^{P \times S}$는 모든 메모리 key에 대한 현재 query의 각 토큰에 대한 attention 가중치, $P$는 현재 프레임의 토큰 수, $S$는 메모리 토큰의 수)
현재 관측치와 관련 없는 메모리를 필터링하기 위해 attention 가중치 $W_t$와 attention threshold $\tau = 5 \times 10^{-4}$를 사용한다. 구체적으로, 각 메모리 인덱스 \(s \in \{1, \ldots, S\}\)에 대해, $W_t (p, s) > \tau$를 만족하는 토큰 \(p \in \{1, \ldots, P\}\)가 하나 이상 존재하면 $s$번째 메모리 feature는 유지되고, 그렇지 않으면 삭제된다. 따라서 관련된 메모리 \(\textbf{F}_\textrm{r_mem}\)은 다음과 같다.
\[\begin{equation} \delta (s) = \begin{cases} 1, & \textrm{if} \; \max_p W_t (p, s) > \tau \\ 0, & \textrm{otherwise} \end{cases} \\ \textbf{F}_\textrm{r_mem} = \{ \textbf{F}_\textrm{mem} (s) \; \vert \; \delta (s) = 1 \} \end{equation}\]($\delta (s)$는 indicator function)
\(\textbf{F}_\textrm{mem}\)은 \(\textbf{F}_\textrm{mem}^K\)와 \(\textbf{F}_\textrm{mem}^V\)이라는 두 가지 구성 요소로 구성되며, 두 구성 요소 모두 위의 필터링 과정을 거친다. 이 메커니즘은 attention 가중치에 따라 결정되는 충분한 관련성을 가진 메모리 요소만 다음 정제 과정에 기여하도록 한다.
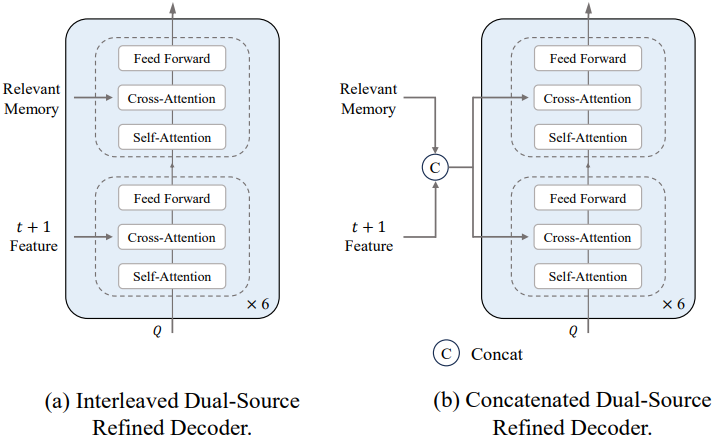
3. Dual-Source Refined Decoder
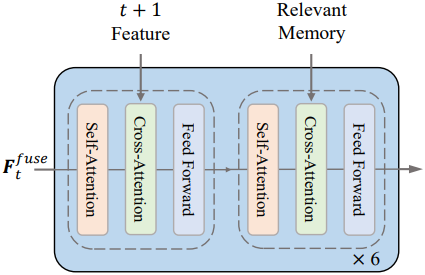
저자들은 메모리 정보 활용도를 극대화하고 다음 프레임과의 정렬을 유지하기 위해 Dual-Source Refined Decoder를 제안하였다. 일반적인 PairwiseBlock만으로 구성된 coarse decoder와 달리, 듀얼 소스 정제 디코더는 PairwiseBlock과 MemoryBlock이라는 두 가지 유형의 블록을 번갈아 사용한다. 이러한 디자인을 통해 현재 프레임 토큰은 시공간 메모리 토큰과 다음 프레임의 feature를 모두 최대한 활용하고 통합할 수 있다.
\(\textbf{F}_{t,i}^r\)를 블록 $i$에서 정제된 feature 표현이라고 하면, 전체 연산은 다음과 같이 정의된다.
\[\begin{equation} \textbf{F}_{t,i}^r = \begin{cases} \textrm{PairwiseBlock} (\textbf{F}_{t,i-1}^r, \textbf{F}_{t+1,i-1}^c), & i \; \textrm{odd} \\ \textrm{MemoryBlock} (\textbf{F}_{t,i-1}^r, \textbf{F}_\textrm{r_mem}), & i \; \textrm{even} \end{cases} \\ \textrm{where} \quad i = 1, \ldots, B, \quad \textbf{F}_{t,0}^r = \textbf{F}_t^\textrm{fuse} \end{equation}\]PairwiseBlock은 정제된 현재 프레임 feature와 다음 프레임의 coarse 토큰 간의 feature 상호작용을 촉진하는 반면, MemoryBlock은 이러한 정제된 feature를 관련 메모리 토큰 \(\textbf{F}_{r_mem}\)과 통합하여 장거리 시공간적 의존성을 향상시킨다. 이러한 교대 구조는 디코더가 즉각적 정보와 과거 정보를 모두 활용하여 robust하고 context-aware한 feature 표현을 구성할 수 있도록 한다.
디코더에 이어 DPT head를 사용하여 출력으로부터 명시적인 3D 재구성 예측이 생성된다.
4. 3D Spatio-Temporal Memory
본 메모리 메커니즘은 short-term temporal memory와 long-term 3D spatial memory를 동시에 유지함으로써 긴 시퀀스를 처리한다. 메모리는 Dual-Source Refined Decoder에서 생성된 과거 토큰으로 구성된다. 고정된 저장 용량을 가진 본 메모리 메커니즘은 중복 토큰을 피하면서 전체적인 공간 표현을 유지한다. 이러한 메모리 디자인은 메모리 리소스에 과부하를 주지 않으면서도 필수적인 시공간적 feature를 효율적으로 포착한다.
Short-term temporal memory는 window 크기가 $K$인 time window $[t-K, t-1]$의 과거 토큰을 저장한다. Key feature \(f^K \in \mathbb{R}^{(K \cdot P) \times C}\)와 value feature \(f^V \in \mathbb{R}^{(K \cdot P) \times C}\)를 저장하여 시간에 따른 정보의 효과적인 활용을 보장한다.
Long-term 3D spatial memory는 토큰 수를 제한하는 동시에 $[1, t-K]$ 내의 토큰을 관리함으로써 GPU 메모리 제약을 완화하고 inference 속도를 향상시킨다. Voxel을 저장 단위로 사용하고 각 voxel은 하나의 토큰을 보유한다. 이러한 sparsification은 메모리 유닛의 수와 장면의 공간적 크기에 균형을 맞춘다. 그러나 장면마다 voxel 크기가 다르고 모델의 최적화가 metric invariant하기 때문에 미리 정의된 voxel 크기는 적합하지 않다. 저자들은 이 문제를 해결하기 위해 적응형 voxel 크기 전략을 도입하였다.
적응형 voxel 크기
메모리는 패치 기반 토큰을 저장하므로, 먼저 각 프레임에서 예측된 pointmap을 가중 평균하여 각 패치에 대한 고유한 3D 위치 $P$를 계산한다. 그런 다음, 각 토큰은 이미지 평면에서 인접한 8개 토큰까지의 3D 유클리드 거리를 계산하며, 평균 거리 $d_i$는 다음과 같다.
\[\begin{equation} d_i = \frac{1}{8} \sum_{j \in \mathcal{N}(i)} \| P_i - P_j \|_2 \end{equation}\]최적의 이미지 voxel 크기 \(v_\textrm{img}\)는 메모리 사용량과 저장 공간 효율성의 균형을 맞추기 위해 모든 토큰에 대한 최소 $d_i$로 결정된다. 장면 voxel 크기 \(v_\textrm{scene}\)은 모든 프레임에 대한 이미지 voxel 크기의 평균으로 계산된다.
\[\begin{equation} v_\textrm{img} = \min_i d_i, \quad v_\textrm{scene} = \frac{1}{t-1} \sum_{j=1}^{t-1} v_{\textrm{img}, j} \end{equation}\]($t$는 현재 프레임의 시퀀스 인덱스)
\(v_\textrm{scene}\)은 inference 중에 지속적인 온라인 업데이트를 거치며, 이를 통해 시간적 시퀀스에 따라 적응형 조정이 가능하다.
3D Spatial Memory Pruning
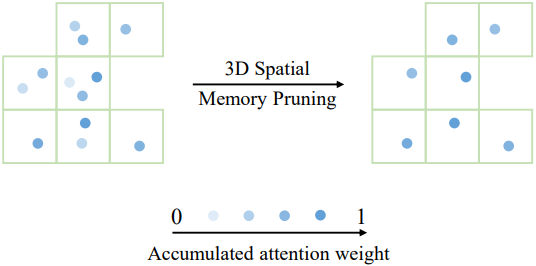
\(v_\textrm{scene}\)이 결정되면, 유사한 3D 위치를 가진 토큰들은 동일한 voxel로 그룹화되고, 서로 멀리 떨어진 토큰들은 다른 voxel에 할당된다. 각 토큰의 누적 attention 가중치가 추적되며, 각 voxel 내에서 가중치가 가장 높은 토큰만 유지된다. 이 메커니즘은 장면의 공간적 표현을 보존하는 동시에 유사한 메모리가 저장되는 것을 방지하여 메모리 크기의 균형을 효과적으로 조절한다.
5. Training
Loss Function
DUSt3R를 따라, 3D regression에는 confidence-aware loss \(\mathcal{L}_\textrm{conf}\)를 사용하고, 예측된 포인트 클라우드의 평균 거리가 실제 평균 거리보다 작도록 하는 scale loss \(\mathcal{L}_\textrm{scale}\)을 사용한다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{conf} + \mathcal{L}_\textrm{scale} \end{equation}\]2단계 커리큘럼 학습
저자들은 모델이 긴 시퀀스를 더 잘 처리할 수 있도록 2단계 학습 전략을 채택했다. 1단계에서는 동영상 시퀀스당 5개의 프레임을 무작위로 샘플링하여 모델을 학습시킨다. 2단계에서는 다른 모듈이 fine-tuning되는 동안 ViT 인코더는 고정된 상태를 유지하여 긴 시퀀스를 처리하기 위해 더 많은 프레임으로 모델을 학습할 수 있다. 구체적으로, 처음에는 10개의 프레임을 샘플링하고 이후 32개의 프레임을 샘플링하여 모델이 더 긴 시퀀스에 점진적으로 적응할 수 있도록 한다.
이러한 단계적 접근 방식은 점진적으로 확장되는 시간적 컨텍스트에서 시공간적 feature 상관관계를 활용하여 긴 시퀀스 재구성 성능을 향상시키고, 순차적 데이터 처리에서 메모리 관련 패턴을 포착하고 활용하는 모델의 능력을 최적화한다.
Experiments
- 데이터셋: Habitat, ARKitScenes, BlendedMVS, ScanNet++, Co3Dv2, ScanNet
- 구현 디테일
- 인코더: ViT-Large (DUSt3R 인코더로 초기화)
- 해상도: 224$\times$224
- time window 크기: 10
- 최대 long-term memory 토큰 수: 3,000
- optimizer: AdamW
- learning rate: 1단계는 $1.12 \times 10^{-4}$, 2단계는 $1 \times 10^{-5}$
- epoch: 1단계는 120, 2단계는 10-view와 32-view 각각 12
- GPU: A100 16개
1. 3D Reconstruction
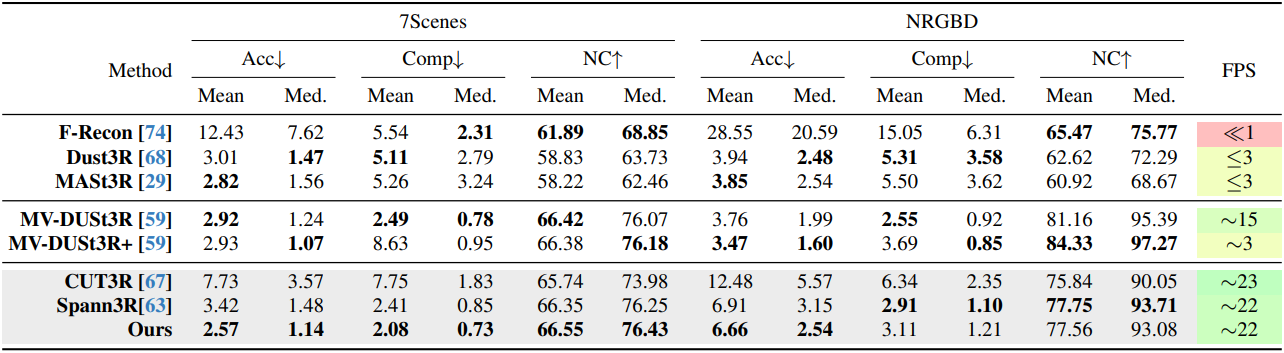
다음은 7Scenes와 NRGBD에서의 재구성 결과를 비교한 것이다.

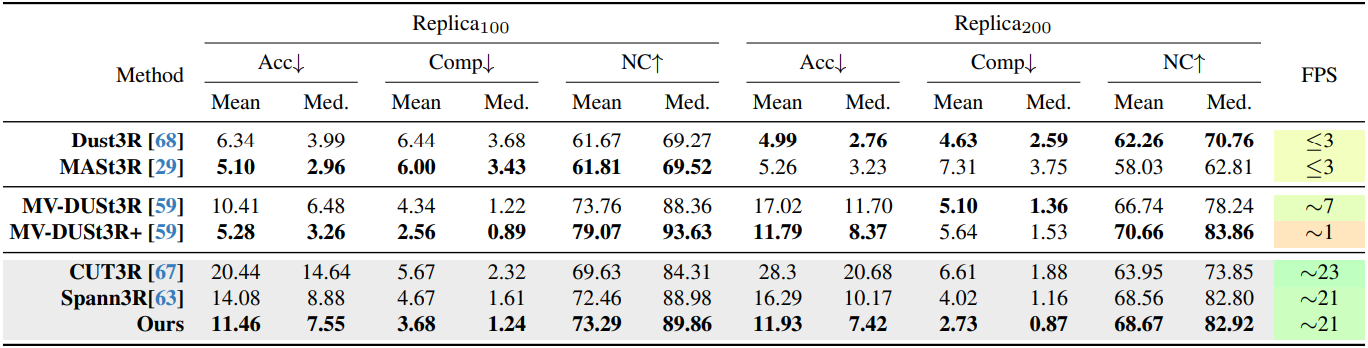
다음은 Replica에서의 재구성 결과를 비교한 것이다.

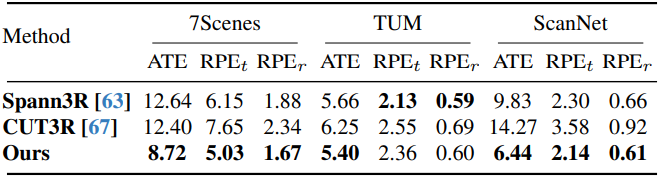
다음은 카메라 포즈 추정 결과를 비교한 것이다. (cm/°)
2. Ablation and analysis
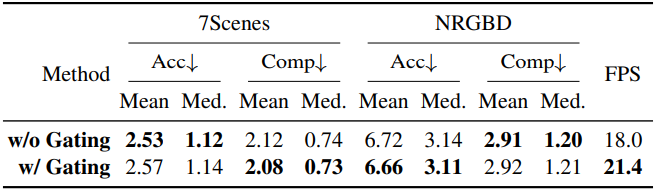
다음은 memory gating에 대한 ablation 결과이다. (7Scenes, NRGBD)
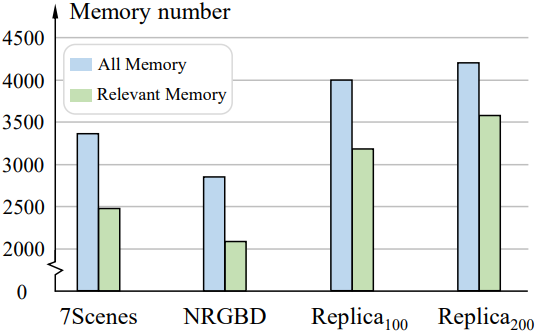
다음은 메모리 수를 장면별로 비교한 결과이다.
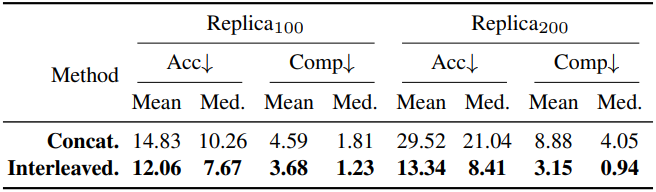
다음은 Refined Decoder에 대한 ablation 결과이다. (Replica)
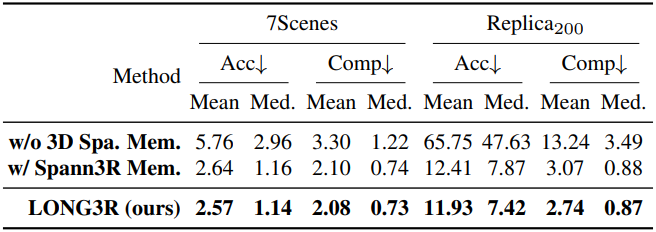
다음은 메모리 프레임워크에 대한 ablation 결과이다. (7Scenes, Replica)
Limitations
- 예측이 첫 번째 프레임을 기준으로 정의되므로, 시점이 크게 벗어나면 모델이 흐릿한 결과를 생성할 수 있다.
- 현재 모델은 동적 학습 데이터가 부족하기 때문에 큰 물체의 움직임이 있는 매우 역동적인 장면을 처리하는 데 어려움을 겪는다.