[논문리뷰] Generating Long Videos of Dynamic Scenes (LongVideoGAN)
NeurIPS 2022. [Paper] [Page] [Github]
Tim Brooks, Janne Hellsten, Miika Aittala, Ting-Chun Wang, Timo Aila, Jaakko Lehtinen, Ming-Yu Liu, Alexei A. Efros, Tero Karras
NVIDIA | UC Berkeley | Aalto University
7 Jun 2022
Introduction
동영상은 카메라 시점, 모션, 변형, 폐색의 복잡한 패턴으로 시간이 지남에 따라 변경되는 데이터이다. 어떤 면에서 동영상은 제한이 없다. 동영상은 임의로 오래 지속될 수 있으며 시간이 지남에 따라 표시될 수 있는 새로운 콘텐츠의 양에는 제한이 없다. 그러나 실제 세계를 묘사하는 동영상은 시간이 지남에 따라 어떤 변화가 가능한지 지시하는 물리적 법칙과도 일관성을 유지해야 한다. 예를 들어 카메라는 부드러운 경로를 따라 3D 공간을 통해서만 이동할 수 있고 개체는 서로 변형할 수 없으며 시간은 뒤로 이동할 수 없다. 따라서 사실적인 긴 동영상을 생성하려면 적절한 일관성을 통합하는 동시에 끝없는 새 콘텐츠를 생성할 수 있는 능력이 필요하다.
본 논문에서는 시간이 지남에 따라 발생하는 풍부한 역동성과 새로운 콘텐츠로 긴 동영상을 생성하는 데 중점을 둔다. 기존 영상 생성 모델은 ‘무한’ 영상을 제작할 수 있지만, 시간축에 따른 변화의 종류와 양은 매우 제한적이다. 예를 들어, 말하는 사람의 합성 무한 동영상에는 입과 머리의 작은 움직임만 포함된다. 또한 일반적인 동영상 생성 데이터셋에는 시간이 지남에 따라 새로운 콘텐츠가 거의 없는 짧은 클립이 포함되는 경우가 많기 때문에 짧은 세그먼트 또는 프레임 쌍에 대한 학습, 동영상의 콘텐츠를 강제로 고정시키거나 작은 시간적 receptive field가 있는 아키텍처를 사용하도록 디자인 선택을 편향시킬 수 있다.
저자들은 시간축을 동영상 생성에서 가장 중요한 축으로 만든다. 이를 위해 모션, 변화하는 카메라 시점, 시간 경과에 따른 물체 및 풍경의 입구/출구를 포함하는 두 개의 새로운 데이터셋을 도입한다. 저자들은는 긴 동영상에 대한 학습을 통해 장기적 일관성을 학습하고 복잡한 시간적 변화를 모델링할 수 있는 시간적 latent 표현을 설계한다.
본 논문의 주요 기여는 방대한 시간적 receptive field와 새로운 시간적 임베딩을 사용하는 계층적 generator 아키텍처이다. 먼저 저해상도로 동영상을 생성한 다음 별도의 super-resolution 네트워크를 사용하여 이를 다듬는 multi-resolution 전략을 사용한다. 높은 공간 해상도에서 긴 동영상에 대한 naive한 학습은 엄청나게 비용이 많이 들지만 동영상의 주요 양상은 낮은 공간 해상도에서 지속된다는 것을 발견했다. 이러한 관찰을 통해 저해상도의 긴 동영상과 고해상도의 짧은 동영상으로 학습할 수 있으므로 시간 축의 우선 순위를 지정하고 장기적인 변화를 정확하게 묘사할 수 있다. 저해상도 및 super-resolution 네트워크는 그 사이에 RGB bottleneck이 있는 상태에서 독립적으로 학습된다. 이 모듈식 디자인을 통해 각 네트워크를 독립적으로 반복하고 다양한 저해상도 네트워크에 대해 동일한 super-resolution 네트워크를 활용할 수 있다.
Our method
실제 동영상에서 관찰되는 장기간의 시간적 행동을 모델링하는 데는 두 가지 주요 과제가 있다. 첫째, 관련 효과를 캡처하기 위해 학습 중에 충분히 긴 시퀀스를 사용해야 한다. 예를 들어 연속 프레임 쌍을 사용하면 몇 초 동안 발생하는 효과에 대한 의미 있는 학습 신호를 제공하지 못한다. 둘째, 네트워크 자체가 장기간에 걸쳐 작동할 수 있도록 해야 한다. 예를 들어 generator의 receptive field가 8개의 인접한 프레임에만 걸쳐 있는 경우 8개 프레임 이상 떨어져 있는 두 프레임은 반드시 서로 관련이 없다.
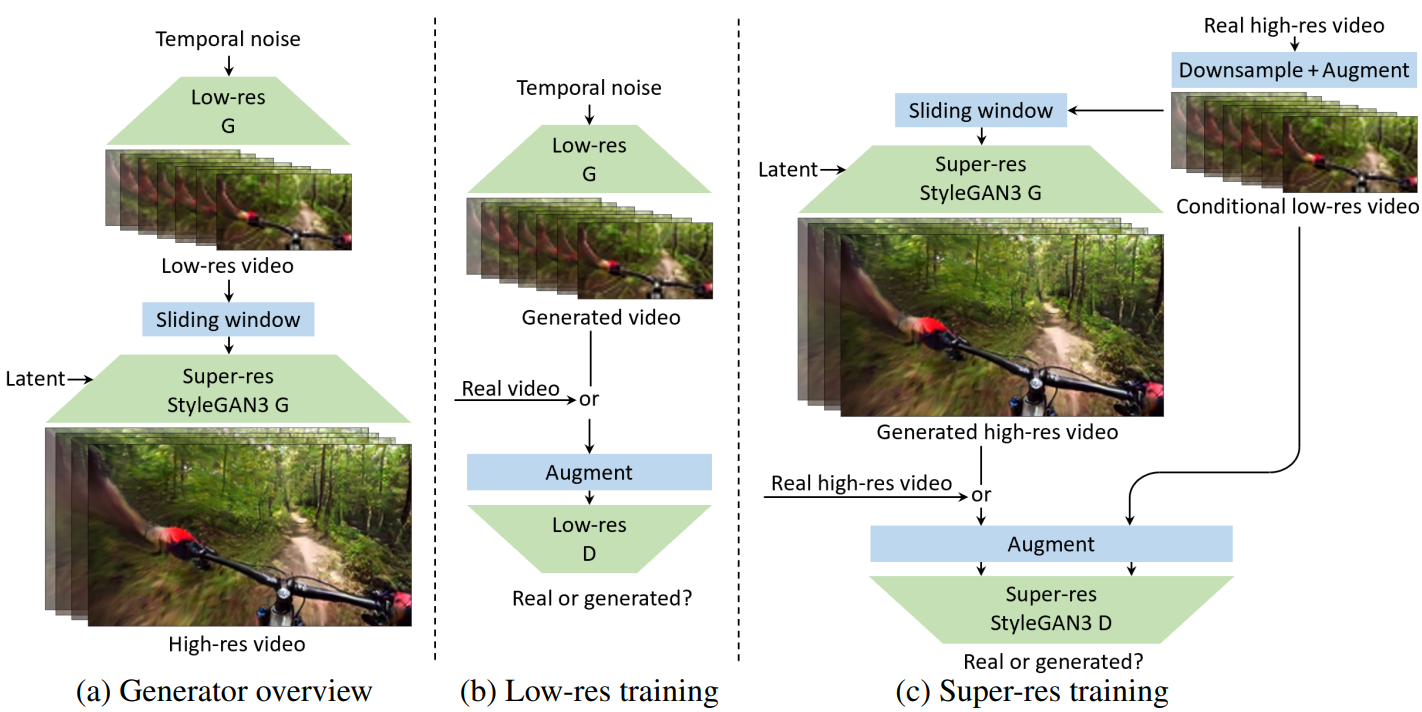
위 그림의 (a)는 generator의 전체 디자인을 보여준다. 가우시안 분포에서 가져온 프레임당 8개의 스칼라 구성 요소로 구성된 가변 길이 temporal noise의 스트림으로 생성 프로세스를 seed한다. Temporal noise는 먼저 저해상도 generator에 의해 처리되어 $64^2$ 해상도의 RGB 프레임 시퀀스를 얻은 다음 별도의 super-resolution 네트워크에 의해 정제되어 $256^2$ 해상도의 최종 프레임을 생성한다. 저해상도 generator의 역할은 시간이 지남에 따라 강력한 표현력과 넓은 receptive field를 필요로 하는 동작 및 장면 구성의 주요 양상을 모델링하는 반면, super-resolution 네트워크는 나머지 디테일을 생성하는 보다 세분화된 작업을 담당한다.
이 2단계 디자인은 긴 동영상을 생성하는 측면에서 최대의 유연성을 제공한다. 특히, 저해상도 generator는 시간이 지남에 따라 fully convolutional되도록 디자인되었으므로 생성된 동영상의 지속 시간과 시간 오프셋은 각각 temporal noise를 shift하고 재구성하여 제어할 수 있다. 반면 super-resolution는 프레임 단위로 작동한다. 9개의 연속적인 저해상도 프레임의 짧은 시퀀스를 받고 단일 고해상도 프레임을 출력한다. 각 출력 프레임은 sliding window를 사용하여 독립적으로 처리된다. fully-convolutional과 프레임당 처리의 조합을 통해 임의 순서로 임의 프레임을 생성할 수 있으며, 이는 예를 들어 인터랙티브한 편집이나 실시간 재생에 매우 바람직하다.
저해상도 및 super-resolution 네트워크는 RGB bottleneck이 사이에 있는 모듈식이다. 이는 네트워크가 독립적으로 학습되고 inference 중에 다양한 조합으로 사용될 수 있기 때문에 실험을 크게 단순화한다.
1. Low-resolution generator
위 그림의 (b)는 저해상도 generator에 대한 학습 설정을 보여준다. 각 iteration에서 generator에 새로운 임시 noise 셋을 제공하여 128프레임(30fps에서 4.3초)의 시퀀스를 생성한다. Discriminator를 학습시키기 위해 랜덤 동영상과 해당 동영상 내에서 128프레임의 랜덤 간격을 선택하여 학습 데이터에서 해당 시퀀스를 샘플링한다. 저자들은 긴 시퀀스를 사용한 학습이 overfitting 문제를 악화시키는 경향이 있음을 관찰했다. 시퀀스 길이가 증가함에 따라 generator가 여러 시간 스케일에서 시간 역학을 동시에 모델링하는 것이 더 어려워지지만 동시에 discriminator가 실수를 더 쉽게 발견할 수 있다. 실제로 저자들은 학습을 안정화하기 위해 강력한 discriminator augmentation이 필요하다는 것을 발견했다. 시퀀스의 각 프레임에 대해 동일한 변환을 사용하는 DiffAug와 $\frac{1}{2} \times$와 $2 \times$ 사이의 분수 시간 stretching을 사용한다.
Architecture
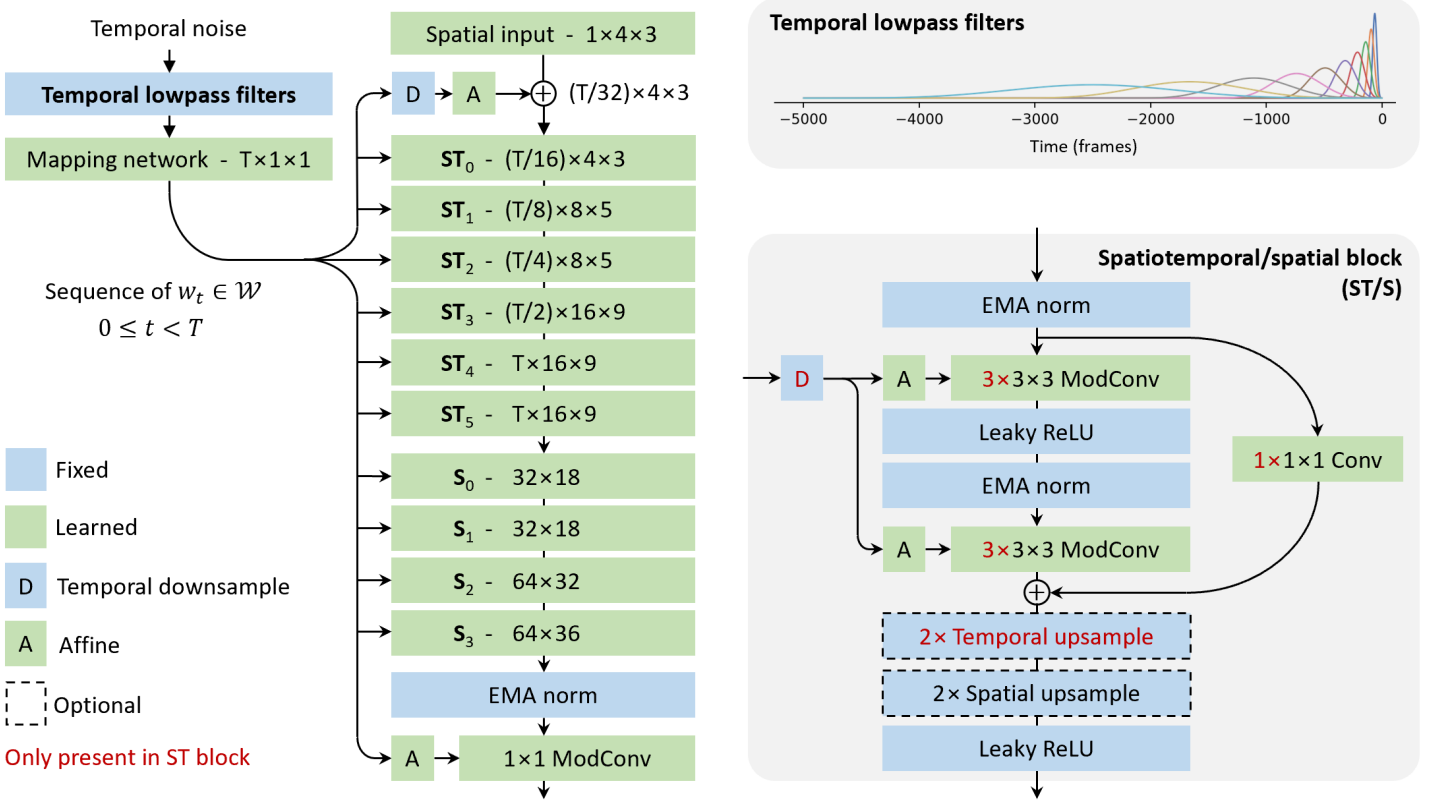
위 그림은 저해상도 generator의 아키텍처를 보여준다. 주요 목표는 시간적 latent 표현, 시간적 스타일 변조, 시공간 convolution 및 시간적 upsample의 신중한 설계를 포함하여 시간 축을 가장 중요한 축으로 만드는 것이다. 이러한 메커니즘을 통해 generator는 방대한 시간적 receptive field(5k 프레임)에 걸쳐 여러 시간 스케일에서 시간적 상관 관계를 나타낼 수 있다.
저자들은 StyleGAN3와 유사한 스타일 기반 디자인을 사용하였다. Temporal noise 입력을 기본 합성 경로에서 각 레이어의 동작을 변조하는 데 사용되는 일련의 중간 latent \(\{w_t\}\)로 매핑한다. 각 중간 latent는 특정 프레임과 연관되지만 기본 경로에 나타나는 계층적 3D convolution을 통해 여러 프레임의 장면 구성 및 시간적 동작에 상당한 영향을 미칠 수 있다.
스타일 기반 디자인의 이점을 최대한 활용하려면 날씨 변화 또는 지속적인 개체와 같은 장기적인 시간적 상관 관계를 중간 latent에서 캡처하는 것이 중요하다. 이를 위해 먼저 일련의 temporal lowpass filter를 사용하여 temporal noise 입력을 풍부하게 한 다음 프레임 단위로 fully-connected mapping network를 통해 전달하는 방식을 채택한다. Lowpass filtering의 목표는 mapping network에 다양한 시간 스케일에 걸쳐 충분한 장기 컨텍스트를 제공하는 것이다. 구체적으로, temporal noise $z(t) \in \mathbb{R}^8$의 스트림이 주어지면 해당하는 풍부한 표현 $z’(t) \in \mathbb{R}^{128 \times 8}$을 $z_{i,j}’ = f_i \ast z_j$로 계산한다. 여기서 \(\{f_i\}\)는 시간 범위가 100 ~ 5000프레임인 128개의 lowpass filter 집합이며, $\ast$는 시간에 대한 convolution을 나타낸다.
주요 합성 경로는 \(\{w_t\}\)의 시간 해상도를 $32 \times$로 다운샘플링하고 이를 $4^2$ 해상도에서 학습된 상수와 연결하는 것으로 시작한다. 그런 다음 먼저 시간 차원(ST)에 초점을 맞춘 다음 공간 차원(S)에 초점을 맞춰 위 그림의 오른쪽 아래에 표시된 일련의 processing block을 통해 시간 및 공간 해상도를 점진적으로 증가시킨다. 처음 4개의 block에는 512개의 채널이 있고, 그 다음에는 각각 256개, 128개, 64개의 채널이 있는 block이 2개씩 있다. Processing block은 skip connection이 추가된 StyleGAN2와 StyleGAN3과 동일한 기본 building block으로 구성된다. 중간 activation은 각 convolution 전에 normalize되고 적절하게 downsampling된 \(\{w_t\}\) 복사본에 따라 변조된다. 실제로 경계 효과를 제거하기 위해 bilinear upsampling을 사용하고 시간 축에 padding을 사용한다. 시간 latent 표현과 시공간 processing block의 조합을 통해 아키텍처는 시간이 지남에 따라 복잡하고 장기적인 패턴을 모델링할 수 있다.
Discriminator의 경우 넓은 시간적 receptive field, 3D 시공간 및 1D 시간적 convolution, 공간 및 시간적 downsampling을 통해 시간 축을 우선시하는 아키텍처를 사용한다.
2. Super-resolution network
동영상 super-resolution network는 조건부 프레임 생성을 위한 StyleGAN3의 간단한 확장이다. 일련의 프레임을 출력하고 명시적 시간 연산을 포함하는 저해상도 네트워크와 달리 super-resolution generator는 단일 프레임을 출력하고 입력에서 시간 정보만 사용한다. 여기서 실제 저해상도 프레임과 시간 전후로 인접한 4개의 실제 저해상도 프레임은 (총 9프레임) 채널 차원을 따라 concat되어 컨텍스트를 제공한다.
공간적 Fourier feature 입력을 제거하고, 저해상도 프레임 스택의 크기를 조정한 후 generator 전체의 각 레이어에 concat한다. Generator 아키텍처는 동영상당 샘플링되는 중간 latent code 사용을 포함하여 StyleGAN3에서 변경되지 않았다. 저해상도 프레임은 생성된 저해상도 이미지에 대한 일반화를 보장하는 데 도움이 되는 데이터 파이프라인의 일부로 컨디셔닝 전에 augmentation을 거친다.
Super-resolution discriminator는 StyleGAN discriminator의 간단한 확장 버전으로, 4개의 저해상도 및 고해상도 프레임이 입력에 concat된다. 유일한 다른 변경 사항은 실제로 불필요하다고 판단한 minibatch standard deviation layer를 제거한 것이다. 4개 프레임의 저해상도 및 고해상도 세그먼트는 두 해상도의 모든 프레임에 동일한 augmentation이 적용되는 적응형 augmentation을 거친다. 또한 저해상도 세그먼트에 공격적인 dropout (전체 세그먼트를 0으로 만들 확률이 p = 0.9)을 적용하여 discriminator가 컨디셔닝 신호에 너무 많이 의존하지 않도록 한다.
이러한 단순한 동영상 super-resolution model이 합리적으로 좋은 고해상도 동영상을 생성하는 데 충분해 보인다는 사실이 놀랍다. 저자들은 실험에서 주로 저해상도 generator에 초점을 맞추고 데이터셋당 학습된 단일 super-resolution network를 활용한다. 향후에 이 간단한 네트워크를 동영상 super-resolution 논문의 고급 모델로 교체할 수 있다.
Datasets
대부분의 기존 동영상 데이터셋은 시간이 지남에 따라 새로운 콘텐츠를 거의 또는 전혀 도입하지 않는다. 예를 들어 말하는 얼굴의 데이터셋은 각 동영상의 지속 시간동안 동일한 사람을 보여준다. UCF101은 다양한 인간 행동을 묘사하지만 동영상은 짧고 카메라 움직임이 제한적이며 시간이 지남에 따라 동영상에 들어오는 새로운 개체가 거의 또는 전혀 없다.

모델을 가장 잘 평가하기 위해 시간이 지남에 따라 복잡한 변화를 보이는 1인칭 산악 자전거 및 승마의 두 가지 새로운 동영상 데이터셋을 도입한다. 본 논문의 새로운 데이터셋에는 말이나 자전거 타는 사람의 피사체 움직임, 공간을 이동하는 1인칭 카메라 시점, 시간 경과에 따른 새로운 풍경과 물체가 포함된다. 동영상은 고화질로 제공되며 문제가 있는 부분, 장면 컷, 텍스트 오버레이, 시야 방해 등을 제거하기 위해 수동으로 다듬었다. 산악 자전거 데이터셋에는 30fps에서 길이의 중앙값이 330프레임인 1202개의 동영상이 있고 승마 데이터 세트는 30fps에서 길이의 중앙값이 6504프레임인 66개의 동영상으로 이루어져 있다.
또한 중요한 카메라 움직임을 포함하지만 다른 유형의 움직임이 없는 ACID 데이터셋과 구름이 지나갈 때 시간이 지남에 따라 새로운 콘텐츠를 나타내는 일반적으로 사용되는 SkyTimelapse 데이터셋에서 모델을 평가하지만 동영상은 상대적으로 동질적이며 카메라는 고정된 상태로 유지된다.
Results
1. Qualitative results
다음은 정성적 결과를 나타낸 예시이다.

다양한 모델들이 생성한 동영상들은 웹페이지에서 확인할 수 있다.
결과의 주요 차이는 본 논문의 모델이 시간이 지남에 따라 사실적인 새 콘텐츠를 생성하는 반면 StyleGAN-V는 동일한 콘텐츠를 지속적으로 반복한다는 것이다. 실제 동영상에서는 시간이 지남에 따라 풍경이 바뀌고 말이 공간을 통해 앞으로 나아갈 때 결과가 나타난다. 그러나 StyleGAN-V로 생성된 동영상은 일정한 간격으로 동일한 장면으로 다시 변형되는 경향이 있다. StyleGAN-V의 유사한 반복 콘텐츠는 모든 데이터셋에서 분명하게 나타난다. 예를 들어 SkyTimelapse 데이터셋에서는 StyleGAN-V가 생성한 구름이 앞뒤로 반복적으로 움직인다는 것을 보여준다. MoCoGAN-HD와 TATS는 시간이 지남에 따라 발산하는 비현실적인 급격한 변화로 인해 어려움을 겪고 있으며 DIGAN 결과에는 시공간 모두에서 볼 수 있는 주기적인 패턴이 포함되어 있다. 본 논문의 모델은 새로운 구름의 지속적인 흐름을 생성할 수 있다.
2. Analyzing color change over time
저자들은 적절한 속도로 새 콘텐츠를 얼마나 잘 생성하는지에 대한 통찰력을 얻기 위해 전체 색 구성표가 시간의 함수로 어떻게 변하는지 분석하였다. RGB 색상 히스토그램 간의 교차점으로 색상 유사성을 측정한다. 이는 실제 콘텐츠 변경에 대한 간단한 프록시 역할을 하며 모델의 편향을 밝히는 데 도움이 된다. $H(x, i)$는 $\sum_i H(x, i) = 1$이 되도록 정규화된 주어진 이미지 $x$에 대한 히스토그램 bin $i \in [1, \cdots, N^3]$의 값을 계산하는 3D 색상 히스토그램 함수를 나타낸다. 동영상 클립 \(x = \{x_t\}\)와 프레임 간격 $t$가 주어지면 다음과 같이 색상 유사성을 정의한다.
\[\begin{equation} S(x, t) = \sum_i \min (H(x_0, i), H(x_t, i)) \end{equation}\]$S(x, t)$가 1이면 색상 히스토그램이 $x_0$와 $x_t$에서 같다는 것을 의미한다. 실제로 저자들은 $N = 20$으로 설정하고 128개의 프레임을 포함한 1000개의 랜덤 동영상 클립에서 $S(\cdot, t)$의 평균과 표준 편차를 측정하였다.
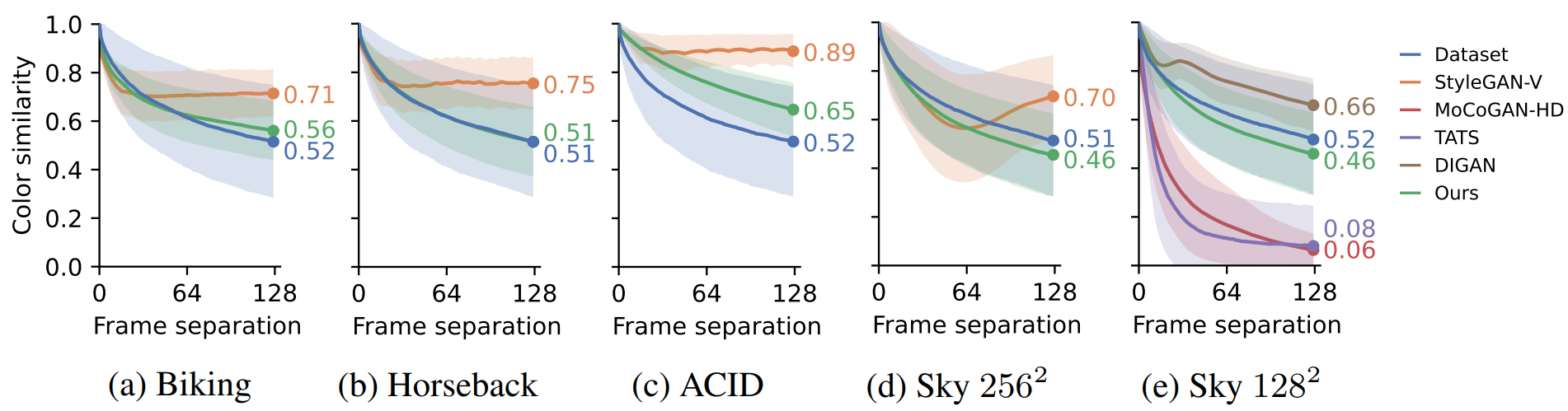
위 그림은 각 데이터셋에서 실제 동영상과 생성된 동영상에 대한 $S(\cdot, t)$를 $t$의 함수로 보여준다. 콘텐츠와 풍경이 점차 변화함에 따라 실제 동영상의 경우 시간이 지남에 따라 곡선이 아래쪽으로 기울어진다. StyleGAN-V과 DIGAN은 색상이 너무 느리게 변하는 쪽으로 편향되어 있다. 이 두 모델 모두 전체 동영상에 대해 고정된 글로벌 latent code를 포함한다. 반면에 MoCoGAN-HD와 TATS는 색상이 너무 빨리 변하는 경향이 있다. 이러한 모델은 각각 RNN과 autoregressive network를 사용하며 둘 다 누적 오차로 인해 어려움을 겪는다. 본 논문의 모델은 목표 곡선의 모양과 거의 일치하며 생성된 동영상의 색상이 적절한 속도로 변경됨을 나타낸다.
3. Fréchet video distance (FVD)
다음은 128프레임과 16프레임의 세그멘트에 대한 FVD를 계산한 표이다.

표의 왼쪽 부분을 보면, 본 논문의 모델은 시간이 지남에 따라 더 복잡한 변화를 포함하는 승마 및 산악 자전거 데이터셋에서 StyleGAN-V를 능가하지만 ACID에서는 성능이 떨어지고 $\textrm{FVD}_128$ 측면에서 SkyTimelapse에서는 약간 성능이 떨어진다. 그러나 이러한 저조한 성과는 사용자 연구의 결론과 크게 다르다. 저자들은 이러한 불일치가 StyleGAN-V가 더 나은 개별 프레임을 생성하고 아마도 더 나은 소규모 모션을 생성하지만 믿을 수 있는 장기적 사실감을 재현하는 데는 심각하게 부족하고 FVD가 주로 전자 측면에 민감하기 때문에 발생한다고 생각한다.
표의 오른쪽 부분은 $128^2$에서 SkyTimelapse에 대한 FVD를 측정한 것이다. 이 비교에서 본 논문의 모델은 $\textrm{FVD}_128$ 측면에서 모든 basline을 능가한다.
4. Ablations
다음은 학습 시퀀스 길이와 temporal lowpass filter footprint에 대한 ablation 결과를 나타낸 표이다.

(a)를 보면 학습 중에 긴 동영상을 관찰하면 모델이 장기적인 일관성을 학습하는 데 도움이 되는 것을 볼 수 있다. (b)를 보면 부적절하게 크기가 조정된 필터를 사용할 경우의 부정적인 영향을 보여준다.
다음은 super-resolution network의 효과를 나타낸 것이다.

(a)와 (b)는 super-resolution network에서 생성된 해당 고해상도 프레임과 함께 모델에서 생성된 저해상도 프레임의 예시를 보여준다. Super-resolution network가 일반적으로 잘 수행됨을 확인할 수 있다. 결과의 품질이 super-resolution network에 의해 불균형적으로 제한되지 않도록 하기 위해 입력으로 super-resolution network에 실제 저해상도 비디오를 제공할 때 FVD를 추가로 측정한다. (c)를 보면 실제로 FVD는 이 경우 크게 향상되며, 이는 저해상도 generator를 추가로 개선하여 실현할 상당한 이득이 있음을 나타낸다.