[논문리뷰] LM2: Large Memory Models
arXiv 2025. [Paper] [Github]
Jikun Kang, Wenqi Wu, Filippos Christianos, Alex J. Chan, Fraser Greenlee, George Thomas, Marvin Purtorab, Andy Toulis
Convergence Labs Ltd.
9 Feb 2025
Introduction
Transformer 기반 모델은 광범위한 응용 분야에서 SOTA 성능을 확립했다. 대규모 모델에 대한 연구에서 입증되었듯이, 데이터와 모델 크기가 증가함에 따라 일반화 능력이 상당히 향상되어 원래의 학습 목표를 넘어서는 새로운 행동으로 이어진다. 하지만 현재의 Transformer 모델은 긴 컨텍스트 추론 task에 적용될 때 중대한 한계에 부딪힌다. 예를 들어, needle-in-a-haystack 문제에서 모델은 매우 긴 문서에 흩어져 있는 사실에 대한 추론을 요구하는 질문에 답해야 한다. 광범위한 컨텍스트를 가진 task를 효과적으로 처리하려면 모델이 방대한 양의 데이터에서 필수적인 정보를 식별할 수 있는 능력이 필요하다.
최근의 메모리 증강 아키텍처는 반복적인 프롬프트를 사용하여 긴 컨텍스트 정보를 추적함으로써 이러한 과제를 해결하려고 시도하였다. 그러나 이러한 아키텍처는 장기 정보를 완전히 통합하지 않고 주로 이전 답변을 프롬프트에 요약하여 긴 컨텍스트에서 성능이 저하된다. 또한 이러한 모델은 메모리 기반 task들에 맞춤화되어 LLM에 내재된 일반화 능력을 희생된다.
이러한 한계를 해결하기 위해, 본 논문은 Transformer 프레임워크를 전용 메모리 모듈로 강화하는 새로운 아키텍처인 Large Memory Model (LM2)을 제안하였다. 이 메모리 모듈은 보조 저장 및 검색 메커니즘으로 기능하며, 입력 임베딩과 동적으로 상호 작용하여 성능을 개선시킨다. 메모리 모듈은 구조화된 프로세스를 따른다. 메모리 뱅크로 초기화하고, 시퀀스 임베딩과의 효율적인 상호 작용을 위해 cross-attention을 활용하고, gating 메커니즘을 사용하여 저장된 정보를 선택적으로 업데이트한다.
LM2는 메모리 저장 및 검색을 즉각적인 처리에서 분리하여, long-term dependency를 모델링하고, 기존 방법의 단점을 극복하면서 계산 효율성을 유지한다. 또한, 긴 컨텍스트와 복잡한 추론이 필요한 task에 특히 적합하다.
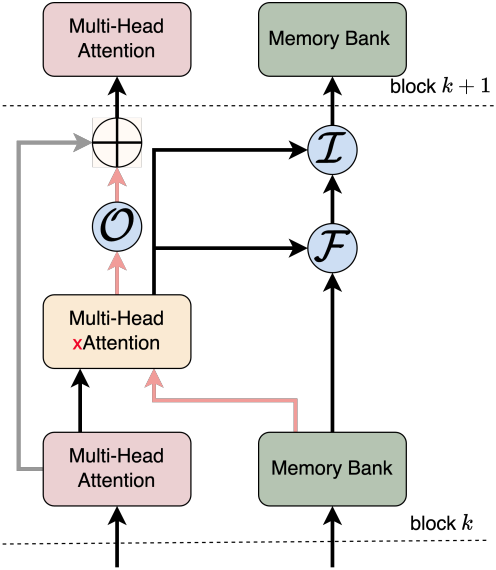
저자들은 원래의 정보 흐름, 즉 한 블록에서 다음 블록으로 전달된 출력 임베딩을 유지하면서 메모리 임베딩으로 표현되는 추가적인 메모리 정보 흐름을 도입하였다. 메모리 정보 흐름은 학습 가능한 출력 게이트에 의해 제어되며, 출력 게이트는 cross-attention을 사용하여 후속 레이어로 전달되는 메모리 정보의 양을 동적으로 조절한다. 이 디자인은 원래의 attention 정보 흐름이 그대로 유지되는 동시에 필요에 따라 관련 메모리 정보를 동적으로 통합하도록 보장한다.
LM2는 BABILong 데이터셋과 MMLU 벤치마크에서 SOTA 메모리 모델인 Recurrent Memory Transformer(RMT)보다 최대 80.4% 더 우수한 성능을 보였으며, multi-hop inference, 수치적 추론, 관계적 논증에서 향상된 능력을 보여주었다. 이러한 개선 사항은 Transformer 아키텍처 내에 명시적 메모리 메커니즘을 통합하면 확장된 컨텍스트를 보다 강력하게 처리할 수 있음을 의미한다.
Method
LM2는 여러 Transformer 디코더 블록으로 구성되어 있으며, 표현의 중간 시퀀스를 동적으로 저장하고 업데이트하는 메모리 모듈로 증강된다. 디코더 블록은 위치 임베딩을 사용하여 입력 시퀀스를 처리하는 반면, 메모리 모듈은 cross-attention 메커니즘을 통해 이러한 임베딩과 상호 작용한다. Multi-head attention과 메모리 모듈 간의 skip connection을 사용하여 학습을 용이하게 하고 Transformer의 원래 중간 임베딩을 유지한다.
메모리 업데이트는 학습 가능한 제어 게이트, 즉 망각 게이트 $\mathcal{F}$, 입력 게이트 $\mathcal{I}$, 출력 게이트 $\mathcal{O}$에 의해 제어된다. 메모리 모듈은 메모리 정보 흐름과 메모리 업데이트라는 두 가지 기본 단계를 통해 작동한다.
1. Memory Information Flow
LM2는 Long-term memory를 저장하도록 설계된 메모리 뱅크 $\textbf{M} \in \mathbb{R}^{N \times d \times d}$를 명시적으로 사용한다 ($N$은 메모리 슬롯의 수, $d$는 각 슬롯의 hidden dimension). 단순화를 위해 각 메모리 슬롯은 단위 행렬 \(\textbf{M}_r = \textbf{I}_{d \times d}\)로 초기화된다.
메모리 뱅크와 입력 임베딩 사이에 cross-attention 기반 메커니즘을 사용하여 관련 정보가 포함된 메모리 슬롯을 찾는다. 구체적으로 각 입력 임베딩 $\textbf{E}$는 query 역할을 하는 반면, 메모리 뱅크 $\textbf{M}$은 key와 value 저장소 역할을 한다. 직관적으로 이는 $\textbf{M}$에서 key를 통해 어디에 있는지를 찾아 관련 정보를 찾은 다음, value를 통해 이를 가져오는 것을 의미한다.
Cross-attention을 활성화하기 위해 입력 임베딩 $\textbf{E} \in \mathbb{R}^{T \times d}$와 ($T$는 시퀀스 길이) 메모리 뱅크 $\textbf{M} \in \mathbb{R}^{N \times d}$가 query $\textbf{Q}$, key $\textbf{K}$, value $\textbf{V}$ 공간으로 projection된다.
\[\begin{equation} \textbf{Q} = \textbf{E}_t \textbf{W}^Q, \quad \textbf{K} = \textbf{M}_t \textbf{W}^K, \quad \textbf{V} = \textbf{M}_t \textbf{W}^V \end{equation}\]($\textbf{W}^Q, \textbf{W}^K, \textbf{W}^V \in \mathbb{R}^{d \times d}$는 학습 가능한 projection matrix, $t$는 디코더 블록 $t$를 의미함)
Attention score는 query와 key 행렬의 스케일링된 내적으로 계산된다.
\[\begin{equation} \textbf{A} = \textrm{softmax} \left( \frac{\textbf{Q} \textbf{K}^\top}{\sqrt{d}} \right) \in \mathbb{R}^{T \times N} \end{equation}\]여기서 $\textbf{A}$은 입력 시퀀스와 메모리 슬롯 간의 정렬을 나타낸다. 결과적인 attention 출력은
\[\begin{equation} \textbf{E}_\textrm{mem} = \textbf{A}\textbf{V} \in \mathbb{R}^{T \times d} \end{equation}\]이고, \(\textbf{E}_\textrm{mem}\)은 입력과 메모리의 정보를 통합한다. 시간적 일관성을 보장하기 위해 causal masking이 적용되고, 선택적으로 상위 $k$개의 attention이 가장 관련성 있는 메모리 상호작용만 유지하는 데 사용된다.
메모리 정보(회색 경로)가 기존 attention 정보 흐름(분홍색 경로)에 미치는 영향을 조절하기 위해 출력 게이트가 도입되었다. 출력 게이트는 \(\textbf{E}_\textrm{mem}\)을 기반으로 메모리 검색의 기여도를 동적으로 제어한다.
\[\begin{equation} g_\textrm{out} = \sigma (\textbf{E}_\textrm{mem}, \textbf{W}_\textrm{out}) \end{equation}\](\(\textbf{W}_\textrm{out} \in \mathbb{R}^{d \times d}\)는 학습 가능한 행렬, $\sigma$는 시그모이드 함수)
그러면, gating된 메모리 출력은 다음과 같이 계산된다.
\[\begin{equation} \textbf{E}_\textrm{gated} = g_\textrm{out} \cdot \textbf{M}_t \end{equation}\]Gating된 메모리 출력은 skip connection을 통해 Transformer 디코더의 표준 attention 정보 흐름에 통합된다. 구체적으로, self-attention 메커니즘의 출력인 \(\textbf{E}_\textrm{attn}\)은 gating된 메모리 출력과 결합된다.
\[\begin{equation} \textbf{E}_\textrm{next} = \textbf{E}_\textrm{attn} + \textbf{E}_\textrm{gated} \end{equation}\]이 skip connection은 표준 attention 출력과 메모리로 증강된 feature가 다음 디코더 레이어에 공동으로 기여하도록 보장한다.
LM2는 메모리 검색을 동적으로 gating하고 attention 흐름과 통합함으로써, 메모리와 컨텍스트 정보의 사용을 효과적으로 균형 있게 조정하여 핵심 Transformer 연산들을 보존하면서 long-term dependency를 모델링하는 능력을 향상시킨다.
2. Memory updates
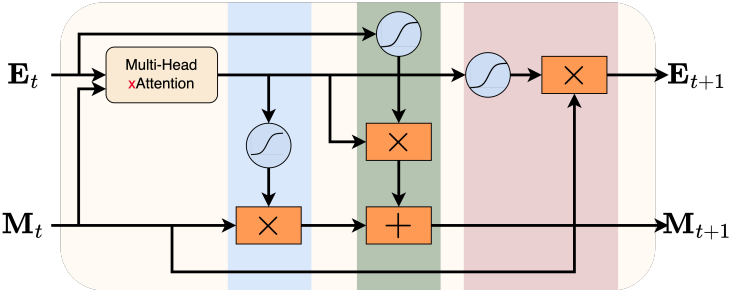
업데이트 프로세스는 입력, 망각, 출력의 세 가지 뚜렷한 단계로 나뉜다. 얼마나 많은 새로운 정보가 도입되고 얼마나 많은 오래된 정보가 폐기되는지를 gating함으로써 긴 컨텍스트 시퀀스를 처리할 때 중요한 장기적 사실을 덮어쓰는 것을 방지하는 동시에 관련성이 없거나 오래된 콘텐츠를 제거한다.
입력 단계
입력 단계에서 모델은 새로 계산된 임베딩 \(\textbf{E}_\textrm{mem}\) 중 얼마를 메모리에 통합할지 결정한다. 이를 위해 먼저 입력 게이트가 계산된다.
\[\begin{equation} g_\textrm{in} = \sigma (\textbf{E}_t \textbf{W}_\textrm{in}) \end{equation}\](\(\textbf{W}_\textrm{in} \in \mathbb{R}^{d \times d}\)는 학습 가능한 행렬, \(\textbf{E}_t\)는 현재 입력 표현, $\sigma$는 시그모이드 함수)
이 gating 메커니즘은 필터 역할을 하여 어떤 관련 정보를 메모리에 써야 하는지 결정하는 동시에 노이즈나 중복된 디테일의 유입을 방지한다.
망각 단계
입력 단계에서 새로운 정보가 제공되면 메모리는 기존 콘텐츠의 어떤 부분을 버릴지 결정해야 한다. 이는 망각 게이트에 의해 관리된다.
\[\begin{equation} g_\textrm{forget} = \sigma (\textbf{E}_\textrm{mem} \textbf{W}_\textrm{forget}) \end{equation}\](\(\textbf{W}_\textrm{forget} \in \mathbb{R}^{d \times d}\)는 학습 가능한 행렬)
1보다 작은 값을 출력함으로써, 망각 게이트는 더 이상 관련성이 없는 메모리 슬롯을 선택적으로 지워 모델이 더 최근 또는 중요한 정보에 집중할 수 있도록 한다.
메모리 업데이트
이 두 가지 gating 메커니즘을 결합하면 업데이트된 메모리 상태가 생성된다.
\[\begin{equation} \textbf{M}_{t+1} = g_\textrm{in} \cdot \textrm{tanh} (\textbf{E}_\textrm{mem}) + g_\textrm{forget} \cdot \textbf{M}_t \end{equation}\]여기서 tanh 함수가 적용되어 새로운 메모리 내용이 제한된다. 메모리 모듈은 가장 관련성 있는 정보를 기억하고 오래된 디테일한 정보를 제거하여 시간이 지나도 간결하고 유익한 정보를 유지한다.
Experiments
- 데이터셋: SmolLM-Corpus
- 언어 모델로 생성한 교과서와 스토리 (총 280억 토큰)
- FineWeb-Edu에서 얻은 교육용 웹 콘텐츠 (총 2,200억 토큰)
- 파이썬 코드
- Base model: Llama-3 (1.2B)
- 디코더 블록 16개 (차원: 2,048)
- feed-forward network 차원: 8,192
- attention head 32개
- 메모리 모듈 (0.5B)
- 메모리 슬롯 2,048개 (차원: 2,048)
- 모든 디코더 블록에 통합됨
1. Performance on Memory Tasks
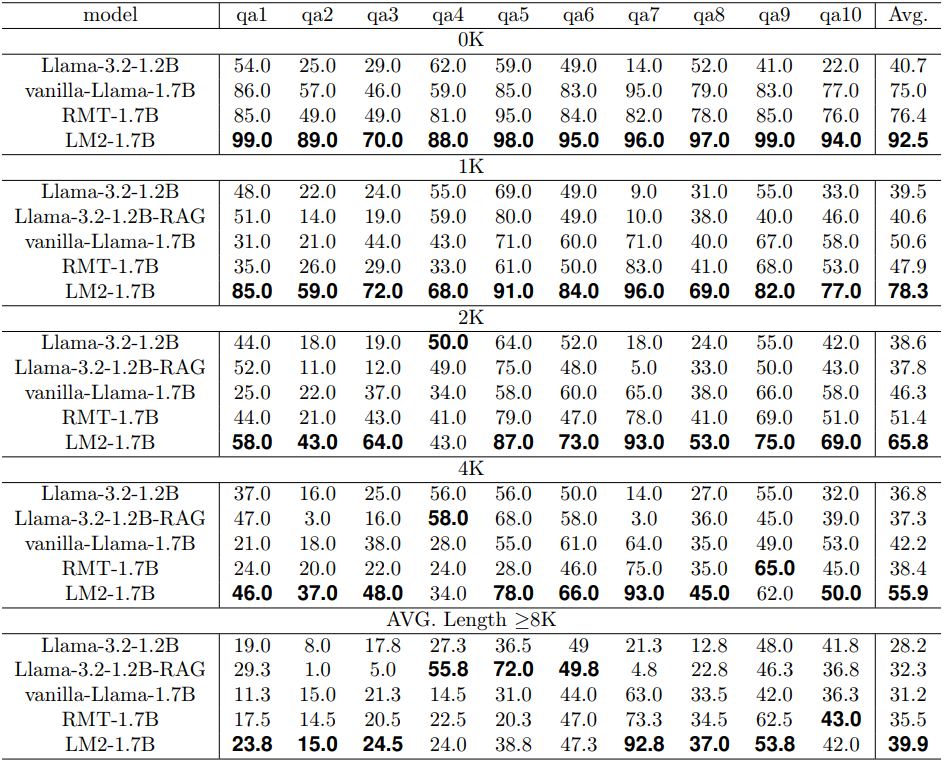
다음은 BABILong 데이터셋에서 성능을 비교한 결과이다.
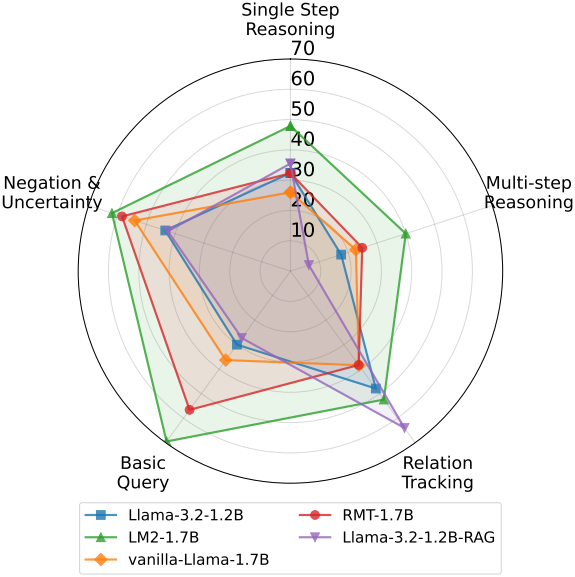
2. Performance on General Benchmarks
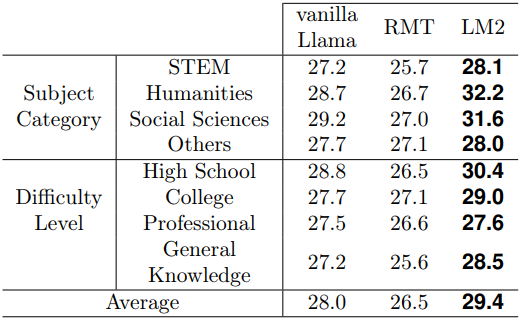
다음은 MMLU 벤치마크에서의 성능을 비교한 표이다.
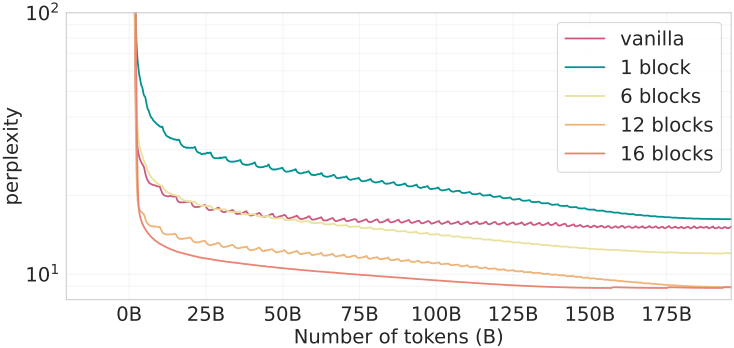
3. Impact of memory modules
다음은 메모리 모듈을 포함하는 디코더 블록의 수에 따른 성능을 비교한 그래프이다. 참고로, 메모리 모듈을 구현하는 순서가 성능에 영향을 미치지 않는다고 한다.
4. Analysis of Memory Representations
저자들은 Neuron Explainer을 활용하여 각 메모리 슬롯의 latent 표현을 분석하였다.

저자들은 MMLU에서 질문들을 뽑아 위와 같이 few-shot 방식으로 프롬프트를 입력하고, 가장 관련된 두 개의 메모리 슬롯(1679, 1684)과 가장 관련이 없는 메모리 슬롯(1)을 선택하였다. Neuron Explainer의 결과를 기반으로 한 각 메모리 슬롯에 대한 분석 결과는 다음과 같다.
- 1679: 타겟 질문에 대한 사실 정보를 검색하고 종합하는 데 특화되어 있으며, 도메인별 지식과 구조화된 추론을 위한 저장소 역할을 한다.
- 1684: 입력 텍스트 내의 구조적 요소에 초점을 맞추고 있으며, 이러한 동작은 모델의 입력 구조 이해를 용이하게 하여 복잡한 명령 형식과 여러 부분으로 된 구조의 효과적인 파싱을 가능하게 한다.
- 1: 입력 텍스트 전반에 걸쳐 주로 부정적인 activation을 보였으며, 이는 task별 콘텐츠에 대한 참여가 최소임을 나타낸다.
5. Test-time memory adaptations
다음은 위의 예시에 대한 메모리 업데이트 전후의 cross-attention 히트맵이다.
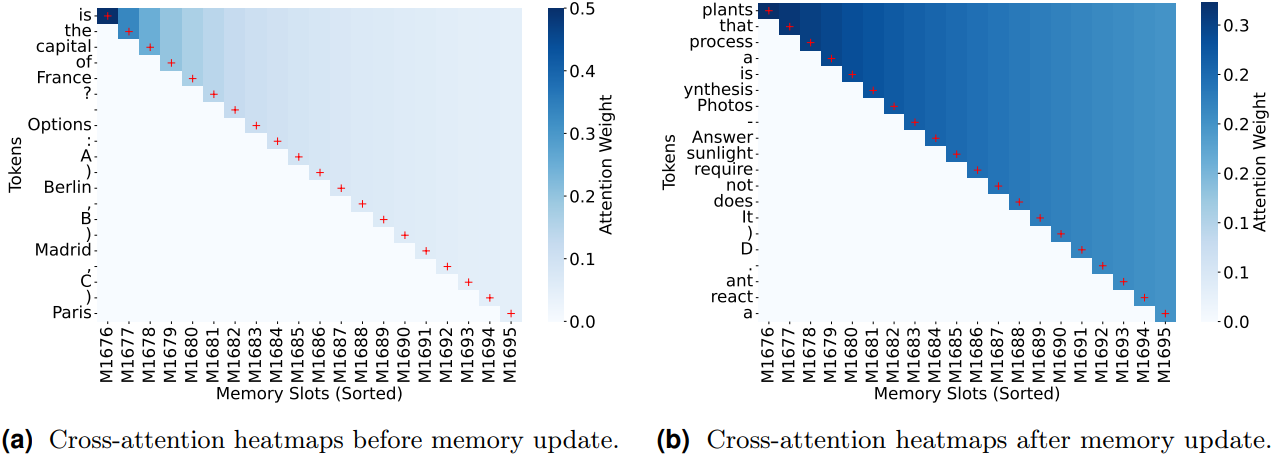
(a)에서 볼 수 있듯이, 메모리 업데이트 전에 “France”와 “Paris”와 같은 토큰은 메모리와 강력하게 상호 작용한다. 이러한 토큰들은 광합성에 대한 질문과 특별히 관련이 없다. 대신 메모리는 처음에 질문의 구조와 사실 정보를 식별하는 데 초점을 맞춘다.
(b)에서 볼 수 있듯이, 메모리 업데이트 후에 메모리 슬롯이 처리하는 토큰은 대상 질문과 관련된 토큰으로 이동한다. Cross-attention은 입력 토큰과 메모리 간의 관계만 계산하므로 이러한 변화는 test-time 메모리 업데이트의 영향을 반영한다. 이러한 변화는 inference 중 메모리의 적응적 특성을 보여준다.