[논문리뷰] Low-latency Real-time Voice Conversion on CPU (LLVC)
arXiv 2023. [Paper] [Github]
Konstantine Sadov, Matthew Hutter, Asara Near
Koe AI
1 Nov 2023
Introduction
음성 변환(voice conversion)은 원래 음성의 단어와 억양을 유지하면서 다른 화자의 스타일로 음성을 렌더링하는 task이다. “Any-to-one” 음성 변환은 학습 중에 보지 못한 임의의 입력 화자의 음성을 하나의 고정 화자 스타일의 음성으로 변환한다. 음성 변환의 실제 적용에는 음성 합성, 음성 익명화, 음성 정체성 변경이 포함된다.
음성 변환의 핵심 과제는 타겟 화자와의 유사성을 보장하고 자연스러운 출력을 생성하는 것이다. 실시간 음성 변환은 기존 고품질 음성 합성 네트워크에 부적합한 추가적인 과제를 부여한다. 즉, 신경망이 실시간보다 빠르게 작동해야 할 뿐만 아니라 낮은 대기 시간과 미래 오디오 컨텍스트에 대한 최소한의 액세스로 작동해야 한다. 또한 광범위한 사용을 위한 실시간 음성 변환 네트워크는 리소스가 적은 컴퓨팅 환경에서도 작동할 수 있어야 한다.
본 논문에서는 Waveformer 아키텍처 기반의 any-to-one 음성 변환 모델을 제안한다. Waveformer는 실시간 사운드 추출을 수행하도록 설계된 반면, LLVC는 모델 출력과 합성된 타겟 음성 사이의 인지 가능한 차이를 최소화하려는 목적 함수로 하나의 타겟 화자와 같은 소리로 모두 변환된 다양한 화자의 음성에 대한 인공적인 병렬 데이터셋에 대해 학습된다. LLVC는 20ms의 낮은 지연 시간으로 CPU에서 스트리밍 방식으로 음성을 변환할 수 있는 최초의 오픈 소스 모델이다.
LLVC
1. Architecture
1.1 Generator
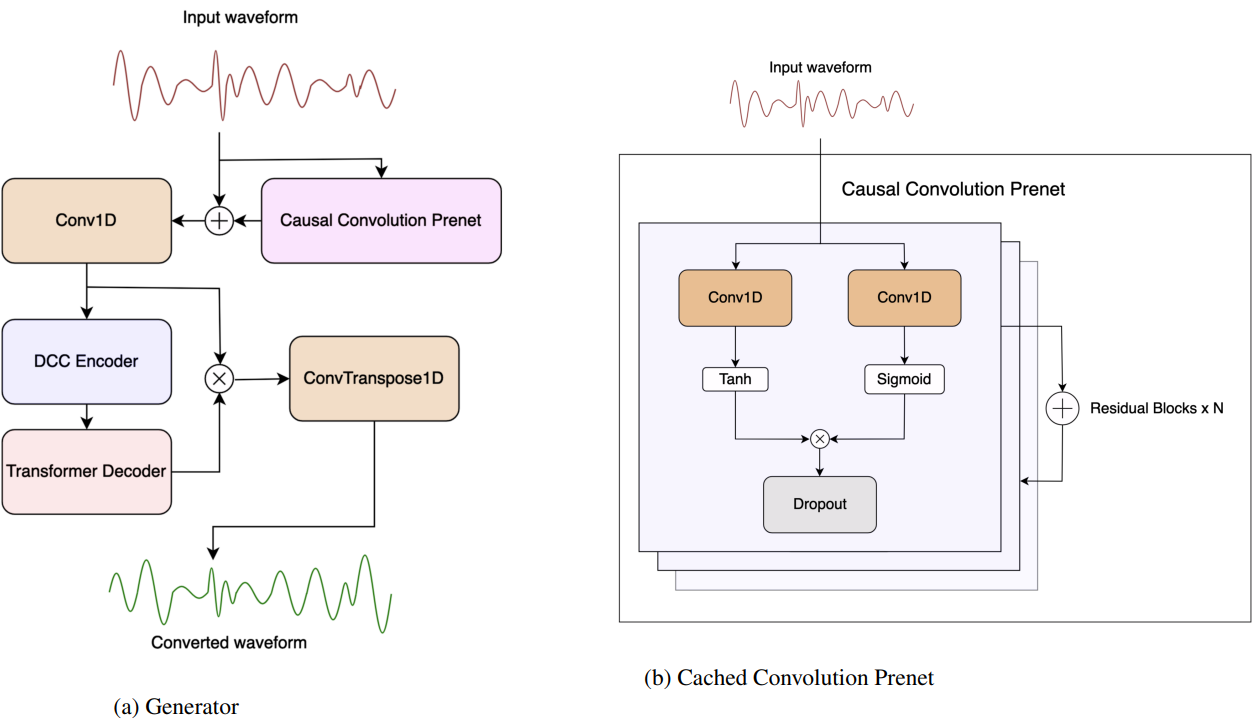
Generator는 Waveformer의 스트리밍 인코더-디코더 모델에서 파생되었다. 저자들은 Waveformer의 512차원 인코더와 256차원 디코더를 모델의 기반으로 채택했지만 inference 지연 시간과 계산 속도를 낮추기 위해 인코더 깊이를 10에서 8로 줄이고 예측을 16개 샘플로 줄였다. 음성 모델링 및 음성 향상을 위한 causal U-Net의 성공을 기반으로 causal convolutions으로 구성된 prenet을 모델 앞에 붙인다.
1.2 Discriminator
RVC의 v2 discriminator에서 영감을 받은 discriminator period를 사용하여 VITS의 multi-period discriminator 아키텍처를 채택하였다.
2. Loss
LLVC의 discriminator는 VITS의 discriminator와 동일한 loss를 사용한다. LLVC의 generator는 VITS의 generator loss와 feature loss, mel-spectrogram loss, self-supervised 음성 표현 기반 loss의 가중 합을 사용한다. Mel-spectrogram loss는 VITS mel loss에서 파생되지만 VITS 구현을 auraloss 라이브러리의 다중 해상도 mel-spectrogram loss로 대체한다. Self-supervised 표현 loss는 사전 학습된 fairseq HuBERT Base model로 인코딩된 feature 간의 L1 거리를 기반으로 한 loss를 사용한다.
3. Inference
LLVC 스트리밍 inference 절차는 Waveformer의 청크 기반 inference를 따른다. 하나의 청크는 $\textrm{dec_chunk_len} \times L$개의 샘플로 구성된다. Inference에는 추가로 $2L$개의 샘플에 대한 예측이 필요하다. 총 지연 시간은
\[\begin{equation} \frac{\textrm{dec_chunk_len} \times L + 2L}{F_s} \end{equation}\]초이다. 여기서 $F_s$는 Hz 단위의 오디오 샘플레이트이다. 변환의 real-time factor (RTF)를 개선하기 위해 한 번에 $N$개의 청크로 네트워크를 실행하여 대기 시간을 늘릴 수도 있다.
Experiments
- 데이터셋: LibriSpeech clean 360 hour train split
- librivox.org 웹사이트에서 얻은 39분 오디오에 대해 학습된 RVC v2 모델로 LibriSpeech 파일을 변환하여 하나의 타겟 화자의 스타일로 병렬 발화를 생성
- RMVPE pitch 추출 방법을 사용하여 타겟 화자 데이터에 대해 325 epoch 동안 32k RVC v2 base model을 fine-tuning
- 일반적인 RVC 파이프라인에는 인코딩된 입력 화자 데이터가 타겟 화자 데이터와 혼합되는 단계가 포함되지만, 변환 품질이나 유사성을 향상시키지 않으면서 성능과 명료도를 저하시키는 것으로 나타났기 때문에 이 단계를 생략
- 32kHz로 변환된 오디오를 16kHz로 다운샘플링
- 학습 디테일
- iteration: 50만 step (53 epochs)
- batch size: 9
- optimizer: AdamW ($\beta_1 = 0.8$, $\beta_2 = 0.999$, $\epsilon = 10^{-9}$)
- learning rate: $5 \times 10^{-4}$ (learning rate decay = 0.999)
- RTX 3090 GPU 1개에서 3일 소요
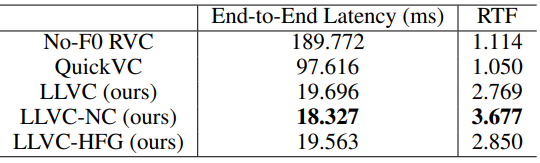
1. Performance
다음은 전체 지연시간과 RTF를 비교한 표이다.
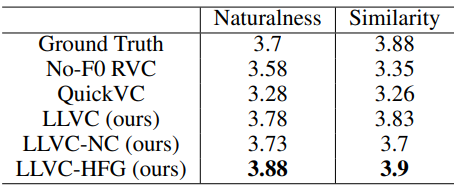
2. Naturalness and Target-Speaker Similarity
다음은 자연스러움과 유사성에 대한 Mean Opinion Scores (MOS)를 비교한 표이다.
3. Objective Metrics
다음은 Resemblyze와 WVMOS 라이브러리를 사용하여 얻은 유사성과 품질에 대한 지표를 비교한 표이다.
