[논문리뷰] Improved Baselines with Visual Instruction Tuning
CVPR 2024. [Paper] [Page] [Github]
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
University of Wisconsin–Madison | Microsoft Research | Columbia University
5 Oct 2023
LLaVA의 후속 논문
Introduction
Large Multimodal Model (LMM)은 범용 어시스턴트의 핵심 구성 요소이기 때문에 점점 인기를 얻고 있다. LLaVA와 MiniGPT-4는 자연스러운 지시 따르기와 인상적인 시각적 추론 능력을 보여주었다. LMM의 능력을 더 잘 이해하기 위해 여러 벤치마크가 제안되었다. 최근 연구에서는 사전 학습 데이터, instruction-following 데이터, 비전 인코더 또는 언어 모델을 각각 확장하여 향상된 성능을 보여주었다.
그러나 많은 벤치마크와 개발에도 불구하고 범용 어시스턴트의 목표를 향해 LMM을 학습시키는 가장 좋은 방법이 무엇인지는 여전히 불분명하다. 예를 들어, LLaVA는 대화형 시각적 추론에 탁월하며 이러한 벤치마크에서는 InstructBLIP보다 성능이 뛰어난 반면, InstructBLIP은 단일 단어 또는 짧은 답변을 요구하는 기존 VQA 벤치마크에서 탁월하다. 모델 아키텍처와 학습 데이터의 상당한 차이를 고려할 때 성능 차이의 근본 원인은 여전히 파악하기 어렵다. 본 논문은 통제된 환경에서 LMM의 디자인 선택을 조사하기 위해 최초로 체계적으로 연구하였다. LLaVA를 기반으로 입력, 모델, 데이터의 관점에서 신중하게 로드맵을 구축하였다.
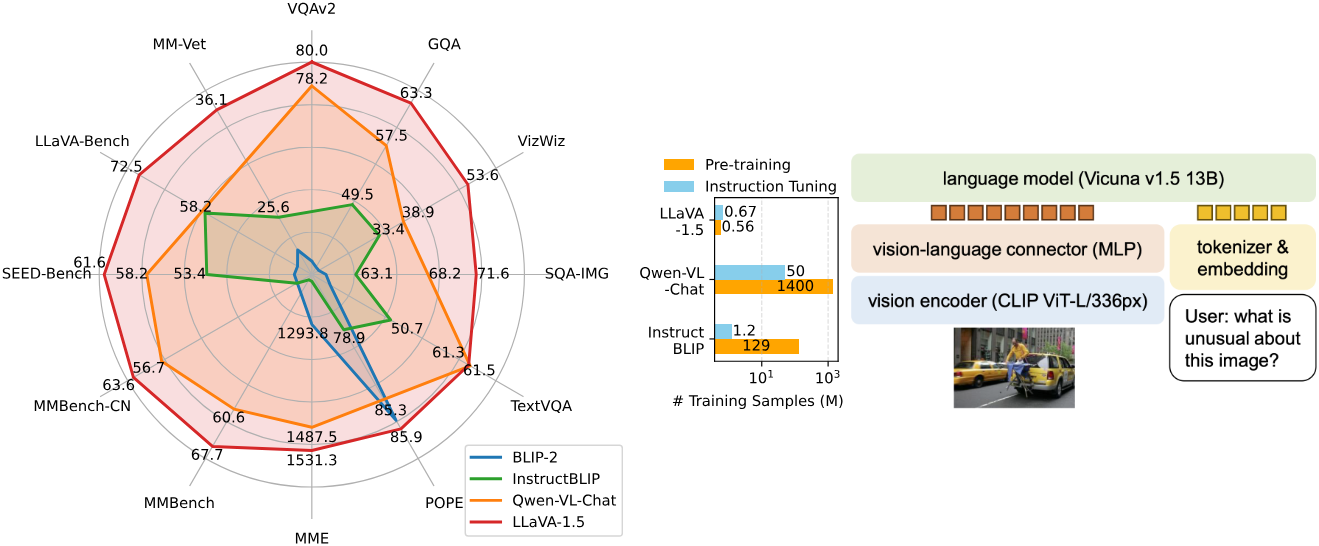
먼저, LLaVA의 fully-connected 비전-언어 커넥터가 놀랍도록 강력하고 데이터 효율적이다. 두 가지 간단한 개선 사항, 즉 MLP cross-modal 커넥터와 VQA와 같은 학문적 작업 관련 데이터를 통합하면 더 나은 멀티모달 이해 능력을 제공한다. 수억 또는 수십억 개의 이미지-텍스트 쌍 데이터에 대해 특별히 설계된 리샘플러를 학습시키는 InstructBLIP과 달리, 단순히 60만 개의 이미지-텍스트 쌍으로 fully-connected projection layer만 학습시키면 된다. 최종 모델인 LLaVA-1.5는 A100 8개에서 약 1일 만에 학습을 마칠 수 있으며 11개의 벤치마크에서 SOTA를 달성하였다. 또한 자체 데이터를 사용하는 Qwen-VL과 달리, 공개 데이터만을 사용하여 학습되었다.
저자들은 LMM의 다른 미해결 문제에 대한 초기 탐색을 조사하였다.
- 고해상도 이미지 입력으로 확장: LLaVA의 아키텍처는 단순히 이미지를 그리드로 분할하고 데이터 효율성을 유지함으로써 더 높은 해상도로 확장하는 데 다재다능하다. 해상도가 높아지면 모델의 상세한 인식 능력이 향상되고 hallucination이 줄어든다.
- 합성 능력: LMM이 합성 능력을 일반화할 수 있다. 예를 들어, 짧은 시각적 추론과 함께 긴 형식의 언어 추론을 학습시키면 멀티모달 질문에 대한 모델의 작성 능력을 향상시킬 수 있다.
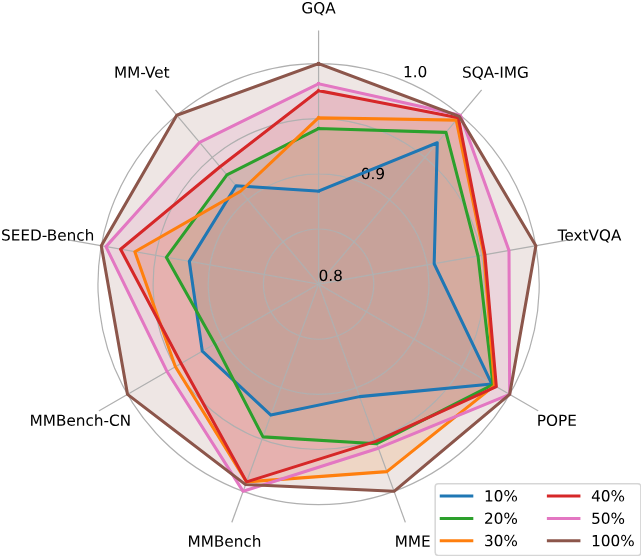
- 데이터 효율성: LLaVA의 학습 데이터 혼합을 무작위로 최대 75%까지 다운샘플링해도 모델 성능이 크게 저하되지 않는다. 이는 보다 정교한 데이터셋 압축 전략의 가능성이 LLaVA의 이미 효율적인 학습 파이프라인을 더욱 향상시킬 수 있음을 시사한다.
- 데이터 스케일링: Hallucination을 도입하지 않고 데이터 세분성 확장을 통해 능력을 향상시킬 수 있다.
Approach
1. Response Format Prompting

자연스러운 응답과 짧은 답변을 모두 포함하는 instruction following 데이터를 활용하는 InstructBLIP과 같은 방법에 대해 단문형 VQA와 장문형 VQA 사이의 균형을 유지할 수 없는 이유는 주로 다음과 같다.
첫째, 응답 형식에 대한 모호한 프롬프트이다 (ex. Q: {질문} A: {답변}). 이러한 프롬프트는 원하는 출력 형식을 명확하게 나타내지 않으며 자연스러운 시각적 대화에 대해서도 LLM을 짧은 형식의 답변으로 overfitting시킬 수 있다.
둘째, LLM을 fine-tuning하지 않는다. InstructBLIP의 경우 instruction tuning을 위해 Qformer만 fine-tuning함으로써 첫 번째 문제가 더욱 악화된다. LLM의 출력 길이를 긴 형식 또는 짧은 형식으로 제어하려면 Qformer의 출력 토큰이 필요하지만 Qformer는 LLM에 비해 용량이 제한되어 있으므로 LLaVA와 달리 제대로 수행하는 능력이 부족할 수 있다.
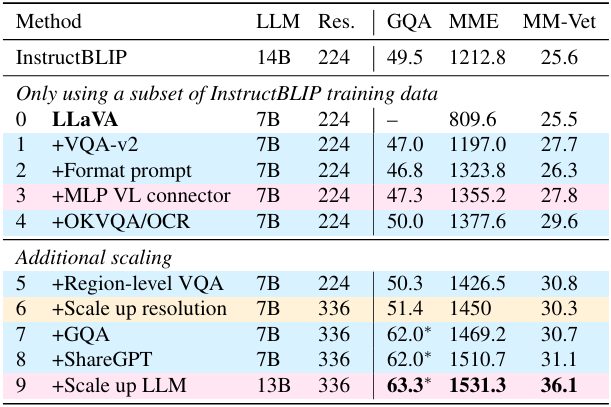
따라서 저자들은 LLaVA가 InstructBLIP의 문제를 해결하면서 짧은 답변을 더 잘 처리할 수 있도록 출력 형식을 명확하게 나타내는 하나의 응답 형식 프롬프트를 사용할 것을 제안하였다. 짧은 답변을 프롬프팅할 때 VQA 질문 끝에 “Answer the question using a single word or phrase”가 추가된다. LLM이 이러한 프롬프트로 fine-tuning되면 LLaVA는 사용자 명령에 따라 출력 형식을 적절하게 조정할 수 있으며 ChatGPT를 사용하여 VQA 답변을 추가로 만들 필요가 없다. 학습에 VQAv2를 포함시키는 것만으로도 LLaVA의 성능이 크게 향상된다.

2. Scaling the Data and Model
- MLP 비전-언어 커넥터. 2-layer MLP로 비전-언어 커넥터의 표현 능력을 향상시키면 원래 linear projection에 비해 LLaVA의 멀티모달 능력이 향상된다.
- 학문적 task 중심의 데이터. 다양한 방식으로 모델의 능력을 향상시키기 위해 VQA, OCR, 영역 수준 인식을 위한 학문적 task 중심의 VQA 데이터셋을 추가로 포함시킨다. 저자들은 먼저 InstructBLIP에서 사용되는 4개의 추가 데이터셋인 OKVQA, A-OKVQA, OCRVQA, TextCaps를 포함시켰다. 또한 영역 수준 VQA 데이터셋인 Visual Genome과 RefCOCO를 추가하면 세밀한 시각적 디테일을 localize하는 모델의 능력이 향상된다.
- 추가 스케일링. 비전 인코더를 CLIPViT-L-336px (사용 가능한 CLIP의 최고 해상도)로 교체하여 LLM이 이미지의 디테일을 명확하게 볼 수 있도록 입력 이미지 해상도를 $336^2$로 더욱 확장한다. 또한 추가적인 시각적 지식 소스로 GQA 데이터셋을 추가하고, ShareGPT 데이터를 통합하여 LLM을 13B로 스케일링시켰다.
모든 수정 사항이 포함된 최종 모델을 LLaVA-1.5라 부르며, 원래 LLaVA보다 훨씬 뛰어난 성능을 달성하였다.
LLaVA-1.5의 경우 동일한 사전 학습 데이터셋을 사용하고 instruction tuning을 위한 학습 iteration 및 batch size를 LLaVA와 거의 동일하게 유지한다. 이미지 입력 해상도가 $336^2$로 증가했기 때문에 LLaVA-1.5의 학습은 LLaVA보다 약 2배가 걸린다. 즉, A100 8개를 사용하여 약 6시간의 사전 학습과 약 20시간의 fine-tuning이 필요하다.
3. Scaling to Higher Resolutions
입력 이미지 해상도를 높이면 모델의 성능이 향상된다. 하지만 기존 CLIP 비전 인코더의 이미지 해상도는 $336^2$로 제한되어 있어 단순히 비전 인코더를 교체하는 것만으로는 더 높은 해상도의 이미지를 지원할 수 없다.
이전 방법들은 ViT를 비전 인코더로 사용하는 경우 해상도를 확장하기 위해 대부분 위치 임베딩의 interpolation을 수행하고 fine-tuning 중에 ViT backbone을 새로운 해상도에 적용했다. 그러나 이를 위해서는 일반적으로 대규모 이미지-텍스트 쌍 데이터셋에서 모델을 fine-tuning해야 하며 이미지 해상도를 inference 중에 LMM이 수용할 수 있는 고정 크기로 제한한다.
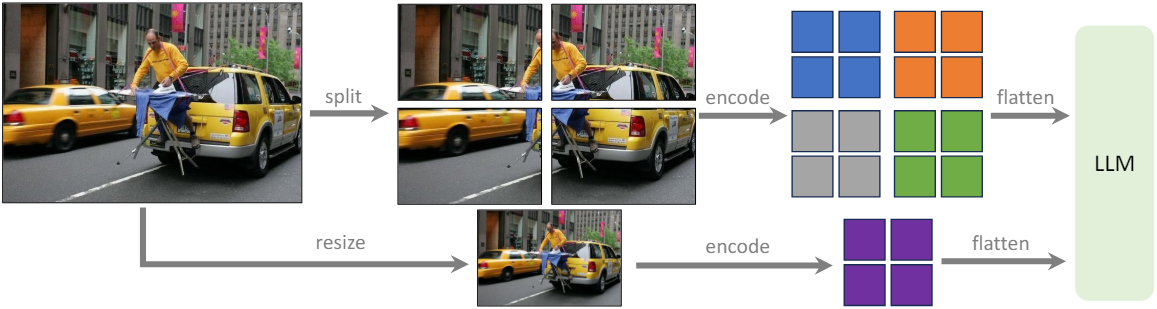
저자들은 그 대신 이미지를 비전 인코더가 원래 학습한 해상도의 더 작은 이미지 패치로 나누고 독립적으로 인코딩함으로써 이 문제를 극복하였다. 개별 패치의 feature map을 얻은 후 이를 대상 해상도의 하나의 feature map으로 결합하고 이를 LLM에 공급한다. LLM에 글로벌 컨텍스트를 제공하고 분할-인코딩-병합 연산의 아티팩트를 줄이기 위해 다운샘플링된 이미지의 feature를 병합된 feature map에 추가로 concatenate한다. 이를 통해 입력을 임의의 해상도로 확장하고 LLaVA-1.5의 데이터 효율성을 유지할 수 있다. 이 모델을 LLaVA-1.5-HD라고 부른다.
Empirical Evaluation
1. Results
다음은 데이터, 모델, 해상도에 대한 스케일링 결과이다.
다음은 이미지를 $224^2$로 resize한 후 글로벌 컨텍스트로서 이미지 패치 feature에 concatenate시켰을 때의 결과이다.

2. Comparison with SOTA
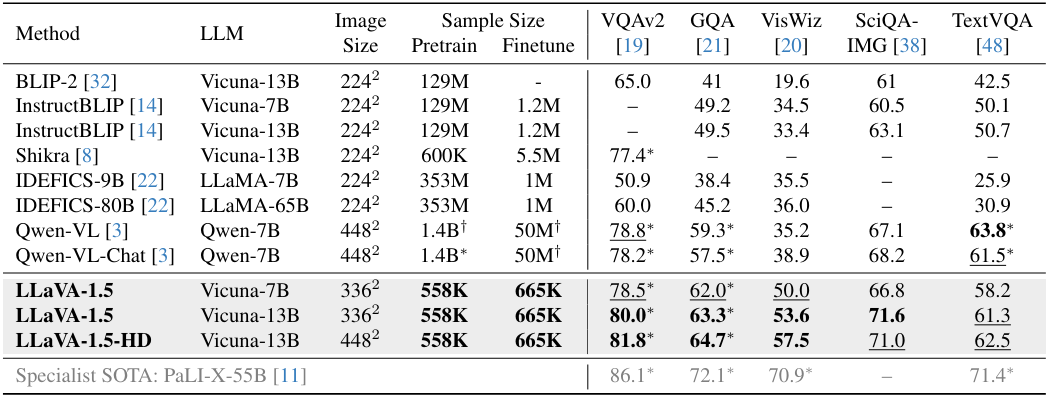
다음은 학문적 task 중심의 데이터셋에 대하여 SOTA 방법들과 비교한 결과이다.
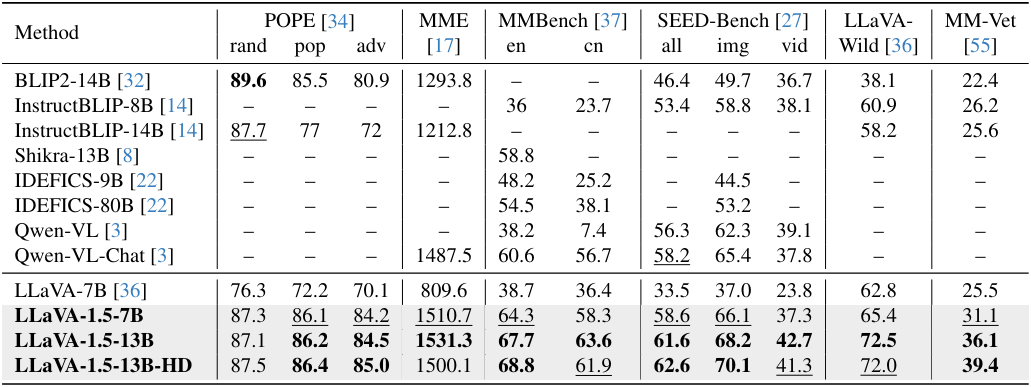
다음은 instruction-following LMM을 위한 벤치마크에서 SOTA 방법들과 비교한 결과이다.
3. Emerging Properties
LLaVA-1.5는 질문을 확인하라고 프롬프팅될 때 까다로운 질문을 감지하고 답변할 수 있다.

LLaVA-1.5는 이미지에서 정보를 추출하고 필요한 형식에 따라 응답할 수 있다.

4. Ablation
다음은 LLM 선택에 대한 ablation 결과이다.
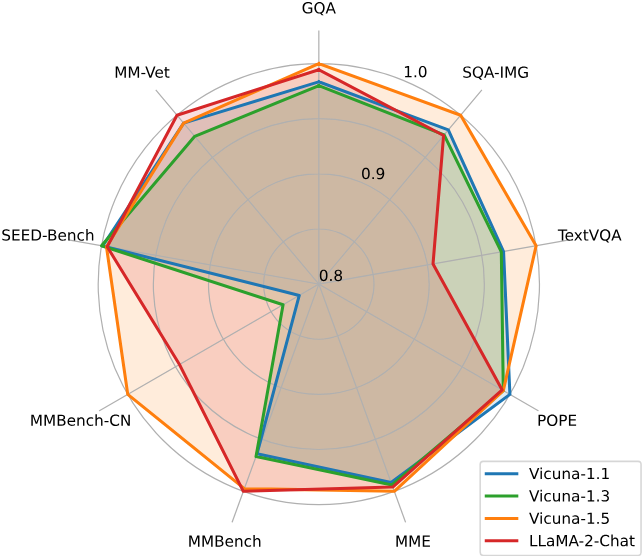
다음은 전체 데이터의 일부만을 사용하였을 때의 성능이다.