[논문리뷰] LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
CVPR 2025. [Paper] [Page] [Github]
Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, Mike Zheng Shou
National University of Singapore | ByteDance
22 Apr 2025

Introduction
본 논문에서는 자동 음성 인식 (ASR) 스크립트를 활용하여 video LLM 학습을 확장하는 것을 목표로 하며, ASR 단어와 해당 동영상 프레임을 밀접하게 인터리빙하는 새로운 스트리밍 학습 방식을 제안하였다. 이 모델은 autoregressive 방식으로 프레임에 할당된 ASR 단어를 생성하도록 학습된다. 기존 LMM은 완전한 문장이나 단락을 기반으로 학습하지만, 본 논문의 방식은 동영상 프레임과 시간적으로 정렬된 짧고 불완전한 ASR 단어 시퀀스를 학습한다. 이는 세 가지 주요 이점을 제공한다.
- 실제 데이터와 자연스럽게 정렬되어 YouTube와 같은 동영상 플랫폼에 쉽게 적용할 수 있다.
- 모델이 시각적 콘텐츠와 음성 언어 간의 세밀한 시간적 상관관계를 학습할 수 있도록 한다.
- Inference 과정에서 프레임당 몇 개의 단어만 생성하여 원활한 스트리밍을 가능하게 하여 매우 낮은 지연 시간을 보장한다.
동영상-ASR 데이터를 학습을 위해, ASR 품질을 향상시키고 시각적 텍스트 정렬을 개선하는 효율적인 데이터 수집 파이프라인을 설계하였다. 이 파이프라인을 통해 Live-CC-5M 사전 학습 데이터셋과 Live-WhisperX-526K SFT 데이터셋을 구축하였다. 다음으로, 동영상-ASR 스트리밍 시퀀스를 효율적으로 모델링하기 위해, 스트리밍 사전 학습 방식을 Qwen2-VL-7B-Base 기반 모델에 통합하여 LiveCC-7B-Base를 생성하고, 정확한 ASR 단어 예측에 영향을 미치는 주요 요인들을 분석하였다. 또한, 실시간 동영상 해설을 평가하기 위해 LLM-as-a-judge 프레임워크를 활용하는 새로운 벤치마크인 LiveSports-3K를 도입하였다.
Method
1. Video-ASR Data Curation
데이터 큐레이션 파이프라인은 아래 그림과 같다.
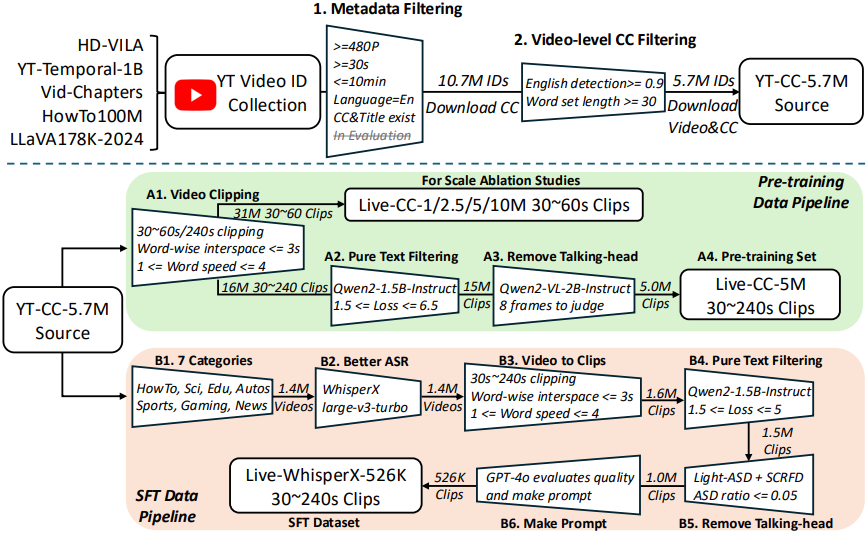
먼저 여러 YouTube 동영상 데이터셋을 통합하고 메타데이터 필터링을 거쳐 570만 개의 동영상으로 구성된 YT-CC-Source-5.7M을 생성한다. 사전 학습 데이터셋인 Live-CC-5M은 기존 YouTube 자막(CC)을 사용하여 구축하고, SFT 데이터셋인 Live-WhisperX-526K은 WhisperX에서 생성된 고품질 ASR을 활용한다.
Live-CC-5M
- A1) ASR 단어 타임스탬프 간격을 기준으로 동영상을 분할한다. 단어 간 간격이 3초를 초과하면 새 클립을 생성한다. 클립이 최대 길이 240초를 초과하면 새 클립으로 분할하고, 30초 미만이거나 초당 1~4단어를 벗어나는 속도를 가진 클립은 삭제한다. 단어 집합 크기에 따라 클립의 순위를 매기고, 100만, 250만, 500만, 1,000만 개의 클립으로 구성된 사전 학습 데이터셋을 생성한다.
- A2) 언어 모델을 사용하여 ASR 스크립트의 텍스트 loss를 계산하여 시각적 콘텐츠에 대한 의존성을 평가한다. Perplexity가 매우 낮으면 스크립트가 자체적으로 완전하며 시각적 기반을 필요로 하지 않은 반면, perplexity가 매우 높으면 ASR 품질이 낮다. Qwen2-1.5B-Instruct를 사용하며, loss 값이 1.5 ~ 6.5 사이인 샘플을 유지한다.
- A3) 각 동영상에 대해 균일하게 샘플링된 8개의 프레임에 Qwen-VL-2B-Instruct를 사용하여 talking-head 콘텐츠를 필터링한다. (신뢰도 0.3 미만만 유지)
Live-WhisperX-526K
- B1) 7개의 YouTube 카테고리만 유지한다.
- B2) WhisperX로 더 정확하고 단어 수준에 맞춰 정렬된 ASR 스크립트를 생성한다.
- B3) A1 단계와 동일하다. 사전 학습의 경우, 이전 ASR이 컨텍스트를 제공하므로 클립을 문장 중간에서 나눌 수 있다. 그러나 이전 ASR 컨텍스트를 사용할 수 없는 instruction tuning 단계에서는 각 클립이 문장의 시작 부분에서 시작하도록 한다. 마지막 ASR 단어는 마침표, 물음표 또는 느낌표여야 하며 현재 클립은 대문자로 시작해야 한다.
- B4) A2 단계와 동일하지만 텍스트 복잡도 범위는 1.5 ~ 5이다.
- B5) A3 단계와 같은 talking-head 필터링 단계이다. 능동 화자 감지(ASD)를 사용하여 talking-head 영상을 식별하고 제외한다. (Light-ASD 사용)
- B6) GPT-4o를 사용하여 각 샘플에 대한 사용자 프롬프트를 생성한다. 프롬프트는 특정 내용을 드러내지 않으면서 음성 스크립트의 스타일과 의도에 맞게 제작된다. 이 프롬프트를 사용하면 SFT 과정에서 이전 ASR을 사용할 필요가 없다.
2. Modeling
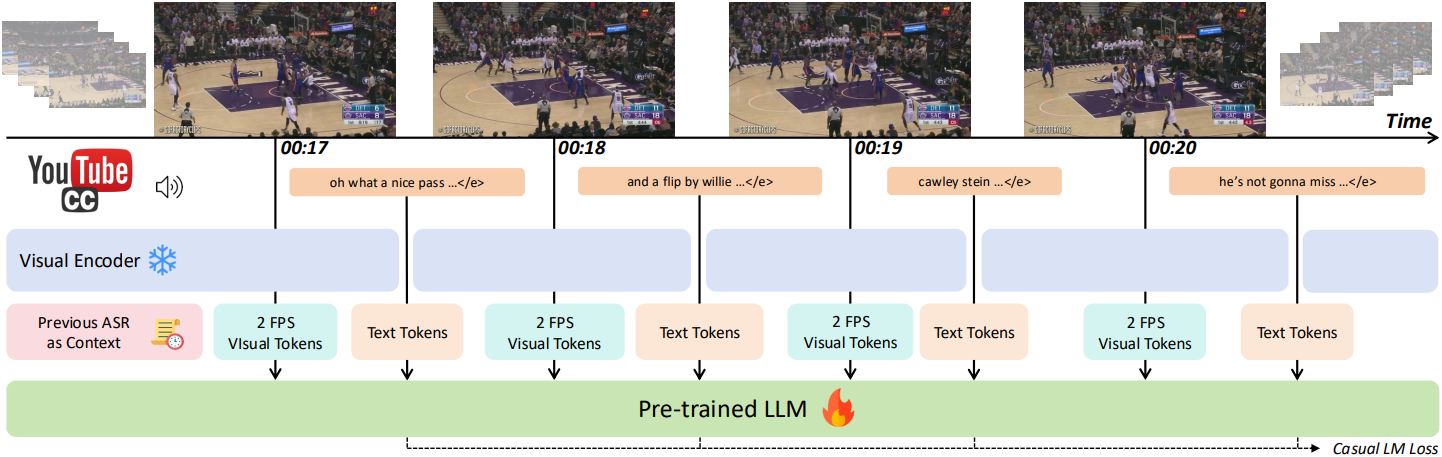
인터리빙 시퀀스를 사용한 학습
모델 아키텍처는 동적 해상도를 지원하고 Qwen2를 LLM backbone으로 사용하는 Qwen2-VL을 기반으로 한다. 저자들은 이미지-텍스트 데이터에 대해 광범위하게 사전 학습되었지만 동영상-텍스트 쌍에 대한 노출이 적은 Qwen2-VL-7B-Base를 사용하였다. 모델은 visual token을 입력으로 처리하면서 텍스트 토큰을 autoregressive하게 예측하도록 학습된다. 캡션 또는 이미지-텍스트 인터리빙 방식 입력을 사용하는 기존 방식과 달리, 본 모델에서는 시간 차원을 따라 ASR 단어와 동영상 프레임을 인터리빙하는 방식을 제안하였다. 학습 시퀀스는 다음과 같은 형식을 갖는다.
\[\begin{equation} [\textrm{Con}] \langle F_{t:t+k} \rangle \langle W_{t:t+k} \rangle \langle F_{t+k:t+2k} \rangle \langle W_{t+k:t+2k} \rangle \ldots \langle F_{t+nk:t+(n+1)k} \rangle \langle W_{t+nk:t+(n+1)k} \rangle \end{equation}\]($[\textrm{Con}]$는 동영상의 컨텍스트 정보 (ex. 프롬프트, 이전 ASR, 동영상 제목), $\langle F \rangle$는 프레임, $\langle W \rangle$는 단어, $t$는 시간 인덱스, $k$는 시간 간격)
기본적으로 2 FPS를 사용하고, 시간 간격은 $k = 1$이다. ASR 텍스트는 문장 중간에서 시작하거나 비공식적인 구어체를 사용할 수 있으므로, 텍스트의 일관성을 높이기 위해 동영상 제목과 이전 ASR 텍스트를 컨텍스트 정보로 통합한다. 이전 ASR 텍스트가 있는 경우, newline 문자로 동영상 제목과 이전 ASR 텍스트를 concat한다.
시퀀스 전처리
사전 학습의 경우, 고정 타임스탬프를 사용하여 음성을 약 2~3초 단위로 분할하는 원본 YouTube ASR 스크립트를 활용한다. 단어 수준 정렬을 근사하기 위해 각 세그먼트의 길이를 구성 단어에 균등하게 분배한다. 이러한 휴리스틱을 통해 전체 동영상에서 상당히 정확한 단어 수준 타임스탬프를 얻을 수 있다. SFT의 경우, 정확한 단어 수준의 타임스탬프를 제공하는 WhisperX를 활용한다.
스트리밍 중 일시적인 중단과 실제 시퀀스 종료(EOS)를 구분하기 위해, 프레임별 텍스트 토큰에 생략 부호 토큰(“…“)을 추가한다. 자막이 없는 무음 프레임의 경우, 이 생략 부호 토큰을 직접 예측한다.
학습 전략
모델 학습은 사전 학습과 SFT를 포함한 두 단계로 구성된다. 사전 학습에서는 인터리빙 시퀀스만을 사용하여 모델을 학습시킨다. 목표는 프레임 feature들을 시간적으로 동기화된 ASR 단어와 정렬하여 모델이 프레임과 언어 간의 시간적 상관관계를 포착할 수 있도록 하는 것이다. 다음으로, LiveCC 모델의 다양한 downstream task 수행 능력을 향상시키기 위해, 스트리밍 모드에서 Live-WhisperX-526K를 사용하여 모델을 학습시키고, 일반적인 캡션 또는 QA를 위한 일반 동영상 및 이미지 데이터셋을 사용한다. 이를 위해 스트리밍 학습을 Qwen2-VL 대화 템플릿과 호환되도록 구성한다.
Inference
Inference 과정에서 LiveCC 모델은 입력 프레임을 순차적으로 처리한다. 언어 디코딩 속도를 높이기 위해 이전 프롬프트, 시각적 프레임, 생성된 텍스트의 key-value (KV) 쌍을 캐싱한다. 긴 시퀀스의 경우, 240초마다 visual token을 삭제하고, 텍스트 토큰은 보관한다.
Experiments
1. Overall Results
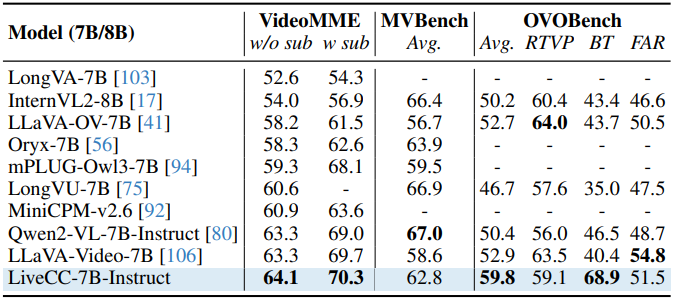
다음은 VideoMME, MVBench, OVOBench에 대한 QA 정확도를 비교한 결과이다.
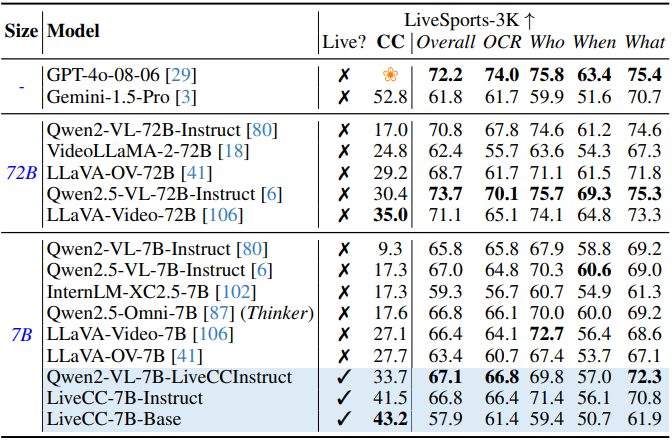
다음은 GPT-4o에 대한 승률과 QA 정확도를 LiveSports-3K 벤치마크에서 비교한 결과이다.
2. Ablation Study
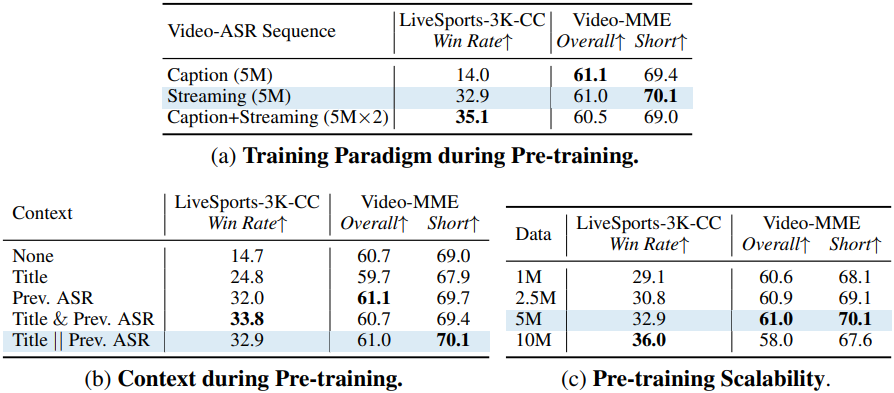
다음은 사전 학습 단계에 대한 ablation 결과이다.
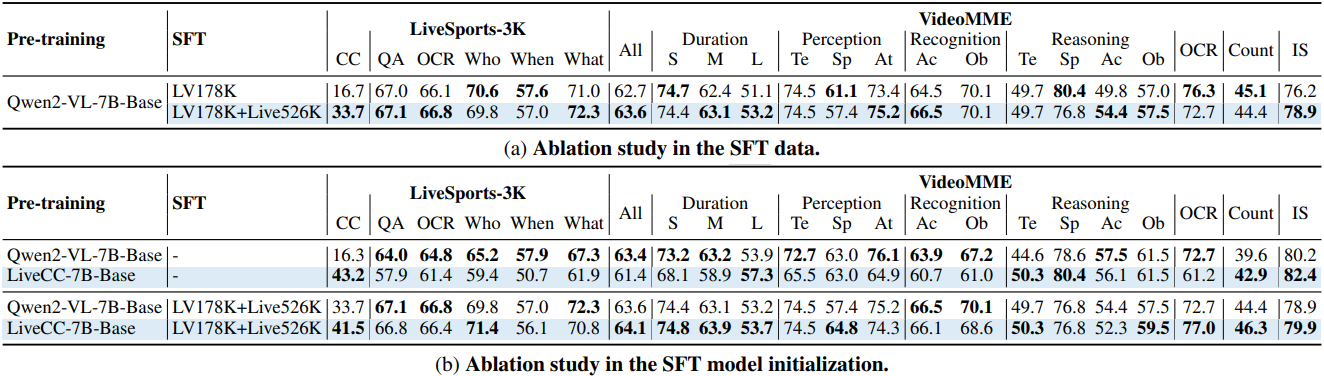
다음은 SFT 단계에 대한 ablation 결과이다.
3. Streaming Commentary Capabilities
다음은 동일한 동영상에 대한 사전 학습된 모델과 instruction tuning 모델의 예측을 비교한 예시이다.
