[논문리뷰] Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
SIGGRAPH Asia 2021. [Paper] [Page] [Github]
Yuanxun Lu, Jinxiang Chai, Xun Cao
Nanjing University | Xmov
22 Sep 2021

Introduction
Talking-head animation, 즉 target의 오디오와 싱크가 맞는 동영상 프레임을 합성하는 것은 인터랙티브한 애플리케이션에 유용하다. 최근 딥 러닝의 발전으로 이 오랜 문제에서 큰 진전을 이루었다. 그러나 사실적이고 표현력이 풍부한 말하는 애니메이션을 구현하는 것은 여전히 어려운 과제이다. 인간은 얼굴 인공물에 극도로 민감하여 원하는 기술에 대한 요구 사항이 높다.
몇 가지 요인이 talking-head animation 생성을 어렵게 만드는 데 기여한다.
- 1차원 오디오 신호에서 고차원 manifold에 놓인 얼굴 움직임으로 매핑하는 어려움과 더불어 오디오와 target 음성 space 간의 도메인 차이로 인해 각자의 말하는 특성을 보존하지 못해 실패하는 어려움이 있다.
- 머리와 몸의 움직임은 오디오와 밀접한 관련이 없다. 예를 들어, 같은 단어를 말할 때 머리를 흔들거나 가만히 있을 수 있는데, 이는 기분, 위치 또는 과거 포즈와 같은 많은 요인에 따라 달라진다.
- 제어 가능한 사실적 렌더링을 합성하는 것은 사소한 일이 아니다. 전통적인 렌더링 엔진은 여전히 원하는 것과 거리가 멀고 그 결과는 한 눈에 가짜로 인식될 수 있다. 뉴럴 렌더러는 사실적 렌더링에 큰 힘을 발휘하지만 예측된 움직임이 학습 코퍼스의 범위를 훨씬 벗어나면 성능 저하가 발생한다.
- 화상 회의나 디지털 아바타와 같은 많은 인터랙티브 시나리오에서는 전체 시스템이 실시간으로 실행되어야 하므로 성능을 손상시키지 않으면서 시스템 효율성이 많이 요구된다.
본 논문에서는 이러한 문제를 해결하고 실용적인 애플리케이션으로 한 걸음 더 나아가기 위해 Live Speech Portraits (LSP)라는 딥 러닝 아키텍처를 제안한다. 본 논문의 시스템은 오디오로 구동되는 얼굴 표정 및 동작 역학(머리 자세 및 상체 동작)을 포함하여 개인화된 talking-head animation 스트림을 생성하고 실시간으로 사실적인 렌더링을 한다.
우선, 저자들은 의미론적 또는 구조적 표현을 학습하는 데 큰 힘을 보여주고 다양한 다운스트림 작업에 도움이 되는 self-supervised 표현 학습의 아이디어를 채택하여 말하는 사람에 독립적인 오디오 feature를 추출한다. 오디오 스트림에서 사실적이고 개인화된 애니메이션을 만들기 위해 오디오 feature를 target feature space에 추가로 project하고 target feature를 사용하여 재구성한다. 이 프로세스는 source에서 target으로의 도메인 적응으로 볼 수 있다. 그 후, 재구성된 오디오 feature에서 얼굴 역학으로의 매핑을 학습할 수 있다.
사실적인 talking-head animation에 기여하는 또 다른 중요한 구성 요소는 머리와 몸의 움직임이다. 오디오에서 개인화되고 시간 일관성 있는 머리 포즈를 생성하기 위해 현재 머리 포즈가 일부는 오디오 정보와, 일부는 이전의 포즈와 관련이 있다고 가정한다. 저자들은 이 두 가지 조건을 기반으로 target의 머리 포즈 분포를 학습하기 위한 새로운 autoregressive 확률 모델을 제안한다. 추정된 분포에서 머리 포즈를 샘플링하고, 샘플링된 머리 포즈에서 상체 움직임을 추가로 inference한다.
사실적인 렌더링을 합성하기 위해 feature map과 후보 이미지를 조건으로 하는 image-to-image 변환 네트워크를 사용한다. 얼굴 역학에 샘플링된 머리 포즈를 적용하고 변환된 얼굴 키포인트와 상체 위치를 이미지 평면에 project하여 랜드마크 이미지를 중간 표현으로 생성한다. 본 논문의 시스템은 여러 모듈로 구성되어 있지만 30fps 이상에서 실시간으로 실행할 수 있을 만큼 충분히 작다.
Method
임의의 음성 스트림이 주어지면 Live Speech Portraits (LSP) 접근 방식은 target의 사실적인 talking-head animation을 실시간으로 생성한다. 본 논문의 접근 방식은 심층 음성 표현 추출, audio-to-face 예측, 사실적인 얼굴 렌더링의 세 단계로 구성된다.
첫 번째 단계는 입력 오디오의 음성 표현을 추출한다. 표현 extractor는 높은 수준의 음성 표현을 학습하고 레이블이 지정되지 않은 음성 코퍼스에서 self-supervised 방식으로 학습된다. 그런 다음 일반화를 개선하기 위해 target의 음성 space에 표현을 project한다. 두 번째 단계는 전체 모션 역학을 예측한다. 두 개의 정교하게 설계된 신경망은 각각 음성 표현에서 입 관련 동작과 머리 포즈를 예측한다. 입 관련 동작은 희박한 3D 랜드마크로 표현되고 머리 포즈는 고정된 회전 및 변환으로 표현된다. 머리 포즈는 입과 관련된 동작보다 오디오 정보와 관련이 적다는 점을 고려하여 확률적 autoregressive model을 사용하여 오디오 정보와 이전 포즈를 조건으로 하는 포즈를 학습한다. 오디오와 거의 상관관계가 없는 다른 얼굴 구성 요소(ex. 눈, 눈썹, 코 등)는 학습셋에서 샘플링된다. 그런 다음 예측된 머리 포즈에서 상체 움직임을 계산한다. 최종 단계에서는 조건부 image-to-image 변환 네트워크를 사용하여 이전 예측과 후보 이미지셋의 사실적인 동영상 프레임을 합성한다.
1. Deep Speech Representation Extraction
입력 정보인 음성 신호는 전체 시스템에 전원을 공급하기 때문에 중요한 역할을 한다. 일반적으로 self-supervised 메커니즘에서 학습되는 딥 러닝 접근 방식을 활용하여 surface feature에서 높은 수준의 말하는 사람에 독립적인 음성 표현을 학습했다.
특히 구조적 음성 표현을 추출하기 위해 autoregressive predictive coding (APC) 모델을 사용한다. APC 모델은 이전 정보가 주어질 때 미래 surface feature를 예측한다. 음성 surface feature로 80차원 log Mel spectrogram을 선택한다. 모델은 표준 3-layer 단방향 GRU(Gated Recurrent Unit)이다.
\[\begin{equation} h_l = \textrm{GRU}^{(l)} (h_{l-1}), \quad \forall l \in [1, L] \end{equation}\]여기서 $h_l \in \mathbb{R}^{512}$은 GRU의 각 layer의 hidden state이다. 마지막 GRU layer의 hidden state를 심층 음성 표현으로 사용한다. Linear layer를 더해 출력을 매핑하여 미래의 log Mel spectrogram을 학습 중에 예측하며, 학습이 끝나고 이 linear layer는 제거된다.
Manifold Projection
사람들은 개인화된 스타일로 간주되는 다양한 말하기 스타일을 소유한다. 심층 음성 표현을 직접 적용하면 입력 음성 표현이 대상의 음성 feature space에서 멀리 위치할 때 잘못된 결과가 발생할 수 있다. 일반화를 개선하기 위해 음성 표현을 추출한 후 manifold projection을 수행한다.
Manifold projection 연산은 사람의 얼굴에서 멀리 떨어진 스케치로 일반화할 수 있는 스케치에서 얼굴을 합성하는 최근 성공에 영감을 받았다. 음성 표현 manifold에 locally linear embedding (LLE) 가정을 적용한다. 각 데이터 포인트와 그 이웃은 고차원 manifold에서 LLE이다.
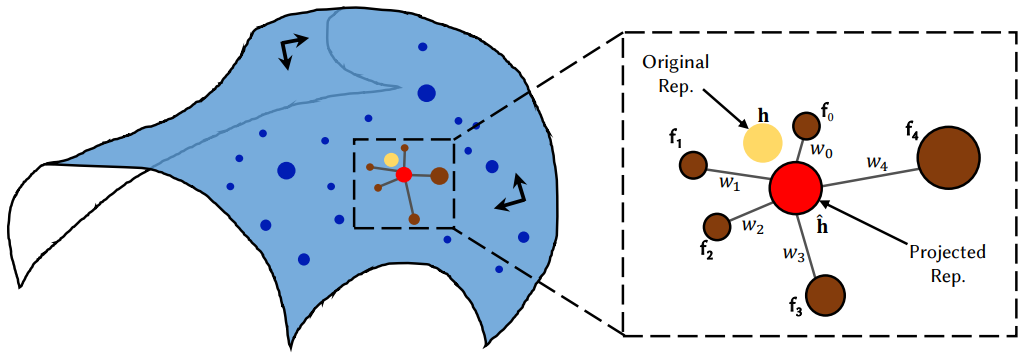
추출된 음성 표현 $h \in \mathbb{R}^{512}$가 주어지면 LLE 가정 하에 재구성된 표현 $\hat{h} \in \mathbb{R}^{512}$를 각 차원에 대하여 계산한다. 위 그림에서 묘사한 것과 같이, 먼저 target 음성 표현 데이터베이스 $\mathcal{D} \in \mathbb{R}^{N_s \times 512}$애서 $h$와 가까운 $K$개의 포인트를 유클리드 거리를 계산하여 찾는다. $N_s$는 학습 프레임의 개수이다. 그런 다음 $h$를 가장 잘 재구성하는 $K$개의 포인트의 선형 결합을 찾는다. 이는 다음 최소화 문제를 해결하여 neighbor를 기반으로 $h$의 중심 좌표를 계산하는 것과 같다.
여기서 $w_k$는 $k$-nearest neighbor $f_k$의 중심 가중치이며 최소 제곱 문제를 해결하여 계산할 수 있다. $K$는 실험에서 경험적으로 10으로 선택되었다. 마지막으로 project된 음성 표현 $\hat{h}$를 얻는다.
\[\begin{equation} \hat{h} = \sum_{k=1}^K w_k \cdot f_k \end{equation}\]이어서, $h$는 입력 심층 음성 표현으로 모션 predictor로 전송된다.
2. Audio to Mouth-related Motion
오디오에서 입과 관련된 움직임을 예측하는 것은 지난 몇 년 동안 광범위하게 연구되었다. 사람들은 딥 러닝 아키텍처를 사용하여 오디오 feature에서 입술 관련 랜드마크, parametric model의 파라미터, 3D 꼭지점 또는 얼굴 혼합 모양과 같은 중간 표현으로의 매핑을 학습한다. 본 논문의 경우 중간 표현으로 물체 좌표에서 target의 평균 위치에 대한 3D 변위 $\Delta v_m \in \mathbb{R}^{25 \times 3}$을 사용한다.
시퀀스 종속성을 모델링하기 위해 LSTM 모델을 사용하여 음성 표현에서 입 관련 동작으로의 매핑을 학습한다. $d$ 프레임 지연을 추가하여 짧은 미래에 모델에 액세스할 수 있도록 하여 품질을 크게 향상시킨다. 이후 LSTM 네트워크의 출력을 MLP에 공급하고 마지막으로 3D 변위 $\Delta v_m$을 예측한다. 요약하면 입 관련 예측 모듈은 다음과 같이 작동한다.
\[\begin{equation} m_0, m_1, \cdots, m_t = \textrm{LSTM} (\hat{h}_0, \hat{h}_1, \cdots, \hat{h}_{t+d}), \quad \Delta v_{m, t} = \textrm{MLP} (m_t) \end{equation}\]여기서 time delay $d$는 실험에서 300ms 지연(60FPS)과 같은 18프레임으로 설정된다. LSTM은 세 개의 layer로 쌓이고 각 layer는 크기가 256인 hidden state를 가진다. MLP 디코더 네트워크에는 hidden state 크기가 256, 512 및 75인 세 개의 layer가 있다.
3. Probabilistic Head and Upper Body Motion Synthesis
머리 포즈와 상체 움직임은 생생한 talking-head animation에 기여하는 또 다른 두 가지 구성 요소이다. 예를 들어 사람들은 말을 할 때 자연스럽게 머리를 흔들고 몸을 움직이며 감정을 표현하고 태도를 청중에게 전달한다.
오디오에서 머리 포즈 추정은 그들 사이에 거의 관계가 없기 때문에 중요하다. 오디오에서 머리 포즈로의 일대다 매핑의 본질적인 어려움을 고려하여 사전 지식으로 두 가지 가정을 한다.
- 머리 포즈는 부분적으로 표현 및 억양과 같은 오디오 정보와 관련이 있다. 예를 들어 사람들은 동의를 표현할 때 고개를 끄덕이고 높은 억양으로 말할 때 고개를 끄덕이는 경향이 있으며 그 반대의 경우도 마찬가지이다.
- 현재 머리 포즈는 과거 머리 포즈에 부분적으로 의한다. 예를 들어, 이전에 큰 각도로 돌린 적이 있다면 사람들이 고개를 돌릴 가능성이 크다.
이 두 가지 가정은 문제를 단순화하고 아키텍처 설계에 동기를 부여한다. 제안된 네트워크 $\phi$는 이전 헤드 포즈와 현재 오디오 정보를 조건으로 볼 수 있는 능력을 가져야 한다. 게다가 회귀 문제로 간주하고 유클리드 거리 loss를 사용하여 학습하는 대신 이 매핑을 확률 분포로 모델링해야 한다. 최근에는 확률 모델이 모션 합성에 성공적으로 사용되고 있으며 결정론적 모델을 능가한다. 머리 움직임의 결합 확률은 다음과 같이 나타낼 수 있다.
\[\begin{equation} p(x \vert \hat{h}) = \prod_{t=1}^T p(x_t \vert x_1, x_2, \cdots, x_{t-1}, \hat{h}_t) \end{equation}\]여기서 $x$는 머리 움직임이고 $\hat{h}$는 음성 표현이다.
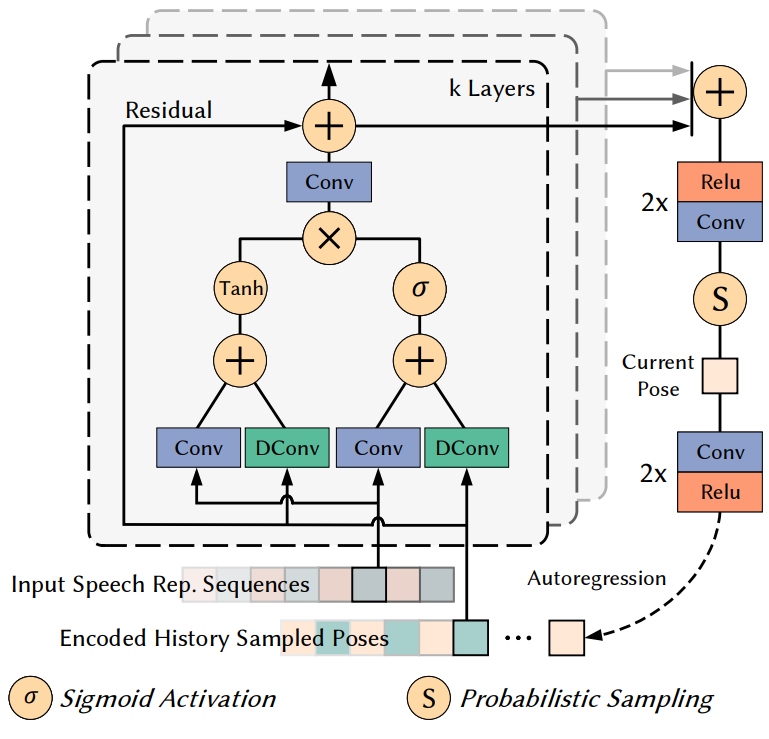
본 논문이 사용하는 확률 모델은 다차원 가우시안 분포이다. 네트워크 아키텍처는 조건부 확률 생성 모델링의 최근 성공에 영감을 받았다. 확률 모델의 세부 설계는 위 그림 4에 설명되어 있다.
모델은 각각 7개의 레이어가 있는 2개의 residual block의 스택이다. 자연스러운 머리 움직임을 생성하는 데 필요한 오랜 시간 종속성을 고려하면 (머리를 왼쪽에서 오른쪽으로 한 번 흔들면 몇 초 동안 지속될 수 있음) 이러한 residual block은 훨씬 적은 파라미터가 있는 일반 convolution 대신 dilation convolution layer를 사용하여 종속성을 캡처한다. Dilation은 아키텍처의 각 layer에 대해 7번 두 배로 증가한 다음 두 번 반복된다: 1, 2, 4, 8, 16, 32, 64, 1, 2, 4, 8, 16, 32, 64. 결과적으로 모델의 이전 헤드 포즈에 대한 receptive field 크기 $F$는 255프레임으로, 실험에서 4.25초에 해당한다. 각 레이어의 출력은 현재 분포를 생성하기 위해 후처리 네트워크(2개의 relu-conv layer의 스택)에 의해 합산되고 처리된다.
특히 모델은 추정된 가우시안의 평균값 $\mu$와 표준편차 $\sigma$를 출력한다. 그런 다음 분포에서 샘플링하여 3D rotation $R \in \mathbb{R}^3$과 transition $T \in \mathbb{R}^3$으로 구성된 최종 머리 포즈 $P \in \mathbb{R}^6$을 얻는다. 저자들은 또한 가우시안 혼합 모델로 시도했지만 뚜렷한 개선점을 찾지 못했다. 샘플링 후 현재 포즈를 다음 timstep에 대한 입력 포즈 정보로 인코딩하여 autoregressive 메커니즘을 형성한다. 요약하면 머리 포즈 추정은 다음과 같이 나타낼 수 있다.
\[\begin{equation} P_{para, t} = \phi (P_{t-F}, \cdots, P_{t-1}, \hat{h}_t) \\ P_t = \textrm{Sample} (P_{para, t}) \end{equation}\]Upper Body Motion
상체 움직임 추정을 위한 이상적인 방법은 신체 모델을 구축하고 파라미터를 추정하는 것이다. 알고리즘이 너무 복잡해지는 것을 방지하기 위해 상체 부분을 수동으로 정의한 여러 어깨 랜드마크로 모양이 지정된 billboard로 할당한다. Billboard의 초기 깊이는 전체 학습 시퀀스에서 랜드마크의 평균 깊이로 설정되며 모두 동일하다. 대부분의 경우 예측된 머리 움직임 $P$에서 transition 부분 $T$의 50%를 가진 billboard 모델을 결과로 사용한다.
4. Photorealistic Image Synthesis
마지막 단계는 이전 예측에서 사실적인 얼굴 렌더링을 생성하는 것이다. 렌더링 네트워크는 사실적이고 제어 가능한 얼굴 동영상 합성의 최근 발전에 영감을 받았다. 적대적 학습과 함께 조건부 image-to-image 변환 네트워크를 backbone으로 사용한다. 네트워크는 조건부 feature map과 target의 후보 이미지 $N = 4$개를 channel-wise concat하여 사실적인 렌더링을 생성한다.
Conditional Feature Maps

얼굴과 상체의 단서를 제공하기 위해 위의 예측에서 각 프레임에 대한 조건부 feature map을 그린다. 조건부 map의 예시는 위 그림에 나와 있다. Feature map은 얼굴 부분과 상체 부분으로 구성된다. 색상으로 semantic 영역 또는 더 나아가 하나의 영역을 그리면, 하나의 채널이 더 풍부한 정보와 더 많은 그리기 시간을 가져간다. 저자들은 이 두 가지 대안에서 뚜렷한 개선점을 찾지 못했다. 희박한 얼굴 랜드마크와 예상하는 상체 billboard는 객체 좌표에서 찾을 수 있다. 따라서 미리 계산된 카메라 고유 파라미터 $K$를 통해 이러한 3D 위치를 2D 이미지 평면에 project해야 한다. 사용하는 카메라 모델은 핀홀 카메라 모델이며
이다. 여기서 $f$는 초점 거리이고 $f(c_x, c_y)$는 principle point이다. 연속적인 2D projection 구성 요소는 미리 정의된 semantic 순서로 선 연결되어 크기 $1 \times 512 \times 512$의 조건부 feature map이 생성된다.
Candidate Image set
조건부 feature map 외에도 target 인물의 후보 이미지셋을 추가로 입력하여 자세한 장면 및 텍스처 단서를 제공한다. 저자들은 이러한 후보 셋을 추가하면 학습 셋에서 변화하는 카메라 움직임을 고려하여 네트워크가 일관된 배경을 생성하는 데 도움이 되고 치아 및 모공과 같은 미묘한 디테일을 합성하기 위한 네트워크의 압력을 완화한다는 것을 발견했다.
이러한 이미지는 자동으로 선택된다. 처음 두 개에 대해 100번째 최소/최대 입 영역을 선택한다. 나머지는 일정한 간격으로 x축 및 y축 회전을 샘플링하고 간격에서 가장 가까운 샘플을 선택한다. 따라서 최종 concat된 입력 이미지의 크기는 $13(1+3 \times 4) \times 512 \times 512$가 된다.
네트워크는 각 해상도 layer에 skip connection이 있는 8-layer UNet-like CNN이다. 각 layer의 해상도는 ($256^2$, $128^2$, $64^2$, $32^2$, $16^2$, $8^2$, $4^2$, $2^2$)이며 각각 채널의 수는 (64, 128, 256, 512, 512, 512, 512, 512)이다. 각 인코더 layer는 하나의 컨벌루션(stride 2)과 하나의 residual block으로 구성된다. 대칭되는 디코더 레이어는 첫 번째 convolution이 scale factor가 2인 nearest upsampling 연산으로 대체된다는 점을 제외하면 거의 동일하다.
Implementation Details
1. Dataset Acquisition and Pre-processing
학습 및 테스트를 위해 7가지 주제의 8가지 target 시퀀스에 본 논문의 접근 방식을 적용한다. 이러한 시퀀스는 3-5분 범위에 걸쳐 있다. 모든 동영상은 60FPS로 추출되고 동기화된 오디오 웨이브는 16Khz 주파수에서 샘플링된다.
먼저 얼굴을 중앙에 유지하도록 동영상을 자른 다음 512 $\times$ 512로 크기를 조정한다. 모든 입력 이미지와 출력 이미지는 동일한 해상도를 공유한다. 학습 및 evaluation을 위해 비디오를 80% / 20%로 나눈다.
상용 툴을 사용하여 모든 비디오에 대해 73개의 미리 정의된 얼굴 랜드마크를 감지한다. 3D 입 모양과 머리 자세의 ground-truth를 제공하기 위해 최적화 기반 3D 얼굴 추적 알고리즘을 사용한다. 카메라 보정의 경우 이진 탐색을 사용하여 초점 거리 $f$를 계산한다. 원점 (c_x, c_y)를 이미지의 중심으로 설정한다. 원본 이미지에서 카메라 보정 및 3D 얼굴 추적을 수행하고 자르기 및 크기 조정 파라미터에 따라 변환 행렬을 계산한다. 상체 움직임의 feature 포인트는 각 시퀀스의 첫 번째 프레임에 대해 한 번 수동으로 선택되고 LK optical flow와 및 OpenCV 구현을 사용하여 나머지 프레임에 대해 추적된다.
APC 음성 표현 extractor를 학습시키기 위해 레이블이 지정되지 않은 발화를 제공하는 Common Voice 데이터셋의 중국어 부분을 사용한다. 특히, 하위 집합에는 다양한 악센트가 있는 889개의 서로 다른 화자가 포함되어 있다. 총 약 26시간의 레이블이 지정되지 않은 발화가 있다.
surface feature로 80차원 log Mel spectrogram을 사용한다. Log Mel spectrogram은 1/60초 프레임 길이, 1/120초 프레임 이동, 512포인트 STFT(Short-Time Fourier Transform)로 계산된다. APC 모델은 표준 중국어로 학습하였지만 모델이 높은 수준의 semantic 정보를 학습하기 때문에 시스템이 다른 언어에서도 여전히 잘 작동한다. 또한 manifold projection은 일반화 능력을 향상시킨다.
2. Loss Functions
Deep Speech Representation Extraction
APC 모델의 학습은 $n$ 프레임 앞의 surface feature 예측을 통해 완전히 self-supervise된다. 일련의 log Mel spectrogram $(x_1, x_2, \cdots, x_T)$가 주어지면 APC 모델은 timestep $t$에서 각 요소 $x_t$를 처리하고 예측 $y_t$를 출력하여 예측 시퀀스 $(y_1, y_2, \cdots, y_T)$를 생성한다. 다음과 같이 입력 시퀀스와 예측 사이의 L1 loss를 최소화하여 모델을 최적화한다.
\[\begin{equation} \sum_{i=1}^{T-n} | x_{i+n} - y_i | \end{equation}\]여기서 $n = 3$으로 설정한다.
Audio to Mouth-related Motion
오디오에서 입 관련 동작으로의 매핑을 학습하기 위해 실제 입 변위와 예측 변위 사이의 $L_2$ 거리를 최소화한다. 특히 loss는 다음과 같이 쓸 수 있다.
\[\begin{equation} \sum_{t=1}^T \sum_{i=1}^N \| \Delta v_{m,t} - \Delta \hat{v}_{m,t} \|_2^2 \end{equation}\]여기서 $T = 240$은 각 iteration에서 모델로 전송되는 연속 프레임 수를 나타낸다. $N = 25$는 실험에서 미리 정의된 입 관련 3D 포인트의 수이다.
Probabilistic Head Motion Synthesis
오디오에서 입 관련 동작으로의 매핑을 학습하는 것 외에도 학습 중에 target의 머리 포즈를 추정하는 것을 목표로 한다. 상체 움직임은 머리 포즈에서 추론할 수 있다. 특히 머리 포즈 분포를 모델링하기 위해 autoregressive model을 사용한다. 포즈 분포의 음의 로그 우도를 최소화하여 모델을 학습시킨다. 이전 머리 포즈 $(x_{t-F}, \cdots, x_t)$와 음성 표현 $h_t$의 시퀀스가 주어지면 확률적 loss는 다음과 같다.
\[\begin{equation} -\log (\mathcal{N} (x_t, h_t \vert \hat{\mu}_n, \hat{\sigma}_n)) \end{equation}\]이 loss 항은 모델이 가우시안 분포의 평균값 $\hat{\mu}_n$와 $\hat{\sigma}_n$를 출력하도록 강제한다. 수치 안정성을 높이기 위해 $\hat{\sigma}_n$ 대신 $-\log (\hat{\sigma}_n)$를 출력한다. 포즈 시퀀스의 각 요소 $x_t \in \mathbb{R}^12$는 현재 포즈 $p_t \in \mathbb{R}^6$과 선형 속도 항 $\Delta p_t \in \mathbb{R}^6$로 구성된다. 분포에서 샘플링한 후 처음 6개 차원의 rotation과 transition만 사용하지만 이러한 속도 항을 추가하면 암시적으로 모델이 모션 속도에 집중하여 더 부드러운 결과를 얻을 수 있다.
Photorealistic Image Synthesis
마지막으로 neural renderer를 학습시켜 사실적인 말하는 사람 이미지를 합성한다. 학습 절차는 적대적 학습 메커니즘을 따른다. Multi-scale PatchGAN 아키텍처를 discriminator $D$의 backbone으로 채택한다. Image-to-image 변환 네트워크 $G$는 Discriminator $D$를 속이기 위해 사실적인 이미지를 생성하도록 학습되는 반면, discriminator $D$는 생성된 이미지라고 말하도록 학습된다. 특히 LSGAN loss를 adversarial loss로 사용하여 discriminator $D$를 최적화한다.
\[\begin{equation} \mathcal{L}_{GAN} (D) = (\hat{r} - 1)^2 + r^2 \end{equation}\]여기서 $\hat{r}$과 $r$은 각각 ground-truth 이미지 $\hat{y}$와 생성된 렌더링 $y$를 입력하였을 때의 discriminator의 classification 출력이다. 저자들은 추가로 color loss \(\mathcal{L}_C\), perceptual loss \(\mathcal{L}_P\), feature matching loss \(\mathcal{L}_{FM}\)를 사용하였다.
\[\begin{equation} \mathcal{L}_G = \mathcal{L}_{GAN} + \lambda_C \mathcal{L}_C + \lambda_P \mathcal{L}_P + \lambda_{FM} \mathcal{L}_{FM} \\ \mathcal{L}_{GAN} = (r - 1)^2 \end{equation}\]가중치 $\lambda_C$, $\lambda_P$, $\lambda_{FM}$은 각각 100, 10, 1로 설정하였다. Color loss는 생성된 이미지 $y$와 ground-truth 이미지 $\hat{y}$의 $L_1$ per-pixel loss이다.
\[\begin{equation} \mathcal{L}_C = \| y - \hat{y} \|_1 \end{equation}\]입에 대하여 가중치를 10배 더 크게 적용하면 입과 관련된 오차는 감소하지만 전체 이미지의 오차가 커진다고 한다.
Perceptual loss의 경우 VGG19 network를 사용하여 $\hat{y}$와 $y$에서 perceptual feature를 추출하고 feature 사이의 $L_1$ 거리를 최소화한다.
\[\begin{equation} \mathcal{L}_P = \sum_{i \in S} \| \phi^{(i)} (y) - \phi^{(i)} (\hat{y}) \|_1 \end{equation}\]여기서 \(S = \{1, 6, 11, 20, 29\}\)는 사용한 layer를 나타낸다.
마지막으로 학습 속도와 안정성을 개선하기 위하여 feature matching loss를 사용한다.
\[\begin{equation} \mathcal{L}_{FM} = \sum_{i=1}^L \|r - \hat{r} \|_1 \end{equation}\]여기서 $L$은 discriminator $D$의 공간적 layer의 수이다.
3. Training Setup and Parameters
- Adam optimizer ($\beta_1 = 0.9$, $\beta_2 = 0.999$)
- Learning rate = $10^{-4}$, 선형적으로 $10^{-5}$로 감소
- Nvidia 1080Ti GPU 사용
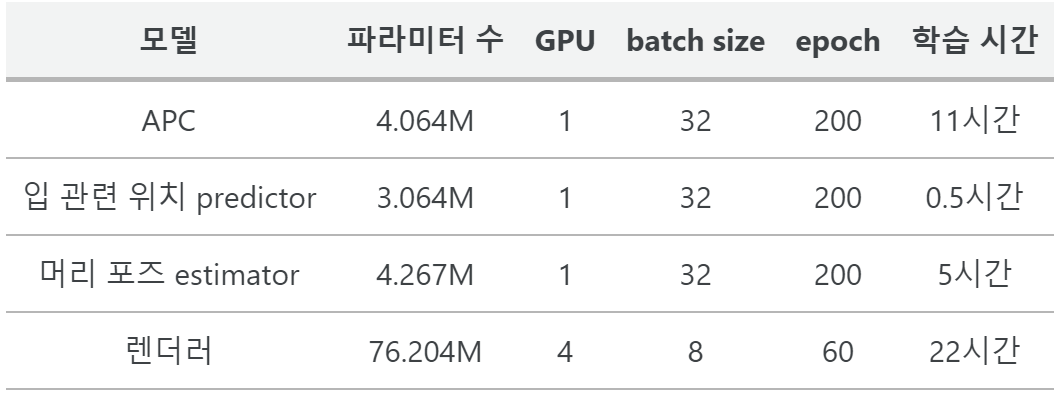
4. Real-Time Animation
Intel Core i7-9700K CPU (32GB RAM), NVIDIA GeForce RTX 2080 (8GB RAM)에서 30FPS 이상에 대하여 inference하는 데 총 27.4ms가 소요된다.
Results
1. Qualitative Evaluation
다음은 오디오 기반 talking-head animation의 결과를 나타낸 것이다.

다음은 본 논문의 방법의 포즈 제어 가능성을 보여준다.

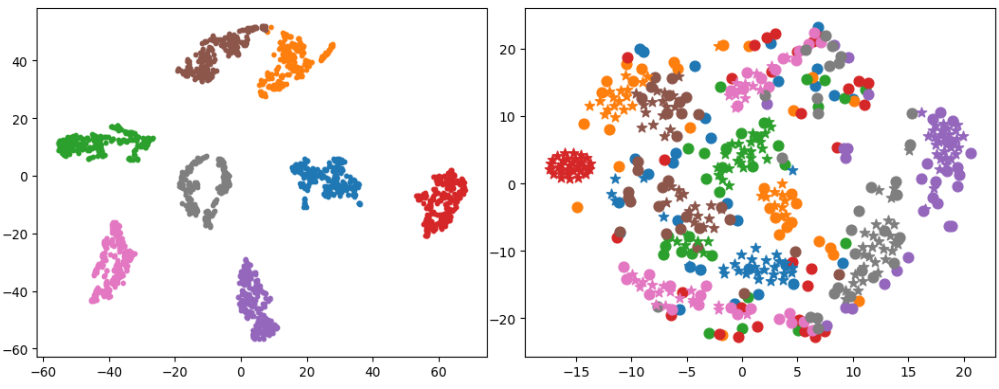
다음은 manifold projection에 대한 t-SNE 시각화이다.

다음은 머리 포즈 생성에 대한 t-SNE 시각화이다. 왼쪽은 생성된 포즈를 시각화 한 것이고, 오른쪽은 생성된 포즈(★)와 학습 코퍼스의 머리 포즈(●)를 시각화 한 것이다.
다음은 추정된 머리 포즈를 정성적으로 비교한 것이다.

2. Quantitative Evaluation
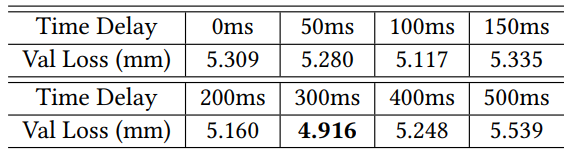
다음은 time delay $d$에 따른 랜드마크 사이의 유클리드 거리를 측정한 것이다.
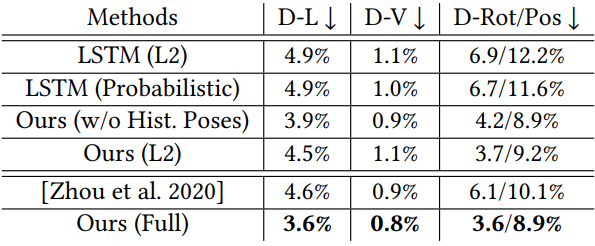
다음은 머리 포즈 예측에 대한 정량적 평가 결과이다.
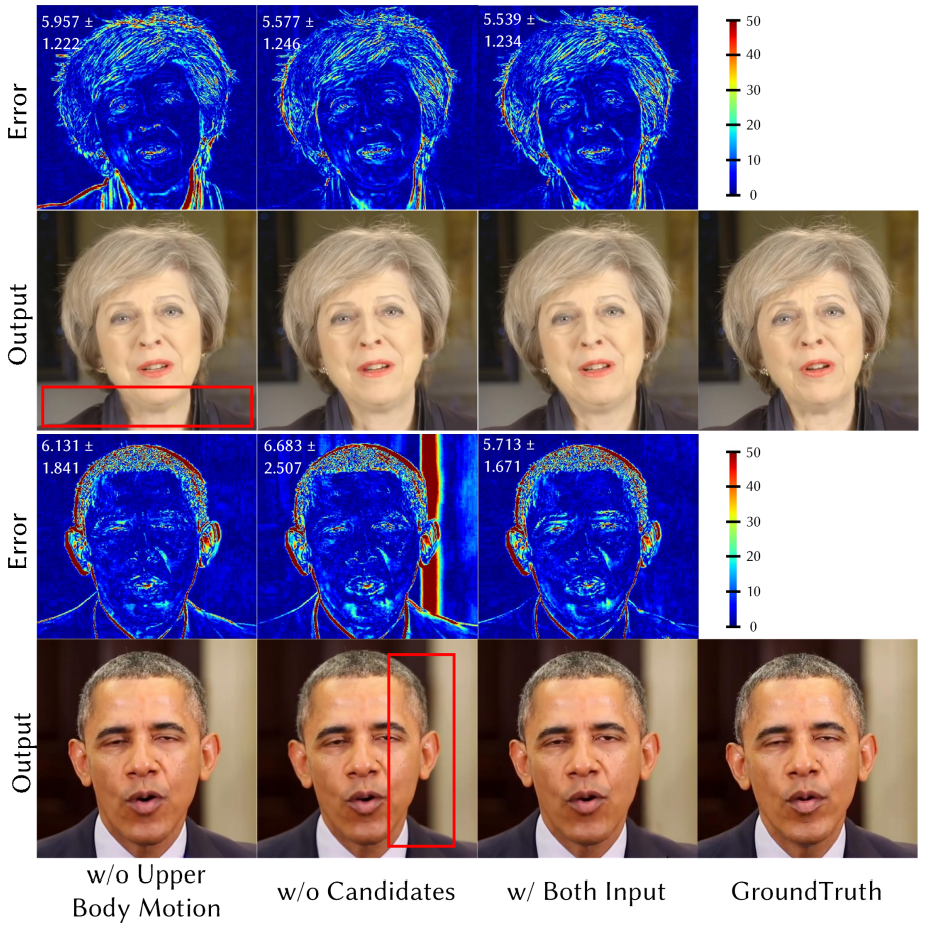
다음은 렌더러의 조건부 입력에 대한 정성적 평가 결과이다.
다음은 렌더러의 아키텍처 디자인에 대한 정성적 평가 결과이다.
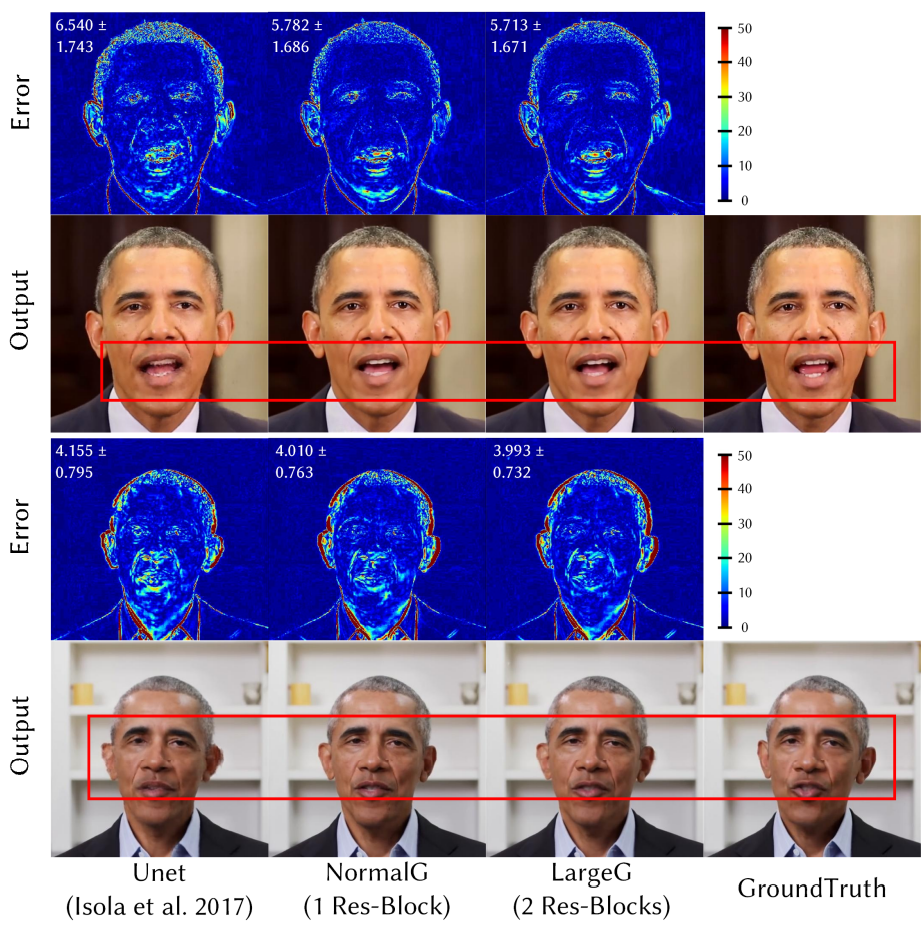
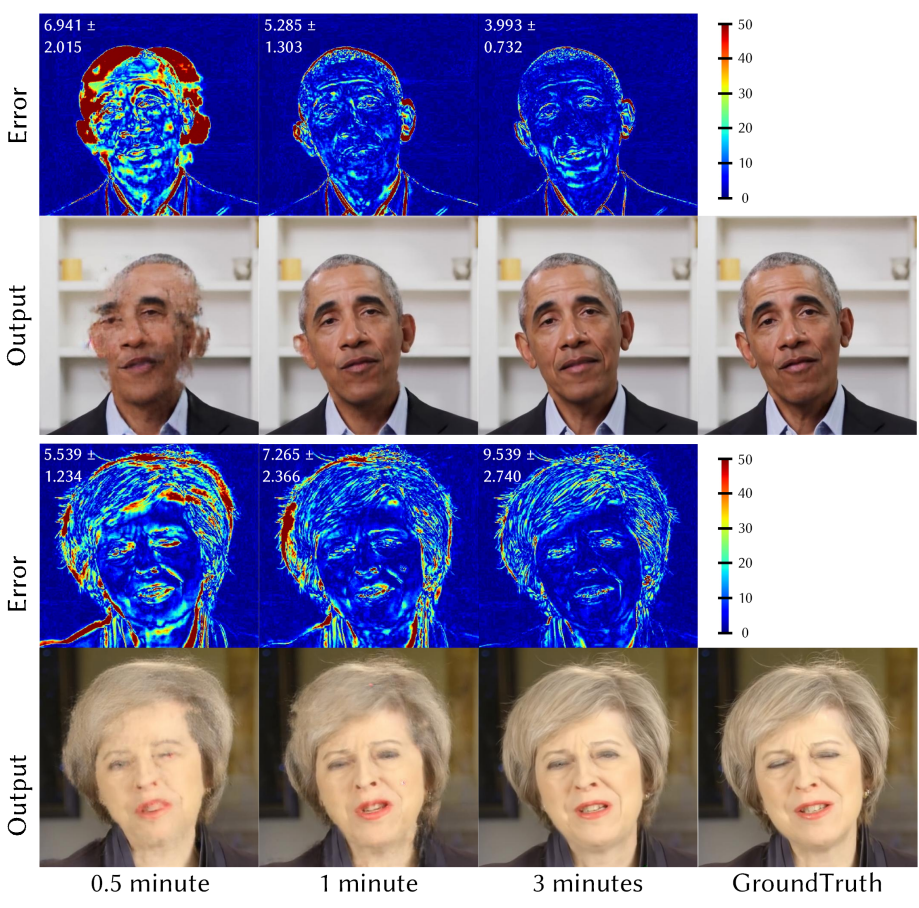
다음은 학습 데이터셋 크기에 대한 정성적 평가 결과이다.
다음은 조건부 입력 (상단), 아키텍처 (중간), 학습 데이터셋 크기 (하단)에 대한 정량적 평가 결과이다.

3. Comparisons to the State-of-the-Art
다음은 state-of-the-art 이미지 기반 생성 방법과 비교한 것이다.

4. User Study
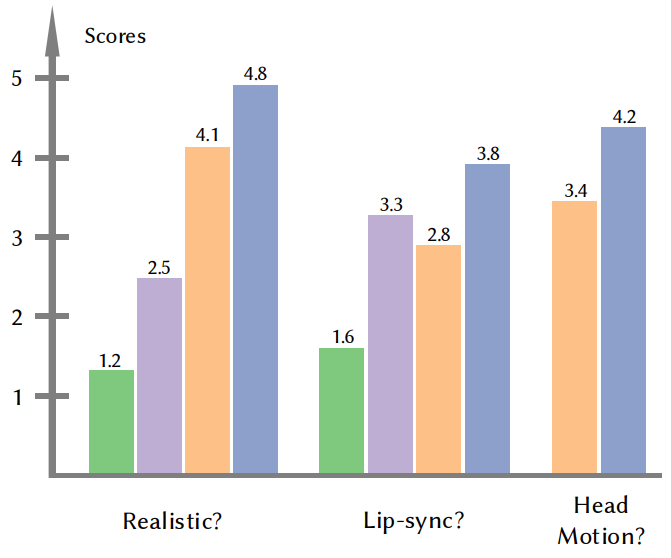
다음은 3개의 user study 결과이다.