[논문리뷰] LISA: Reasoning Segmentation via Large Language Model
CVPR 2024. [Paper] [Github]
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
CUHK | HIT | SmartMore | MSRA
1 Aug 2023

Introduction
본 논문에서는 복잡한 추론과 관련된 함축적인 쿼리 텍스트를 기반으로 바이너리 segmentation mask를 생성해야 하는 새로운 segmentation task인 reasoning segmentation을 도입하였다. 특히, 쿼리 텍스트는 간단한 참조에 국한되지 않고 복잡한 추론이나 세상에 대한 지식을 포함하는 보다 복잡한 설명도 포함한다. 이 task를 수행하려면 모델은 두 가지 핵심 능력을 보유해야 한다. 이미지와 함께 복잡하고 함축적인 텍스트 쿼리를 추론해야 하며, segmentation mask를 생성해야 한다.
사용자 의도를 추론하고 이해하는 LLM의 탁월한 역량에 영감을 받아 LLM의 이러한 능력을 활용하여 앞서 언급한 첫 번째 문제를 해결하는 것을 목표로 한다. 여러 연구들에서 시각적 입력을 수용하기 위해 강력한 추론 능력을 Large Multimodal Model (LMM)에 통합했다. 하지만 이러한 모델의 대부분은 주로 텍스트 생성 task에 집중하고 segmentation mask와 같은 세분화된 출력 형식이 필요한 비전 task를 수행하는 데 여전히 부족하다.
본 논문은 segmentation mask를 생성할 수 있는 LMM인 LISA를 소개한다. 구체적으로, 기존 vocabulary에 추가 토큰, 즉 <SEG>를 통합한다. <SEG> 토큰을 생성하면 해당 토큰의 hidden embedding이 해당 segmentation mask로 추가로 디코딩된다. Segmentation mask를 임베딩으로 표현함으로써 LISA는 segmentation 능력을 획득하고 end-to-end 학습의 이점을 얻는다.
놀랍게도 LISA는 강력한 zero-shot 능력을 보여준다. 일반 semantic segmentation 및 referring segmentation 데이터셋만을 사용하여 모델을 학습하면 reasoning segmentation task에서 놀랍도록 효과적인 성능을 얻을 수 있다. 또한 239개의 reasoning segmentation 데이터 샘플에 대한 fine-tuning을 통해 LISA의 성능이 크게 향상시킬 수 있다.
또한 저자들은 효율성을 검증하기 위해 ReasonSeg라는 reasoning segmentation 평가를 위한 벤치마크를 만들었다. 1000개 이상의 이미지-명령 쌍으로 구성된 이 벤치마크는 task에 대한 설득력 있는 평가 지표를 제공한다. 실제 응용과 더욱 밀접하게 일치시키기 위해 OpenImages와 ScanNetv2의 이미지에 복잡한 추론이 포함된 함축적인 텍스트 쿼리로 주석을 달았다.
Reasoning Segmentation
1. Problem Definition
Reasoning segmentation task는 입력 이미지 \(\textbf{x}_\textrm{img}\)와 함축적인 쿼리 텍스트 명령 \(\textbf{x}_\textrm{txt}\)가 주어지면 binary segmentation mask $\textbf{M}$을 출력하는 것이다. 이 task는 referring segmentation와 유사하지만 훨씬 더 어렵다. 주요 차이점은 쿼리 텍스트의 복잡성에 있다. 쿼리 텍스트에는 간단한 문구 대신 더 복잡한 표현이나 더 긴 문장이 포함된다. 이러한 쿼리 텍스트에는 복잡한 추론과 세상에 대한 지식을 포함하고 있다.
2. Benchmark

정량적 평가가 부족하기 때문에 reasoning segmentation에 대한 벤치마크를 설정하는 것이 필수적이다. 신뢰할 수 있는 평가를 보장하기 위해 저자들은 OpenImages와 ScanNetv2에서 다양한 이미지들을 수집하여 함축적인 텍스트 명령과 고품질 마스크로 주석을 달았다. 다양한 시나리오를 다루기 위해 텍스트 명령은 두 가지 유형으로 구성된다.
- 짧은 문구
- 긴 문장
ReasonSeg 벤치마크는 총 1218개의 이미지-명령-마스크 데이터 샘플로 구성된다. 이 데이터셋은 각각 239, 200, 779개의 데이터 샘플을 포함하는 train, val, test의 세 가지 split으로 분할된다. 벤치마크의 주요 목적은 평가이므로 validation set과 test set에는 더 많은 수의 데이터 샘플이 포함된다.
Method
1. Architecture
Embedding as Mask
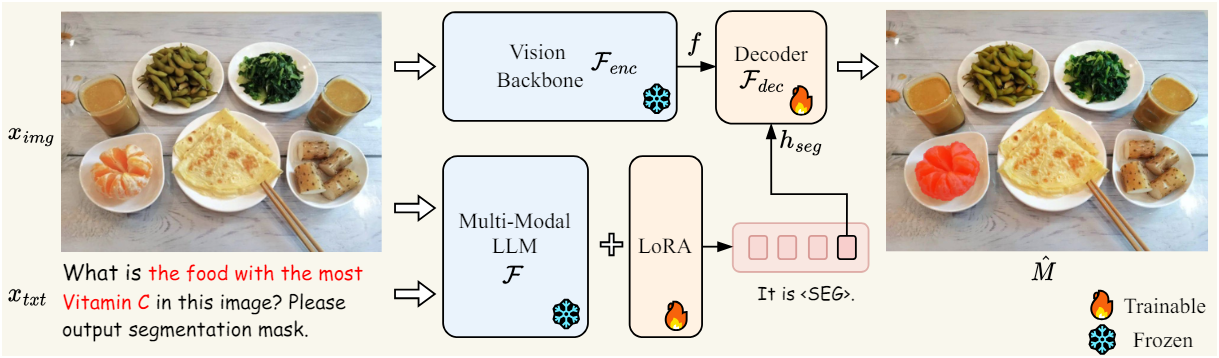
대부분의 최신 LMM (ex. LLaVA, Flamingo, BLIP-2, Otter)은 이미지와 텍스트를 입력으로 지원하지만 텍스트만 출력할 수 있고 세분화된 segmentation mask를 직접 출력할 수는 없다. VisionLLM은 segmentation mask를 다각형 시퀀스로 파싱하여 segmentation mask를 일반 텍스트로 표현하고 기존 LMM 프레임워크 내에서 end-to-end 학습을 가능하게 하는 솔루션을 제공하였다.
그러나 다각형 시퀀스를 사용한 end-to-end 학습은 최적화 문제를 야기하고 엄청난 양의 데이터와 계산 리소스를 사용하지 않는 한 일반화 능력이 저하될 수 있다. 예를 들어, 7B 모델을 학습시키려면 VisionLLM에는 NVIDIA 80G A100 GPU 32개로 50 epochs의 학습이 필요하며 이는 불가능하다. 이와 대조적으로 LISA-7B를 학습시키는 데에는 NVIDIA 24G 3090 GPU 8개에서 3일도 채 걸리지 않는다.
저자들은 LMM에 새로운 segmentation 능력을 주입하기 위해 embedding-as-mask 패러다임을 제안하였다. 먼저 segmentation 출력에 대한 요청을 나타내는 새로운 토큰, 즉 <SEG>를 사용하여 원래 LLM의 vocabulary를 확장한다. 입력 이미지 \(\textbf{x}_\textrm{img}\)와 함께 텍스트 명령 \(\textbf{x}_\textrm{txt}\)가 주어지면 이를 LMM $\mathcal{F}$에 공급하고, 이는 차례로 텍스트 응답 \(\hat{\textbf{y}}_\textrm{txt}\)를 출력한다.
\[\begin{equation} \hat{y}_\textrm{txt} = \mathcal{F} (\textbf{x}_\textrm{img}, \textbf{x}_\textrm{txt}) \end{equation}\]LLM이 binary segmentation mask를 생성하려는 경우 \(\hat{\textbf{y}}_\textrm{txt}\)에 <SEG> 토큰이 포함된다. 그런 다음 <SEG> 토큰에 해당하는 LLM의 마지막 레이어 임베딩 \(\tilde{\textbf{h}}_\textrm{seg}\)를 추출하고 MLP projection layer $\gamma$를 적용하여 \(\textbf{h}_\textrm{seg}\)를 얻는다. 동시에 비전 백본 \(\mathcal{F}_\textrm{enc}\)는 \(\textbf{x}_\textrm{img}\)에서 dense한 visual feature $\textbf{f}$를 추출한다. 마지막으로 \(\textbf{h}_\textrm{seg}\)와 $\textbf{f}$는 디코더 \(\mathcal{F}_\textrm{dec}\)에 공급되어 최종 segmentation mask \(\hat{\textbf{M}}\)을 생성한다. 디코더 \(\mathcal{F}_\textrm{dec}\)의 상세한 구조는 SAM을 따른다.
\[\begin{equation} \textbf{h}_\textrm{seg} = \gamma (\tilde{\textbf{h}}_\textrm{seg}), \quad \textbf{f} = \mathcal{F}_\textrm{enc} (\textbf{x}_\textrm{img}) \\ \hat{M} = \mathcal{F}_\textrm{dec} (\textbf{h}_\textrm{seg}, \textbf{f}) \end{equation}\]Training Objectives
모델은 텍스트 생성 loss \(\mathcal{L}_\textrm{txt}\)와 segmentation mask loss \(\mathcal{L}_\textrm{mask}\)를 사용하여 end-to-end로 학습된다.
\[\begin{equation} \mathcal{L} = \lambda_\textrm{txt} \mathcal{L}_\textrm{txt} + \lambda_\textrm{mask} \mathcal{L}_\textrm{mask} \end{equation}\]\(\mathcal{L}_\textrm{txt}\)는 autoregressive cross-entropy loss이고 \(\mathcal{L}_\textrm{mask}\)는 per-pixel binary cross-entropy (BCE) loss와 DICE loss의 조합이다. GT \(\textbf{y}_\textrm{txt}\)와 \(\textbf{M}\)이 주어지면 loss는 다음과 같이 계산된다.
\[\begin{equation} \mathcal{L}_\textrm{txt} = \textbf{CE} (\hat{y}_\textrm{txt}, \textbf{y}_\textrm{txt}) \\ \mathcal{L}_\textrm{mask} = \lambda_\textrm{bce} \textbf{BCE} (\hat{\textbf{M}}, \textbf{M}) + \lambda_\textrm{dice} \textbf{DICE} (\hat{\textbf{M}}, \textbf{M}) \end{equation}\]제안된 방법은 기존 LMM에 새로운 segmentation 능력을 부여하여 텍스트뿐만 아니라 세분화된 출력 형식도 생성할 수 있다. 또한 end-to-end 학습 파이프라인을 기반으로 하며 LLM과 비전 모듈을 hidden embedding으로 연결한다. 이는 분리된 2단계 방법보다 훨씬 더 효과적이다.
2. Training
Training Data Formulation

위 그림에서 볼 수 있듯이 학습 데이터는 주로 세 부분으로 구성되며, 모두 널리 사용되는 공개 데이터셋에서 파생된다.
Semantic Segmentation Dataset
Semantic segmentation 데이터셋은 일반적으로 이미지와 멀티클래스 레이블로 구성된다. 학습 중에 각 이미지에 대해 여러 카테고리를 무작위로 선택한다. 질문과 답변 템플릿을 다음과 같다.
USER: <IMAGE> Can you segment the {class name} in this image?
ASSISTANT: It is <SEG>.
여기서 {class name}은 선택된 카테고리이고 <IMAGE>는 이미지 패치 토큰이다. Binary segmentation mask는 GT로 사용된다. 학습 중에는 데이터 다양성을 보장하기 위해 다른 템플릿을 사용하여 QA 데이터를 생성하기도 한다. 저자들은 ADE20K, COCO-Stuff, LVIS-PACO part segmentation 데이터셋을 채택하였다.
Vanilla Referring Segmentation Dataset
참조 분할 데이터셋은 입력 이미지와 대상 개체에 대한 명시적인 짧은 설명을 제공한다. 질문과 답변 템플릿을 다음과 같다.
USER: <IMAGE> Can you segment {description} in this image?
ASSISTANT: Sure, it is <SEG>.
여기서 {description}은 제공된 명시적인 설명이다. 저자들은 refCOCO, refCOCO+, refCOCOg, refCLEF 데이터셋을 채택하였다.
Visual Question Answering Dataset
LMM의 원래 VQA 능력을 유지하기 위해 학습 중에 VQA 데이터셋도 포함된다. LLaVA v1에는 LLaVA-Instruct-150k를 사용하고 LLaVA v1.5에는 LLaVA-v1.5-mix665k를 사용한다.
위의 데이터셋들에는 referring segmentation 데이터 샘플이 포함되어 있지 않다. 대신 쿼리 텍스트에 대상 물체가 명시적으로 표시된 샘플만 포함된다. 놀랍게도 복잡한 추론 학습 데이터가 없어도 LISA는 ReasonSeg 벤치마크에서 인상적인 zero-shot 능력을 보여준다.
또한 저자들은 복잡한 추론이 포함된 239개의 데이터 샘플에 대해서만 모델을 fine-tuning하면 성능이 더욱 향상될 수 있음을 발견했다.
Trainable Parameters
사전 학습된 LMM $\mathcal{F}$ (LLaVA)의 학습된 지식을 보존하기 위해 LoRA를 활용하여 효율적인 fine-tuning을 수행한다. 비전 백본 \(\mathcal{F}_\textrm{enc}\)는 완전히 고정되며, 디코더 $\mathcal{F}_\textrm{dec}$는 완전히 fine-tuning된다. 또한 LLM 토큰 임베딩, LLM head, projection layer $\gamma$도 학습 가능하다.
결과 모델은 원래 가지고 있던 텍스트 생성 능력을 망각하는 문제를 피하고 대화 능력을 유지한다. 잠재적인 이유는 학습 가능한 파라미터를 줄이기 위해 LoRA fine-tuning을 사용하고 fine-tuning 중에 VQA 데이터셋을 통합한다는 것이다.
Experiment
1. Reasoning Segmentation Results
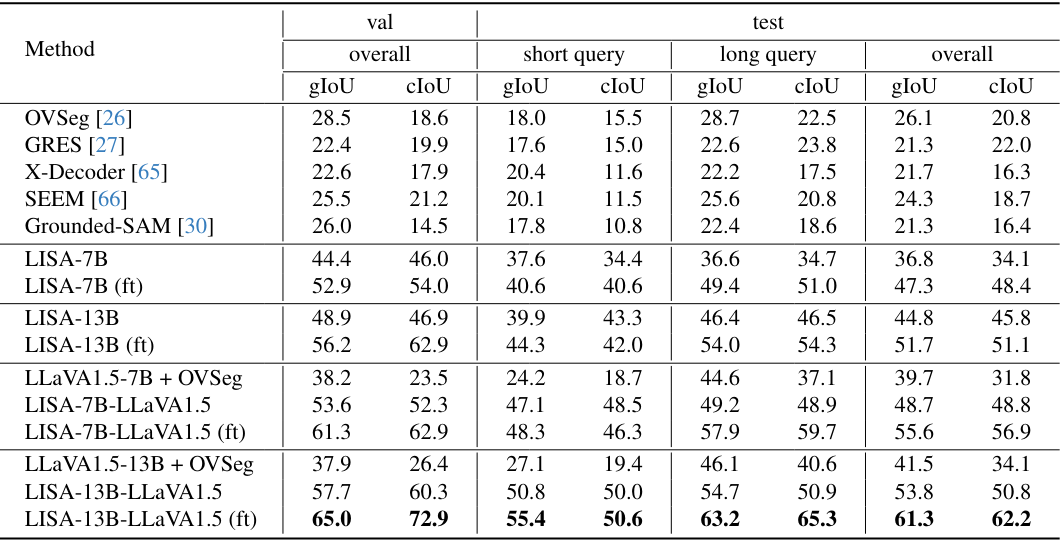
다음은 기존 방법들과 reasoning segmentation 성능을 비교한 표이다. (ft)는 239개의 reasoning segmentation 데이터로 모델을 fine-tuning한 것이다.
2. Vanilla Referring Segmentation Results
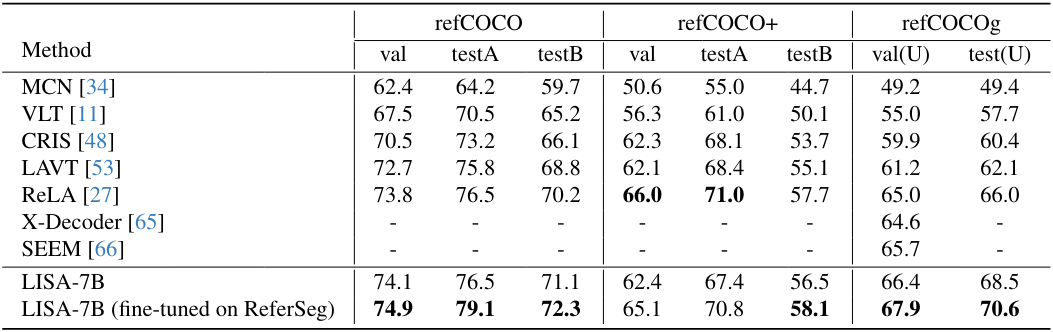
다음은 기존 방법들과 referring segmentation 성능을 비교한 표이다.
3. Ablation Study
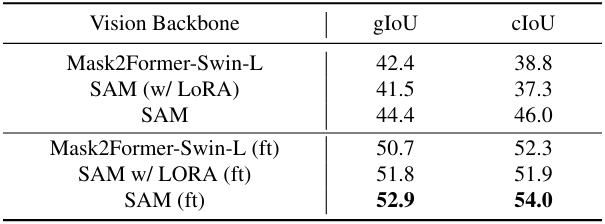
다음은 비전 백본에 대한 ablation 결과이다.
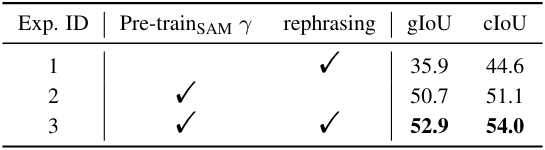
다음은 SAM의 사전 학습된 가중치와 rephrasing에 대한 ablation 결과이다.
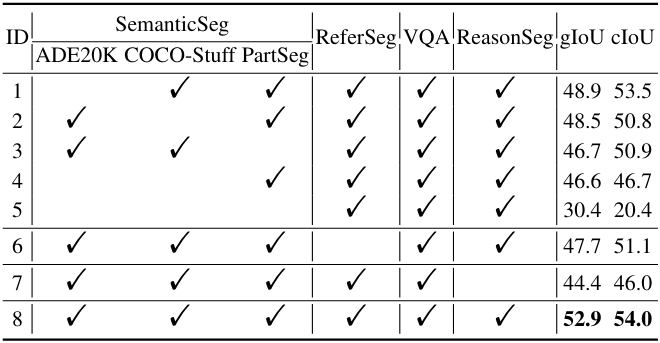
다음은 학습 데이터에 대한 ablation 결과이다.
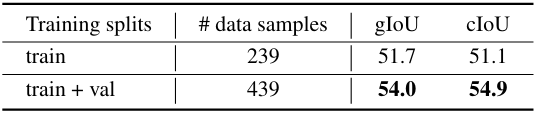
다음은 ReasonSeg test set에서의 결과이다.
4. Qualitative Results
다음은 기존 방법들과 시각적으로 비교한 것이다.
