[논문리뷰] Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
ICCV 2025. [Paper] [Page] [Github]
Yujie Zhou, Jiazi Bu, Pengyang Ling, Pan Zhang, Tong Wu, Qidong Huang, Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Anyi Rao, Jiaqi Wang, Li Niu
Shanghai Jiao Tong University | University of Science and Technology of China | The Chinese University of Hong Kong | Hong Kong University of Science and Technology | Stanford University | Shanghai AI Laboratory
12 Feb 2025

Introduction
본 논문에서는 추가적인 학습이나 최적화 과정 없이 부드럽고 고품질의 relighting된 동영상을 생성할 수 있는 Light-A-Video을 제안하였다. 동영상에 대한 일반적인 설명과 조명 조건을 제공하는 텍스트 프롬프트가 주어지면, Light-A-Video 파이프라인은 이미지 기반 모델의 relighting 능력과 video diffusion model (VDM)의 모션 prior를 최대한 활용하여 zero-shot 방식으로 입력 동영상을 relighting할 수 있다.
프레임별로 이미지 relighting 모델을 적용하면 생성된 광원이 동영상 프레임 간에 불안정하다. 이러한 불안정성은 외형의 relighting 불일치와 프레임 간 심한 깜빡임 현상을 초래한다. 저자들은 생성된 광원을 안정화하고 일관된 결과를 보장하기 위해 이미지 relighting 모델의 self-attention layer내에 Consistent Light Attention (CLA) 모듈을 설계했다. CLA는 시간적으로 평균화된 feature들을 attention 연산에 통합함으로써 프레임 간 상호작용을 촉진하고 구조적으로 안정적인 광원을 생성한다.
프레임 간 외형 안정성을 더욱 향상시키기 위해, 본 논문에서는 Progressive Light Fusion (PLF) 전략을 통해 VDM의 모션 prior를 활용하였다. Light transport에 대한 물리적 원리를 따르는 PLF는 linear blending을 점진적으로 사용하여 CLA에서 relighting된 외형을 각 원본 denoising target에 통합함으로써 동영상 denoising process를 원하는 relighting 방향으로 점진적으로 유도한다.
최종적으로, Light-A-Video는 완벽한 end-to-end 파이프라인으로서 부드럽고 일관된 동영상 relighting을 효과적으로 구현한다. 학습이 필요 없는 Light-A-Video는 특정 VDM에 제한되지 않으므로 다양한 인기 동영상 생성 backbone과 높은 호환성을 가진다.
Method
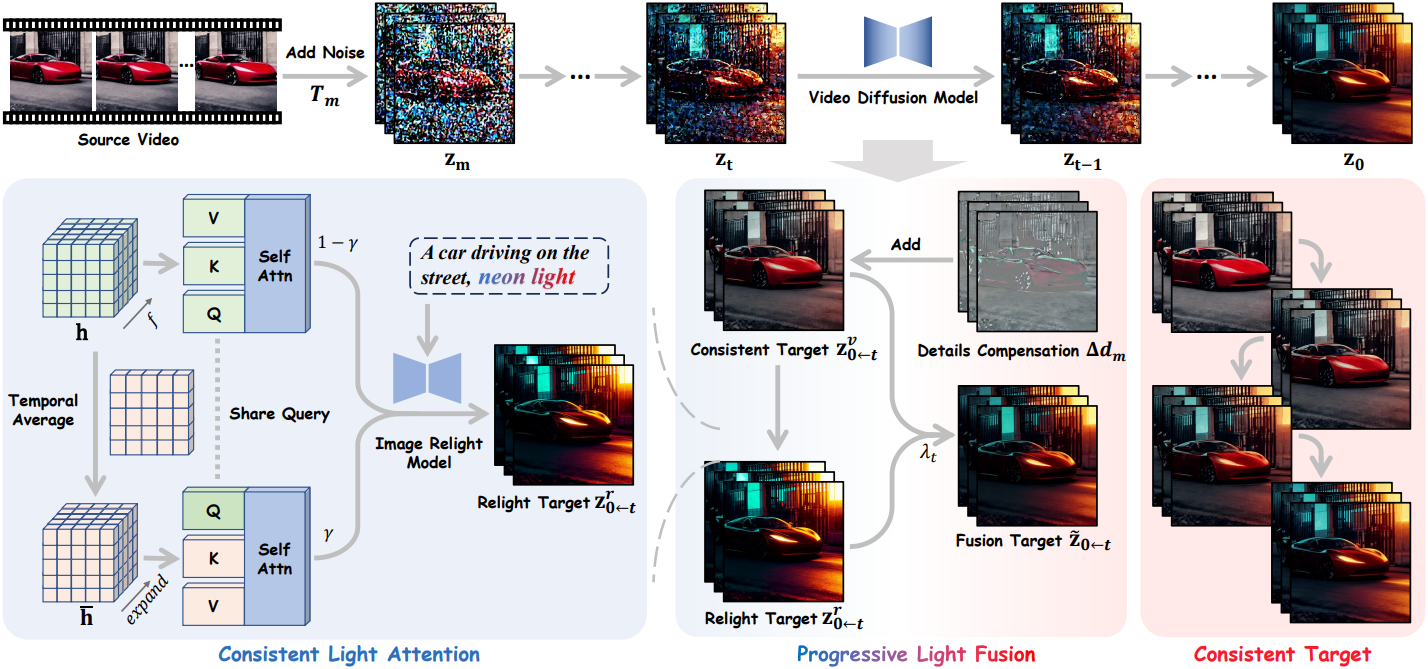
1. Problem Formulation
원본 동영상과 조명 조건 $c$가 주어졌을 때, 동영상 relighting의 목표는 원본 동영상의 모션을 유지하면서 조명 조건 $c$를 일치시켜 relighting된 동영상으로 변환하는 것이다. 단순히 외형적인 측면에만 초점을 맞추는 이미지 relighting과는 달리, 동영상 relighting은 시간적 일관성과 모션 보존이라는 추가적인 과제를 안고 있으며, 프레임 간의 시각적 일관성을 요구한다.
2. Consistent Light Attention
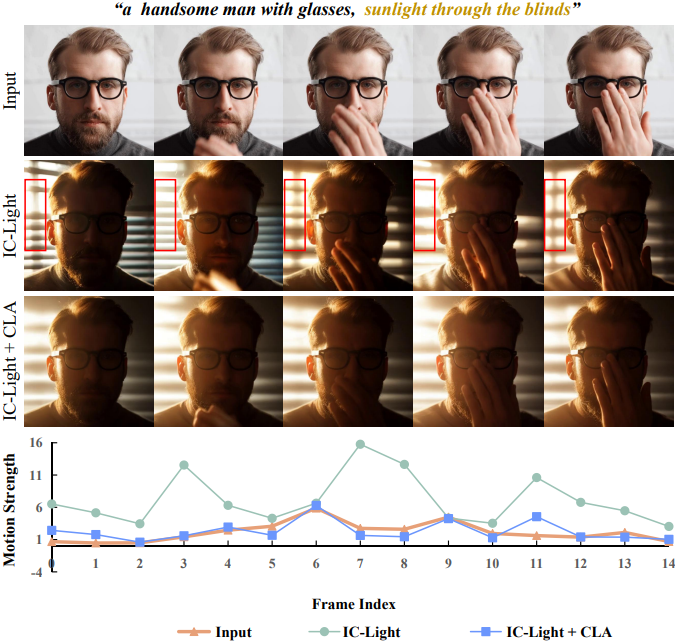
동영상 relighting에 대한 간단한 접근 방식은 동일한 조명 조건에서 프레임별로 직접 이미지 relighting을 수행하는 것이다. 그러나 위 그림에서 볼 수 있듯이, 이러한 단순한 방법은 프레임 간 외형 일관성을 유지하지 못하여 생성된 광원의 잦은 깜빡임과 시간적 조명 불일치를 초래한다.
프레임 간 정보 통합을 개선하고 안정적인 광원을 생성하기 위해, 본 논문에서는 Consistent Light Attention (CLA) 모듈을 제안하였다. 구체적으로, IC-Light 모델의 각 self-attention layer는 동영상 feature map \(\textbf{h} \in \mathbb{R}^{(b \times f) \times (h \times w) \times d}\)를 입력으로 사용한다. Linear projection을 통해 $\textbf{h}$는 query, key, value feature \(Q, K, V \in \mathbb{R}^{(b \times f) \times (h \times w) \times d}\)로 projection된다. Attention 계산은 다음과 같이 정의된다.
\[\begin{equation} \textrm{Self-Attn}(Q, K, V) = \textrm{Softmax} \left( \frac{QK^\top}{\sqrt{d}} \right) V \end{equation}\]CLA 모듈에서는 이중 스트림 attention 융합 전략이 적용된다. 입력 feature $\textbf{h}$가 주어지면, 원본 스트림은 feature map을 attention 모듈에 직접 입력하여 프레임별 attention을 계산하고 출력 \(\textbf{h}_1^\prime\)을 생성한다. 평균 스트림은 먼저 $\textbf{h}$를 \(\mathbb{R}^{b \times f \times (h \times w) \times d}\)로 reshape하고 시간 차원을 따라 평균을 낸 다음 $f$번 확장하여 \(\bar{\textbf{h}}\)를 얻는다.
평균 스트림은 고주파 시간 변동을 완화하여 프레임 간 안정적인 배경 광원 생성을 용이하게 한다. 반면, 원본 스트림은 원래의 고주파 디테일을 유지하여 평균화 과정에서 발생하는 디테일 손실을 보완한다. 그런 다음, \(\bar{\textbf{h}}\)는 self-attention 모듈에 입력되고 출력은 \(\bar{\textbf{h}}_2^\prime\)가 된다. CLA 모듈의 최종 출력 \(\textbf{h}_o^\prime\)는 두 스트림 간의 가중 평균이며, trade-off 파라미터 $\gamma$가 적용된다.
\[\begin{equation} \textbf{h}_o^\prime = (1 - \gamma) \textbf{h}_1^\prime + \gamma \bar{\textbf{h}}_2^\prime \end{equation}\]CLA를 활용하면 전체 동영상에 걸쳐 글로벌 컨텍스트를 파악하고 더욱 안정적인 광원을 생성할 수 있다.
3. Progressive Light Fusion
CLA 모듈은 프레임 간 일관성을 향상시키지만 픽셀 수준의 제약 조건이 부족하여 외형 디테일에 불일치가 발생한다. 이를 해결하기 위해 대규모 동영상 데이터셋으로 학습된 video diffusion model (VDM)에서 모션 prior를 활용하고, temporal attention 모듈을 사용하여 일관된 모션 및 조명 변화를 보장한다. Light-A-Video의 독창성은 denoising process에 relighting 결과를 점진적으로 적용하는 데 있다.
먼저 원본 동영상이 latent space로 인코딩된 다음, $T_m$ step noise가 추가되어 noise가 포함된 latent \(\textbf{z}_m\)을 얻는다. 각 denoising step $t$에서, noise가 없는 성분 \(\hat{\textbf{z}}_{0 \leftarrow t}\)가 예측되며, 이는 현재 step의 denoising target이 된다.
VDM의 모션 prior를 기반으로 하는 denoising process는 \(\hat{\textbf{z}}_{0 \leftarrow t}\)가 시간적으로 일관성을 유지하도록 유도한다. 따라서, 이를 환경 조명 $L_t^v$를 갖는 동영상 Consistent Target \(\textbf{z}_{0 \leftarrow t}^v\)로 정의한다. 그러나 예측된 \(\hat{\textbf{z}}_{0 \leftarrow t}\)와 원본 동영상 사이에는 여전히 차이가 존재하여, relighting된 동영상에서 디테일 손실이 발생한다.
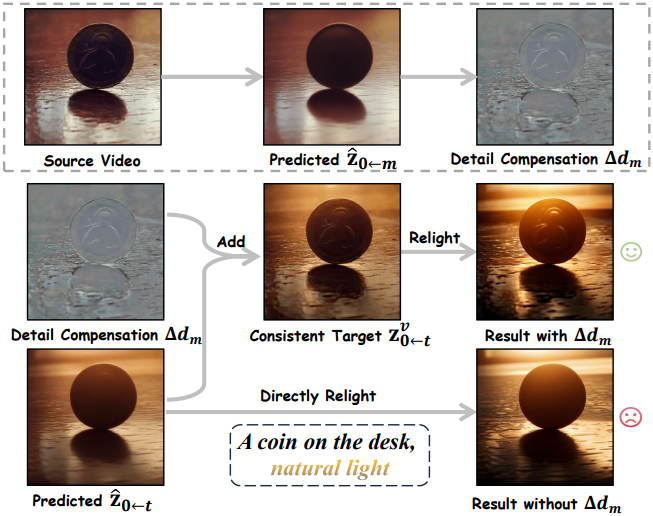
이러한 문제를 해결하기 위해, 각 step에서 \(\textbf{z}_{0 \leftarrow t}^v\)에 디테일 보정 \(\Delta d_m\)을 적용한다. 그런 다음, \(\textbf{z}_{0 \leftarrow t}^v\)를 CLA 모듈로 보내 relighting된 latent를 얻고, 이는 $t$번째 denoising step에서 조명 $L_t^r$을 갖는 Relighting Target \(\textbf{z}_{0 \leftarrow t}^r\)로 사용된다.
Light transport 이론에 따라, 사전 학습된 VAE \(\{\mathcal{E}(\cdot), \mathcal{D}(\cdot)\}\)를 사용하여 두 개의 target을 픽셀 수준으로 디코딩하여 각각 이미지 \(\textbf{I}_t^v\)와 \(\textbf{I}_t^r\)을 얻는다. 융합된 이미지 \(\textbf{I}_t^f\)는 다음과 같이 나타낼 수 있다.
\[\begin{equation} \textbf{I}_t^f = \textbf{T} (L_t^v + L_t^r) = \textbf{I}_t^v + \textbf{I}_t^r = \mathcal{D}(\textbf{z}_{0 \leftarrow t}^v) + \mathcal{D}(\textbf{z}_{0 \leftarrow t}^r) \end{equation}\]각 step에서 인코딩된 latent \(\mathcal{E}(\textbf{I}_t^f)\)를 새로운 target으로 직접 사용하는 것은 최적의 성능을 내지 못하는 것으로 관찰되었다. 이는 두 target 사이의 간격이 지나치게 커서 VDM의 정제 능력을 초과하고 결과적으로 눈에 띄는 시간적 조명 떨림을 유발하기 때문이다.
저자들은 이러한 간격을 완화하기 위해 점진적 조명 융합 전략을 제안하였다. 구체적으로, denoising이 진행됨에 따라 감소하는 융합 가중치 \(\lambda_t\)를 도입하여 relighting target의 영향을 점진적으로 줄인다. 점진적 조명 융합의 결과 \(\textbf{I}_t^p\)는 다음과 같다.
\[\begin{equation} \textbf{I}_t^p = \textbf{I}_t^v + \lambda_t (\textbf{I}_t^r - \textbf{I}_t^v) \end{equation}\]인코딩된 latent \(\tilde{\textbf{z}}_{0 \leftarrow t}\)는 step $t$의 Fusion Target으로 사용되며, 원래의 \(\textbf{z}_{0 \leftarrow t}^v\)를 대체한다. Fusion target을 기반으로, $v$-prediction을 사용하는 DDIM scheduler로 noise가 적은 latent \(\textbf{z}_{t-1}\)을 계산할 수 있다.
\[\begin{equation} a_t = \sqrt{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t}}, \quad b_t = \sqrt{\vphantom{1} \bar{\alpha}_{t-1}} - \sqrt{\vphantom{1} \bar{\alpha}_t} a_t \\ \textbf{z}_{t-1} = a_t \textbf{z}_t + b_t \tilde{\textbf{z}}_{0 \leftarrow t} \end{equation}\]융합된 target \(\tilde{\textbf{z}}_{0 \leftarrow t}\)는 새로운 denoising 방향 \(\tilde{\textbf{v}}_t\)을 결정한다.
\[\begin{equation} \tilde{\textbf{v}}_t = \frac{\sqrt{\vphantom{1} \bar{\alpha}_t} \textbf{z}_t - \tilde{\textbf{z}}_{0 \leftarrow t}}{\sqrt{1 - \bar{\alpha}_t}} \end{equation}\]즉, PLF는 본질적으로 \(\textbf{v}_t\)를 반복적으로 정제하고 denoising process를 relighting 방향으로 유도한다.
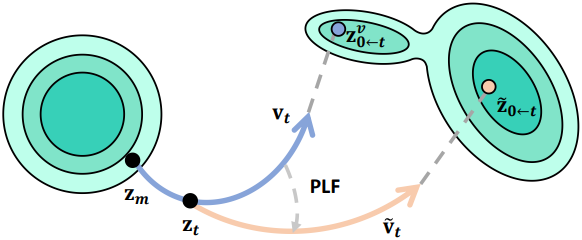
Euler Scheduler나 Rectified Flow와 같이 denoising 방향을 모델링할 수 있는 다른 scheduler도 적용 가능하다. Denoising이 진행됨에 따라 부드럽고 일관된 조명 주입이 이루어져 일관된 동영상 relighting이 보장된다.
Experiments
1. Qualitative Results
다음은 baseline 방법들과의 정성적 비교 결과이다.

2. Video Relighting with Background Generation
다음은 텍스트 조건에 따른 동영상 relighting 및 배경 생성 결과이다.

3. Quantitative Evaluation
다음은 baseline 방법들과의 정량적 비교 결과이다.

4. Ablation Study
다음은 ablation study 결과이다.
