[논문리뷰] LEO: Generative Latent Image Animator for Human Video Synthesis
arXiv 2023. [Paper] [Page] [Github]
Yaohui Wang, Xin Ma, Xinyuan Chen, Antitza Dantcheva, Bo Dai, Yu Qiao
Google Research, Brain Team
6 May 2023

Introduction
GAN과 diffusion model과 같은 심층 생성 모델은 동영상 합성의 획기적인 발전을 촉진하여 text-to-video 생성, 동영상 편집, 3D-aware 동영상 생성과 같은 task를 향상시켰다. 기존 연구들이 프레임별 시각적 품질과 관련하여 유망한 결과를 입증했지만, 풍부한 글로벌 및 로컬 변형을 포함하는 인간 동영상에 맞게 조정된 강력한 시공간적 일관성을 가지는 동영상을 합성하는 것은 여전히 어려운 일이다.
본 논문은 인간 동영상 합성의 시공간적 일관성을 강조하는 효과적인 생성 프레임워크를 제안한다. 이를 염두에 두고 근본적인 step은 외형과 움직임에 대하여 동영상의 disentanglement(분리)와 관련이 있다. 이전 접근 방식은 외형과 모션 feature를 각각 제공하는 두 개의 공동으로 학습된 별개의 네트워크를 통해 이러한 문제를 해결하였으며, 먼저 이미지 generator 학습을 목표로 한 다음 이미지 generator의 latent space에서 동영상을 생성하기 위해 시간적 네트워크 학습을 목표로 하는 2단계 생성 파이프라인을 사용하였다. 그럼에도 불구하고 이러한 접근 방식은 16프레임으로 짧게 생성된 동영상에서도 시간적 아티팩트뿐만 아니라 공간적 아티팩트와 관련된 제한 사항을 포함한다. 저자들은 그러한 한계가 생성 과정에서 나타나는 외형과 모션의 불완전한 disentanglement에서 비롯된다고 주장한다. 특히, Disentanglement를 보장하기 위한 우세한 메커니즘이나 어려운 제약이 없으면 상위 레벨 semantic의 사소한 동요도 증폭되어 pixel space에 상당한 변화를 가져올 것이다.
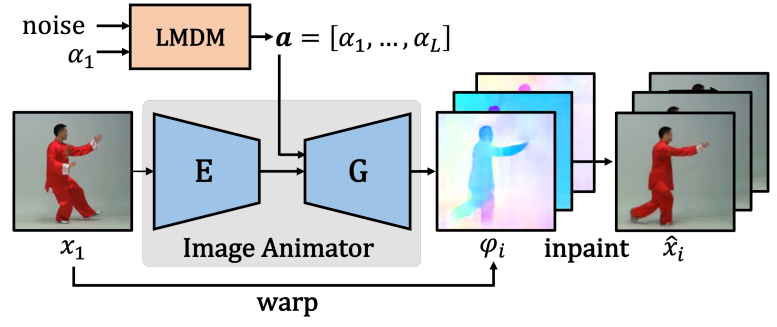
위의 내용에서 벗어나 외형과 모션에 관한 동영상 disentanglement를 위해 본 논문에서는 위 그림과 같이 강력한 시공간 일관성을 보장하기 위해 간소화된 인간 동영상 생성을 위한 새로운 프레임워크 LEO를 제안한다. 이 프레임워크는 모션 semantic을 나타내는 일련의 flow map이 핵심이며, 이는 본질적으로 모션을 외형과 분리한다. 특히 LEO는 Latent Motion Diffusion Module (LMDM)과 flow 기반 이미지 애니메이터를 통합한다. 동영상을 합성하기 위해서는 조건부 생성을 위해 외부에서 초기 프레임을 받거나 unconditional한 생성을 위해 생성 모듈에서 초기 프레임을 얻는다. 이러한 초기 프레임과 LMDM에서 샘플링된 모션 코드 시퀀스가 주어지면 flow 기반 이미지 애니메이터는 일련의 flow map을 생성하고 해당 프레임 시퀀스를 warpand-inpaint 방식으로 합성한다.
LEO의 학습은 두 단계로 나뉜다. 먼저 flow 기반 이미지 애니메이터를 학습하여 입력 이미지를 저차원 latent 모션 코드로 인코딩하고 이러한 코드를 flow map에 매핑하여 warping과 inpainting을 통해 재구성하는 데 사용한다. 따라서 flow 기반 이미지 애니메이터는 일단 학습되면 모션 관련 정보만 포함하도록 엄격하게 제한되는 모션 코드 space를 자연스럽게 제공한다.
두 번째 단계에서는 이미지 애니메이터가 제공하는 space에서 모션 코드 시퀀스를 합성하고 학습 데이터에서 이전의 모션을 캡처하도록 LMDM을 학습한다. LEO에 짧은 학습 동영상 외에 랜점 길이의 동영상을 합성할 수 있는 능력을 부여하기 위해 LMDM에서 Linear Motion Condition (LMC) 메커니즘을 채택한다. 모션 코드의 시퀀스를 직접 합성하는 것과 달리, LMC는 LMDM이 시작 모션 코드에 대해 residual(잔차) 시퀀스를 합성할 수 있도록 하여 추가 residual 시퀀스를 concat하여 더 긴 동영상을 쉽게 얻을 수 있도록 한다.
Method
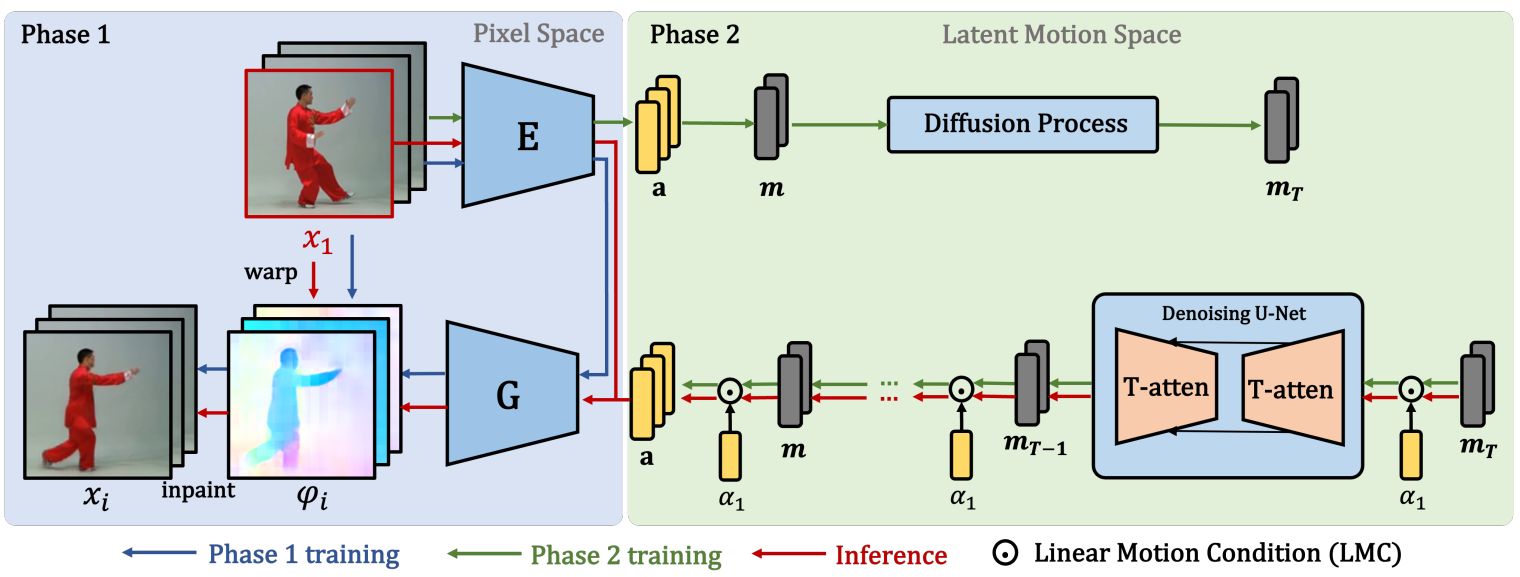
위 그림과 같이 LEO의 학습은 2단계로 구성된다. 먼저 데이터셋의 고품질 latent 모션 코드를 학습하도록 이미지 애니메이터를 학습시킨다. 두 번째 단계에서는 Latent Motion Diffusion Model (LMDM)을 학습하여 latent 모션 코드에서 모션 prior를 학습한다. 동영상을 합성하기 위해 사전 학습된 이미지 애니메이터는 동영상 시퀀스를 생성하기 위해 시작 프레임을 warping과 inpainting하는 데 사용되는 해당 flow map을 생성하는 모션 코드를 사용한다.
동영상 시퀀스 \(v = \{x_i\}_{i=1}^L, x_i \sim \mathcal{X} \in \mathbb{R}^{3 \times H \times W}\)를 \(v = \{\mathcal{T} (x_1, G(\alpha_i))\}_{i=2}^L, \alpha_i \sim A \in \mathbb{R}^{1 \times N}\)으로 공식화한다. 여기서 $x_i$는 $i$번째 프레임을 나타내고, $\alpha_i$는 timestep $i$에서의 latent 모션 코드를 나타내며, $G$는 $\alpha_i$로부터 flow map $\phi_i$를 생성하는 것을 목표로 하는 이미지 애니메이터의 generator를 나타낸다. 생성된 프레임은 $\phi_i$를 사용하여 $x_1$을 warping($\mathcal{T}$)하여 얻는다.
1. Learning Latent Motion Codes
프레임 단위의 latent 모션 코드 학습을 위해 입력 이미지를 해당 모션 코드로 인코딩할 수 있는 state-of-the-art 이미지 애니메이터 LIA를 사용한다. LIA는 인코더 $E$와 generator $G$의 두 모듈로 구성된다. 학습 중에 소스 이미지 $x_s$와 driving 이미지 $x_d$가 주어지면 $E$는 $x_s$, $x_d$를 모션 코드 $\alpha = E (x_s, x_d)$로 인코딩하고 $G$는 코드에서 flow field $\phi = G(\alpha)$를 생성한다. LIA는 driving 이미지 재구성을 목표로 self-supervised 방식으로 학습된다.
Self-supervised 방식으로 LIA를 학습하면 프레임워크에 두 가지 주목할만한 이점이 있다.
- LIA는 고품질 지각 결과를 얻을 수 있다.
- 모션 코드는 flow map과 엄격히 동일하므로 $\alpha$가 어떠한 외형의 간섭 없이 모션과만 관련된다는 보장이 있다.
2. Leaning a Motion Prior
LIA가 타겟 데이터셋에서 잘 학습되면 주어진 동영상 \(v = \{x_i\}_{i=1}^L\)에 대해 고정된 $E$로 모션 시퀀스 \(a = \{\alpha_i\}_{i=1}^L\)을 얻을 수 있다. 학습의 두 번째 단계에서 temporal Diffusion Model에 의해 모션 prior를 학습한다.
이미지 합성과 달리 두 번째 단계의 데이터는 일련의 시퀀스다. 먼저 $a$의 시간적 상관 관계를 모델링하기 위해 temporal Diffusion Model을 적용한다. 이 모델의 일반적인 아키텍처는 1D U-Net이다. 이 모델을 학습하기 위해 간단한 평균 제곱 loss을 사용하여 표준 학습 전략을 따른다.
\[\begin{equation} L_\textrm{LMDM} = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (a_t, t) \|_2^2] \end{equation}\]여기서 $\epsilon$는 스케일링되지 않은 noise, $t$는 timestep, $a_t$은 시간 $t$에 대한 latent noised 모션 코드이다. Inference 과정에서 랜덤 Gaussian noise $a_T$를 \(a_0 = \{\alpha_i\}_{i=1}^L\)로 반복적으로 denoise하고 generator를 통해 최종 동영상 시퀀스를 얻는다.
동시에 저자들은 완전한 unconditional 방식으로 모션 시퀀스를 학습하는 것이 전면적인 한계를 가져온다는 것을 발견했다. 즉,
- 생성된 코드는 부드러운 동영상을 생성하기에 충분히 일관성이 없다
- 코드는 고정된 길이의 동영상을 제작하는 데만 사용할 수 있다.
따라서 이러한 문제를 해결하기 위해 고품질 및 긴 인간 동영상을 목표로 하는 Conditional Latent Motion Diffusion Model (cLMDM)을 제안한다.
LIA의 주요 특징 중 하나는 linear motion space와 관련이 있다는 것이다. $a$의 모든 모션 코드 $\alpha_t$는 다음과 같이 재구성될 수 있다.
\[\begin{equation} \alpha_i = \alpha_1 + m_i, \quad i \ge 2 \end{equation}\]여기서 $\alpha_1$은 첫 번째 timestep에서의 모션 코드를 나타내고 $m_i$는 timestep 1과 $i$ 사이의 모션 차이를 나타내므로 $a$를 다음과 같이 다시 공식화할 수 있다.
\[\begin{equation} a = a_1 + m \end{equation}\]여기서 \(m = \{m_i\}_{i=2}^L\)는 모션 차이 시퀀스를 나타낸다. 따라서 모션 시퀀스가 $\alpha_1$과 $m$으로 표현될 수 있음을 나타낸다. 이를 기반으로 cLMDM에서 Linear Motion Condition (LMC) 메커니즘을 사용하여 생성 프로세스를 $\alpha_1$로 컨디셔닝한다. 학습하는 동안 각 timestep에서 전체 $a$ 대신 $m_t$에만 noise를 추가하고 $\alpha_1$은 그대로 둔다. cLMDM의 목적 함수는 다음과 같다.
\[\begin{equation} L_\textrm{cLMDM} = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (m_t, \alpha_1, t) \|_2^2] \end{equation}\]여기서 $\alpha_1$은 조건 신호이고 $m_t$는 시간 $t$에서의 $m$이다. $\alpha_1$은 먼저 $m_t$에 더해진 다음 시간 차원으로 concat된다. LMC는 $m_0$에 도달할 때까지 각 timestep에서 적용된다. 최종 모션 시퀀스는 $a_0 = [\alpha_1, m_0]$로 구한다. $\alpha_1$이 초기 모션을 따르도록 생성된 $m$을 제한하는 강력한 신호 역할을 하기 때문에 관련 생성된 모션 시퀀스가 더 안정적이고 더 적은 아티팩트를 포함한다.
cLMDM의 결과가 이전 모델보다 성능이 우수하지만 학습 및 inference 단계 모두에서 ground truth $\alpha_1$이 필요하다. Unconditional한 생성을 위해 프레임별 방식으로 분포 $p(\alpha_ㅑ)$에 맞추기 위해 추가적인 간단한 Diffusion Model을 학습한다. cLMDM과 이 간단한 Diffusion Model을 공동으로 Latent Motion Diffusion Model (LMDM)이라고 한다. 이러한 방식으로 LMDM은 conditional 및 unconditional 모션 생성 모두에서 작동할 수 있다.
랜덤 길이의 동영상을 생성하기 위해 제안된 LMDM을 기반으로 하는 autoregressive 접근 방식을 제안한다. 이전에 생성된 시퀀스의 마지막 모션 코드를 현재 시퀀스의 $\alpha_1$로 취함으로써 랜덤하게 샘플링된 noise를 사용하여 LMDM은 무한한 길이의 모션 시퀀스를 생성할 수 있다. 사전 학습된 LIA에서 이러한 시퀀스를 시작 이미지와 결합함으로써 LEO는 사실적인 긴 동영상을 합성할 수 있다.
3. Learning Starting Frames
프레임워크에서 동영상을 합성하려면 시작 이미지 $x_1$이 필요하다. 이미지 space는 독립적으로 모델링되므로 여기서는 $x_1$을 얻기 위한 두 가지 옵션을 제안한다.
Option 1: existing images
첫 번째 옵션은 실제 분포 또는 이미지 생성 네트워크에서 이미지를 직접 가져오는 것이다. 이러한 맥락에서 모델은 $x_1$에서 미래의 움직임을 예측하는 방법을 배우는 조건부 동영상 생성 모델이다. 시작 모션 $\alpha_1$은 $\alpha_1 = E(x_1)$을 통해 구한다.
Option 2: conditional Diffusion Models
두 번째 옵션은 $\alpha_1$을 조건으로 conditional DDPM (cDDPM)을 학습하여 $x_1$을 합성하는 것이다. LEO와 LMDM, cDDPM을 결합하여 unconditional한 영상 합성이 가능하다.
Experiments
- 데이터셋: TaichiHD, FaceForensics, CelebV-HQ
- Metrics: FVD, KVD, Average Content Distance (ACD)
1. Qualitative Evaluation
다음은 LEO를 다양한 모델들과 정성적으로 비교한 것이다.
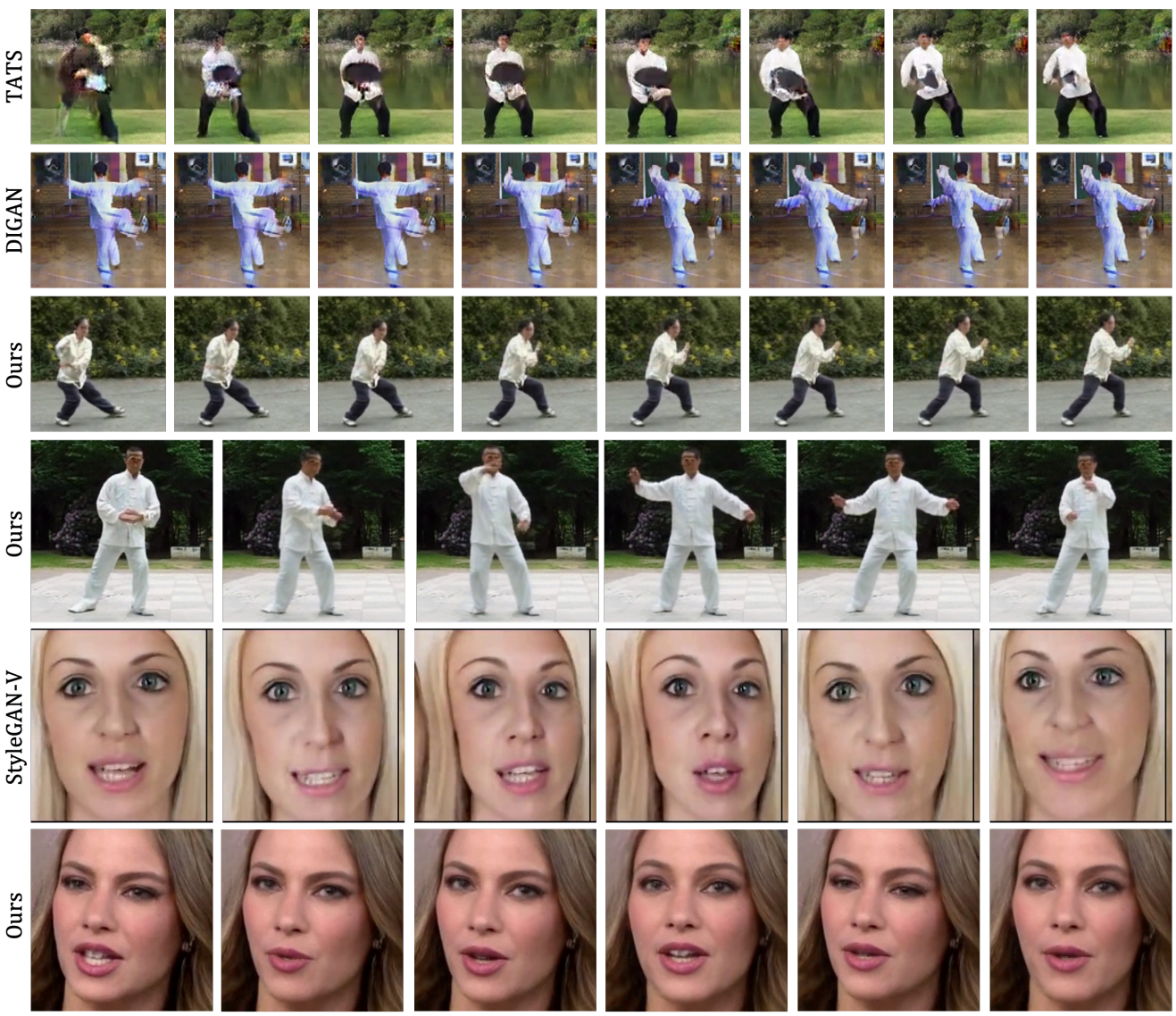
다음은 긴 동영상 생성 결과를 비교한 것이다.

2. Quantitative evaluation
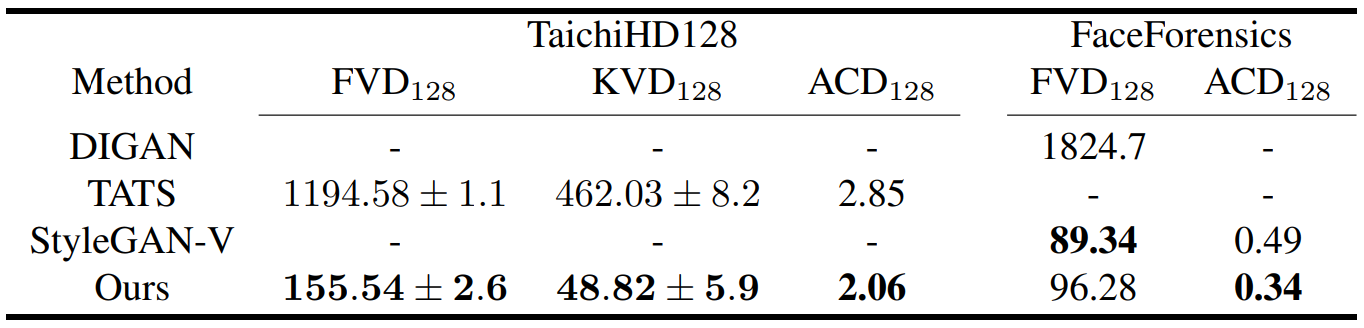
다음은 unconditional 및 conditional한 짧은 동영상 생성에 대한 평가 결과이다.

다음은 unconditional한 긴 동영상 생성에 대한 평가 결과이다.
다음은 user study 결과이다.

3. Ablation study
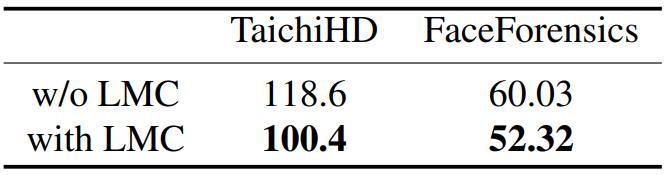
다음은 LMC 유무에 대한 ablation study 결과이다.
Additional Analysis
1. Motion and appearance disentanglement
저자들은 동일한 $x_1$을 다른 $m$과 결합하여 $m$이 모션과 관련된 것인지 밝히는 것을 목표로 실험을 진행하였다. 다음 그림은 $m$이 다르면 같은 피사체가 다른 동작을 수행할 수 있음을 보여준다.

이는 LMDM이 실제로 모션 space을 학습하고 있으며 외형과 모션이 명확하게 분리되어 있음을 증명한다. 이 실험은 다른 noise 시퀀스가 다양한 모션 시퀀스를 생성할 수 있기 때문에 모델이 학습 데이터셋에 overfitting되지 않음을 추가로 나타낸다.
2. Video Editing
외형이 $x_1$로 모델링되므로 시작 이미지의 semantic을 수정하여 동영상을 편집할 수 있다. Image-to-image translation이 필요한 이전 접근 방식과 비교할 때 LEO는 semantic을 한 번에 편집하면 된다.

관련 결과는 위 그림에 나와 있다. 다양한 프롬프트를 입력하여 시작 프레임에 ControlNet을 적용한다. 모션 space가 외형 space와 완전히 분리되어 있기 때문에 동영상은 원래의 시간적 일관성을 유지하면서 외형을 독특하게 변경한다.