[논문리뷰] LEDITS: Real Image Editing with DDPM Inversion and Semantic Guidance
arXiv 2023. [Paper] [Page] [Hugging Face]
Linoy Tsaban, Apolinário Passos
HuggingFace
2 Jul 2023
Introduction
텍스트 기반 diffusion model을 사용한 이미지 합성의 탁월한 현실감과 다양성은 큰 주목을 받으며 관심이 급증했다. 대규모 모델의 출현은 수많은 사용자의 상상력을 자극하여 이미지 생성에 전례 없는 창의적 자유를 부여했다. 결과적으로, 이미지 편집을 위해 이러한 강력한 모델을 활용하는 방법을 모색하는 데 초점을 맞춘 지속적인 연구 노력이 나타났다. 직관적인 텍스트 기반 편집의 최근 발전은 텍스트만 사용하여 이미지를 조작하는 diffusion 기반 방법의 능력을 보여주었다.
최근 연구에서는 diffusion model에 대한 semantic guidance (SEGA) 개념이 도입되었다. SEGA는 외부 guidance가 필요 없으며 기존 생성 프로세스에서 계산되며 정교한 이미지 합성 및 편집 능력을 갖춘 것으로 입증되었다. SEGA로 식별된 개념 벡터는 강력하고, 분리되어 있으며, 임의로 결합할 수 있고, 단조롭게 확장될 수 있다. 다른 연구들에서는 픽셀을 텍스트 프롬프트의 토큰과 연결하는 cross-attention layer의 semantic 정보를 활용하는 의미론적 이해에 기반을 둔 이미지 생성 방법을 탐구했다. Cross attention map에 대한 연산을 통해 생성된 이미지에 대한 다양한 변경이 가능하지만 SEGA는 토큰 기반 컨디셔닝이 필요하지 않으며 여러 semantic 변경의 결합이 가능하다.
SOTA 도구를 사용하여 실제 이미지를 텍스트 기반으로 편집하려면 주어진 이미지를 반전(inversion)시켜야 하므로 이를 실제 이미지에 활용하는 데 상당한 어려움이 따른다. 이를 위해서는 diffusion process의 입력으로 사용된 후 입력 이미지를 생성하는 일련의 noise 벡터를 찾아야 한다. 대부분의 diffusion 기반 편집 연구들은 하나의 noise map에서 생성된 이미지로의 결정론적 매핑인 DDIM 방식을 사용한다.
DDPM inversion에서는 DDPM 방식에 대한 inversion 방법이 제안되었다. 해당 논문에서는 DDPM 방식의 생성 프로세스와 관련된 noise map을 계산하는 새로운 방법을 제안하여 일반 DDPM 샘플링에 사용되는 것과 다르게 동작한다. 즉, timestep에 걸쳐 상관 관계가 있고 더 높은 분산을 갖는다. 이 편집 친화적인 DDPM Inversion은 텍스트 기반 편집 task에서 자체적으로 또는 다른 편집 방법과 결합하여 SOTA 결과를 달성하는 것으로 나타났으며 DDIM inversion 기반 방법들과 달리 각 입력 이미지 및 텍스트에 대해 다양한 결과를 생성할 수 있다.
본 논문에서는 LEDITS라고 하는 DDPM inversion 및 SEGA 기술의 결합 및 통합을 자연스럽게 탐색하는 것을 목표로 하였다. LEDITS는 semantic하게 가이드되는 생성 프로세스에 대한 간단한 수정으로 구성된다. 이 수정은 SEGA 기법을 실제 이미지로 확장함과 동시에 두 가지 방법의 편집 능력을 동시에 활용하는 통합 편집 방식을 도입하여 SOTA 방법으로 경쟁력 있는 정성적 결과를 보여주었다.
LEDITS - DDPM Inversion X SEGA
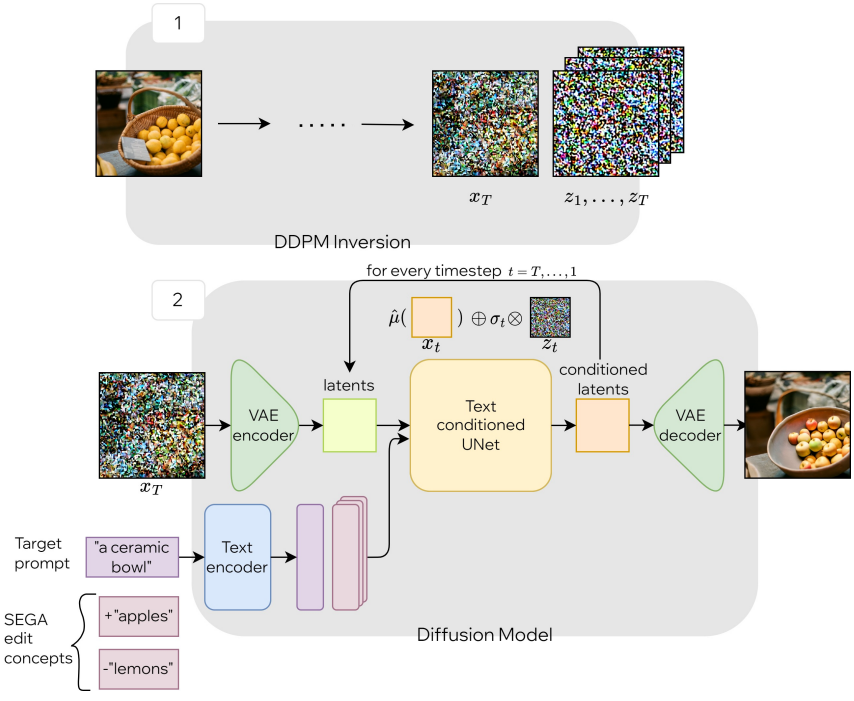
본 논문은 denoising process의 SEGA 방식에 대한 간단한 수정으로 구성된 간단한 통합을 제안하였다. 이러한 수정을 통해 각 구성 요소의 편집 효과에 대한 완전한 제어를 유지하면서 두 가지 방법을 모두 사용하여 편집할 수 있는 유연성이 가능해졌다. 먼저 입력 이미지에 DDPM inversion을 적용하여 이와 관련된 latent code를 추정한다. 편집 작업을 적용하기 위해 각 timestep $t$에 대해 미리 계산된 noise 벡터를 사용하여 SEGA에서 사용된 논리를 DDPM inversion 방식으로 반복하도록 denoising 루프를 수행한다. 즉, DDPM inversion으로 계산된 $x_T$로 denoising process를 시작한다. \(\epsilon_{\theta_t}\)를 timestep $t$에서 semantic guidance를 적용한 diffusion model의 noise 추정치라고 하면, 다음과 같이 latent를 업데이트한다.
여기서 $z_t$는 inversion 프로세스에서 얻은 noise map이다. LEDITS의 개요는 위 그림과 같다. Pseudo-code는 Algorithm 1에 요약되어 있다.

Experiments
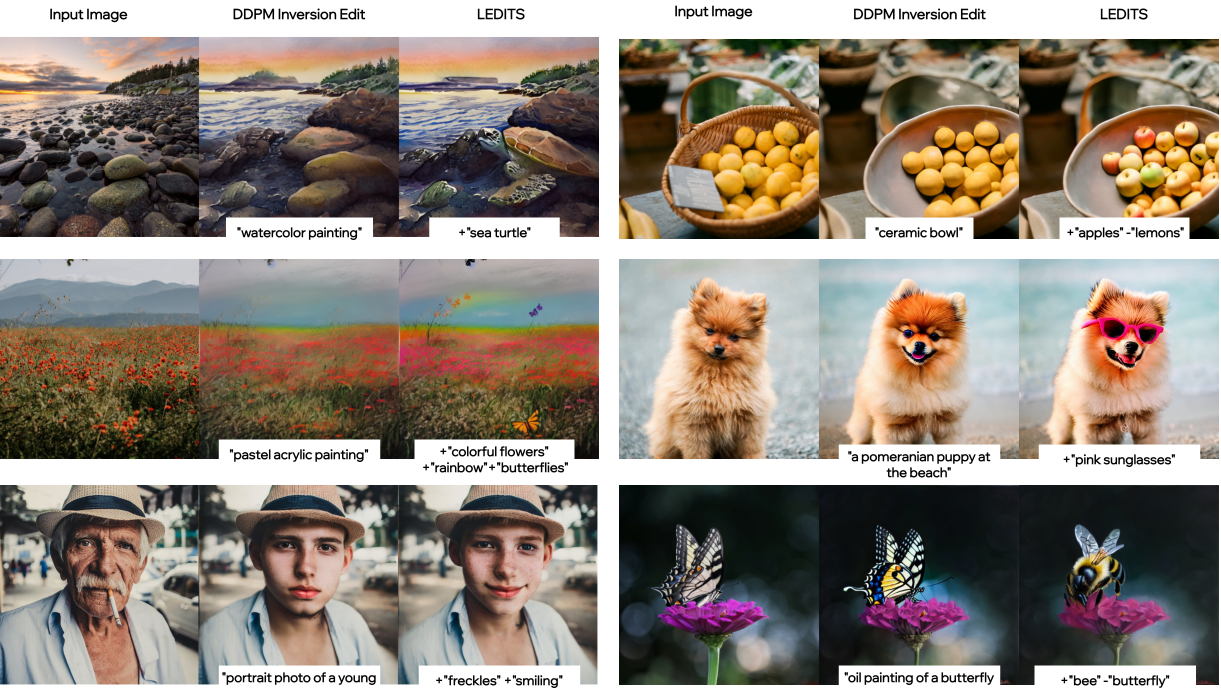
다음은 LEDITS를 사용한 이미지 편집 결과들이다.

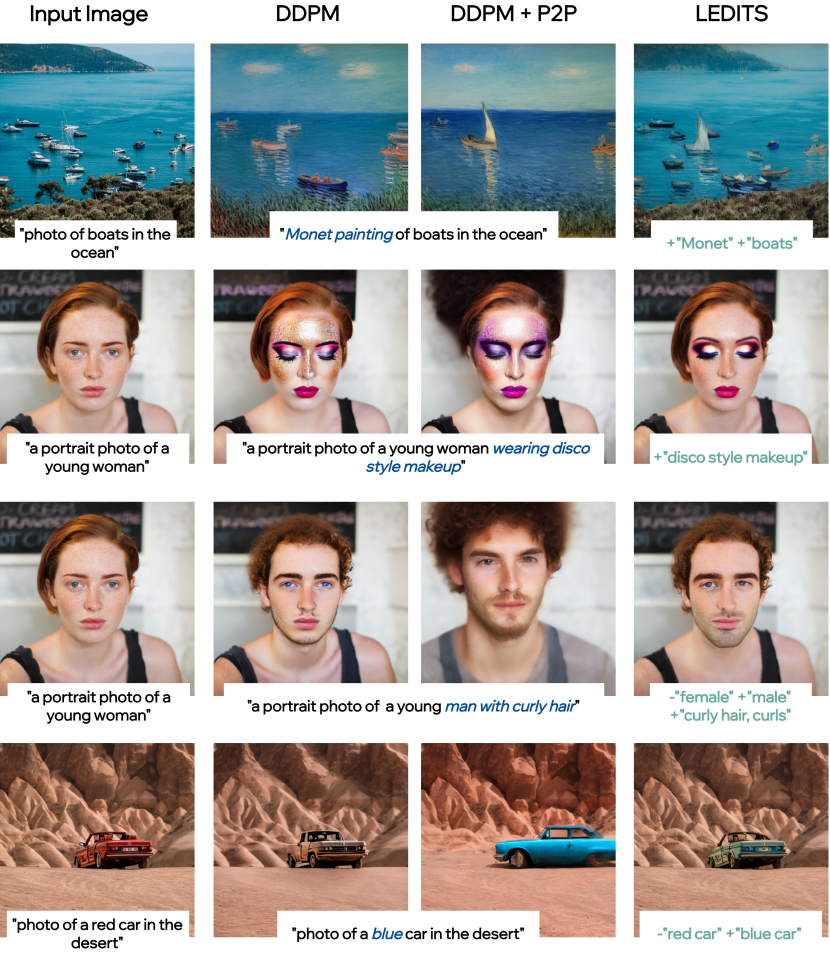
다음은 DDPM inversion만 사용했을 때와 DDPM inversion에 prompt-to-prompt를 사용했을 때의 결과를 LEDITS과 비교한 것이다.
다음은 편집에 DDPM inversion만 사용할 때 skip-steps와 guidance scale 파라미터의 효과를 비교한 결과이다.
