[논문리뷰] LDM3D: Latent Diffusion Model for 3D
arXiv 2023. [Paper] [Github]
Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-Yen Tseng, Fabio Nonato, Matthias Muller, Vasudev Lal
Intel | Intel Labs | Blockade Labs
18 May 2023
Introduction
컴퓨터 비전 분야는 최근 몇 년 동안 특히 생성 AI 분야에서 상당한 발전을 이루었다. 이미지 생성 도메인에서 Stable Diffusion은 텍스트 프롬프트에서 임의의 고충실도 RGB 이미지를 생성하는 개방형 소프트웨어를 제공하여 콘텐츠 제작에 혁신을 가져왔다. 본 논문은 Stable Diffusion v1.4를 기반으로 하며 Latent Diffusion Model for 3D (LDM3D)를 제안한다. 원래 모델과 달리 LDM3D는 주어진 텍스트 프롬프트에서 이미지와 깊이 맵 데이터를 모두 생성할 수 있다. 이를 통해 사용자는 텍스트 프롬프트의 완전한 RGBD 표현을 생성하여 몰입감 있는 360° view에 생명을 불어넣을 수 있다.
LDM3D 모델은 RGB 이미지, 깊이 맵, 캡션을 포함하는 튜플 데이터셋에서 fine-tuning되었다. 이 데이터셋은 4억 개 이상의 이미지-캡션 쌍을 포함하는 대규모 이미지-캡션 데이터셋인 LAION-400M 데이터셋의 부분 집합에서 구성되었다. Fine-tuning에 사용되는 깊이 맵은 이미지의 각 픽셀에 대해 매우 정확한 상대 깊이 추정치를 제공하는 DPT-Large 깊이 추정 모델에 의해 생성되었다. 정확한 깊이 맵의 사용은 현실적이고 몰입감 있는 360° view를 생성하여 사용자가 텍스트 프롬프트를 생생한 디테일로 경험할 수 있도록 하는 데 중요하다.
저자들은 LDM3D의 잠재력을 보여주기 위해 생성된 2D RGB 이미지와 깊이 맵을 사용하여 TouchDesigner로 360° projection을 계산하는 애플리케이션인 DepthFusion을 개발했다. TouchDesigner는 몰입형 및 인터랙티브한 멀티미디어 경험을 생성할 수 있는 다목적 플랫폼이다. DepthFusion은 TouchDesigner의 능력을 활용하여 텍스트 프롬프트를 생생하고 자세하게 전달하는 독특하고 매력적인 360° view를 생성한다. DepthFusion은 디지털 콘텐츠를 경험하는 방식을 혁신할 수 있는 잠재력을 가지고 있다. 고요한 숲, 분주한 도시 풍경, 미래의 공상과학 세계 등에 대한 설명으로 DepthFusion은 사용자가 이전에는 불가능했던 방식으로 텍스트 프롬프트를 경험할 수 있는 몰입감 있고 매력적인 360° view를 생성할 수 있다.
Methodology
1. LDM-3D
모델 아키텍처
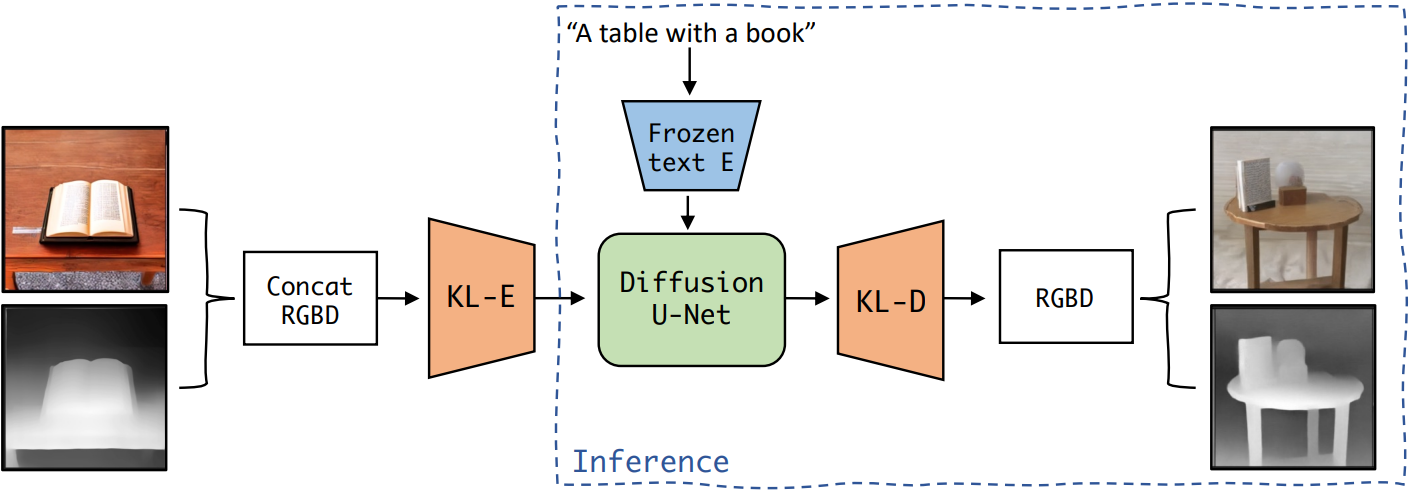
LDM3D는 16억 개의 파라미터로 이루어진 KL 정규화된 diffusion model로, 약간의 수정으로 Stable Diffusion에서 채택되어 텍스트 프롬프트에서 이미지와 깊이 맵을 동시에 생성할 수 있다 (위 그림 참조).
모델에 사용된 KL-autoencoder (KL-AE)는 KL-divergence loss 항을 포함하는 VAE 아키텍처이다. 이 모델을 특정 요구 사항에 맞게 조정하기 위해 KL-AE의 첫 번째와 마지막 Conv2d 레이어를 수정한다. 이러한 조정을 통해 모델은 concat된 RGB 이미지와 깊이 맵으로 구성된 수정된 입력 형식을 수용할 수 있었다.
Diffusion model은 주로 2D convolution layer로 구성된 U-Net backbone 아키텍처를 사용한다. Diffusion model은 학습된 저차원의 KL 정규화된 latent space에서 학습되었다. 픽셀 space에서 학습된 transformer 기반 diffusion model과 비교하여 보다 정확한 재구성과 효율적인 고해상도 합성이 가능하다.
텍스트 컨디셔닝을 위해 고정된 CLIP 텍스트 인코더가 사용되며 인코딩된 텍스트 프롬프트는 cross-attention을 사용하여 U-Net의 다양한 레이어에 매핑된다. 이 접근 방식은 복잡한 자연어 텍스트 프롬프트로 효과적으로 일반화되어 단일 패스에서 고품질 이미지와 깊이 맵을 생성하며 Stable Diffusion 모델에 비해 9,600개의 파라미터만 추가되었다.
데이터 전처리
이 모델은 이미지 및 캡션 쌍을 포함하는 LAION-400M 데이터셋의 부분 집합에서 fine-tuning되었다. LDM3D 모델 fine-tuning에 사용된 깊이 맵은 384$\times$384의 기본 해상도에서 inference를 실행하는 DPT-Large 깊이 추정 모델에 의해 생성되었다. 깊이 맵은 16비트 정수 형식으로 저장되었으며 3채널 RGB-like array로 변환되어 RGB 이미지에서 사전 학습된 Stable Diffusion의 입력 요구 사항과 보다 밀접하게 일치한다. 이 변환을 위해 16비트 깊이 데이터가 3개의 개별 8비트 채널로 unpack되었다. 이러한 채널 중 하나는 16비트 깊이 데이터에 대해 0이지만 이 구조는 잠재적인 24비트 깊이 맵 입력과 호환되도록 설계되었다. 이 reparameterization을 통해 전체 깊이 범위 정보를 보존하면서 깊이 정보를 RGB와 같은 이미지 형식으로 인코딩할 수 있다.
원본 RGB 이미지와 생성된 깊이 맵은 [0, 1] 범위 내의 값을 갖도록 정규화되었다. 오토인코더 모델 학습에 적합한 입력을 생성하기 위해 RGB 이미지와 깊이 맵이 채널 차원을 따라 concat되었다. 이 프로세스는 512$\times$512$\times$6 크기의 입력 이미지를 생성하며, 처음 세 채널은 RGB 이미지에 해당하고 나머지 세 채널은 깊이 맵을 나타낸다. Concat된 입력을 통해 LDM3D 모델은 RGB 이미지와 깊이 맵 모두의 공동 표현을 학습하여 일관된 RGBD 출력을 생성하는 능력이 향상되었다.
Fine-tuning 절차
Fine-tuning 프로세스는 두 단계로 구성된다. 첫 번째 단계에서는 오토인코더를 학습시켜 더 낮은 차원의 지각적으로 동등한 데이터 표현을 생성한다. 그 후 학습을 단순화하고 효율성을 높이는 고정된 오토인코더를 사용하여 diffusion model을 fine-tuning한다. 이 방법은 고차원 데이터로 효과적으로 확장하여 transformer 기반 접근 방식을 능가하므로 재구성과 생성 능력의 균형을 맞추는 복잡성 없이 보다 정확한 재구성과 효율적인 고해상도 이미지 및 깊이 합성이 가능하다.
오토인코더 fine-tuning
KL-AE는 8,233개의 샘플로 구성된 training set과 2,059개의 샘플을 포함하는 validation set에서 fine-tuning되었다. 각 샘플에는 캡션과 해당 이미지 및 깊이 맵 쌍이 포함되어 있다.
수정된 오토인코더의 fine-tuning을 위해 픽셀 space 이미지 해상도의 8배인 downsampling factor를 가진 KL-AE 아키텍처를 사용한다. 이 downsampling factor는 빠른 학습 과정과 고품질 이미지 합성 측면에서 최적이다.
Fine-tuning 과정에서는 learning rate가 $10^{-5}$, batch size가 8인 Adam optimizer를 사용한다. 모델을 83 epochs 동안 학습된다. 이미지와 깊이 데이터 모두에 대한 loss function은 perceptual loss과 원래 KL-AE의 사전 학습에서 사용된 patch 기반의 adversarial loss의 조합으로 구성된다.
\[\begin{equation} L_\textrm{Autoencoder} = \min_{E, D} \max_{\psi} (L_\textrm{rec} (x, D(E(x))) - L_\textrm{adv} (D(E(x))) + \log D_\psi (x) + L_\textrm{reg} (x; E, D)) \end{equation}\]여기서 $D(E(x))$는 재구성된 이미지, $L_\textrm{rec} (x, D(E(x)))$는 perceptual reconstruction loss, $L_\textrm{adv} (D(E(x)))$는 adversarial loss, $D_\psi (x)$는 patch 기반 discriminator loss이고 $L_\textrm{reg} (x; E, D)$는 KL 정규화 loss이다.
Diffusion model fine-tuning
오토인코더 fine-tuning에 이어 diffusion model을 fine-tuning하는 두 번째 단계로 진행된다. 이는 latent 입력 크기가 64$\times$64$\times$4인 고정된 오토인코더의 latent 표현을 입력으로 사용한다.
이 단계에서는 learning rate가 $10^{-5}$이고 batch size가 32인 Adam optimizer를 사용한다. 다음과 같은 loss function을 사용하여 178 epochs에 대하여 diffusion model을 학습한다.
\[\begin{equation} L_\textrm{LDM3D} := \mathbb{E}_{\epsilon \sim \mathcal{N}(0, 1), t} [\| \epsilon - \epsilon_\theta (z_t, t) \|_2^2] \end{equation}\]여기서 $\epsilon_\theta (z_t, t)$는 denoising U-Net에 의해 예측된 noise이고 $t$는 균일하게 샘플링된다. Stable Diffusion v1.4 모델의 가중치를 시작점으로 사용하여 LDM3D fine-tuning을 시작한다.
2. Immersive Experience Generation
이미지 생성을 위한 AI 모델은 AI 예술의 공간에서 두드러지게 나타났으며 일반적으로 diffuse된 콘텐츠의 2D 표현을 위해 설계되었다. 이미지를 3D 몰입형 환경에 투사하려면 만족스러운 결과를 얻기 위해 매핑 및 해상도 수정을 고려해야 했다. 올바르게 project된 출력의 또 다른 이전 제한 사항은 단일 시점으로 인해 인식이 손실될 때 발생한다. 현대식 시청 장치 및 기술은 입체 몰입 경험을 위해 두 시점 사이의 시차를 필요로 한다. 기록 장치는 일반적으로 시차와 카메라 파라미터를 기반으로 3D 출력을 생성할 수 있도록 고정된 거리에 있는 두 대의 카메라에서 영상을 캡처한다. 그러나 단일 이미지에서 동일한 결과를 얻으려면 픽셀 space의 오프셋을 계산해야 한다. LDM3D 모델을 사용하면 깊이 맵이 RGB 색상 space와 별도로 추출되며 3D에서 동일한 이미지 space의 적절한 “왼쪽” 및 “오른쪽” 시점을 구별하는 데 사용할 수 있다.
먼저 초기 이미지가 생성되고 해당 깊이 맵이 저장된다. TouchDesigner를 사용하면 RGB 컬러 이미지가 3D 공간에서 equirectangular spherical polar object의 외부에 project된다. 원근감은 몰입형 공간을 보는 중심으로 구형 오브젝트 내부의 원점 0,0,0에 설정된다. 구의 vertex는 원점에서 모든 방향으로 동일한 거리로 정의된다. 그런 다음 깊이 맵은 모노톤 색상 값을 기반으로 원점에서 해당 vertex까지의 거리를 조작하기 위한 지침으로 사용된다. 1.0에 가까운 값은 vertex을 원점에 더 가깝게 이동하고 0.0의 값은 원점에서 더 먼 거리로 조정된다. 값이 0.5이면 vertex을 조작하지 않는다. 0,0,0의 monoscopic view에서 “광선”이 원점에서 바깥쪽으로 선형으로 확장되기 때문에 이미지의 변경을 감지할 수 없다. 그러나 입체 시점의 이중 시점에서는 매핑된 RGB 이미지의 픽셀이 역동적인 방식으로 왜곡되어 깊이 있는 착시를 제공한다. Vertex 거리가 초기 계산에 대해 동일하게 크기가 조정되므로 단일 시점을 원점 0,0,0에서 멀리 이동하는 동안에도 이와 동일한 효과를 관찰할 수 있다. RGB 색상 space와 깊이 맵 픽셀이 동일한 영역을 차지하기 때문에 기하학적 모양을 가진 개체에는 TouchDesigner 내의 렌더링 엔진에서 자체 가상 형상 치수를 통해 대략적인 깊이가 지정된다.
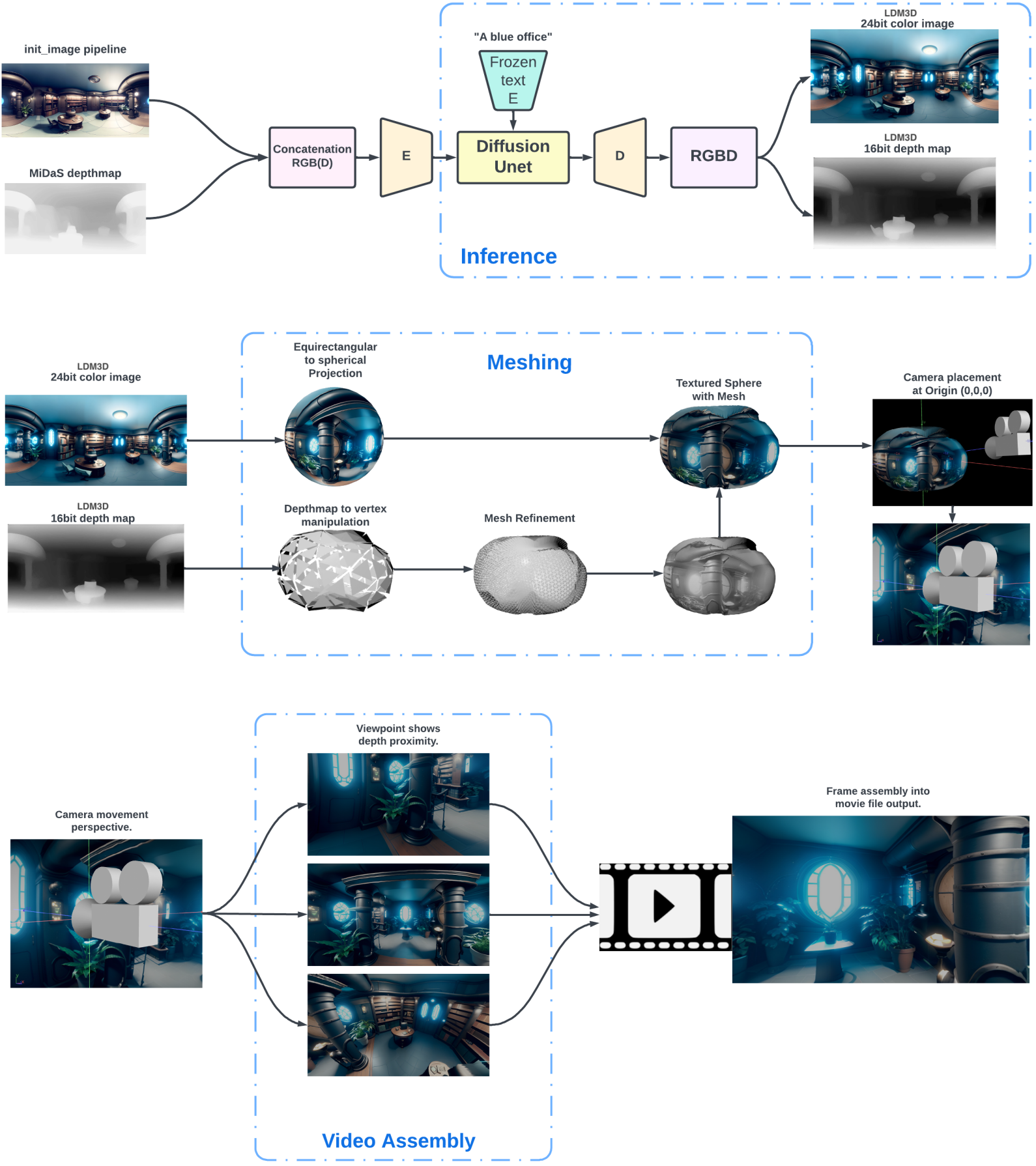
위 그림은 전체 파이프라인을 설명한다. 이 접근 방식은 TouchDesigner 플랫폼에 국한되지 않으며 파이프라인에서 RGB 공간과 깊이 색 공간을 활용할 수 있는 유사한 렌더링 엔진 및 소프트웨어 내에서도 복제될 수 있다.
Results
1. Qualitative Evaluation
다음은 Stable Diffusion v1.4와 RGB 이미지를 비교하고 DPT-Large와 깊이 맵을 비교한 결과이다.

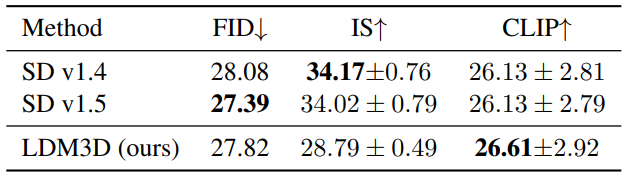
2. Quantitative Image Evaluation
다음은 512$\times$512 MS-COCO에서 평가한 text-to-image 합성 결과이다.
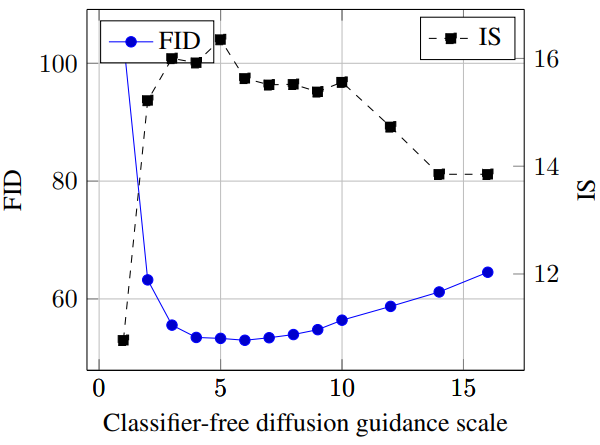
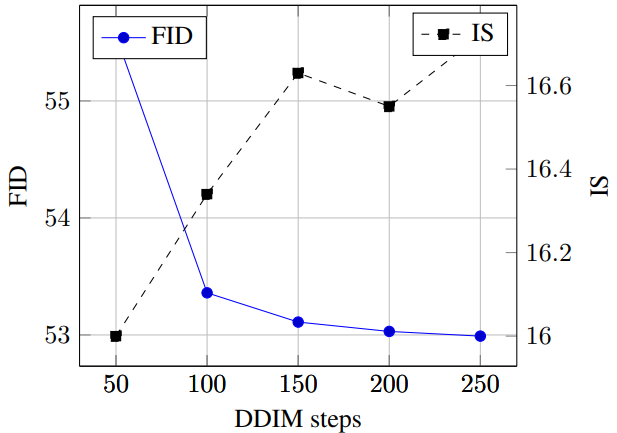
다음은 classifier-free guidance scale에 대한 FID와 IS를 나타낸 그래프이다.
다음은 DDIM step에 대한 FID와 IS를 나타낸 그래프이다.
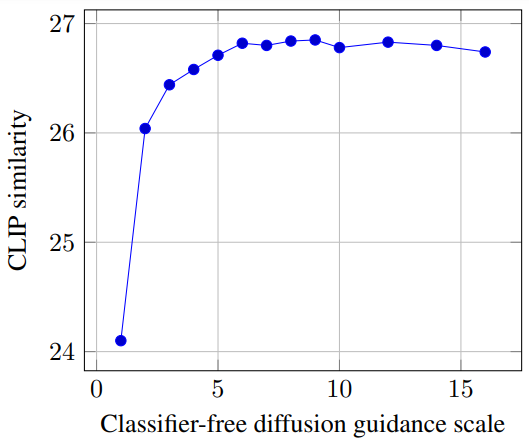
다음은 classifier-free guidance scale에 대한 CLIP 유사도 점수를 나타낸 그래프이다.
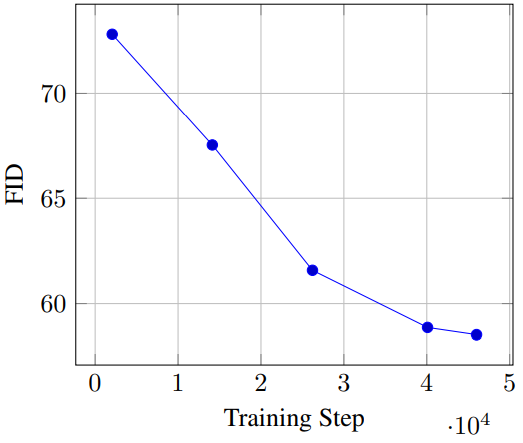
다음은 학습 step 수에 대한 FID를 나타낸 그래프이다.
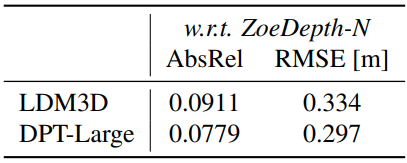
3. Quantitative Depth Evaluation
다음은 레퍼런스 모델인 ZoeDepth-N에 대한 깊이 평가 결과이다.
다음은 깊이 시각화 결과이다.

4. Autoencoder Performance
다음은 KL-AE fine-tuning 접근 방식을 비교한 결과이다.
