[논문리뷰] LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
ICCV 2023 (Oral). [Paper] [Page] [Github]
Koutilya Pnvr, Bharat Singh, Pallabi Ghosh, Behjat Siddiquie, David Jacobs
University of Maryland College Park | Vchar.ai | Amazon
22 Mar 2023
Introduction
텍스트 기반 image segmentation은 인페인팅, image matting, 언어 안내 편집 등과 같은 여러 이미지 편집 애플리케이션에 유용하다. 최근에는 합성 파이프라인에 대한 세밀한 제어가 필요한 여러 텍스트 기반 이미지 합성 워크플로우 내에서도 주목을 받고 있다. 그러나 객체의 경계를 정확하게 찾기 위해 네트워크를 학습시키는 것은 어렵고 인터넷 규모에서 경계에 주석을 다는 것은 비실용적이다. 또한 대부분의 self-supervision 또는 weak supervision 문제는 학습 경계를 장려하지 않는다. 예를 들어 분류 또는 캡션에 대한 학습을 통해 모델은 경계에 초점을 맞추지 않고 이미지의 가장 차별적인 부분을 학습할 수 있다. 저자들은 인터넷 규모에서 개체 레벨의 supervision 없이 학습될 수 있는 latent diffusion model(LDM)이 개체 경계에 주의를 기울여야 하므로 텍스트 기반 image segmentation에 유용한 feature를 학습할 수 있다는 가설을 세웠다. 저자들은 LDM이 표준 baseline에 비해 이 task의 성능을 최대 6%까지 향상시킬 수 있다는 것을 보여줌으로써 이 가설을 뒷받침하였다. 이러한 이득은 LDM 기반 segmentation 모델이 AI 생성 이미지에 적용될 때 더욱 증폭된다.
저자들은 사전 학습된 LDM 내부에 개체 레벨의 semantic 정보가 존재한다는 앞서 언급한 가설을 테스트하기 위해 간단한 실험을 수행하였다. Reverse process의 일부로 사전 학습된 LDM에서 unconditional noise 추정치와 텍스트 조건부 noise 추정치 사이의 pixel-wise norm을 계산하였다. 이 계산은 noisy한 입력이 해당 텍스트 조건에 더 잘 맞도록 수정해야 하는 공간 위치를 식별한다. 따라서 pixel-wise norm의 크기는 텍스트 프롬프트를 식별하는 영역을 나타낸다.
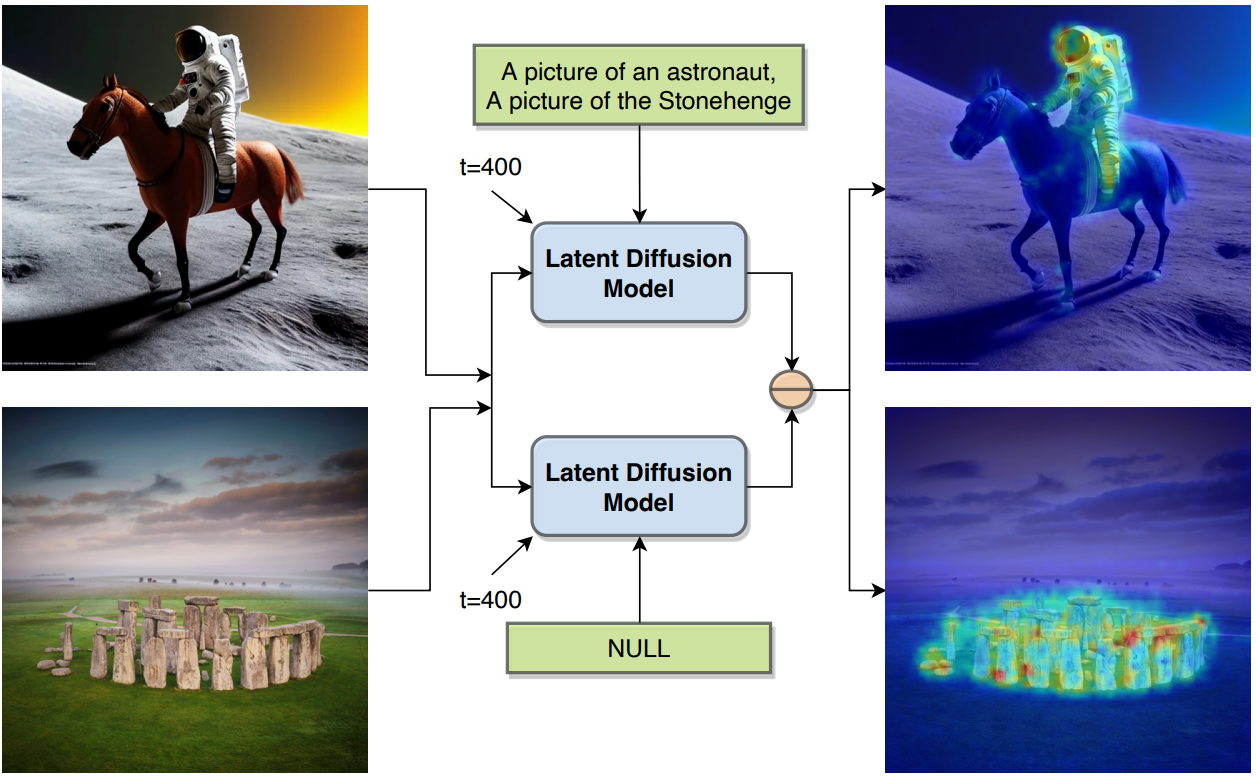
위 그림에서 볼 수 있듯이 pixel-wise norm은 LDM이 이 task에 대해 학습되지 않았지만 주제의 대략적인 segmentation을 나타낸다. 이것은 이러한 대규모 LDM이 시각적으로 만족스러운 이미지를 생성할 수 있을 뿐만 아니라 내부 표현이 segmentation과 같은 task에 유용할 수 있는 세분화된 semantic 정보를 인코딩한다는 것을 분명히 보여준다.
충실도가 높고, 사실적이고, 의미론적으로 의미 있는 text-to-image 합성을 위한 LDM의 성공은 주로 VQGAN에 의해 추출된 효율적으로 압축된 latent space $z$에 대한 의존도에 기인한다. 저자들은 실험에서 이 $z$가 원본 이미지에 비해 segmentation network에 더 나은 시각적 입력으로 작용하는 semantic 보존 압축 latent 표현임을 관찰하였다. $z$ space는 예술, 만화, 일러스트레이션, 실제 사진과 같은 여러 도메인에서 학습되기 때문에 AI 생성 이미지의 텍스트 기반 segmentation을 위한 보다 강력한 입력 표현이기도 하다. 또한 LDM의 내부 레이어는 이미지 구조 생성을 담당하므로 객체에 대한 풍부한 semantic 정보를 포함한다. 이러한 레이어의 soft mask는 이미지 편집에 대한 최근 연구들에서 latent 입력으로도 사용되었다. 이 정보는 이미지를 생성하는 동안 이미 존재하므로, 생성된 객체의 semantic 경계를 얻기 위해 이를 디코딩하는 LD-ZNet 형식의 아키텍처를 제안한다. 이 아키텍처는 AI 생성 이미지에서 개체의 segmentation에 도움이 될 뿐만 아니라 자연 이미지에 대한 성능도 향상된다.
LDMs for Text-Based Segmentation
Text-to-image latent diffusion아키텍처는 두 단계로 구성된다.
- 주어진 이미지에 대해 압축된 latent 표현 $z$를 추출하는 오토인코더 기반 VQGAN
- Forward process로 생성된 noisy한 $z$를 denoise하도록 학습된, 텍스트 feature로 컨디셔닝된 diffusion UNet
텍스트 feature는 사전 학습된 고정 CLIP 텍스트 인코더에서 가져오고 cross-attention을 통해 UNet의 여러 레이어에서 컨디셔닝된다.
본 논문에서는 저자들은 두 stage로 텍스트 기반 segmentation task의 성능 향상을 보여준다.
- 첫 번째 stage에서 압축된 latent space $z$를 분석하고 $z$를 시각적 입력으로 사용하여 텍스트 프롬프트에 따라 segmentation mask를 추정하는 ZNet이라는 접근 방식을 제안한다.
- 시각적-언어적 semantic 정보에 대한 stable-diffusion LDM의 두 번째 stage에서 내부 표현을 연구하고 segmentation task의 추가 개선을 위해 ZNet 내부에서 활용하는 방법을 제안한다. 이 접근 방식을 LD-ZNet이라고 한다.
1. ZNet: Leveraging Latent Space Features

LDM의 첫 번째 stage에서 latent space $z$는 위 그림과 같이 semantic 정보를 보존하는 이미지의 압축된 표현이다. 첫 번째 stage의 VQGAN은 대규모 학습 데이터와 loss의 조합(perceptual loss, patch 기반 adversarial loss,
KL-regularization loss)의 도움을 받아 이러한 semantic 보존 압축을 달성한다.
이 압축된 latent 표현 $z$가 텍스트 프롬프트와의 연관성 측면에서 원본 이미지에 비해 더 강력하다. 이는 $z$가 원본 이미지에 비해 요소가 48배 적은 $\frac{H}{8} \times \frac{W}{8} \times 4$ 차원 feature이며 semantic 정보를 보존하기 때문이다. 이전의 여러 연구들에서는 저차원 표현을 보존하는 정보를 생성하는 PCA와 같은 압축 기술이 더 잘 일반화됨을 보여주었다. 따라서 고정된 CLIP 텍스트 feature와 함께 $z$ 표현을 segmentation network에 대한 입력으로 사용한다.
또한 VQGAN은 예술, 만화, 일러스트레이션, 초상화 등과 같은 여러 도메인에서 학습되기 때문에 여러 도메인에서 더 잘 일반화되는 강력하고 간결한 feature를 학습한다. 이 접근 방식을 ZNet이라고 한다. ZNet의 아키텍처는 LDM의 denoising UNet 모듈과 동일하며, 따라서 LDM의 두 번째 stage의 사전 학습된 가중치로 초기화한다.
2. LD-ZNet: Leveraging Diffusion Features
텍스트 프롬프트와 timestep $t$가 주어지면 LDM의 두 번째 stage는 $t$ timestep 동안 forward process를 통해 얻은 latent 표현 $z$의 noisy한 버전인 $z_t$를 denoise하도록 학습된다. 일반적인 인코더/디코더 블록에는 내부적으로 self-attention이 있고 텍스트 feature와 함께 cross-attention이 있는 spatial-attention 모듈이 뒤따르는 residual layer가 포함되어 있다. 이러한 spatial-attention 모듈 바로 뒤에 인코더와 디코더의 서로 다른 블록에서 개발된 내부 시각적 언어 표현의 semantic 정보를 분석한다. 또한 ZNet segmentation network에 대한 cross-attention을 사용하여 이러한 latent diffusion feature를 활용하고, 최종 모델을 LD-ZNet이라고 한다.
Visual-Linguistic Information in LDM Features
저자들은 텍스트 기반 image segmentation task를 위해 다양한 블록과 timestep에서 사전 학습된 LDM에 존재하는 semantic 정보를 평가하였다. 이 실험에서는 UNet에 있는 모든 인코더와 디코더 블록에 걸쳐 있는 spatial-attention layer 1~16 바로 뒤에 latent diffusion feature를 고려한다. 각 블록에서 100번째 timestep마다 feature를 분석한다. Phrasecut 데이터셋의 training 및 validation set의 작은 부분집합을 사용하고 이러한 feature 위에 간단한 디코더를 학습하여 관련 binary mask를 예측한다.
구체적으로 이미지 $I$와 timestep $t$가 주어지면 먼저 LDM의 첫 번째 stage에서 latent 표현 $z$를 추출하고 forward diffusion에서 noise를 추가하여 $t$에 대한 $z_t$를 얻는다. 다음으로 텍스트 프롬프트에 대해 고정된 CLIP 텍스트 feature를 추출하고 LDM의 denoising UNet에 입력하여 해당 timestep의 모든 블록에서 내부 시각적 언어 feature를 추출한다. 이러한 표현을 사용하여 수렴될 때까지 해당 디코더를 학습한다. 마지막으로 validation 데이터셋의 작은 부분집합에서 AP metric을 평가한다. 다양한 블록과 timestep의 feature 성능은 아래 그림과 같다.
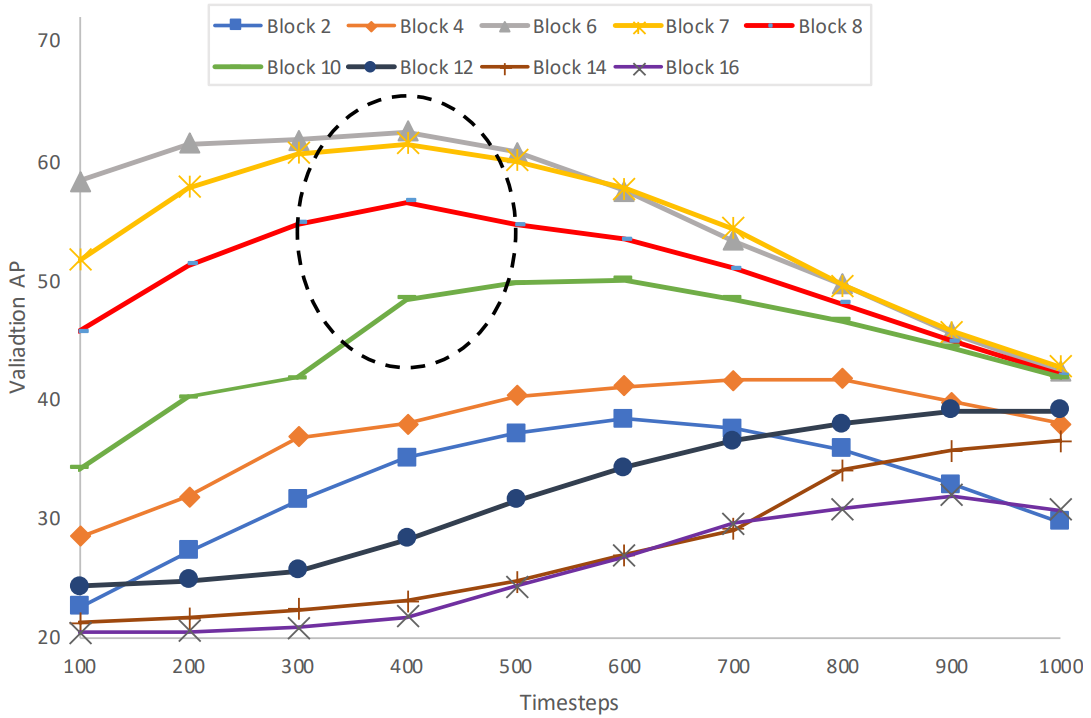
UNet의 중간 블록 \(\{6,7,8,9,10\}\)이 인코더의 초기 블록 또는 디코더의 이후 블록에 비해 더 많은 semantic 정보를 포함하고 있음을 관찰할 수 있다. 또한 timestep 300~500이 이러한 중간 블록에 대해 다른 timestep에 비해 가장 많은 시각적-언어적 semantic 정보를 포함하고 있음을 관찰할 수 있다. 이는 말이나 얼굴에 대한 few-shot semantic segmentation task를 위한 unconditional DDPM 모델에서 평가할 때 가장 유용한 정보를 포함하는 timestep이 \(\{50, 150, 250\}\)인 것과 대조된다. 이러한 차이가 나는 이유는 이미지 합성이 텍스트에 의해 유도되어 unconditional한 이미지 합성과 달리 reverse process에서 더 일찍 semantic 정보가 출현하기 때문이다.
LD-ZNet Architecture
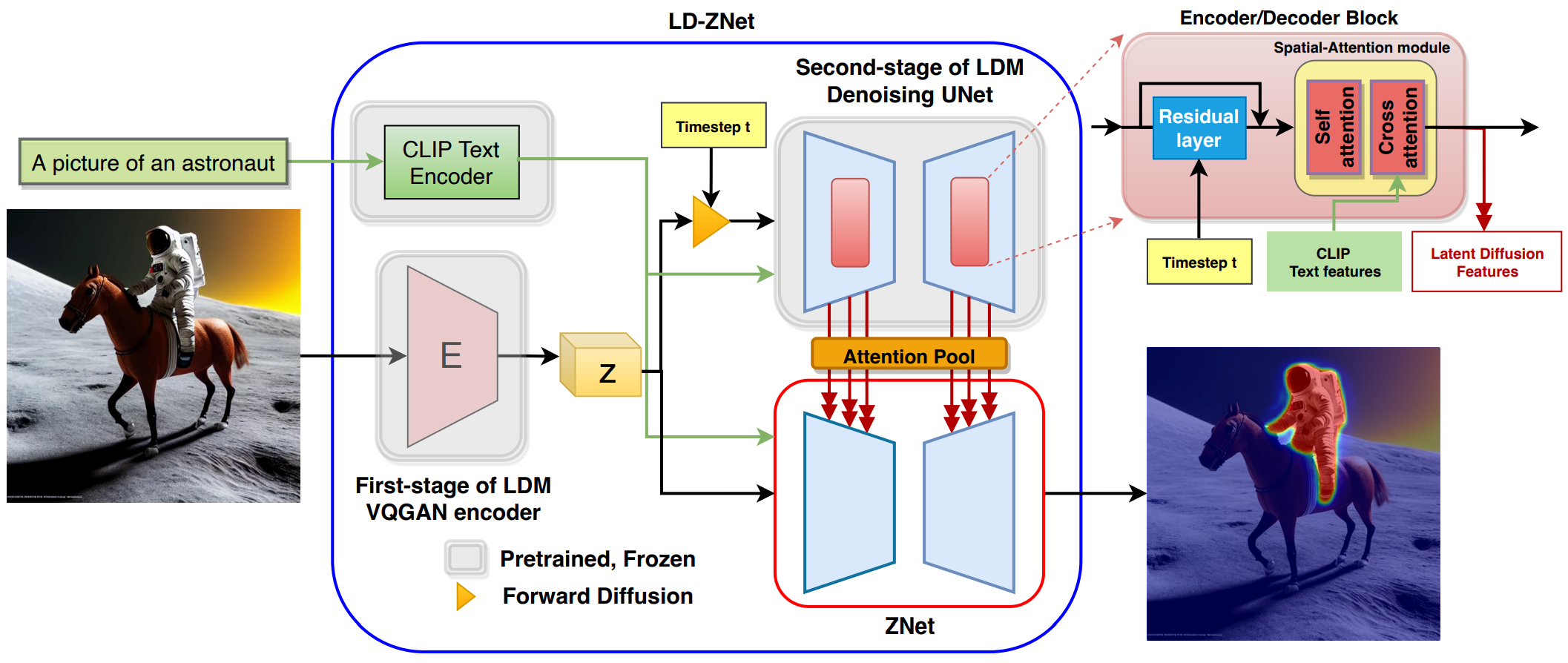
본 논문은 위 그림과와 같이 사전 학습된 LDM의 여러 spatial-attention 모듈에서 앞서 언급한 시각적 언어 표현을 ZNet에 사용하는 것을 제안한다.
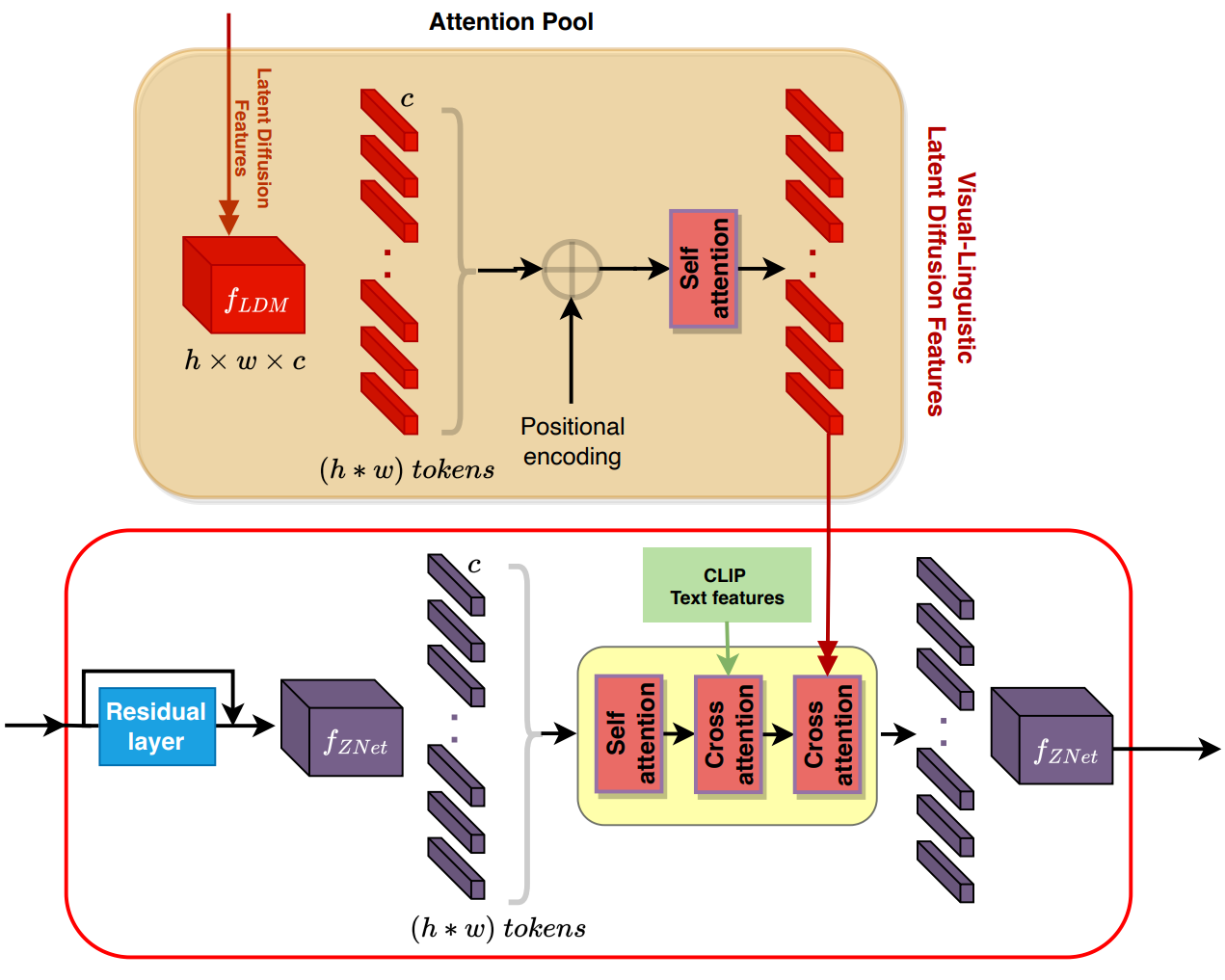
이러한 latent diffusion feature는 위 그림과 같이 해당 spatial-attention 모듈에서 cross-attention 메커니즘을 통해 ZNet에 주입된다. 이를 통해 ZNet과 LDM의 시각적 언어 표현 간의 상호 작용이 가능하다. 구체적으로 cross-attention에 참여하는 feature의 범위를 일치시키기 위해 학습 가능한 레이어로 작동할 뿐만 아니라 LDM 표현의 픽셀에 위치 인코딩을 추가하는 attention pool layer를 통해 latent diffusion feature를 전달한다. Attention pool의 출력은 제안된 cross-attention 메커니즘이 ZNet feature의 해당 픽셀에 attention을 할 수 있도록 하는 위치 인코딩된 시각적 언어 표현이다. LDM에서 이러한 latent diffusion feature로 보강된 ZNet을 LD-ZNet이라고 한다.
앞선 분석에 따라 LDM의 블록 \(\{6,7,8,9,10\}\)의 내부 feature를 ZNet의 해당 블록에 통합하여 LDM에서 가장 semantic하고 다양한 시각 언어 정보를 제공한다. AI 생성 이미지의 경우 이러한 블록은 어쨌든 최종 이미지를 생성하고 LD-ZNet을 사용하여 장면에서 개체를 분할하는 데 사용할 수 있는 이 정보를 활용할 수 있다.
Experiments
- 데이터셋: Phrasecut, AIGI (AI-generated images), RefCOCO, RefCOCO+, G-Ref
- Implementation details
- LDM: stable-diffusion v1.4
- 텍스트 인코더: ViT-L/14 CLIP text encoder
- optimizer: Adam
- learning rate: $5 \times 10^{-7}$
1. Image Segmentation Using Text Prompts
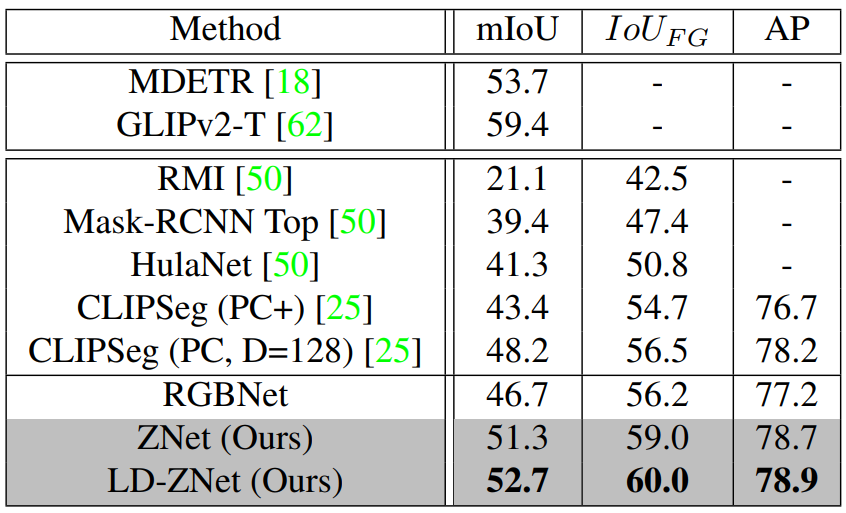
다음은 PhraseCut testset에서의 텍스트 기반 image segmentation 성능이다.
다음은 PhraseCut testset에서의 정성적 비교 결과이다.

2. Generalization to AI Generated Images
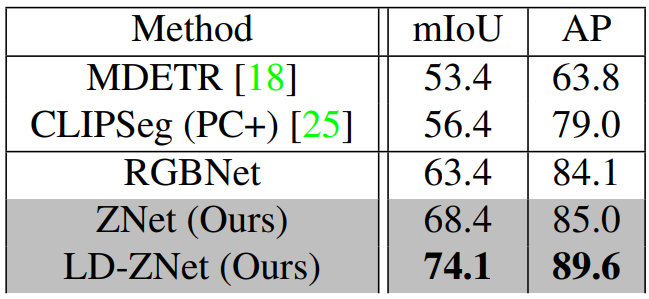
다음은 AIGI 데이터셋에서 LD-ZNet의 일반화 능력을 다른 SOTA 방법들과 비교한 표이다.
다음은 AIGI 데이터셋에서의 정성적 비교 결과이다.

3. Generalization to Referring Expressions
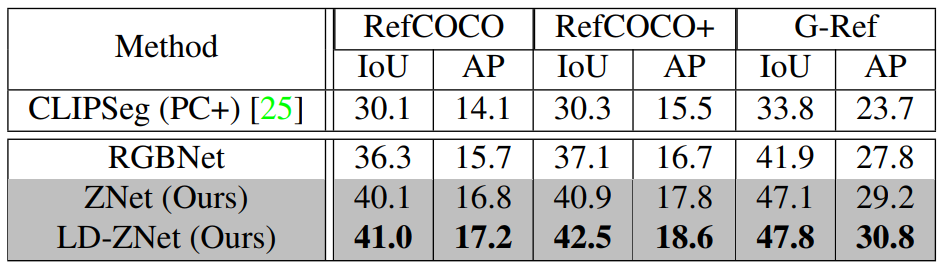
다음은 다른 데이터셋의 다양한 유형의 표현식에 대해 제안된 접근 방식의 일반화 능력을 비교한 표이다.
4. Cross-attention vs Concat for LDM features
다음은 LDM feature를 통합하는 방법에 대한 실험 결과이다.

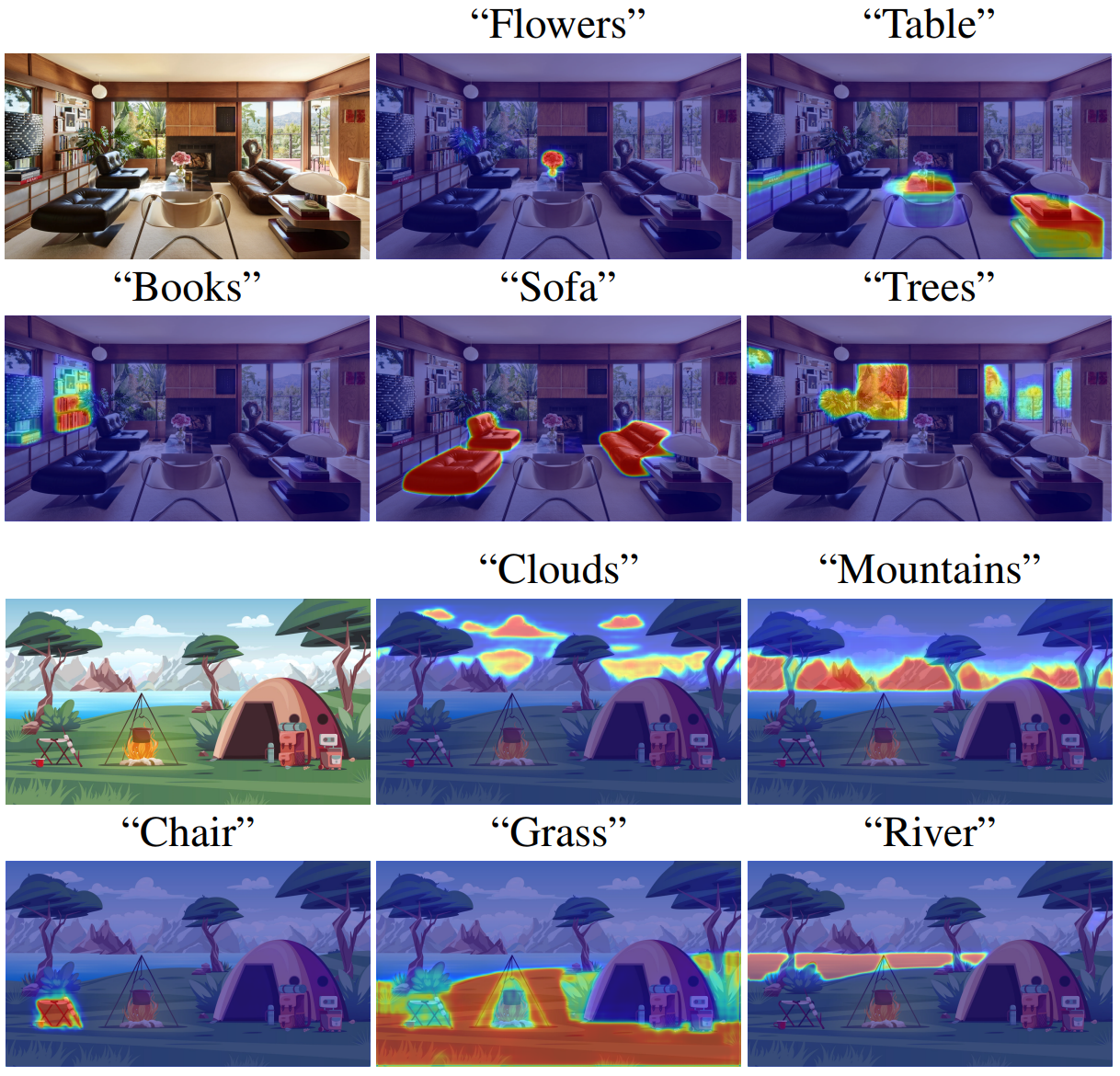
5. More Qualitative Results
다음은 AIGI 데이터셋에 대한 LD-ZNet의 다양한 결과들이다.

다음은 실제 이미지와 카툰에 대한 텍스트 기반 image segmentation 결과이다.