[논문리뷰] LangSplat: 3D Language Gaussian Splatting
CVPR 2024 (Highlight). [Paper] [Page] [Github]
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, Hanspeter Pfister
Tsinghua University | Harvard University
26 Dec 2023

Introduction
3D 언어 필드를 모델링하면 open-vocabulary를 사용하여 3D 월드와 상호 작용하고 쿼리할 수 있다. 그러나 언어 주석이 포함된 대규모의 다양한 3D 장면 데이터가 없기 때문에 기존 접근 방식들은 CLIP과 같은 기존 vision-language model에서 3D 장면으로의 feature distillation을 사용한다. 이러한 방법은 속도와 정확성 모두에서 제한을 받아 실제 적용 가능성이 제한된다. 이 두 가지 문제를 해결하기 위해 본 논문은 3D 언어 필드 모델링의 두 가지 주요 측면, 즉 2D와 3D 사이의 격차를 해소하는 3D 모델링 접근 방식과 3D 포인트에 대해 학습할 내용을 결정하는 렌더링 대상을 다시 살펴보았다.
CLIP 임베딩은 픽셀이 아닌 이미지와 정렬되므로 3D 포인트에 대한 CLIP 임베딩을 학습하는 것이 모호할 수 있다. 자른 패치에서 CLIP 임베딩을 사용하면 동일한 3D 위치가 다양한 규모의 semantic 개념과 연관될 수 있으므로 모호성 문제가 발생한다. 예를 들어, 곰의 코에 위치한 포인트는 “곰의 코”, “곰의 머리”, “곰”이라는 세 가지 고유한 텍스트 쿼리에 대해 높은 응답 값을 생성해야 한다.
이 문제를 해결하기 위해 현재 방법은 NeRF에 스케일 입력을 도입하고, 다양한 스케일에서 패치별 CLIP feature를 사용하여 학습하고, 최적의 맵을 선택하기 위해 쿼리하는 동안 여러 스케일에서 2D map을 dense하게 렌더링한다. 그러나 이 스케일 기반 솔루션은 효율성과 성능을 모두 저하시킨다. 다양한 스케일로 렌더링해야 하므로 쿼리 시간이 최대 30배까지 늘어날 수 있다. 또한, 다양한 스케일을 가진 대부분의 패치는 종종 배경의 다른 물체를 포함하거나 대상 물체의 일부를 생략하는 등 물체를 정확하게 포함하지 못한다. 부정확한 CLIP feature로 인해 학습된 3D 언어 필드에는 명확한 경계가 부족하고 상당한 양의 잡음이 포함된다. 이 문제를 완화하기 위해 픽셀 정렬된 DINO feature를 동시에 학습하는 경우가 많지만 성능은 여전히 만족스럽지 않다.
본 논문에서는 위와 같은 문제를 해결하기 위해 3D Language Gaussian Splatting (LangSplat)을 제안하였다. 3D 표현을 구축하기 위해 NeRF 대신 3D Gaussian Splatting을 사용한다. LangSplat은 3D language Gaussian을 정의하며, 각 Gaussian은 언어 임베딩을 통해 강화된다. Gaussian들은 여러 학습 뷰에서 캡처한 이미지 패치에서 추출된 CLIP 임베딩을 사용하여 supervise되므로 멀티뷰 일관성이 보장된다.
각 Gaussian에 고차원의 언어 임베딩을 직접 저장하는 것은 메모리 비효율적이다. 메모리 비용을 줄이고 렌더링 효율성을 더욱 향상시키기 위해 먼저 장면의 CLIP 임베딩을 저차원 latent space에 매핑하는 장면별 언어 오토인코더를 학습시킨다. 이러한 방식으로 각 Gaussian들에는 저차원의 언어 latent feature만 포함되며 렌더링된 feature를 디코딩하여 최종 언어 임베딩을 얻는다.
모호성 문제를 해결하기 위해 Segment Anything Model (SAM)에 의해 정의된 semantic 계층 구조를 사용한다. 각 2D 이미지에 대해 SAM을 사용하여 여러 semantic level에서 잘 분할된 3개의 map을 얻는다. 그런 다음 정확한 경계 마스크의 CLIP feature를 추출하고 이 feature 해당 마스크의 모든 점에 할당한다. SAM 기반 마스크를 사용한 학습은 각 점에 정확한 CLIP 임베딩을 제공하여 모델 정확도를 높일 뿐만 아니라 사전 정의된 세 가지 semantic 스케일에서 직접 쿼리를 가능하게 한다. 이를 통해 여러 스케일과 보조 DINO feature에 대한 집중적인 검색이 필요하지 않으므로 효율성이 효과적으로 향상된다.
Proposed Approach
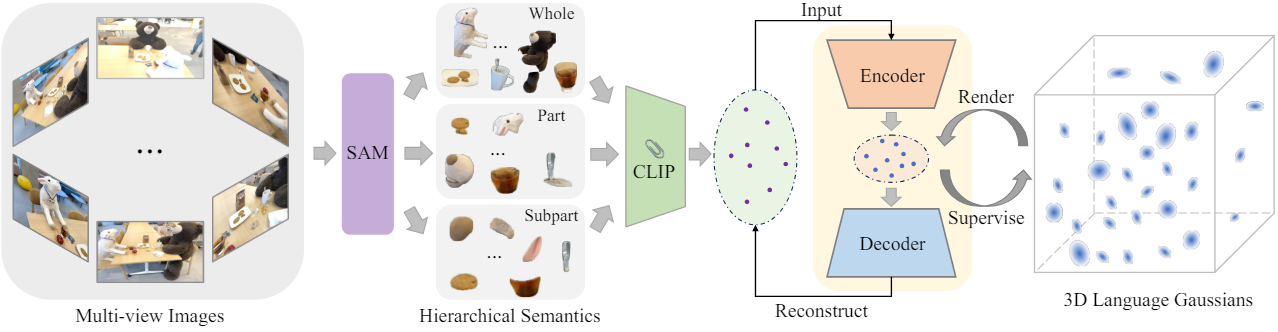
1. Learning Hierarchical Semantics with SAM
Image segmentation을 위한 foundation model인 SAM은 동일한 물체에 속하는 주변 픽셀과 함께 픽셀을 정확하게 그룹화할 수 있으므로 경계가 명확한 여러 마스크로 이미지를 분할할 수 있다. 또한 SAM은 포인트 프롬프트에 대해 세 가지 계층적 semantic level을 나타내는 whole, part, subpart라는 세 가지 다른 마스크를 생성하여 모호성을 해결한다. 따라서 SAM을 활용하여 정확한 마스크를 얻은 다음 픽셀 정렬된 feature를 얻는 데 사용한다. 또한 모호성 문제를 해결하기 위해 SAM이 정의한 semantic 계층 구조를 명시적으로 모델링한다. 이를 통해 각 입력 이미지에 대해 정확한 멀티스케일 segmentation map을 제공할 수 있다.
32$\times$32 포인트 프롬프트의 그리드를 SAM에 입력하여 세 가지 다른 semantic level에서 마스크 $M_0^s$, $M_0^p$, $M_0^w$를 얻는다 (각각 subpart, part, whole). 그런 다음 예측된 IoU score, 안정성 점수, 마스크 간 중복률을 기반으로 3개의 마스크 집합 각각에 대해 중복 마스크를 제거한다. 필터링된 각 마스크 집합은 전체 이미지를 독립적으로 분할하여 $M^s$, $M^p$, $M^w$의 세 가지 segmentation map을 생성한다. 획득한 segmentation map을 사용하여 분할된 각 영역에 대한 CLIP feature를 추출한다. 이러한 feature들은 장면 내의 다양한 레벨에서 물체들의 semantic context를 캡처한다.
Semantic level $l$에서 픽셀 $v$의 언어 임베딩은 다음과 같다.
\[\begin{equation} \mathcal{L}_t^l (v) = V (I_t \odot M^l (v)), \quad l \in \{s, p, w\} \end{equation}\]3D 장면에서 렌더링된 각 픽셀은 이제 정확한 semantic context에 맞춰 조정되는 CLIP feature를 갖는다. 이러한 정렬은 모호성을 줄이고 언어 기반 쿼리의 정확성을 향상시킨다. SAM 기반 접근 방식의 또 다른 장점은 사전 정의된 semantic scale이며, 각 scale에서 3D 언어 필드를 직접 쿼리할 수 있다. 이렇게 하면 여러 스케일에 걸쳐 집중적인 검색이 필요하지 않으므로 쿼리 프로세스가 더욱 효율적이 된다.
2. 3D Gaussian Splatting for Language Fields
2D 이미지 세트 \(\{L_t^l \; \vert \; t = 1, \ldots, T\}\)에 대한 언어 임베딩을 얻은 후 3D 점과 2D 픽셀 간의 관계를 모델링하여 3D 언어 장면을 학습할 수 있다. 오래 걸리는 NeRF 대신 3D 언어 필드 모델링을 위해 3D Gaussian Splatting을 사용한다.
본 논문에서는 세 가지 언어 임베딩 \(\{f^s, f^p, f^w\}\)로 각 3D Gaussian을 강화하는 3D language Gaussian Splatting을 제안하였다. 이러한 임베딩은 SAM에서 제공하는 계층적 semantic을 캡처하는 CLIP feature에서 파생된다. 렌더링 효율성을 유지하기 위해 타일 기반 rasterizer를 채택한다.
Semantic level $l$에서 픽셀 $v$의 렌더링된 언어 임베딩은 다음과 같다.
\[\begin{equation} F^l (v) = \sum_{i \in N} f_i^l \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j), \quad l \in \{s, p, w\} \end{equation}\]언어 정보를 Gaussian에 직접 통합함으로써 3D 언어 필드가 언어 기반 쿼리에 응답할 수 있다.
LangSplat은 복잡한 3D 장면을 모델링하기 위해 수백만 개의 3D 포인트를 생성할 수 있다. CLIP 임베딩은 고차원 feature이므로 CLIP latent space에서 $f^l$을 직접 학습시키면 메모리와 시간 비용이 크게 늘어난다. 512차원의 CLIP feature를 학습하면 3D Gaussian을 저장하는 데 필요한 메모리 요구 사항이 35배 이상 증가하여 메모리가 쉽게 부족해진다.
메모리 비용을 줄이고 효율성을 높이기 위해 장면별 언어 오토인코더를 도입한다. 이 오토인코더는 장면의 CLIP 임베딩을 저차원 latent space에 매핑하여 메모리 요구 사항을 줄인다. CLIP 모델은 4억 개의 이미지-텍스트 쌍을 사용하여 학습되었으며 $D$차원 latent space에서 임의의 텍스트와 이미지를 정렬해야 하기 때문에 매우 컴팩트할 수 있다. 그러나 여기서 학습하는 언어 필드 $\Phi$는 장면별로 다르다. 실제로 각 입력 이미지에 대해 SAM으로 분할된 수백 개의 마스크를 얻게 되는데, 이는 CLIP 학습에 사용되는 이미지 수보다 훨씬 적다. 따라서 장면의 모든 분할된 영역은 CLIP latent space에 sparse하게 분포되어 장면별 오토인코더를 사용하여 이러한 CLIP feature를 더욱 압축할 수 있다.
구체적으로, SAM segmentation mask의 CLIP feature 모음 \(\{L_t^l\}\)을 사용하여 가벼운 오토인코더를 학습시킨다. 인코더 $E$는 $D$차원 CLIP feature $L_t^l (v) \in \mathbb{R}^D$를 $H_t^l (v) = E(L_t^l (v)) \in \mathbb{R}^d$로 매핑한다 ($d \ll D$). 그런 다음 디코더 $\Psi$를 학습하여 압축된 표현의 원본 CLIP 임베딩으로 재구성한다. 오토인코더는 CLIP 임베딩에 대한 재구성 목적 함수로 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{ae} = \sum_{l \in \{s, p, w\}} \sum_{t=1}^T d_\textrm{ae} (\Psi (E (L_t^l (v))), L_t^l (v)) \end{equation}\]여기서 $d_\textrm{ae}$는 오토인코더를 위한 distance function이며, 저자들은 L1 loss와 cosine distance loss를 모두 채택하였다.
오토인코더를 학습시킨 후 모든 CLIP 임베딩 \({L_t^l}\)을 장면별 latent feature \(\{H_t^l\}\)로 변환한다. 그리고 CLIP latent space 대신 장면별 latent space에서 언어 임베딩을 학습하도록 한다. 즉, $f^l \in \mathbb{R}^d$가 된다. 저자들은 $d = 3$을 선택했다. 다음과 같은 목적 함수를 가지고 언어 임베딩을 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{lang} = \sum_{l \in \{s, p, w\}} \sum_{t=1}^T d_\textrm{lang} (F_t^l (v), H_t^l (v)) \end{equation}\]여기서 $d_\textrm{lang}$은 Gaussian들을 위한 distance function이다.
Inference 시에는 언어 임베딩을 3D에서 2D로 렌더링한 다음 장면별 디코더 $\Psi$를 사용하여 CLIP 이미지 임베딩 $\Psi (F_t^l) \in \mathbb{R}^{D \times H \times W}$를 복구한다. 이를 통해 CLIP 텍스트 인코더를 사용한 open-vocabulary 쿼리가 가능해진다.
3. Open-vocabulary Querying
CLIP 모델이 제공하는 이미지와 텍스트 사이의 잘 정렬된 latent space로 인해 학습된 3D 언어 필드는 open-vocabulary 3D 쿼리를 쉽게 지원할 수 있다. 기존의 많은 open-vocabulary 3D semantic segmentation 방법은 일반적으로 카테고리 목록에서 카테고리 선택하므로 장면에 대한 포괄적인 카테고리 목록을 얻는 것은 어렵다. 이와 다르게 LangSplat은 임의의 텍스트 쿼리가 주어지면 정확한 객체 마스크를 생성한다.
LERF를 따라 각 텍스트 쿼리에 대한 관련성 점수를 계산한다. 구체적으로, 각 렌더링된 언어 임베딩 $\phi_\textrm{img}$와 각 텍스트 쿼리 $\phi_\textrm{qry}$에 대해 관련성(relevancy) 점수는 다음과 같이 정의된다.
\[\begin{equation} \min_i \frac{\exp (\phi_\textrm{img} \cdot \phi_\textrm{qry})}{\exp (\phi_\textrm{img} \cdot \phi_\textrm{qry}) + \exp (\phi_\textrm{img} \cdot \phi_\textrm{canon}^i)} \end{equation}\]여기서 $\phi_\textrm{canon}^i$은 “object”, “things”, “stuff”, “texture”에서 선택된 미리 정의된 표준 문구의 CLIP 임베딩이다. 따라서 각 텍스트 쿼리에 대해 각각 특정 semantic level의 결과를 나타내는 세 개의 relevancy map을 얻는다. 그리고 가장 높은 관련성 점수를 산출하는 semantic level을 선택한다. 3D object localization task의 경우 관련성 점수가 가장 높은 포인트를 바로 선택한다. 3D semantic segmentation task의 경우 선택한 임계값보다 낮은 관련성 점수를 가진 포인트를 필터링하고 남은 포인트들을 객체 마스크로 예측한다.
Experiments
- 데이터셋: LERF dataset, 3D-OVS dataset
- 구현 디테일
- CLIP: OpenCLIP ViT-B/16
- SAM: ViT-H
- 오토인코더: MLP (512차원 $\rightarrow$ 3차원)
- 먼저 RGB scene을 3만 iteration 동안 학습시킨 후 파라미터를 고정시키고 언어 feature들을 추가 3만 iteration 동안 학습
- 해상도: 1440$\times$1080
- 학습은 NVIDIA RTX3090에서 25분/4GB 메모리 소요
1. Results on the LERF dataset
Quantitative Results
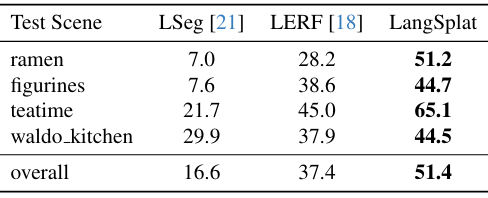
다음은 LERF 데이터셋에서의 localization 정확도(왼쪽)와 3D semantic segmentation에 대한 평균 IoU(오른쪽)이다. (% 생략)
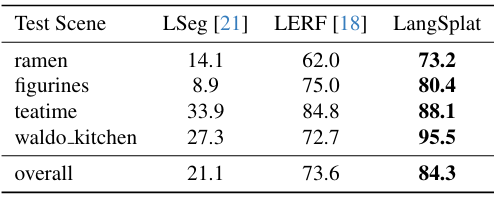
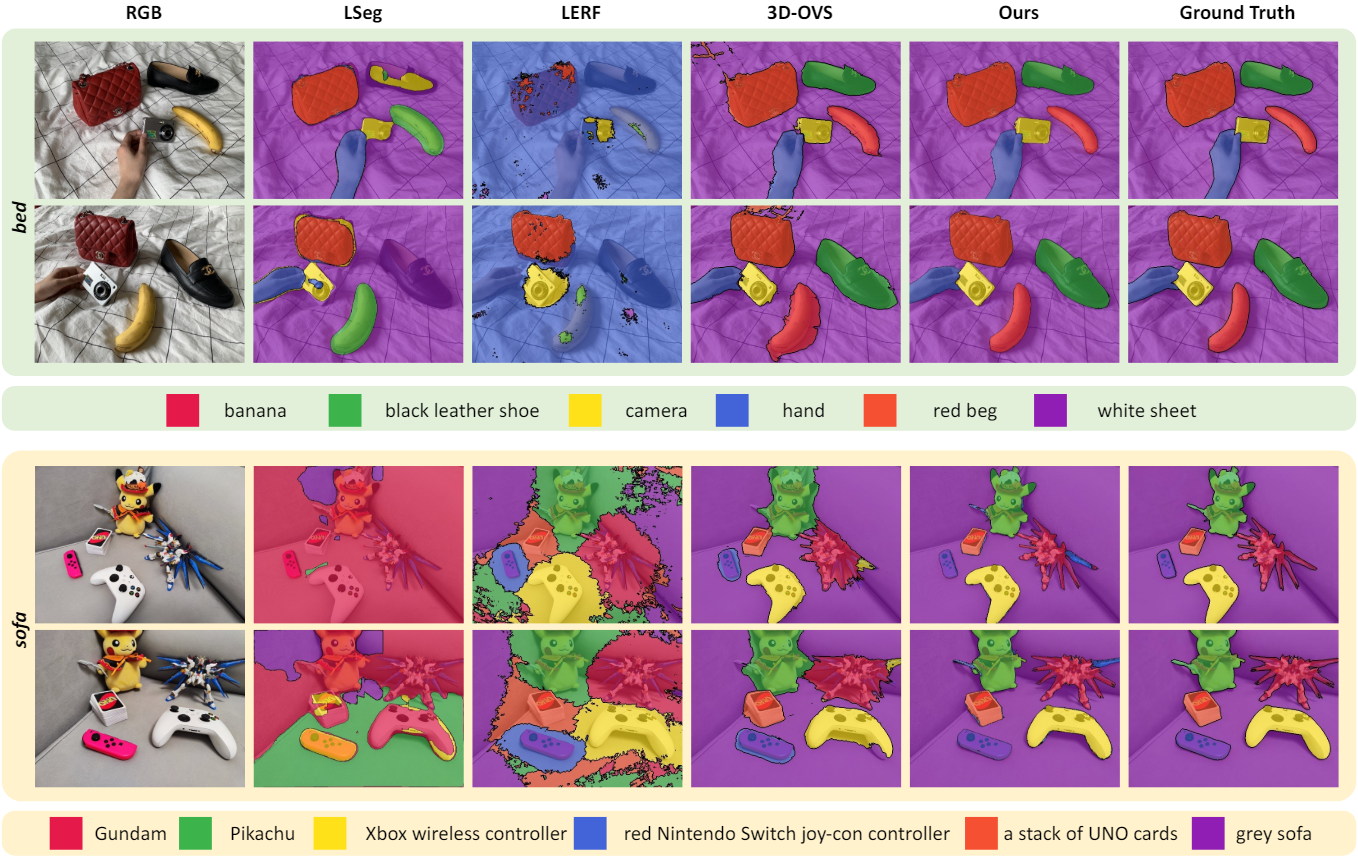
다음은 LERF 데이터셋에서의 open-vocabulary 3D object localization 결과이다.

다음은 LERF 데이터셋에서의 open-vocabulary 3D semantic segmentation 결과이다.

2. Results on the 3D-OVS dataset
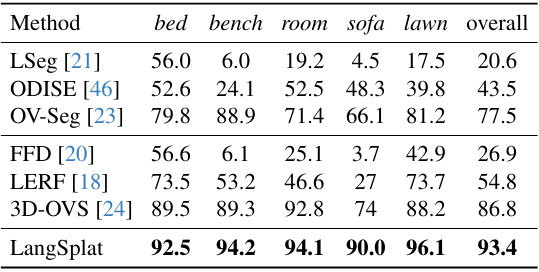
다음은 3D-OVS 데이터셋에서 여러 기존 방법들과 결과를 비교한 것이다. (표는 mIoU(%)를 비교)
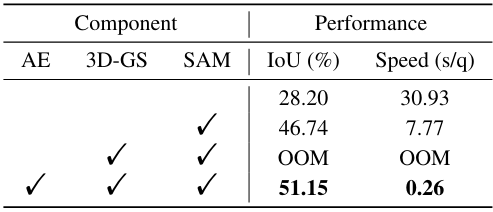
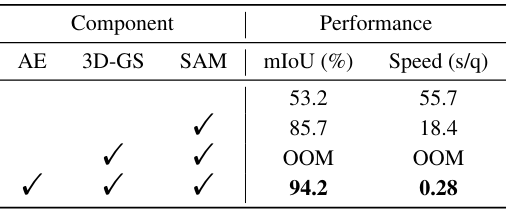
3. Ablation
다음은 LERF 데이터셋(왼쪽)과 3D-OVS 데이터셋(오른쪽)에서의 ablation 결과이다.