[논문리뷰] LaMD: Latent Motion Diffusion for Video Generation
arXiv 2023. [Paper]
Yaosi Hu | Zhenzhong Chen | Chong Luo
Wuhan University | Microsoft Research Asia
23 Apr 2023
Introduction
동영상 생성은 인간의 의도를 정확하게 반영하는 자연스럽고 고품질의 동영상을 생성하는 것을 목표로 한다. 지속적인 노력에도 불구하고 이 분야는 아직 이 목표를 완전히 달성하지 못했다. 동영상 생성 문제에 대한 기존의 간단한 솔루션 중 하나는 동영상의 각 프레임에 대한 픽셀 값을 직접 생성하는 심층 모델을 학습시키는 것이다. 그러나 동영상 데이터의 양이 너무 많아 모델을 효과적으로 학습하는 것이 어렵고 이러한 효율성 부족에는 두 가지 의미가 있다.
- 학습 절차에는 모델의 확장성을 방해할 수 있는 상당한 계산 리소스가 필요하다.
- Generator가 인간의 시각 시스템에 덜 눈에 띄는 공간 고주파수 디테일에 너무 집중하게 만들 수 있다.
따라서 지각적으로 관련된 정보에 초점을 맞춘 동영상을 효율적이고 효과적으로 생성할 수 있는 새로운 동영상 생성 프레임워크를 개발하는 것이 필수적이다.
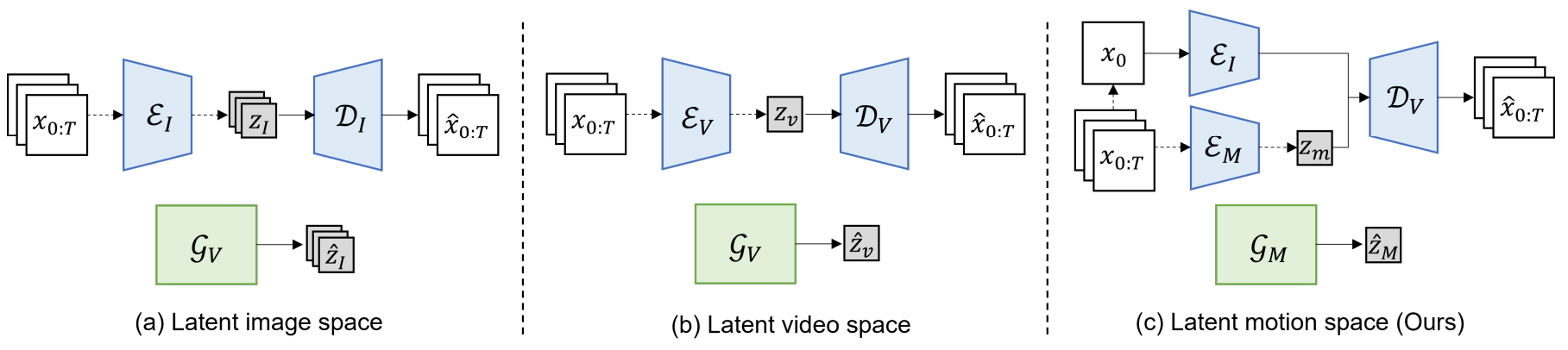
Pixel-space 생성 접근 방식에 대한 대안으로 latent-space 생성은 모델 학습 중에 데이터 중복을 줄이고 리소스를 절약하기 위해 선호되는 선택이 되었다. 이것은 사전 학습된 오토인코더를 사용하여 생성 프로세스를 픽셀 도메인에서 보다 효율적이고 압축된 latent 도메인으로 전송함으로써 달성한다. 현재 latent space 동영상 생성은 latent space의 대응에 따라 두 가지 일반적인 패러다임을 따른다. 위 그림의 (a)에 묘사된 첫 번째 패러다임은 이미지 오토인코더를 사용하여 각 프레임을 latent 토큰으로 변환하여 동영상 생성 문제를 latent space의 이미지 생성 문제로 효과적으로 단순화한다. 위 그림의 (b)에 묘사된 두 번째 패러다임은 3D 동영상 오토인코더를 사용하여 동영상 클립을 latent space로 변환한 다음 이 latent video space 내에서 콘텐츠를 생성한다.
Latent space 동영상 생성을 위한 이 두 가지 패러다임은 각각 고유한 강점과 약점을 가지고 있다. 첫 번째 패러다임은 latent space 이미지 생성의 최근 발전을 활용하고 고품질의 의미론적으로 정확한 프레임을 생성할 수 있다. 그러나 2D 이미지 오토인코더는 프레임 간의 시간적 관계를 고려하지 않기 때문에 생성된 프레임 컬렉션은 시간적으로 일관성이 없고 움직임을 정확하게 묘사하지 못할 수 있다. 반대로 두 번째 패러다임은 동영상 클립에서 latent video 도메인으로의 시공간 압축을 구현하여 모션 일관성 문제를 극복한다. 그럼에도 불구하고 3D 시공간 정보가 필요한 동영상 latent space를 모델링하는 것은 상당한 과제를 안고 있다.
이 문제를 해결하려면 동영상에서 가장 지각적으로 관련된 정보를 모델링하는 데 집중하는 것이 중요하다. 이미지 생성에 비해 동영상 생성의 성능이 떨어지는 것은 동영상에서 일관되고 자연스러운 움직임을 생성하기 어렵기 때문이다. 동영상의 시각적 외형과 모션 구성 요소를 분리함으로써 특히 모션 생성에 집중할 수 있다. 이 아이디어는 위 그림의 (c)에 묘사된 것처럼 latent motion space에서 생성 문제를 해결하기 위한 새로운 패러다임에 대한 본 논문의 설계를 뒷받침한다. Latent video space 더 작은 latent motion space를 사용하면 모델링 복잡도가 줄어든다. 이 접근 방식은 Image-to-Video(I2V)와 Text-Image-to-Video(TI2V) 생성을 직접 대상으로 하며 추가된 T2I(Text-to-Image) 생성으로 T2V(Text-to-Video) 생성 문제도 해결할 수 있다.
본 논문에서는 Latent Motion Generation 패러다임의 실질적인 구현을 나타내는 Latent Motion Diffusion (LaMD) 프레임워크를 제시한다. LaMD 프레임워크는 Motion-Content Decomposed Video Autoencoder (MCD-VAE)와 diffusion-based motion generator (DMG)의 두 가지 구성 요소로 구성된다. MCD-VAE는 멀티스케일 이미지 인코더, information bottleneck을 사용하는 가벼운 모션 인코더, 동영상 재구성을 위한 디코더를 활용하여 모양이나 콘텐츠에서 모션을 분리하는 문제를 해결한다. DMG 모듈은 Diffusion Model (DM)의 매우 효과적인 생성 성능의 영향을 받는다. 연속적인 latent space에서 모션 변수를 점진적으로 denoise하고 미리 얻은 콘텐츠 feature와 선택적 텍스트를 multimodal 조건으로 통합할 수도 있다. DMG 모듈의 계산 복잡도는 이미지 diffusion model과 유사하므로 다른 동영상 diffusion model에 비해 리소스 활용도가 감소하고 샘플링 속도가 빨라진다.
Method
모션의 본질은 궤적과 같이 프레임을 가로지르는 역동적인 움직임에 있다. 이러한 움직임은 공간적 차원과 시간적 차원 모두에서 매우 중복되며 콘텐츠와 자연스럽게 분리될 수 있다. 따라서 latent motion space에서 동영상 생성을 지원하기 위해 먼저 콘텐츠와 모션의 표현을 분리하고 융합하여 동영상을 재구성하는 motion-content decomposed video autoencoder (MCD-VAE)를 설계한다. 그런 다음 제안된 diffusion-based motion generator (DMG)는 텍스트와 같은 다른 선택적 조건을 사용하여 미리 얻은 콘텐츠 feature를 조건으로 하는 콘텐츠별 motion latent를 생성하는 것을 목표로 한다.
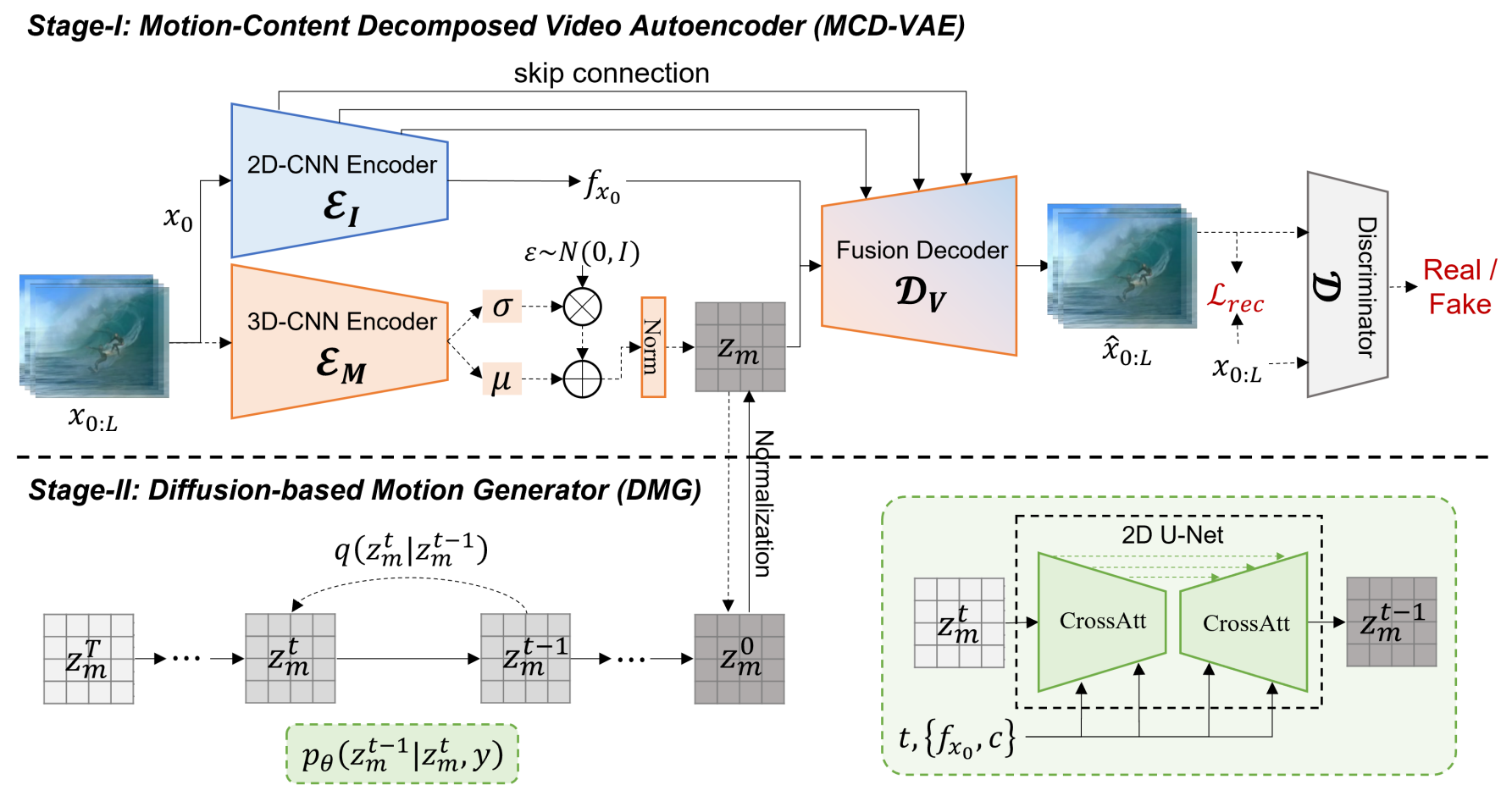
2단계 접근법 LaMD는 위 그림과 같이 설명된다. 학습 중에 먼저 동영상 전용 데이터를 사용하여 MCD-VAE를 학습시키고 해당 파라미터를 고정한 다음 latent space에서 DMG를 학습시킨다. 샘플링하는 동안 DMG는 주어진 이미지 및 기타 선택적 조건에서 추출된 콘텐츠 feature에 따라 정규 분포에서 점진적으로 motion latent를 생성한다. 그런 다음 이러한 motion latent를 MCD-VAE 디코더에 입력하여 동영상을 합성한다.
1. Motion-Content Decomposed Video Autoencoder
이미지 기반 동영상 생성을 목표로 하는 모션 구성 요소는 공간 및 시간 차원에서 높은 중복성으로 인해 크게 압축될 수 있으며 더 많은 콘텐츠 정보를 보존하면 재구성 품질을 향상시키는 데 도움이 된다. 따라서 각각 다른 압축 전략을 사용하는 두 개의 개별 인코더를 사용하여 모션 및 콘텐츠 feature를 추출한다.
MCD-VAE는 2D-CNN 기반 이미지 인코더 \(\mathcal{E}_I\), 3D-CNN 기반 모션 인코더 \(\mathcal{E}_M\), 퓨전 디코더 \(\mathcal{D}_V\)로 구성된다. $L$ 프레임을 포함하는 동영상 \(x_{0:L} \in \mathbb{R}^{L \times H \times W \times 3}\)이 주어지면, 2D UNet 아키텍처에 기반한 \(\mathcal{E}_I\)는 먼저 첫 번째 프레임 $x_0$를 콘텐츠 latent $f_{x_0} \in \mathbb{R}^{h \times w \times d’}$로 인코딩한다. 또한 중간 멀티스케일 표현 $f_{x_0}^1, \cdots, f_{x_0}^k$를 중간 표현으로 인코딩한다. 여기서 $k$는 스케일의 수를 나타낸다.
\[\begin{equation} \{f_{x_0}, f_{x_0}^1, \cdots, f_{x_0}^k\} = \mathcal{E}_I (x_0) \end{equation}\]한편, 모션 인코더 $\mathcal{E}_M$은 각각의 공간적 및 시간적 downsampling factor $f_s$, $f_t$를 갖는 3D UNet 아키텍처를 기반으로 동영상에서 motion latent를 추출한다. 모션 표현을 분해하려면 motion branch에 추가 제약 조건이 필요하다. 여기서 latent motion 분포와 정규 분포 사이의 KL divergence에 제약을 가하는 information bottleneck을 사용한다. 이 KL divergence에 해당하는 페널티로 bottleneck의 크기를 제어함으로써 모션 인코더는 콘텐츠 정보를 짜내고 모션을 분해할 수 있다. 이 프로세스는 다음과 같이 parameterize된다.
\[\begin{equation} z_m = \mu_\theta (\mathcal{E}_M (x_{0:T})) + \epsilon \cdot \sigma_\theta (\mathcal{E}_M (x_{0:L})), \quad \epsilon \sim \mathcal{N}(0,I) \end{equation}\]또한 latent space의 더 작은 manifold가 나중 generator의 모델링에 도움이 된다는 점을 고려하여 얻은 latent motion $z_m$은 정규화 layer을 통과하여 diffusion 기반 생성 모델의 학습 안정성과 효율성을 효과적으로 개선한다. $f_t = L$로 설정한다는 점은 시간적 중복성이 완전히 폐기됨을 의미한다. 따라서 $h = H / f_s$, $w = W / f_s$인 경우 latent motion 표현은 $z_m \in \mathbb{R}^{h \times w \times d}$로 상당히 콤팩트하고 차원이 낮다.
디코더는 콘텐츠와 모션을 융합하여 동영상 픽셀을 재구성하는 것을 목표로 한다. 3D UNet 디코더는 먼저 공간적으로 정렬된 motion latent를 가장 깊은 콘텐츠 feature와 융합한 다음 skip connection을 통해 점진적으로 멀티스케일 콘텐츠 feature를 통합한다. 융합하는 동안 전체 동영상을 합성할 때까지 공간 및 시간 해상도가 점차 증가한다.
\[\begin{equation} \hat{x}_{0:L} = \mathcal{D}_V (z_m, f_{x_0}, f_{x_0}^1, \cdots, f_{x_0}^k) \end{equation}\]목적 함수에는 $L_1$ 픽셀 레벨 거리와 LPIPS perceptual similarity loss를 결합한 재구성 loss와 KL divergence와 hyperparameter $\beta$가 포함되어 motion latent의 명확한 분해를 제어한다. 또한, 재구성의 사실성을 향상시키기 위해 동영상 discriminator $\mathcal{D}$를 통해 적대적 목적 함수를 적용한다. 따라서 전체 목적 함수는 다음과 같다.
\[\begin{aligned} \underset{\mathcal{E}_I, \mathcal{E}_M, \mathcal{D}_V}{\arg \min} & \max_{\mathcal{D}} \mathbb{E}_{x \sim p(x)} [\mathcal{L}_{GEN} + \lambda \mathcal{L}_{GAN}] \\ \mathcal{L}_{GAN} =\;& \log \mathcal{D} (x_{0:L}) + \log (1 - D(\hat{x}_{0:L})) \\ \mathcal{L}_{GEN} =\;& \| x_{0:L} - \hat{x}_{0:L} \|_1 + \textrm{LPIPS} (x_{0:L}, \hat{x}_{0:L}) \\ &+ \beta \; \textrm{KL} (q_{\mu_\theta, \sigma_\theta, \mathcal{E}_M} (z_m \vert x_{0:L}) \;\|\; \mathcal{N}(0, I)) \end{aligned}\]2. Diffusion-based Motion Generator
연속 latent space에서 정규화된 모션을 기반으로 diffusion-based motion generator(DMG)를 적용하여 고정된 Markov Chain의 reverse process를 통해 모션 분포 $p(z_m)$를 학습한다.
DMG는 forward diffusion process와 reverse denoising process로 구성된다. Latent motion $z_m^0 \sim p(z_m)$이 주어지면 forward process는 미리 정의된 일련의 분산 $\beta_1, \cdots, \beta_T$에 따라 점잔적으로 $z_m^0$에 Gaussian noise를 추가하여 noise level이 증가하는 일련의 모션 $z_m^1, \cdots, z_m^T$를 생성한다.
\[\begin{equation} q(z_m^t \vert z_m^0) := \mathcal{N}(z_m^t; \sqrt{\vphantom{1} \bar{\alpha}_t} z_m^0, (1 - \bar{\alpha}_t) I) \\ \bar{\alpha}_t = \prod_{s=1}^t \alpha_s, \quad \alpha_t = 1 - \beta_t \end{equation}\]$z_m^t$에서 $z_m^0$을 복구하기 위해 reverse process는 parameterize된 Gaussian transition을 통해 점진적으로 noise를 제거한다.
\[\begin{aligned} p_\theta (z_m^{t-1} \vert z_m^t, y) &= \mathcal{N}(z_m^{t-1}; \mu_\theta (z_m^t, t, y), \sigma_t^2 I) \\ \mu_\theta (z_m^t, t, y) &= \frac{1}{\sqrt{\alpha_t}} \bigg( z_m^t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta (z_m^t, t, y) \bigg) \end{aligned}\]여기서 $\epsilon_\theta$는 noise를 근사화하기 위한 학습 가능한 오토인코더이다. $y$는 모션 생성을 안내하는 조건을 나타내며, 여기에는 생성된 모션의 사실성을 보장하기 위한 미리 획득한 콘텐츠 feature $f_{x_0}$와 모션 생성 프로세스에 대한 추가 제어를 제공하는 선택적 텍스트 입력이 포함된다. 2D UNet 백본을 $\epsilon_\theta$로 사용하는 LDM을 cross-attention 메커니즘과 함께 사용하여 조건을 통합한다. 목적 함수는 다음과 같이 단순화할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{simple} (\theta) := \| \epsilon_\theta (z_m^t, t, y) - \epsilon \|_2^2 \end{equation}\]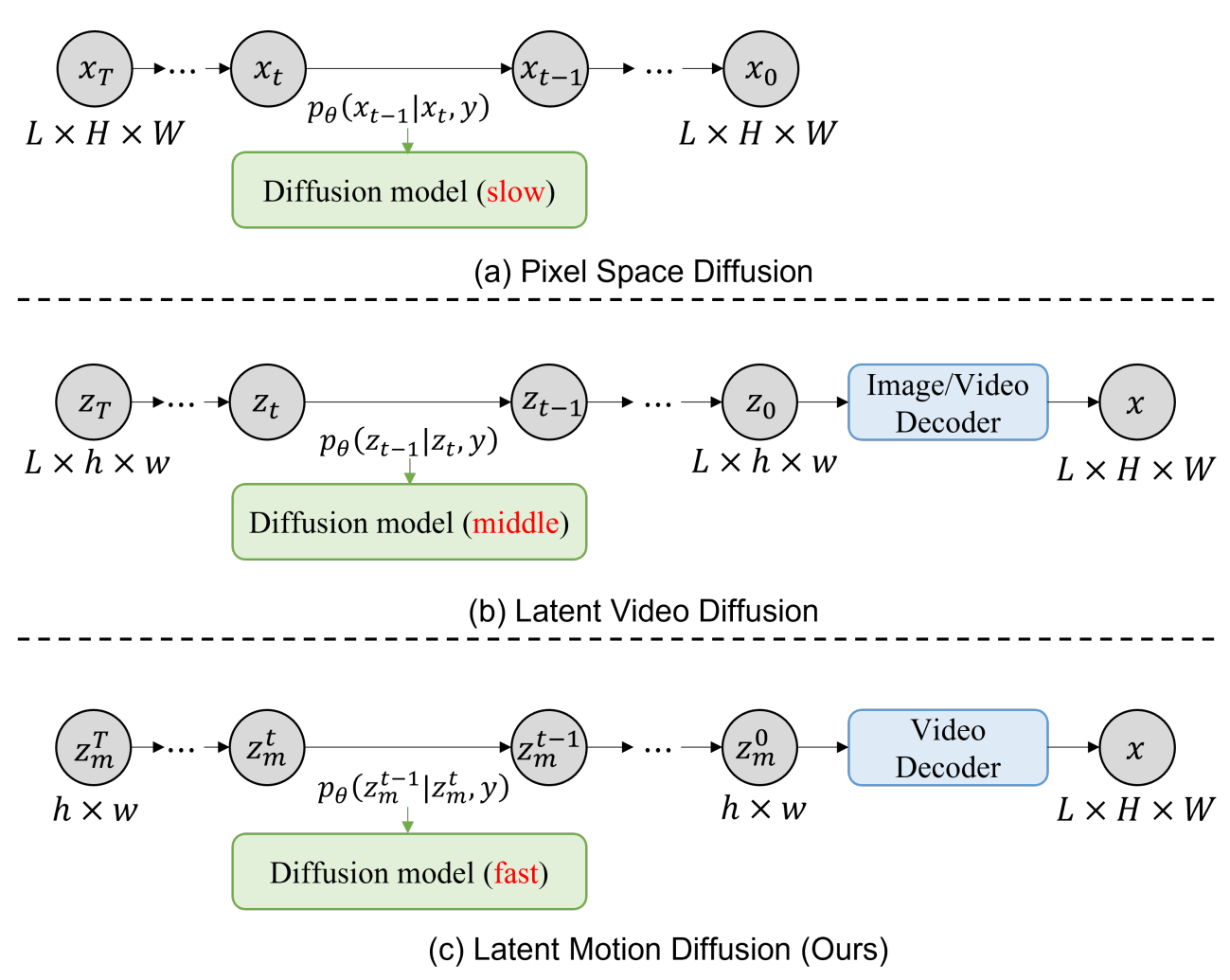
샘플링 중에 샘플링 속도를 개선하기 위해 샘플링 step $K$개가 포함된 하위 시퀀스의 noise schedule을 채택한다. Diffusion model에서 generator $\epsilon_\theta$는 샘플링 중에 재귀적으로 실행된다. 결과적으로 $\epsilon_\theta$의 계산 복잡도는 특히 동영상 데이터의 경우 샘플링 속도에 상당한 영향을 미칠 수 있다. 따라서 저자들은 위 그림과 같이 다양한 동영상 diffusion model의 계산 비용을 비교하여 LaMD의 샘플링 효율성을 분석하였다.
3D UNet 모델을 기반으로 pixel-space diffusion을 사용하여 $L \times H \times W$ 차원의 동영상 픽셀을 직접 생성하면 샘플링 속도가 가장 느려진다. 이에 비해 $f_s$와 $f_t$를 사용하여 동영상을 latent video space로 압축함으로써 latent video diffusion은 동일한 모델 아키텍처와 채널 크기에서 계산 복잡도를 $f_t \cdot f_s^2$배 줄일 수 있다. 대조적으로, 2D UNet 구조를 기반으로 제안된 LaMD의 복잡도는 pixel-space diffusion보다 최소 $L \cdot f_s^2$배 적으며 3D UNet에서 temporal convolution을 고려할 때 훨씬 더 복잡하다. LaMD는 이미지 diffusion model에 필적하는 계산 비용과 동영상 diffusion 패러다임 중에서 가장 빠른 샘플링 속도를 달성하였다.
Experiments
- 데이터셋: BAIR Robot Pushing, Landscape, CATER-GENs
- Implementation Details
- $f_s = 4$, \(f_t = \{16, 32\}\)
- 샘플링 중에 latent motion은 $K = 200$ timestep으로 생성됨
1. Reconstruction Ability of MCD-VAE
다음은 Landscape(위)과 BAIR Robot Pushing(아래)에서 MCD-VAE의 재구성 결과이다.

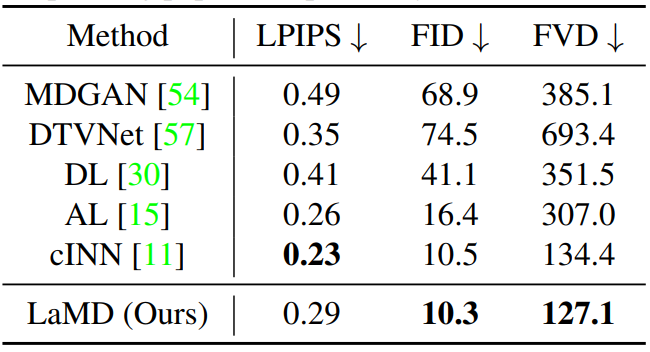
다음은 BAIR Robot Pushing과 Landscape에서의 재구성 성능을 나타낸 표이다.

다음은 상단 행의 외형 feature와 중간 행의 latent motion을 기반으로 재구성한 동영상(하단 행)이다.

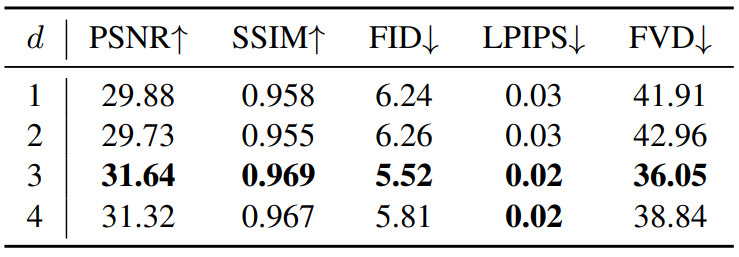
다음은 BAIR Robot Pushing에서 MCD-VAE의 motion capacity에 대한 ablation study 결과이다.
2. Image-to-Video Generation
다음은 BAIR Robot Pushing에서 생성된 샘플이다.

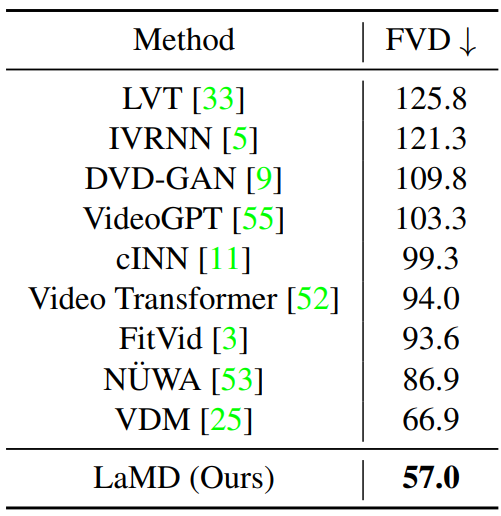
다음은 BAIR Robot Pushing에서의 정량적 평가를 state-of-the-art와 비교한 표이다.
다음은 Landscape에서 생성된 샘플이다.

다음은 Landscape에서의 정량적 평가를 state-of-the-art와 비교한 표이다.
3. Text-Image-to-Video Generation
다음은 CATER-GEN-v1과 CATER-GEN-v2에서 생성된 샘플이다.

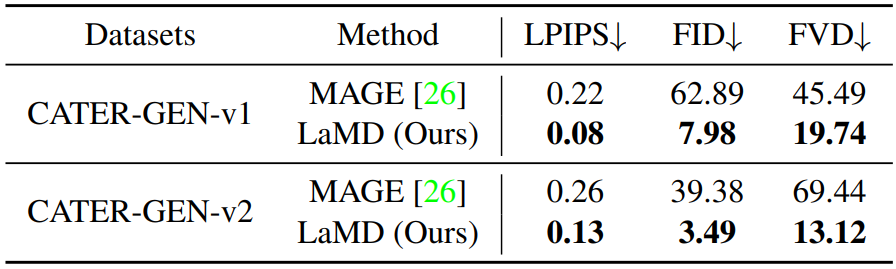
다음은 CATER-GEN-v1과 CATER-GEN-v2에서의 정량적 평가 결과이다.
다음은 샘플링 중 서로 다른 timestep에서 생성된 동영상이다. $t = 999$는 랜덤 latent motion을 기반으로 합성된 비디오에 해당하고 $t = 0$은 최종 생성된 동영상에 해당한다.
