[논문리뷰] L4P: Low-Level 4D Vision Perception Unified
arXiv 2025. [Paper] [Page]
Abhishek Badki, Hang Su, Bowen Wen, Orazio Gallo
NVIDIA
18 Feb 2025
Introduction
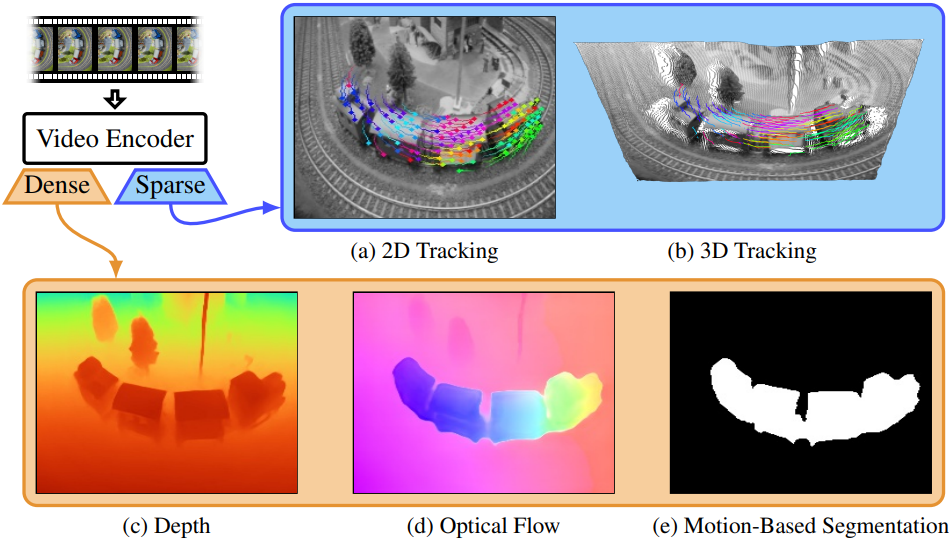
대량의 동영상 데이터에서 학습한 prior를 활용하여 dense하고 sparse한 여러 4D 비전 인식 task를 통합 아키텍처를 통해 zero-shot 방식으로 해결할 수 있을까?
이 목표를 달성하는 데에는 여러 가지 도전 과제가 따른다. 4D 인식을 넘어서는 다양한 task에서도 prior를 효과적으로 학습하고 공유하려면, 여러 task에서 공통으로 사용할 수 있는 강력한 backbone 아키텍처가 필요하다. 또한, 보조 task들에서 사전 학습이 가능하도록 일반화된 구조여야 한다. 특히, dense task와 sparse task는 근본적으로 다른 표현 방식을 요구하는데, 예를 들어 dense task는 2D 평면을 사용하는 반면, sparse task는 3D track을 필요로 한다.
저자들은 이러한 요구 사항을 충족하기 위해, 사전 학습된 VideoMAE와 task별 경량 head들을 결합한 아키텍처를 제안하였다. VideoMAE는 중간 및 고수준 비전 task에서 성공적으로 활용되어 왔지만, 저수준 4D 인식에서 픽셀 간 시공간 관계를 포착하는 능력은 아직 충분히 탐구되지 않았다. 저자들은 VideoMAE가 사전 학습을 통해 강력한 prior를 학습했다는 점에서 이를 backbone으로 선택했다. 또한, VideoMAE는 비교적 낮은 계산 비용으로 동영상을 토큰화할 수 있는 feedforward 방식의 온라인 메커니즘을 제공한다.
Dense task의 경우, VideoMAE를 DPT 기반의 head와 결합한다. DPT는 깊이 추정, 이미지 segmentation 등에서 우수한 성능을 보인 것으로 알려져 있다. Sparse task의 경우, tracking에 집중하며, 특히 Track-Any-Point (TAP) 방식을 채택한다. Tracking은 정밀하고 복잡한 움직임과 물체 간 물리적 상호작용을 이해하는 데 필수적이며, 이는 다운스트림 응용에도 중요하다. Track 추정 문제는 쿼리한 픽셀에 대한 2D heatmap과 관련된 깊이 및 visibility 토큰을 예측하는 방식으로 작동한다. 이 메커니즘을 통해 dense task와 sparse task를 통합된 프레임워크 내에서 처리할 수 있다.
본 논문의 접근 방식은 여러 가지 바람직한 특성과 장점을 제공한다.
- 사전 학습된 VideoMAE 모델을 활용함으로써 일반적인 저수준 4D 인식에서 사용되는 데이터셋과는 잠재적으로 다른, 더 다양하고 방대한 데이터셋에서 학습된 prior를 활용할 수 있다.
- 연산 효율성이 뛰어나다. 16프레임의 동영상 청크를 처리하는 데 약 300ms(프레임당 약 19ms)가 소요되며, 이는 각 task에 특화된 기존 방법들과 비슷하거나 더 빠른 속도이다.
- Task별 head를 결합함으로써 새로운 task를 위한 학습해야 할 파라미터의 수를 줄일 수 있다.
- 아키텍처를 범용 VideoMAE와 task별 head로 분리함으로써, dense task와 sparse task를 하나의 모델에서 해결할 수 있는 메커니즘을 제공한다.
- VideoMAE는 이미 VLM의 인코더로 사용되고 있으며, 이를 저수준 4D 인식으로 학습하면 이후 해당 VLM에서도 이러한 능력이 발현될 가능성이 있다.
Method
1. Video Masked Auto-Encoders
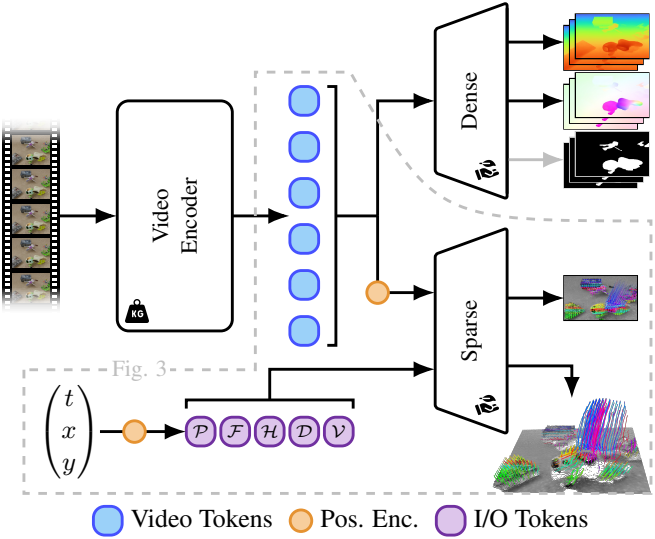
사전 학습된 VideoMAEv2를 ViT 기반 동영상 인코더로 사용한다. 인코더는 $T \times H \times W$ 크기의 동영상에서 작동하고, $t \times h \times w$의 시공간 패치 크기와 cube embedding을 사용하여 입력 동영상을 토큰 시퀀스로 변환한다. 그런 다음, 토큰들은 시공간적 attention을 사용하여 ViT 아키텍처에 의해 처리되어 동영상 토큰 $\mathcal{S} \in \mathbb{R}^{P \times C}$를 생성한다 ($P$는 토큰 수, $C$는 임베딩 차원). 동영상 인코더는 동영상 클립당 한 번만 실행된다. 인코딩이 완료되면 가벼운 head를 적용하여 토큰을 원하는 출력으로 디코딩할 수 있다. 포인트 추적 task의 경우, 토큰들이 여러 포인트를 병렬로 추적하도록 독립적으로 프롬프팅할 수 있다.
2. Dense Prediction Heads
Dense prediction task는 일반적으로 입력과 동일한 해상도 $H \times W$의 출력을 생성한다. 다양한 dense prediction task가 있지만, 본 논문에서는 깊이 추정, optical flow 추정, 모션 기반 segmentation을 다루었다.
Dense prediction task가 성공하려면 로컬 및 글로벌 공간 구조를 모두 캡처하는 것이 중요하다. 저자들은 단일 이미지 깊이 추정에 대한 성능과 효율성으로 인해 DPT를 dense prediction head로 채택했다. DPT는 transformer 내부의 다양한 레이어에서 토큰을 점진적으로 조립하고 결합하여 전체 해상도 예측을 생성한다.
VideoMAE의 3D 토큰을 활용하고 시간적 추론을 가능하게 하기 위해, DPT head 내부의 모든 2D convolution을 3D convolution으로 대체한다. 이러한 수정은 최소한의 추가적인 계산으로 시간적 일관성을 가져오기에 충분하다. 각 dense prediction task에 대한 DPT head의 구조는 출력 차원을 맞추기 위한 마지막 레이어만 다르다. (깊이와 모션 기반 segmentation은 1개의 채널, optical flow는 2개의 채널)
$T$ 프레임보다 긴 동영상의 경우, stride $T/2$로 inference를 실행한다. 일관성을 강화하기 위해, 연속되는 window에서 프레임의 깊이 예측을 정렬하기 위해 affine transformation을 사용한다. 이 전략은 상대적인 깊이에 대한 개별 window에는 영향을 미치지 않지만, 장기적인 시간적 일관성을 크게 개선한다. Optical flow와 모션 기반 segmentation의 경우, 단순히 겹치는 예측을 덮어쓴다.
3. Sparse Prediction Heads
- 입력: 픽셀 프롬프트 $(t_i, x_i, y_i)$
- 출력: 해당 3D 궤적 \(\mathcal{T}_i = \{\hat{x}_i (t), \hat{y}_i (t), \hat{d}_i (t), \hat{v}_i (t)\}_{t=0}^{S-1}\)
- \((\hat{x}_i (t), \hat{y}_i (t))\): 2D 위치
- \(\hat{d}_i (t)\): 카메라 기준 깊이
- \(\hat{v}_i (t)\): visibility (보이는 지, 가려졌는 지)
Sparse prediction task는 픽셀을 2D에서 추적하는 것뿐만 아니라, 가려진 구간에서도 추적해야 하며, track의 깊이까지 추론해야 하므로 매우 어려운 task이다. 또한, 동영상 인코더는 고정된 $T$ 프레임의 window만을 처리할 수 있는 제한적인 시간적 컨텍스트를 가지며, 임의로 긴 동영상($S > T$)에서도 tracking이 가능해야 한다. 따라서 일반적인 목적의 head를 그대로 적용하기는 어렵다.
이를 해결하기 위해, 저자들은 온라인(online) 접근법을 도입한다. 즉, 동영상 인코더의 시간적 컨텍스트($T$ 프레임) 내에서 입력 픽셀 프롬프트의 3D track을 추정할 수 있는 head를 설계하였다. 또한, $T$ 프레임을 넘어서는 온라인 추정을 위해, head에 메모리 메커니즘을 추가하고 이를 효율적으로 학습하는 방법을 제안하였다.
Tracking within the Temporal Context
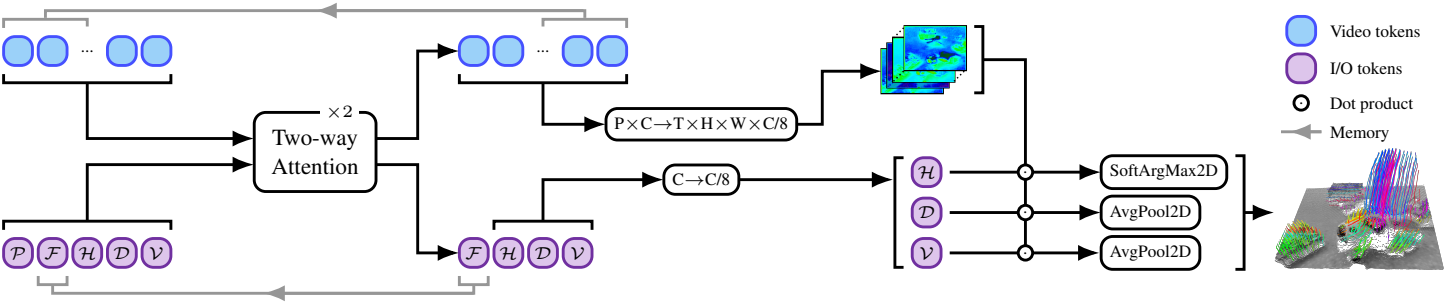
Sparse tracking task를 통합 프레임워크 내에서 다루기 위해서는 특별한 고려가 필요하다. 저자들은 track 위치를 직접 추정하는 대신, track을 dense한 확률 히트맵으로 표현할 것을 제안하였다. Tracking을 픽셀 정렬된 2D 맵 추정 문제로 변환하면, sparse task와 dense task 간의 공유 표현이 가능해져 backbone을 공유하는 것이 보다 자연스럽게 이루어진다.
이를 달성하기 위해, SAM의 프롬프트 인코딩 및 마스크 디코딩 메커니즘을 변형하여 적용한다. 입력 픽셀 프롬프트는 3D 위치 인코딩과 학습 가능한 임베딩을 활용하여 $C$차원의 임베딩을 가진 입력 포인트 토큰 $\mathcal{P}$를 생성한다. 마찬가지로, 3D track의 여러 구성 요소를 추정하기 위해 학습 가능한 임베딩을 가진 출력 토큰을 정의한다. 여기에는 동영상 전반에 걸쳐 track의 2D 픽셀 위치를 추정하는 히트맵 토큰 $\mathcal{H}$, track의 깊이를 추정하는 깊이 토큰 $\mathcal{D}$, track의 visibility를 추정하는 visibility 토큰 $\mathcal{V}$가 포함된다.
입력 및 출력 토큰들은 3D 위치 인코딩된 비디오 토큰 $\mathcal{S}$와 양방향 어텐션 메커니즘을 통해 상호작용하며 비디오 특징을 디코딩한다. 디코딩된 비디오 특징은 리샘플링된 후, 최종적으로 출력 토큰과의 내적을 수행하여 $T \times H \times W$ 크기의 출력 마스크를 생성한다.
2D track 추정의 경우, 이 출력 마스크를 2D track 위치를 나타내는 확률 히트맵으로 해석하고, 2D soft-argmax 연산을 적용하여 각 프레임 $t$에서 \((\hat{x}_i (t), \hat{y}_i (t))\)을 추정한다. 깊이와 visibility 추정의 경우, 2D average pooling 연산을 수행한 후, 깊이의 경우 exponential, visibility의 경우 sigmoid를 적용하여 각 프레임 $t$에서 \(\hat{d}_i (t)\)와 \(\hat{v}_i (t)\)를 추정한다.
이 단순한 설계 덕분에, 동영상 내 어디에서든 쿼리 포인트를 설정하여 병렬로 tracking을 수행할 수 있다. SAM의 two-way attention 메커니즘을 적용하면서도, head 구조를 경량화하기 위해 두 개의 two-way attention 레이어만 사용한다. 또한, SAM의 원래 마스크 디코더에 포함된 2D convolution을 3D convolution으로 대체하여 시간 정보를 효과적으로 활용할 수 있도록 설계하였다.
A Memory Mechanism for Long Videos
저자들은 $T$ 프레임 길이의 하나의 window를 넘어 tracking하기 위해 온라인 방식을 채택했다.
단순한 접근 방식은 window 간 track을 순차적으로 연결하는 것이다. 두 개의 연속적인 window가 겹쳐져 있을 때, 첫 번째 window에서 추정된 2D track의 한 지점을 활용하여 두 번째 window에서 tracking을 수행할 수 있다. 이를 위해 두 window가 겹치는 구간에서 track 상의 한 지점을 쿼리로 사용하며, 가장 높은 visibility를 가진 지점을 선택하면 보다 안정적인 연결이 가능하다.
그러나 이 방법은 두 가지 문제점을 가지고 있다.
- Tracking된 점이 window의 겹치는 구간에서 visibility가 없을 수도 있다. 이를 해결하기 위해, track-feature 토큰 $\mathcal{F}$를 도입하여 이후 window에 추가적인 프롬프트로 전달한다. 이 토큰을 쿼리 점 주변의 로컬 외관으로 명시적으로 초기화하지 않고, 대신 two-way attention head가 tracking에 가장 유용한 정보를 자유롭게 포착할 수 있도록 한다, 심지어 가려짐이 발생한 경우에도 이를 추적할 수 있도록 설계되었다.
- Window를 넘어서 추론하는 것을 허용하지 않기 때문에, track이 이동하거나 손실될 가능성이 크다. Track-feature 토큰은 이를 어느 정도 보완하지만, 더 강력한 window 간 정보 공유를 위해, 현재 window의 two-way attention 단계에서 디코딩된 동영상 토큰을 다음 window로 전달한다. 이를 위해, 겹치는 영역의 디코딩된 동영상 토큰을 linear layer로 projection한 후, 이를 다음 window의 two-way attention 단계로 들어가는 동영상 토큰에 더한다.
이러한 메모리 전략은 window를 넘나드는 효과적인 추론을 가능하게 하며, tracking의 안정성을 크게 향상시킨다.
메모리 메커니즘을 학습하려면 unrolled window training이 필요하다. 즉, 길이가 $S$인 동영상에서 모든 겹치는 window에 대한 동영상 feature를 계산한 후, 전체 동영상에 대해 온라인 방식으로 track을 계산해야 한다. 그러나 이러한 방식을 end-to-end로 학습하는 것은 메모리 제약으로 인해 어려운 문제이다.
이를 해결하기 위해, 저자들은 두 단계 학습 전략을 도입하였다.
- 하나의 window만을 학습하지만, 네트워크의 모든 파라미터를 학습시킨다.
- 동영상 인코더의 마지막 몇 개의 레이어를 제외한 나머지를 고정한 후, tracking head와 함께 unrolled window training을 위한 fine-tuning을 수행한다.
Experiments
- 데이터셋: Kubric, PointOdyssey, DynamicReplica, TartanAir
- 인코더: VideoMAEv2
- 입력 차원: RGB 16$\times$224$\times$224
- 패치 크기: 2$\times$14$\times$14
- 출력 차원: $C$ = 1408, 8$\times$16$\times$16 $\rightarrow$ 동영상 토큰 2048개
- 인코더 블럭: 40개
- DPT head: 14, 21, 28, 36번 블럭의 출력을 사용
- sparse head: 마지막 블럭(39번)의 출력 사용
- 학습
- 1단계: 16프레임 단일 window에 대하여 end-to-end로 전체 fine-tuning
- 2단계: 40프레임 클립에 대하여 인코더의 마지막 세 레이어와 sparse head만 fine-tuning
- 16프레임의 겹치는 window 4개 (stride 8)
- batch size: 8
- iteration: 10만
- GPU: NVIDIA A100 8개 (각 단계는 1일, 2일 소요)
- Loss
- dense head: 깊이는 SILog loss, optical flow는 L1 loss
- sparse head: 2D 위치는 L1 loss, 깊이는 scale-invariant loss, visibility는 binary cross entropy loss
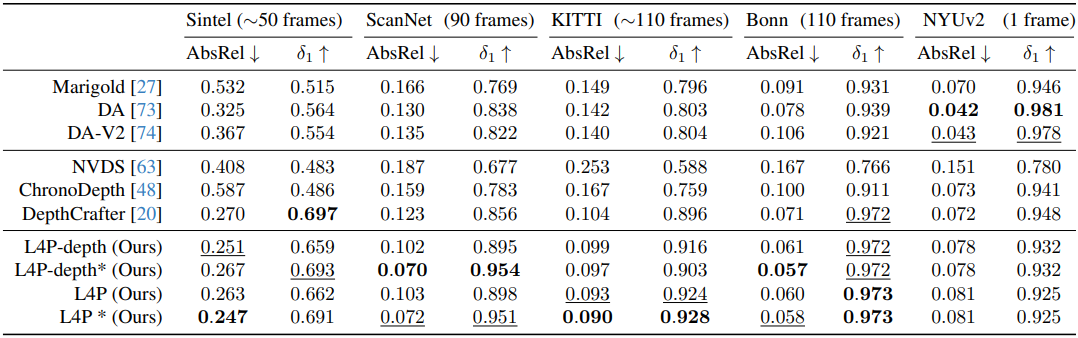
1. Video Depth Estimation
다음은 zero-shot 깊이 추정 결과를 비교한 것이다.
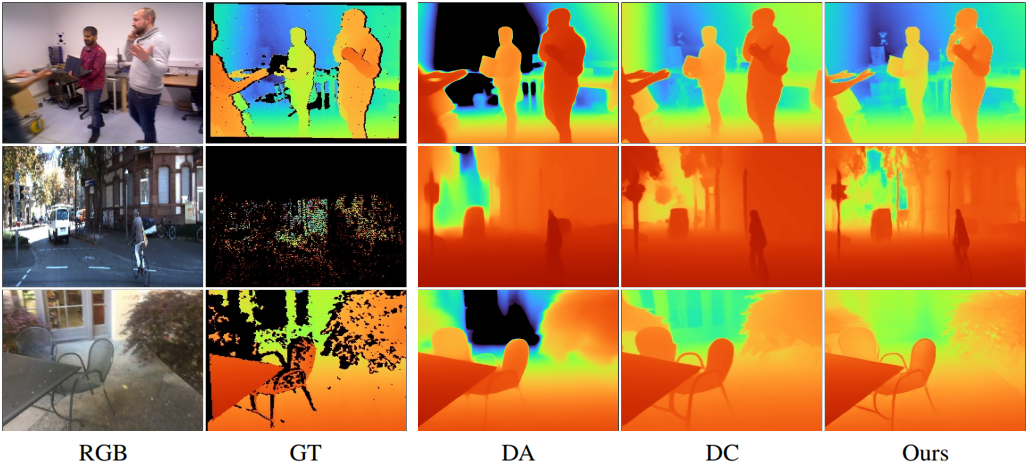
2. Multi-Frame Optical Flow Estimation
다음은 optical flow 추정 결과를 비교한 것이다.
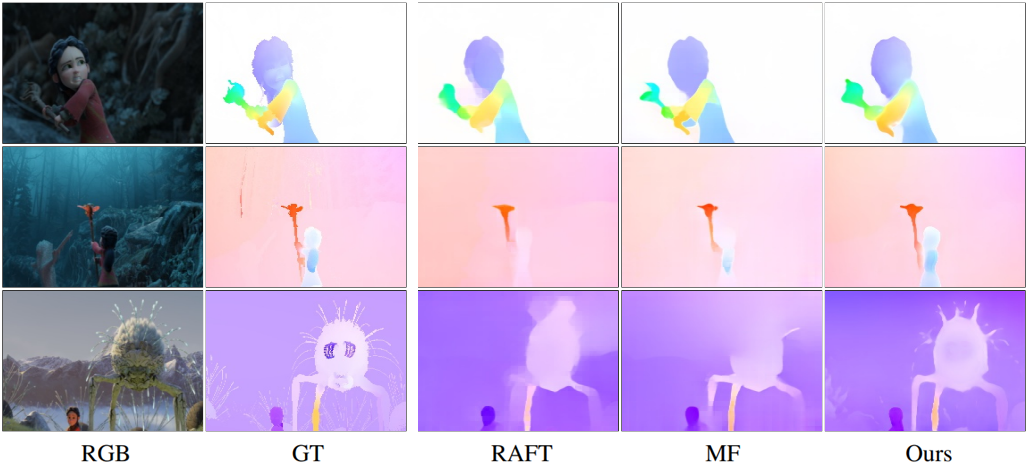

3. Sparse 2D/3D Track Estimation
다음은 2D tracking 결과를 비교한 것이다.
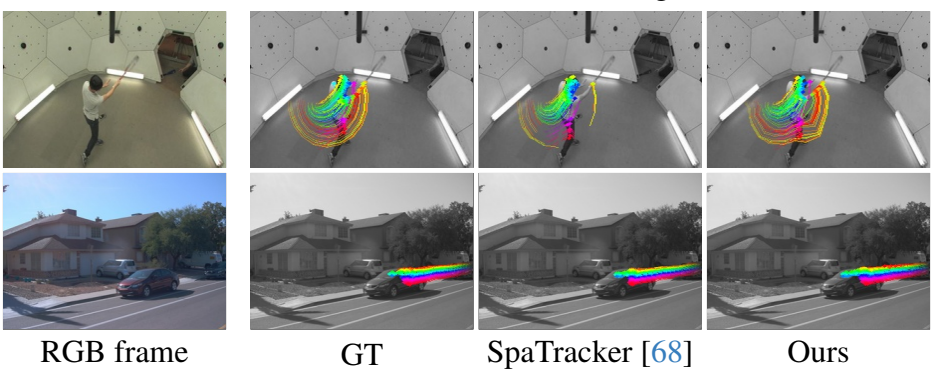
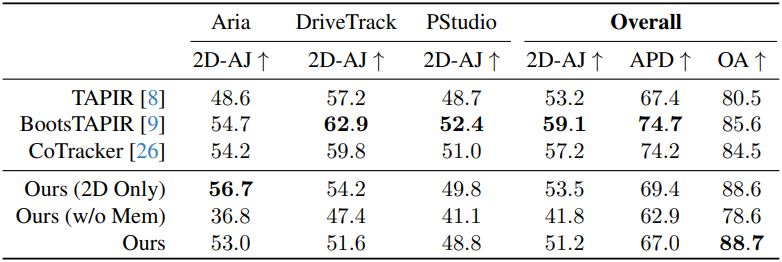
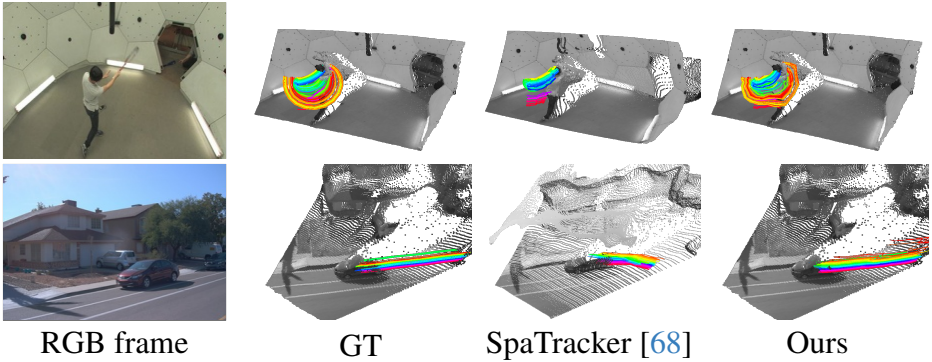
다음은 3D tracking 결과를 비교한 것이다. (CM은 COLMAP, ZD는 ZoeDepth)
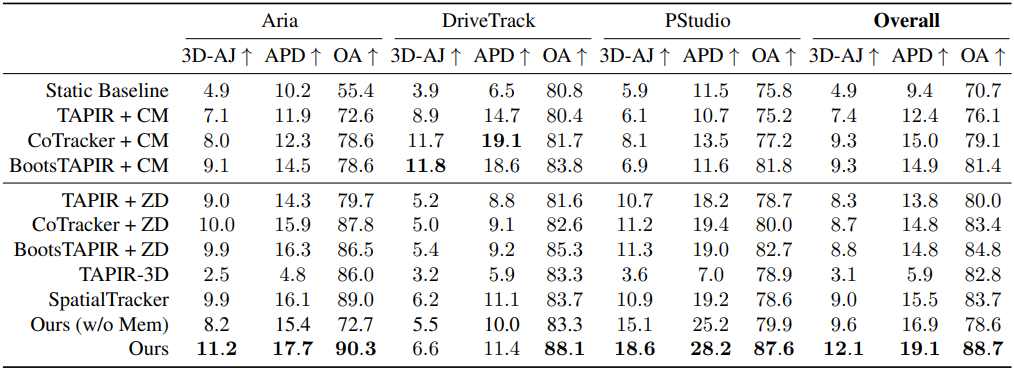
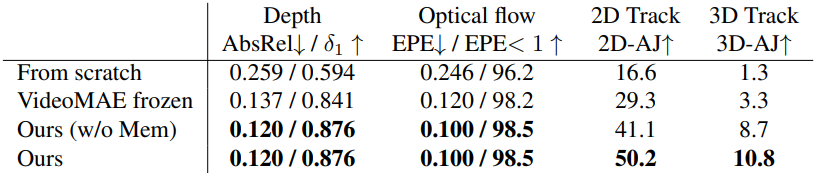
4. Ablations
다음은 ablation 결과이다.
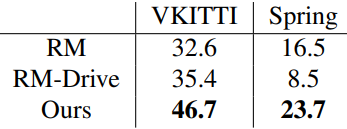
5. Additional Task: Motion-based Segmentation
저자들은 네트워크에 새로운 task를 추가하는 방법을 보여주기 위해, 인코더를 고정시켜 놓고 모션 기반 segmentation을 위한 dense head를 fine-tuning하였다. 다음은 모션 기반 segmentation 결과를 비교한 것이다.