[논문리뷰] L4GM: Large 4D Gaussian Reconstruction Model
NeurIPS 2024. [Paper] [Page]
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, Huan Ling
NVIDIA | University of Toronto | University of Cambridge | MIT | Nanyang Technological University
14 Jun 2024

Introduction
최근 3D Large Reconstruction Model (LRM)이라 불리는 하나의 이미지에서 3D 재구성을 위한 유망한 방법이 등장했다. 3D LRM은 대규모 합성 및 실제 데이터셋으로 대형 transformer 모델을 학습시킨 후, 한 번의 forward pass로 하나의 이미지에서 neural radiance field로 표현되는 3D object를 생성하므로 속도가 매우 빠르다.
본 논문은 동영상에서 3D Gaussian 시퀀스를 재구성하는 것을 목표로 하는 최초의 4D LRM인 L4GM을 제시하였다. L4GM의 핵심은 새로운 대규모 데이터셋으로, Objaverse 1.0에서 렌더링된 animated 3D object의 멀티뷰 동영상 1,200만 개를 포함한다. L4GM은 멀티뷰 이미지에서 3D Gaussian을 출력하도록 학습된 3D LRM인 LGM을 기반으로 구축되었다. LGM을 확장하여 일련의 프레임을 입력으로 취하고 각 프레임에 대한 3D Gaussian 표현을 생성한다. 시간적으로 일관된 3D 표현을 학습시키기 위해 프레임 사이에 temporal self-attention layer를 추가한다. 두 개의 연속적인 3D Gaussian 표현을 입력받아 중간 Gaussian 세트를 출력하는 interpolation 모델을 학습시켜 출력을 더 높은 fps로 업샘플링한다. L4GM은 여러 뷰에서 Gaussian을 렌더링하고 timestep당 이미지 재구성 loss로 학습된다.
L4GM은 합성 데이터에 대해서만 학습하였음에도 불구하고 Sora에서 생성된 동영상이나 실제 동영상에 매우 잘 일반화된다. 또한 L4GM은 video-to-4D 벤치마크에서 다른 접근 방식보다 100~1,000배 빠른 속도로 SOTA 품질을 달성했으며, ImageDream과 같은 멀티뷰 생성 모델과 결합하여 빠른 video-to-4D 생성을 가능하게 한다.
Method
본 논문의 목표는 동적 물체의 동영상 \(\mathcal{I} = \{I_t\}_{t=1}^T\)가 주어지면 물체의 정확한 4D 표현을 신속하게 재구성하는 것이다 ($T$는 동영상 길이). L4GM은 개념적으로 단순하면서도 영향력 있는 두 가지 통찰력에 기반을 두고 있다.
- 4D 데이터가 희소하므로 이미지에 대해 작동하고 대규모 3D 정적 물체 데이터샛에 대해 광범위하게 사전 학습된 LGM을 활용한다. 이 전략은 사전 학습된 모델의 robustness를 활용하여 제한된 데이터로 4D 재구성 모델을 효과적으로 학습시킨다.
- 4D 재구성을 위해 멀티뷰 동영상을 사용하는 대부분의 기존 방법과 달리 저자들은 초기 단계에서 멀티뷰 이미지를 활용하는 것이 충분하다는 것을 발견했다. 멀티뷰 이미지 diffusion model을 활용하여 뷰의 첫 번째 프레임을 확장함으로써 이러한 멀티뷰 이미지를 쉽게 얻을 수 있다. Temporal self-attention layer를 추가함으로써 이 정보를 후속 timestep에 걸쳐 전파하고 적용함으로써 초기 멀티뷰 입력을 활용한다. 이 접근 방식은 일관된 멀티뷰 동영상을 생성하는 데에서 오는 계산 복잡도와 어려움을 크게 줄이는 동시에 재구성 품질을 향상시킨다.
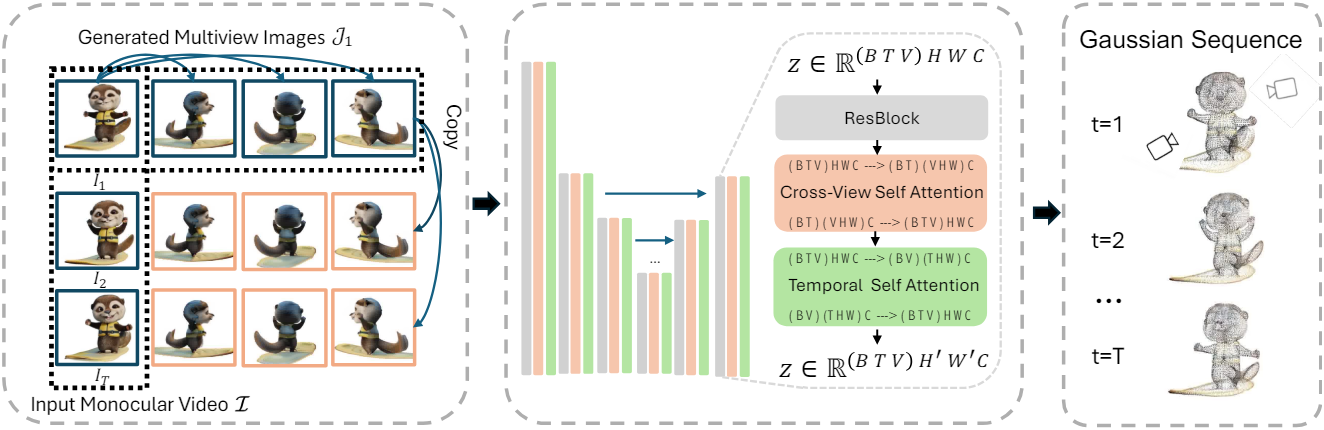
L4GM은 동영상을 처리하여 각 timestep에 대한 3D Gaussian 세트 \(\mathcal{P} = \{P_t\}_{t=1}^T\)을 출력한다. L4GM은 사전 학습된 3D LGM의 확장으로, 동적 모델링을 위하여 temporal self-attention layer를 사용한다. 입력된 동영상의 첫 번째 프레임을 기반으로 $V$개의 멀티뷰 이미지들을 생성한다. 이렇게 생성된 뷰들은 입력 동영상과 함께 L4GM에 공급되어 전체 4D 시퀀스를 재구성한다. 또한 L4GM을 4D interpolation 모델로 더욱 fine-tuning하여 입력 동영상보다 더 높은 FPS에서 4D 장면을 생성하고 더 부드럽고 자세한 모션을 제공할 수 있다.
1. ImageDream으로 멀티뷰 이미지 생성
LGM의 단일 이미지 시나리오와 유사하게 ImageDream을 사용하여 초기 프레임 $I_1$을 조건으로 카메라 포즈 $\mathcal{O}$에서 3개의 orthogonal view \(\mathcal{J}_1\)을 생성한다.
그러나 생성된 멀티뷰 이미지의 시야각이 입력 프레임 $I_1$과 일치하지 않는 경우가 많다. 이 문제를 해결하기 위해 먼저 3D LGM을 사용하여 생성된 멀타뷰 이미지에서 초기 3D Gaussian 세트인 \(P_\textrm{init}\)을 재구성하고 \(P_\textrm{init}\)에서 \(\mathcal{J}_1\)을 렌더링한다.
2. 3D LGM을 4D 재구성 모델로 전환
모델 아키텍처
사전 학습된 LGM의 asymmetric U-Net 구조를 backbone으로 채택한다. LGM의 입력 사양에 맞추기 위해 \(\mathcal{J}_1\)에서 생성된 멀티뷰 이미지를 다른 모든 timestep에 복제하여 $T \times V$의 그리드를 구성한다. 단순화를 위해 참조 동영상의 카메라는 정적이고 객체만 이동한다고 가정하므로 카메라 포즈 $\mathcal{O}$도 복사한다. LGM과 유사하게 이러한 포즈는 Plücker ray embedding을 사용하여 임베딩된다. 이 카메라 임베딩을 입력 이미지의 RGB 채널과 concatenate한다. Concatenate된 입력은 $BTV \times H \times W \times C$ 형식으로 reshape성되어 asymmetric U-Net에 공급된다. ($B$는 batch size)
L4GM 내의 각 U-Net 블록은 여러 개의 residual block으로 구성되며 그 다음에는 cross-view self-attention layer가 이어진다. 다양한 timestep에 걸쳐 시간적 일관성을 유지하기 위해 각 cross-view self-attention layer 뒤에 새로운 temporal self-attention layer를 도입한다. Temporal self-attention layer는 뷰 축 $V$를 독립적인 동영상의 batch로 처리한다. 처리 후 데이터는 원래대로 다시 reshape된다.
\[\begin{aligned} \textbf{x} &= \textrm{rearrange} (\textbf{x}, BTV \times H \times W \times C \rightarrow BV \times THW \times C) \\ \textbf{x} &= \textbf{x} + \textrm{TempSelfAttn} (\textbf{x}) \\ \textbf{x} &= \textrm{rearrange} (\textbf{x}, BV \times THW \times C \rightarrow BTV \times H \times W \times C) \end{aligned}\]여기서 $\textbf{x}$는 feature이다.
U-Net의 출력은 $B \times T \times V \times H_\textrm{out} \times W_\textrm{out} \times 14$ 형태의 14채널 feature map으로 구성된다. 각각의 $1 \times 14$는 픽셀당 Gaussian의 파라미터 세트로 처리된다. 뷰 차원 $V$를 따라 이러한 Gaussian을 concatenate하여 각 timestep에 대한 하나의 3D Gaussian 세트를 형성하고 결과적으로 $T$개의 3D Gaussian 세트 \(\{P_t\}_{t=1}^T\)가 된다.
Loss Functions
입력 카메라 포즈 $\mathcal{O}$ 외에도 멀티뷰 supervision을 위해 다른 카메라 포즈 세트 \(\mathcal{O}_\textrm{sup}\)을 선택한다. 카메라 포즈 \(\mathcal{O} \cup \mathcal{O}_\textrm{sup}\)에 대한 출력 4D 표현의 동영상 렌더링에 대한 간단한 재구성 목적 함수를 사용하여 모델을 학습시킨다.
3. Autoregressive 재구성
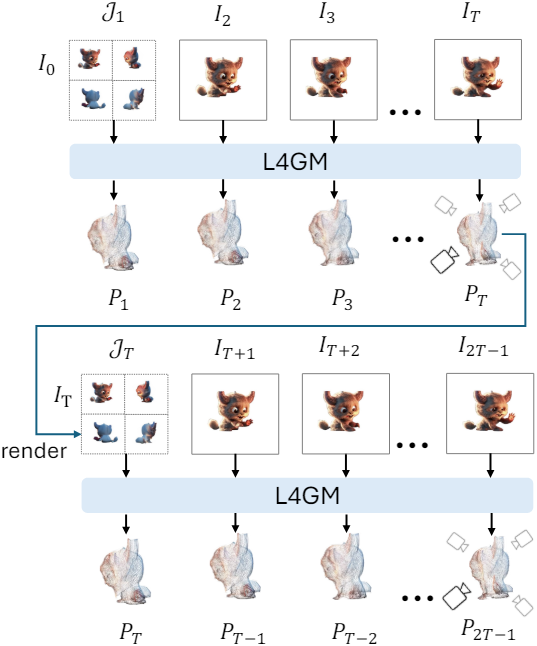
Base model은 고정 길이 $T$의 동영상에 맞게 설계되었다. $T$를 초과하는 긴 동영상의 경우 동영상을 크기 $T$의 청크로 분할하여 순차적으로 처리한다. 먼저 초기 $T$개의 프레임에 L4GM을 적용하여 $T$개의 Gaussian 세트를 생성한다. 그런 다음 4개의 orthogonal view에서 마지막 Gaussian 세트를 렌더링하여 새로운 멀티뷰 이미지를 얻는다. 이렇게 새로 렌더링된 멀티뷰 이미지는 다음 동영상 프레임 세트와 함께 다음 Gaussian 세트를 생성하는 데 사용된다. 동영상의 모든 프레임이 재구성될 때까지 이 프로세스가 반복된다. 이러한 autoregressive한 재구성 방법은 품질의 큰 저하 없이 10회 이상 반복될 수 있다.
4. 4D interpolation 모델
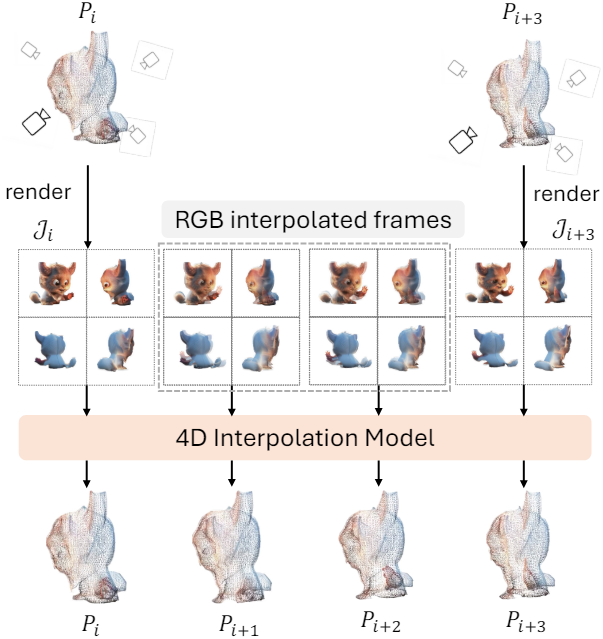
L4GM은 프레임을 따라 Gaussian을 추적하지 않으므로 Gaussian 궤적을 직접 보간하는 것은 불가능하다. 따라서 L4GM 위에 fine-tuning된 4D interpolation 모델을 학습시킨다. 두 개의 멀티뷰 이미지 세트가 4D interpolation 모델에 입력되며 모델은 중간 Gaussian 세트를 생성하도록 학습된다. 새로 생성된 중간 프레임에 대하여 멀티뷰 이미지 사이의 RGB 픽셀의 가중치 평균을 활용한다. 실제로는 두 개의 추가 프레임이 삽입된다.
Objaverse-4D dataset
1. 데이터셋 수집
4D 재구성 task를 위한 대규모 데이터셋을 수집하기 위해 Objaverse 1.0에서 모든 animated object를 렌더링한다.
80만 개의 object 중 애니메이션이 있는 object는 44,000개뿐이다. 각 object에는 여러 개의 연관된 애니메이션이 있을 수 있으므로 총 11만 개의 애니메이션을 얻는다. 모든 애니메이션은 24fps이다.
데이터셋은 대부분 조작된 캐릭터나 물체에 대한 애니메이션으로 구성된다. 모션에는 역동적인 이동, 세밀한 표정, 연기 효과 등 다양한 시나리오가 포함된다. 많은 애니메이션이 판타지 스타일을 특징으로 하기 때문에 데이터셋에는 상당한 양의 변형 모션이 있다.
2. 데이터셋 렌더링
저자들은 실제 동영상이 대부분 0° 고도의 카메라 포즈를 가지고 있다는 가정을 채택하고 이에 따라 학습 데이터에 대한 입력 뷰를 렌더링하였다. 특히 애니메이션의 길이는 다양하므로 각 애니메이션을 1초 길이의 클립으로 분할하고 각 4D object를 48개 뷰 $\times$ 1초 길이의 클립으로 렌더링한다. 뷰는 두 가지 카메라 세트에서 나온다.
- 고정 카메라 16개: 0° 고도에 균일한 방위각으로 배치
- 랜덤 카메라 32개: 임의의 고도와 방위각에 배치
학습 중에는 고정 카메라 16개에서 입력 카메라 포즈 $\mathcal{O}$를 샘플링하고 랜덤 카메라 32개에서 \(\mathcal{O}_\textrm{sup}\)을 샘플링한다. 또한, optical flow 크기를 기반으로 움직임이 작은 동영상 약 50%를 추가로 필터링하여 총 1200만 개의 동영상으로 Objaverse-4D 데이터셋을 구성하였다.
Experiments
- 구현 디테일
- 고정된 카메라 intrinsic과 조명 효과를 사용
- base model
- FPS: 8 (24에서 다운샘플링)
- epoch: 200
- 학습 시 $T = 8$, inference 시 $T = 16$
- 입력 카메라 4개, supervision 카메라 4개
- 각 forward pass는 약 0.3초 소요
- interpolation model
- FPS: 24
- epoch: 100
- 두 프레임을 보간하는 데 약 0.065초 소요
1. Comparisons to State-of-the-Art Methods
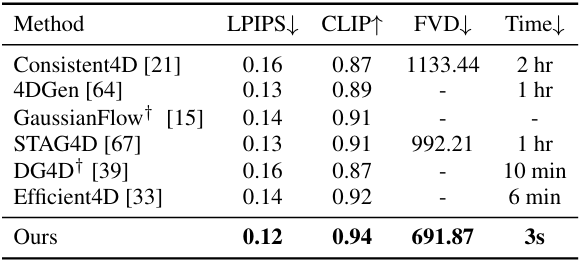
다음은 video-to-4D에 대한 정량적 평가 결과이다.
다음은 두 실제 동영상에 대한 재구성 결과이다.
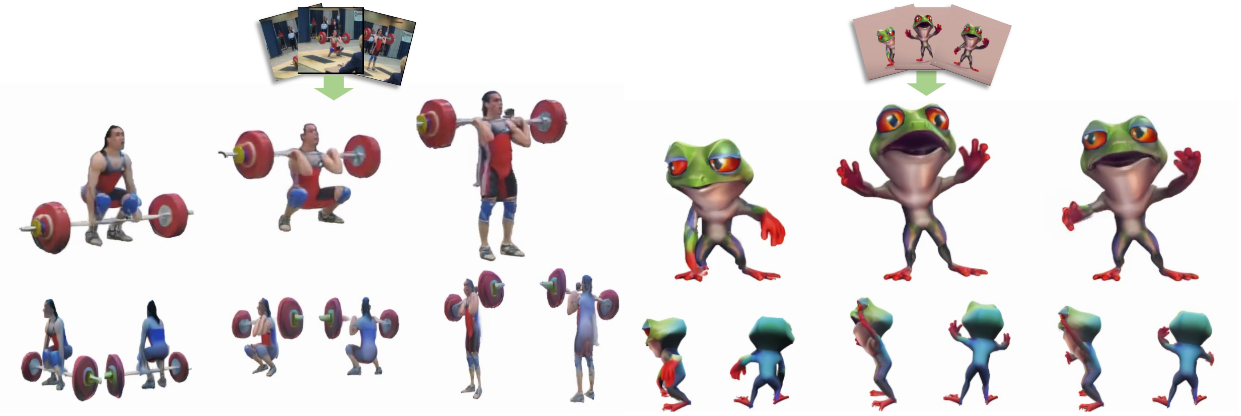
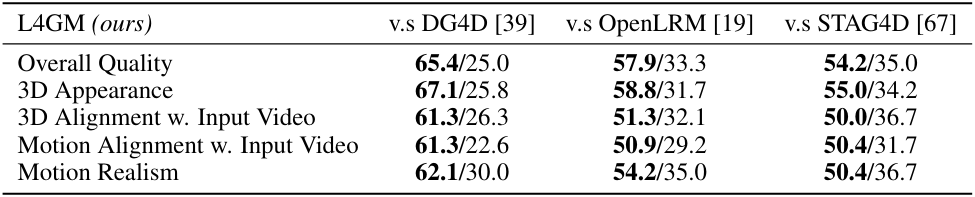
다음은 다른 모델들과 비교한 결과이다.

2. Ablation Studies
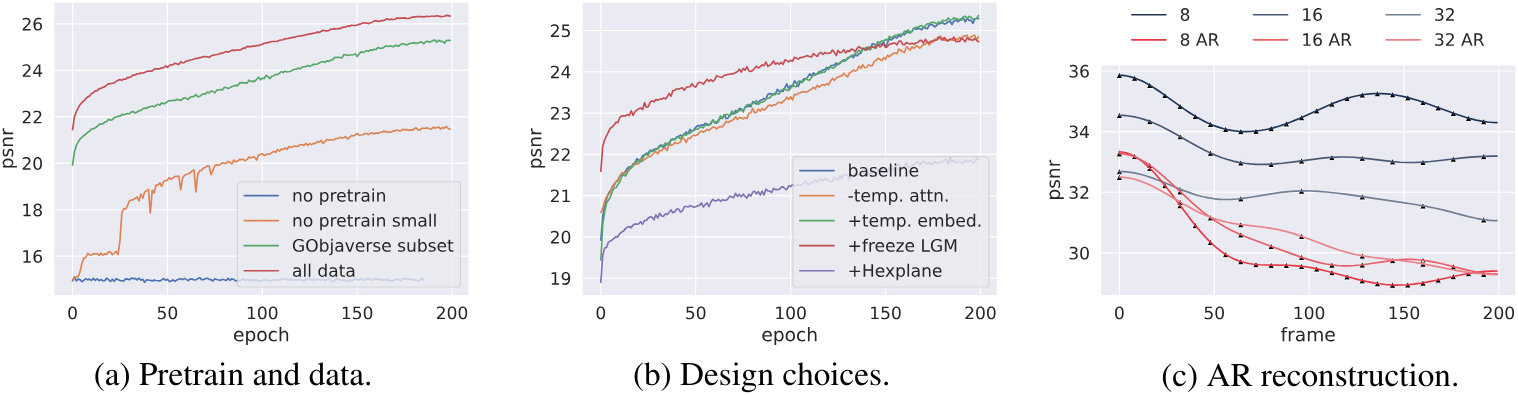
다음은 (a) 사전 학습 및 데이터, (b) 모델 디자인, (c) autoregressive 재구성에 대한 ablation 결과이다.