[논문리뷰] Voice Conversion With Just Nearest Neighbors (kNN-VC)
INTERSPEECH 2023. [Paper] [Page]
Matthew Baas, Benjamin van Niekerk, Herman Kamper
Stellenbosch University
3 May 2023
Introduction
음성 변환 (Voice Conversion)의 목표는 내용을 변경하지 않고 유지하면서 원본 음성을 타겟 음성으로 변환하는 것이다. 소스 및 타겟 speaker 집합이 얼마나 제한적인지에 따라 음성 변환 시스템을 분류할 수 있다. 가장 일반적인 경우는 학습 중에 소스 및 타겟 스피커가 보지 못하는 any-to-any conversion이다. 여기서 목표는 레퍼런스로 몇 가지 예를 사용하여 타겟 음성으로 변환하는 것이다. 최근의 any-to-any 방법은 자연스러움과 speaker 유사성을 향상시키지만 복잡성이 증가한다. 결과적으로 학습 및 inference에 비용이 많이 들고 개선 사항을 평가하고 구축하기가 어렵다. 저자들은 고품질 음성 변환에 복잡성이 필요한지 질문한다.
본 논문은 이 질문에 답하기 위해 any-to-any conversion을 위한 간단하고 강력한 방법인 k-nearest neighbors voice conversion (kNN-VC)을 소개한다. 명시적 변환 모델을 학습하는 대신 kNN을 사용한다. 먼저 self-supervised 음성 표현 모델을 사용하여 소스 및 레퍼런스 발화 모두에 대한 feature 시퀀스를 추출한다. 다음으로 소스 표현의 각 프레임을 레퍼런스에서 가장 가까운 이웃으로 교체하여 타겟 speaker로 변환한다. 특정 self-supervised 표현은 음성학적 유사성을 캡처하기 때문에 일치하는 타겟 프레임이 소스와 동일한 콘텐츠를 가질 것이다. 마지막으로 neural vocoder로 변환된 feature를 보코딩하여 변환된 음성을 얻는다.
저자들은 any-to-any conversion에 중점을 두고 kNN-VC를 여러 SOTA 시스템과 비교하였다. 단순함에도 불구하고 kNN-VC는 주관적 평가와 객관적 평가 모두에서 명료도와 speaker 유사성을 일치시키거나 향상시킨다. 또한 타겟 데이터 크기와 vocoder 학습 결정이 변환 품질에 미치는 영향을 이해하기 위해 ablation을 하였다.
kNN-VC
Concatenative voice conversion은 본 논문의 접근 방식과 관련된 또 다른 연구이다. Concatenative conversion의 아이디어는 소스 콘텐츠와 일치하는 타겟 음성 단위를 함께 연결하는 것이다. 타겟 음성에서만 출력을 구성함으로써 concatenative 방법은 양호한 speaker 유사성을 보장한다. Concatenative 시스템의 핵심 구성 요소는 일반적으로 병렬 데이터 또는 시간 정렬 전사가 필요한 단위 선택이다. 본 논문의 방법은 단위 선택 접근법으로도 볼 수 있다. 그러나 인간이 정의한 단위를 사용하는 대신 self-supervised 음성 모델의 feature를 사용한다. 최근 연구에 따르면 self-supervised 표현은 음성의 많은 속성을 선형적으로 예측한다. 특히 유사한 feature는 공유된 음성 콘텐츠를 나타낸다. 이것은 본 논문의 연구 질문으로 이어진다.
이러한 개선된 음성 표현을 고려할 때 고품질 음성 변환을 위해 여전히 복잡한 방법이 필요한가?
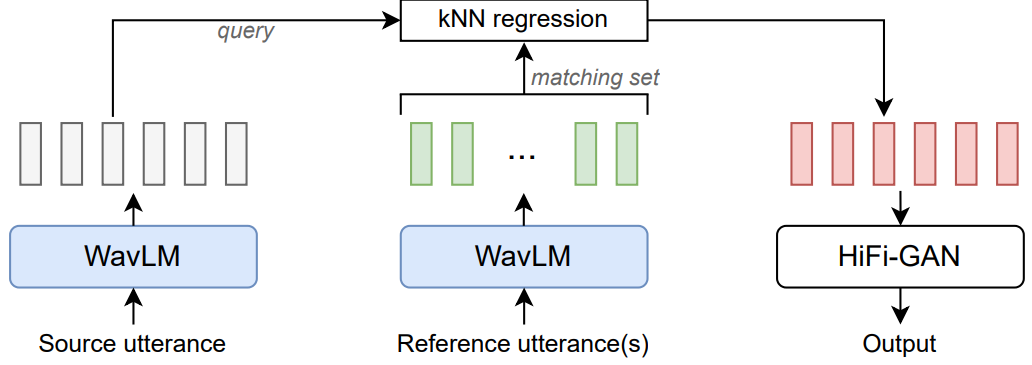
본 논문은 이 질문에 답하기 위해 k-nearest neighbors voice conversion (kNN-VC)을 제안한다. 위 그림은 인코더-컨버터-보코더 구조를 따르는 개요를 보여준다. 먼저 인코더는 소스 음성과 레퍼런스 음성의 self-supervised 표현을 추출한다. 다음으로 컨버터는 각 소스 프레임을 레퍼런스에서 가장 가까운 이웃에 매핑한다. 마지막으로 보코더는 변환된 feature에서 오디오 파형을 생성한다.
1. Encoder
kNN-VC는 query sequence라고 하는 소스 발화의 feature 시퀀스를 추출하는 것으로 시작한다. 또한 타겟 speaker로부터 하나 이상의 발화의 feature 시퀀스를 추출하여 self-supervised feature 벡터의 대규모 풀로 함께 섞는다. 이 bag-of-vectors를 matching set라고 부른다. 이 인코더의 목표는 주변 feature에 유사한 음성 콘텐츠가 있는 표현을 추출하는 것이다. 최근의 self-supervised 모델은 전화 식별 테스트에서 좋은 점수를 받았기 때문에 좋은 후보이다. 즉, 동일한 전화의 인스턴스를 서로 다른 전화보다 서로 더 가깝게 인코딩한다. 인코더 모델은 kNN-VC에 대해 fine-tuning되거나 추가로 학습되지 않으며, feature를 추출하는 데만 사용된다.
2. k-nearest neighbors matching
타겟 speaker로 변환하기 위해 query sequence의 모든 벡터에 kNN regression을 적용한다. 구체적으로 각 query 프레임을 matching set에서 kNN의 평균으로 바꾼다. 유사한 self-supervised 음성 feature가 음성 정보를 공유하기 때문에 kNN을 수행하면 speaker ID를 변환하는 동안 소스 음성의 콘텐츠를 보존할 수 있다. Concatenative 방법과 유사하게 타겟 feature에서 직접 변환된 query를 구성하여 양호한 speaker 유사성을 보장한다. kNN regression 알고리즘도 non-parametric하며 학습이 필요하지 않으므로 이 방법을 쉽게 구현할 수 있다.
3. Vocoder
보코더는 변환된 feature를 오디오 파형으로 변환한다. spectrogram으로 컨디셔닝하는 대신 기존의 보코더를 조정하여 self-supervised feature를 입력으로 사용한다. 그러나 학습과 inference 중에 입력 간에 불일치가 있다. Inference를 위해 kNN 출력, 즉 matching set에서 선택된 feature의 평균으로 보코더를 컨디셔닝한다. 서로 다른 음성 컨텍스트를 사용하여 다양한 시점에서 이러한 feature를 선택하여 인접한 프레임 간에 불일치가 발생한다.
4. Prematched vocoder training
이 문제를 해결하기 위해 사전 일치 학습을 한다. 특히 kNN을 사용하여 보코더 학습 세트를 재구성한다. 각 학습 발화를 query로 사용하여 동일한 spekaer의 나머지 발화를 사용하여 matching set을 만든다. 그런 다음 kNN regression을 적용하여 matching set을 사용하여 query sequence를 재구성한다. 이러한 사전 일치된 feature에서 원래 파형을 예측하도록 보코더를 학습시킨다. Inference 중에 발생하는 데이터와 유사한 데이터에 대해 보코더를 학습하여 robustness를 향상시키는 것이 아이디어다.
Experimental setup
- 데이터셋: LibriSpeech
Encoder
사전 학습된 WavLM-Large 인코더를 사용하여 소스 발화와 레퍼런스 발화에 대한 feature을 추출한다. 저자들은 예비 실험에서 선형 전화 인식 task에서 잘 수행되는 나중 계층 (22, 24, 마지막 여러 레이어의 평균)의 feature를 사용했다. 아이디어는 더 많은 콘텐츠 정보를 포함하여 kNN 매핑을 개선하는 것이었다. 그러나 이는 더 나쁜 피치와 에너지 재구성으로 이어졌다. 이러한 관찰을 바탕으로 저자들은 spekaer 식별과 높은 상관 관계가 있는 레이어 (WavLM-Large의 레이어 6)를 사용하는 것이 speaker 유사성과 소스 발화에서 운율 정보를 유지하는 데 필요하다는 것을 발견했다. 따라서 16kHz 오디오의 20ms마다 단일 벡터를 생성하는 WavLM-Large의 레이어 6에서 추출한 feature를 사용한다.
kNN regression
균일한 가중치로 $k = 4$를 설정하고 코사인 거리를 사용하여 feature를 비교한다. 저자들은 예비 실험에서 kNN-VC가 $k = 4$ 주변의 값 범위에 대해 상당히 robust하다는 것을 발견했다. 즉, 더 많은 레퍼런스 오디오를 사용할 수 있는 경우 (ex. 10분 이상) 더 큰 값의 $k$를 사용하면 변환 품질이 개선된다.
Vocoder
HiFi-GAN V1 아키텍처를 학습시킨다. WavLM에서 1024차원 입력 벡터를 받아 10ms hop length와 64ms Hann window의 128차원 mel-spectrogram을 사용하여 16kHz 오디오를 보코딩하도록 수정한다. LibriSpeech train-clean-100 데이터셋에서와 동일한 optimizer, step 및 기타 hyperparameter를 사용하여 모델을 학습시킨다. 저자들은 두 가지 변형을 학습시켰다. 하나는 순수한 WavLMLarge 레이어 6 feature에 대해 학습되고 다른 하나는 사전 일치된 레이어 6 feature에 대해 학습된다. 이러한 디자인 선택을 통해 8GB VRAM GPU에서 8분 분량의 레퍼런스 오디오를 통한 inference가 실시간보다 빠르다.
1. Voice conversion
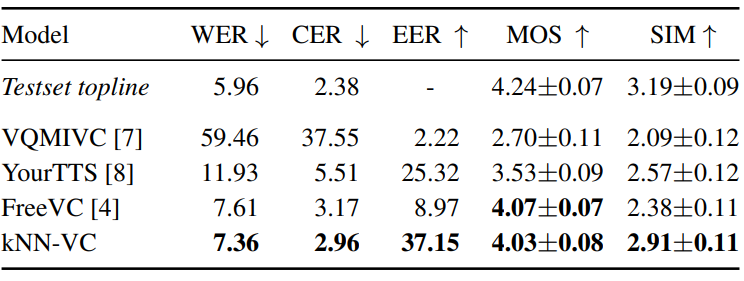
다음은 LibriSpeech test-clean subset에서 명료성 (W/CER), 자연스러움 (MOS), speaker 유사성 (EER, SIM)을 비교한 표이다.
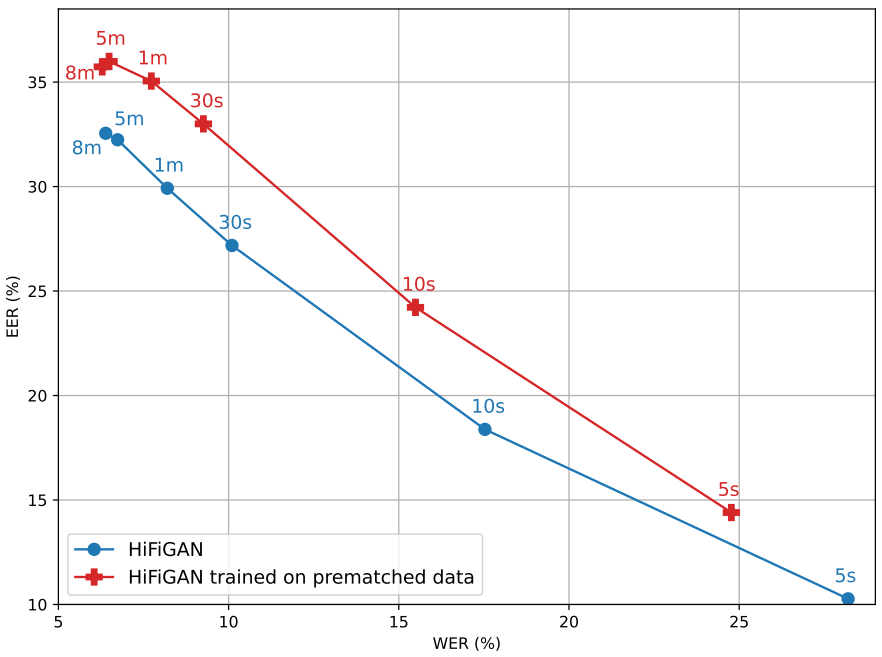
2. Ablation: Prematching and amount of reference data
다음은 두 보코더 변형에 대하여 다양한 양의 타겟 speaker 데이터에 따른 WER($\downarrow$)과 EER($\uparrow$)을 나타낸 그래프이다. (LibriSpeech dev-clean subset)