[논문리뷰] Jukebox: A Generative Model for Music
arXiv 2020. [Paper] [Blog] [Github]
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever
OpenAI
30 Apr 2020
Introduction
음악은 창작 과정에서 독특한 인간 정신을 불러일으키며, 컴퓨터가 이 창작 과정을 포착할 수 있는지에 대한 질문은 수십 년 동안 컴퓨터 과학자들을 매료시켰다. 우리는 피아노 악보를 생성하는 알고리즘, 가수의 목소리를 생성하는 디지털 보코더, 다양한 악기의 음색을 생성하는 신디사이저를 가지고 있다. 각각 멜로디, 작곡, 음색, 노래하는 사람의 목소리 등 음악 생성의 특정 측면을 포착한다. 그러나 모든 작업을 수행하는 단일 시스템은 아직 파악하기 어렵다.
생성 모델 분야는 지난 몇 년 동안 엄청난 발전을 이루었다. 생성 모델링의 목표 중 하나는 데이터의 두드러진 측면을 캡처하고 실제 데이터와 구별할 수 없는 새로운 인스턴스를 생성하는 것이다. 가설은 데이터 생성 방법을 학습함으로써 데이터의 가장 좋은 특징을 학습할 수 있다는 것이다. 최근 몇 년 동안 텍스트, 음성 및 이미지 생성의 발전을 이루었다.
생성 모델은 음악 생성 작업에도 적용되었다. 이전 모델들은 연주할 각 음의 타이밍, 피치, 속도 및 악기를 지정하는 피아노롤의 형태로 음악을 symbolic하게 생성했다. Symbolic 접근법은 저차원 space에서 문제를 해결함으로써 모델링 문제를 더 쉽게 만든다. 그러나 생성할 수 있는 음악을 특정 음표 시퀀스와 렌더링할 고정된 악기 집합으로 제한한다. 동시에 연구자들은 음악을 오디오 조각으로 직접 제작하려는 nonsymbolic 접근 방식을 추구해 왔다. 이것은 문제를 더욱 어렵게 만든다. 오디오의 space는 모델링할 많은 양의 정보 콘텐츠로 인해 매우 높은 차원이기 때문이다. 오디오 도메인 또는 스펙트로그램 도메인에서 피아노 곡을 생성하는 모델과 함께 약간의 성공이 있었다. 주요 한계점은 오디오를 직접 모델링하면 극도로 긴 범위의 종속성이 도입되어 음악의 높은 수준의 semantic을 학습하는 데 계산적으로 어려움이 있다는 것이다. 어려움을 줄이는 방법은 덜 중요한 정보는 잃지만 대부분의 음악 정보는 유지하는 것을 목표로 오디오의 저차원 인코딩을 학습하는 것이다. 이 접근 방식은 몇 가지 악기 집합으로 제한된 짧은 악기 조각을 생성하는 데 어느 정도 성공을 거두었다.
본 논문에서는 state-of-the-art 심층 생성 모델을 사용하여 오디오 도메인에서 몇 분에 걸친 장거리 일관성을 통해 다양한 고충실도 음악을 생성할 수 있는 단일 시스템을 생성할 수 있음을 보여준다. 본 논문의 접근 방식은 계층적 VQ-VAE 아키텍처를 사용하여 오디오를 이산적인 space로 압축하고 loss function은 음악 정보의 최대량을 유지하면서 압축 레벨을 높이도록 설계되었다. 이 압축된 space에 대해 최대 likelihood 추정으로 학습된 autoregressive Sparse Transformer를 사용하고 각 압축 레벨에서 손실된 정보를 재생성하도록 autoregressive upsampler를 학습시킨다.
본 논문의 모델은 록, 힙합, 재즈와 같은 매우 다양한 음악 장르의 노래를 만들 수 있다. 다양한 악기의 멜로디, 리듬, 장거리 구성, 음색은 물론 음악과 함께 생성할 가수의 스타일과 목소리를 캡처할 수 있다. 또한 기존 곡의 새로운 버전을 생성할 수 있다. 본 논문의 접근 방식은 옵션이 생성 프로세스에 영향을 줄 수 있도록 한다. Top prior을 conditional prior로 교체하여 가수에게 무엇을 부를 것인지 가사로 컨디셔닝하거나 작곡을 제어하기 위해 미디로 컨디셔닝한다.
Music VQ-VAE
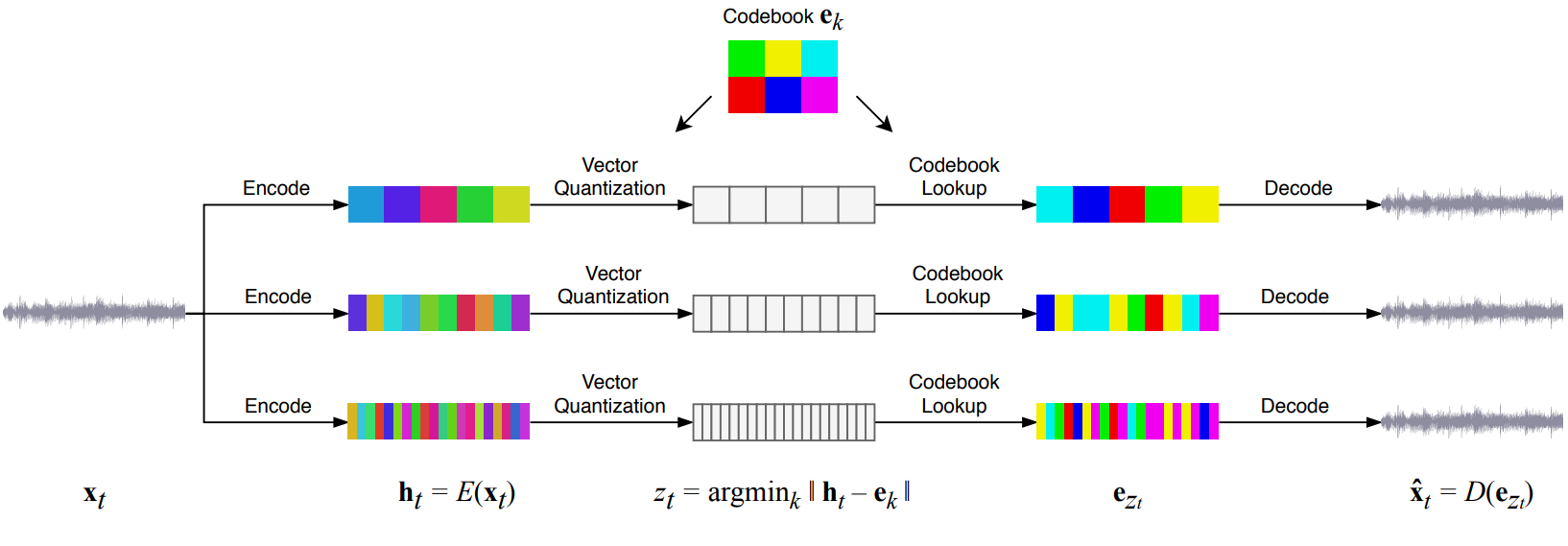
이미지에 대한 계층적 VQ-VAE 모델의 결과에서 영감을 받아 위 그림에 표시된 것처럼 세 가지 추상화 레벨을 사용하여 오디오를 모델링하는 데 동일한 기술을 적용하는 것을 고려한다. 각 레벨에서 WaveNet 스타일의 noncausal 1-D dilated convolution로 구성된 residual network를 사용하며, 다른 hop length와 일치하도록 다운샘플링 및 업샘플링 1D convolution과 인터리브된다.
1. Random restarts for embeddings
VQ-VAE는 codebook collapse를 겪는 것으로 알려져 있다. 모든 인코딩이 단일 또는 소수의 임베딩 벡터에 매핑되는 반면 코드북의 다른 임베딩 벡터는 사용되지 않아 bottleneck의 정보 용량이 줄어든다. 이를 방지하기 위해 랜덤 재시작을 사용한다. 코드북 벡터의 평균 사용량이 임계값 아래로 떨어지면 현재 배치의 인코더 출력 중 하나로 랜덤하게 재설정한다. 이렇게 하면 코드북의 모든 벡터가 사용되고 있으므로 codebook collapse를 완화하여 학습할 기울기가 있게 된다.
2. Separated Autoencoders
오디오에 계층적 VQ-VAE를 사용할 때, 저자들은 모델이 병목 현상이 적은 하위 레벨을 통해 모든 정보를 전달하기로 결정함에 따라 병목 현상이 있는 top-level이 거의 활용되지 않고 때로는 완전한 collapse를 겪는다는 것을 관찰했다. 각 레벨에 저장된 정보의 양을 최대화하기 위해 다양한 hop length로 별도의 autoencoder를 학습하기만 하면 된다. 각 레벨의 이산 코드는 서로 다른 압축 레벨에서 입력의 독립적인 인코딩으로 처리될 수 있다.
3. Spectral Loss
샘플 레벨 reconstruction loss만 사용하는 경우 모델은 낮은 주파수를 재구성하는 방법만 학습한다. 중간부터 높은 주파수를 캡처하기 위해 다음과 같이 정의되는 spectral loss을 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{spec} = \| | \textrm{STFT} (x) | - | \textrm{STFT} (\hat{x}) | \|_2 \end{equation}\]학습하기 더 어려운 위상에 주의를 기울이지 않고 모델이 스펙트럼 구성 요소와 일치하도록 권장한다. 이것은 오디오에 대한 병렬 디코더를 학습할 때 power loss 및 spectral convergence를 사용하는 것과 유사하다. 후자의 접근 방식과 본 논문의 접근 방식 사이의 한 가지 차이점은 더 이상 스펙트럼 신호 대 잡음비를 최적화하지 않는다는 것이다. 신호의 크기로 나누면 대부분 무음 입력에 대해 수치적 불안정성이 발생한다. 모델이 STFT 파라미터의 특정 선택에 overfitting되는 것을 방지하기 위해 시간과 주파수 해상도를 절충하는 여러 STFT 파라미터에 대해 계산된 spectral loss \(\mathcal{L}_\textrm{spec}\)들의 합을 사용한다.
Music Priors and Upsamplers
VQ-VAE를 학습시킨 후 샘플을 생성하기 위해 압축된 space에 대한 prior $p(z)$를 학습해야 한다. Prior model을 다음과 같이 분해한다.
\[\begin{aligned} p(z) &= p(z^\textrm{top}, z^\textrm{middle}, z^\textrm{bottom}) \\ &= p(z^\textrm{top}) p(z^\textrm{middle} \vert z^\textrm{top}) p(z^\textrm{bottom} \vert z^\textrm{middle}, z^\textrm{top}) \end{aligned}\]그리고 top-level prior $p(z^\textrm{top})$, 업샘플러 $p(z^\textrm{middle} \vert z^\textrm{top})$와 $p(z^\textrm{bottom} \vert z^\textrm{middle}, z^\textrm{top})$에 대해 별도의 모델을 학습시킨다. 이들 각각은 VQ-VAE에 의해 생성된 개별 토큰 space의 autoregressive 모델링 문제이다. 따라서 현재 autoregressive 모델링에서 SOTA인 sparse attention을 사용하는 Transformer를 사용한다. 본 논문은 구현 및 확장이 더 쉬운 Scalable Transformer라고 하는 단순화된 버전을 제안한다.
업샘플러의 경우 top-level 코드의 컨디셔닝 정보를 autoregressive Transformer에 제공해야 한다. 그러기 위해 deep residual WaveNet과 upsampling strided convolution 및 layer norm을 사용하고 출력을 현재 레벨의 임베딩에 추가 위치 정보로 추가한다. 동일한 오디오 세그먼트에 해당하는 상위 레벨 코드 청크에서만 하위 레벨로 컨디셔닝한다.
각 레벨에서 동일한 컨텍스트 길이의 이산 코드에 대해 Transformer를 사용한다. 이는 더 큰 hop length로 오디오 길이를 늘리고 더 높은 레벨에서 더 긴 시간적 종속성을 모델링하는 동시에 각 레벨 학습을 위해 동일한 계산 공간을 유지한다. 본 논문의 VQ-VAE는 convolution이므로 동일한 VQ-VAE를 사용하여 임의 길이의 오디오에 대한 코드를 생성할 수 있다.
1. Artist, Genre, and Timing Conditioning
생성 모델은 학습되는 동안 추가 컨디셔닝 신호를 제공함으로써 더 잘 제어할 수 있다. 첫 번째 모델의 경우 노래에 대한 아티스트와 장르 레이블을 제공한다. 여기에는 두 가지 장점이 있다. 첫째, 오디오 예측의 엔트로피를 줄여서 모델이 특정 스타일에서 더 나은 품질을 달성할 수 있다. 둘째, 생성 시 선택한 스타일로 생성하도록 모델을 조종할 수 있다. 또한 학습 시간에 각 세그먼트에 대한 타이밍 신호를 첨부한다. 이 신호에는 곡의 전체 길이, 해당 특정 샘플의 시작 시간과 경과된 곡의 비율이 포함된다. 이를 통해 모델은 반주의 시작이나 곡이 끝날 때 박수 갈채와 같은 전체 구조에 의존하는 오디오 패턴을 학습할 수 있다.
2. Lyrics Conditioning
위의 컨디셔닝된 모델은 다양한 장르와 예술적 스타일의 노래를 생성할 수 있지만 이러한 모델이 생성한 노래 목소리는 종종 매력적인 멜로디로 노래되지만 대부분 옹알이로 구성되어 인식 가능한 영어 단어를 거의 생성하지 않는다. 가사로 생성 모델을 제어할 수 있도록 각 오디오 세그먼트에 해당하는 가사로 모델을 컨디셔닝하여 학습 시 더 많은 컨텍스트를 제공하여 모델이 음악과 동시에 노래를 생성할 수 있도록 한다.
Lyrics-to-singing (LTS) task
컨디셔닝 신호에는 타이밍이나 발성 정보 없이 가사 텍스트만 포함된다. 따라서 가사와 노래의 시간적 정렬, 아티스트의 목소리, 그리고 피치, 멜로디, 리듬, 심지어 노래의 장르에 따라 구절을 부를 수 있는 다양한 방법을 모델링해야 한다. 가사 데이터에는 종종 코러스와 같은 반복된 섹션에 대한 텍스트 레퍼런스 또는 해당 음악과 일치하지 않는 가사 부분이 포함되어 있기 때문에 컨디셔닝 데이터는 정확하지 않다. 리드 보컬, 반주 보컬, 대상 오디오의 배경 음악 사이에도 분리가 없다. 이로 인해 Lyrics-to-singing(LTS)가 TTS보다 훨씬 더 어렵다.
Providing lyrics for chunks of audio
데이터셋에는 노래의 가사가 포함되어 있지만 작업을 더 쉽게 하기 위해 더 짧은(24초) 오디오 청크에 대해 학습한다. 학습 중에 오디오에 해당하는 가사를 제공하기 위해 가사의 문자를 각 노래의 지속 시간에 선형으로 span하고 학습 중에 현재 세그먼트를 중심으로 고정된 크기의 문자 window를 전달하는 간단한 휴리스틱을 사용한다. 이 간단한 선형 정렬 전략은 놀라울 정도로 잘 작동했지만 빠른 가사가 있는 힙합과 같은 특정 장르에서는 실패했다고 한다. 이 문제를 해결하기 위해 Spliter를 사용하여 각 노래에서 보컬을 추출하고 추출된 보컬에서 NUS AutoLyricsAlign을 실행하여 가사의 단어 레벨 정렬을 얻어 주어진 오디오 청크에 대한 가사를 보다 정확하게 제공하였다고 한다. 저자들은 실제 가사가 window 안에 있을 확률이 높도록 충분히 큰 window를 선택하였다.
Encoder-decoder model
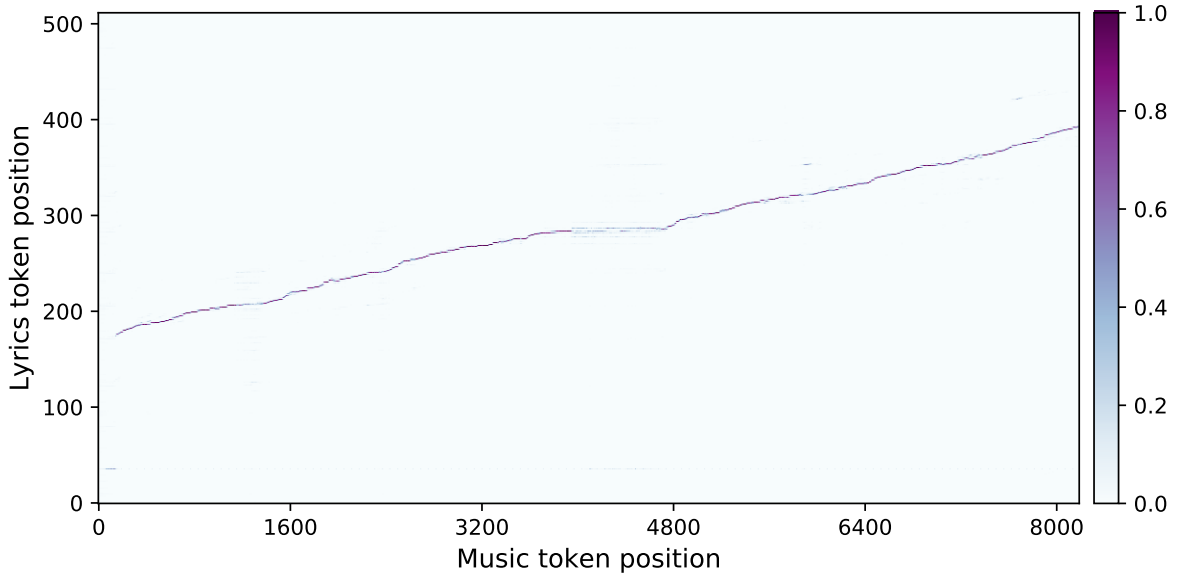
인코더-디코더 스타일 모델을 사용하여 가사의 문자로 컨디셔닝하고 top-level 음악 토큰을 생성하는 디코더가 처리하는 가사에서 인코더는 feature를 생성한다. 가사 인코더는 가사에 대한 autoregressive 모델링 loss가 있는 Transformer이며 마지막 레벨은 가사의 feature로 사용된다. 음악 디코더에서 음악 토큰의 query가 가사 토큰의 key와 value에만 attention 연산을 하는 몇 개의 추가 인코더-디코더 attention 레이어를 끼워 넣는다. 이 레이어는 가사 인코더의 마지막 레이어에서 activation을 처리한다. 아래 그림에서 이러한 레이어 중 하나에서 학습한 attention 패턴이 가사와 노래 사이의 정렬에 해당함을 알 수 있다.
3. Decoder Pretraining
가사 조건부 모델을 학습하는 데 필요한 계산을 줄이기 위해 사전 학습된 unconditional한 top-level prior을 디코더로 사용하고 model surgery를 사용하여 가사 인코더를 도입한다. MLP의 출력 projection 가중치와 이러한 residual block의 attention layer를 0으로 초기화하여 추가된 레이어가 초기화 시 identity function을 수행하도록 한다. 따라서 초기화 시 모델은 사전 학습된 디코더와 동일하게 동작하지만 인코더 상태 및 파라미터와 관련하여 여전히 기울기가 있어 모델이 인코더 사용 방법을 학습할 수 있다.
4. Sampling
VQ-VAE, 업샘플러, top-level prior를 학습한 후에는 이를 사용하여 새로운 노래를 샘플링할 수 있다.
Ancestral sampling
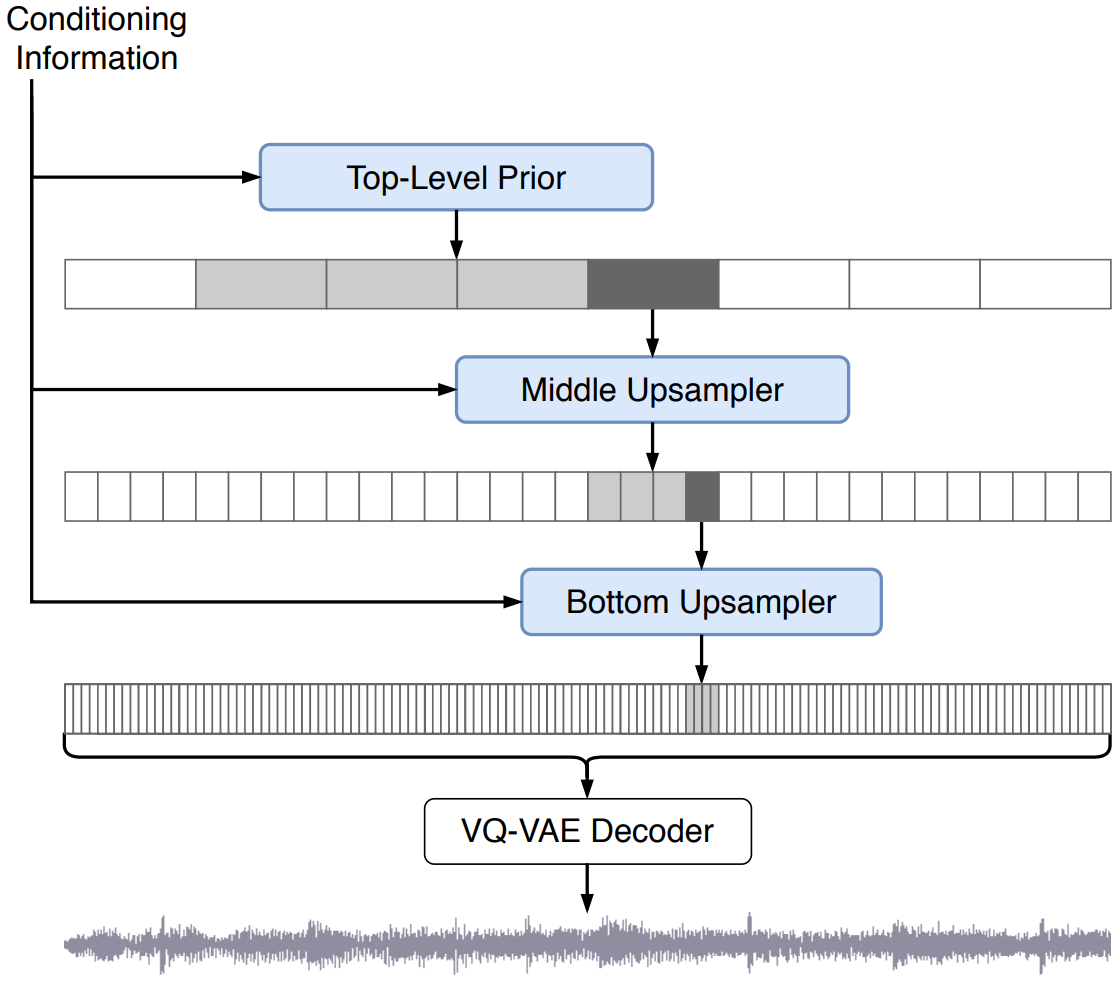
먼저 일반적인 top-level 샘플링 프로세스(위 그림 참조)를 통해 top level 코드를 한 번에 하나씩 생성한다. 첫 번째 토큰을 생성한 다음 이전에 생성된 모든 토큰을 입력으로 모델에 전달하고 모든 이전 토큰으로 컨디셔닝하여 다음 토큰을 출력한다. 그런 다음 top level 코드에서 conditioning wavenet을 실행하여 middle level에 대한 컨디셔닝 정보를 생성하고 그로부터 ancestral sampling을하고 bottom level에 대해서도 동일한 작업을 수행한다.
Windowed sampling
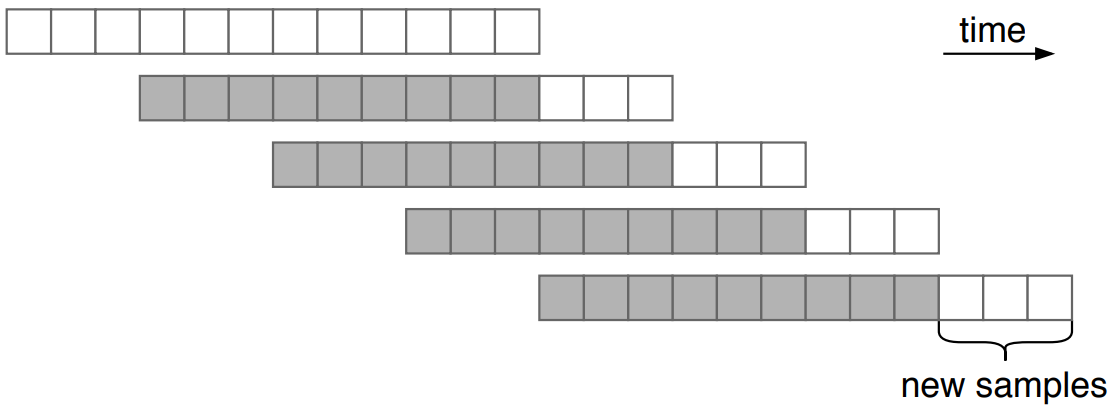
컨텍스트 길이보다 긴 세그먼트를 샘플링하기 위해 sampling window를 컨텍스트의 절반만큼 앞으로 이동하고 이 절반 컨텍스트에서 조건부 샘플링을 계속하는 window sampling을 사용한다 (위 그림 참조). 여기에서 더 작은 hop length를 사용하여 속도와 품질을 절충할 수 있다.
Primed sampling
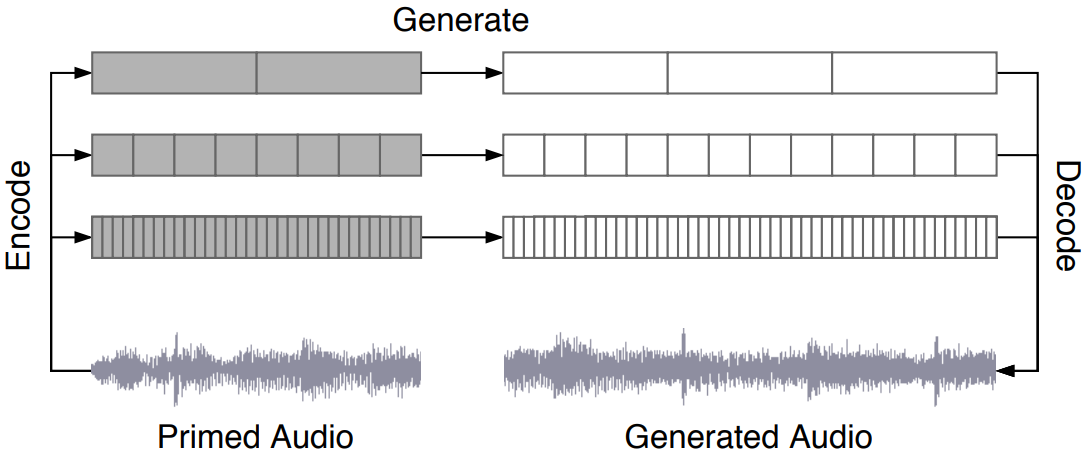
모델에서 전체 토큰 시퀀스를 샘플링하는 대신 위 그림과 같이 실제 노래의 세그먼트에 해당하는 top, middle, bottom level 코드를 얻기 위해 VQ-VAE의 forward pass를 실행할 수도 있다. Ancestral sampling 과정에서 이것을 초기 토큰으로 사용할 수 있고 이것들로부터 계속 샘플링하여 노래의 새로운 완성을 생성할 수 있다.
Experiments
- 데이터셋
- LyricWiki의 메타데이터와 가사를 쌍으로 한 120만 개의 노래에 대한 새로운 데이터셋을 구성
- 메타데이터는 각 노래의 아티스트, 앨범, 장르, 발매년도, 분위기, 플레이리스트 키워드로 구성
- 32bit, 44.1kHz의 오디오의 오른쪽과 왼쪽 채널을 랜덤하게 다운믹싱하여 data augmentation을 수행하여 모노 채널 오디오를 생성
- Training Details
- 음악 VQ-VAE의 경우 각 레벨에 대해 코드북 크기 2048로 각각 8x, 32x 및 128x로 44kHz 오디오를 압축하는 3가지 레벨의 bottleneck을 사용
- VQ-VAE는 200만 개의 파라미터가 있으며 3일 동안 256개의 V100에서 9초 오디오 클립에 대해 학습
- 코드북 업데이트에 지수 이동 평균(EMA)을 사용
- Prior과 upsampler 모델의 경우 VQ-VAE 코드의 토큰 컨텍스트 8192개를 사용 (top, middle, bottom level에서 각각 약 24초, 6초, 1.5초의 오디오에 해당)
- Upsampler는 10억 개의 파라미터가 있고 128개의 V100에서 2주 동안 학습
- top-level prior는 50억 개의 파라미터가 있고 512개의 V100에서 4주 동안 학습
- Learning rate는 0.00015, weight decay 0.002, Adam optimizer 사용
- 가사 컨디셔닝을 위해 prior을 재사용하고 작은 인코더를 추가한 후 2주 동안 512개의 V100에서 모델을 학습
1. Samples
저자들은 샘플 품질을 높이는 일련의 모델들을 학습시켰다. 첫 번째 모델은 22kHz VQ-VAE 코드와 상대적으로 작은 prior 모델을 사용하여 MAESTRO 데이터셋에서 학습되었다. 저자들은 이것이 피아노와 가끔 바이올린으로 충실도가 높은 클래식 음악 샘플을 생성할 수 있음을 관찰했다. 그런 다음 장르 및 아티스트 레이블이 있는 더 크고 다양한 노래 데이터셋을 수집하였다. 동일한 모델이 이 새로운 데이터셋에서 학습되었을 때 클래식 음악 이외의 다양한 샘플을 생성할 수 있었고 1분 이상 음악성과 일관성을 보여주었다고 한다.
일반적으로 충실도가 높고 일관된 노래를 생성할 수 있다는 참신함에도 불구하고 샘플 품질은 여전히 여러 요인에 의해 제한되었다. 첫째, 작은 upsampler와 함께 22kHz 샘플링 속도를 사용하면 업샘플링 및 디코딩 단계에서 잡음이 발생하여 거친 질감으로 들렸다고 한다. 렌더링 시간이 길어지는 대신 모든 후속 실험에서 44kHz VQ-VAE와 10억 파라미터 upsampler를 사용하여 충실도를 개선했다고 한다.
둘째, 10억 파라미터의 top-level prior는 노래와 다양한 음악적 음색을 생성할 만큼 충분히 크지 않았다고 한다. 먼저 저자들은 모델 크기를 50억 개의 파라미터로 늘리는 방법을 살펴보았다. 용량이 클수록 노래의 더 넓은 분포를 더 잘 모델링할 수 있으므로 더 나은 음악성, 더 긴 일관성 및 초기 노래를 가진 샘플이 생성된다고 한다. 전반적인 질적 개선이 있지만 unconditional 모델은 여전히 인식할 수 있는 단어를 노래하는 데 어려움을 겪었다고 한다. 가사 컨디셔닝을 사용하여 seq2seq 모델을 학습시키고 주로 영어로 된 노래로만 데이터셋을 제한하여 노래를 이해하기 쉽고 제어할 수 있게 만들었다고 한다.
Jukebox라고 부르는 최종 모델은 이러한 모든 개선 사항을 사용한다. 모든 사람이 음악을 다르게 경험하기 때문에 평균 의견 점수 또는 FID와 같은 metric으로 샘플을 평가하는 것은 일반적으로 까다롭고 의미가 없다. 생성된 샘플의 일관성, 음악성, 다양성 및 참신함을 수동으로 평가하였다고 한다.
Coherence: 저자들은 샘플이 top-level prior의 컨텍스트 길이(약 24초)를 통해 음악적으로 매우 일관되게 유지되고 더 긴 샘플을 생성하기 위해 window를 슬라이드할 때 유사한 하모니와 질감을 유지한다는 것을 발견했다. 그러나 top-level에는 전체 노래의 컨텍스트가 없기 때문에 장기적인 음악 패턴을 들을 수 없으며 반복되는 후렴구나 멜로디도 들을 수 없다.
생성은 노래의 시작(ex. 박수 또는 느린 반주 워밍업), 합창처럼 들리는 섹션, 간주를 거쳐 페이드되거나 마지막에 마무리된다. Top-level prior은 항상 노래의 어느 부분이 시간적으로 완료되었는지 알고 있으므로 적절한 시작, 중간 및 끝을 모방할 수 있다.
Musicality: 샘플은 익숙한 음악적 하모니를 자주 모방하고 가사는 일반적으로 매우 자연스러운 방식으로 세팅된다. 종종 멜로디의 가장 높거나 긴 음표는 인간 가수가 강조하기로 선택한 단어와 일치하며 가사는 거의 항상 구절의 운율을 포착하는 방식으로 렌더링된다. 이것은 모델이 음성 텍스트의 리듬을 안정적으로 캡처하는 힙합 생성에서 두드러진다. 저자들은 생성된 멜로디가 일반적으로 인간이 작곡한 멜로디보다 덜 흥미롭다는 것을 발견했다. 특히 많은 인간의 선율에 친숙한 선행 및 후행 패턴을 듣을 수 없으며 선율적으로 기억에 남는 후렴구를 거의 들을 수 없다.
Diversity: Likelihood 학습은 모든 모드를 다루도록 권장하므로 모델이 다양한 샘플을 생성할 것으로 기대할 수 있다.
- Re-renditions: 학습 데이터에 존재하는 아티스트와 가사 조합을 조건으로 여러 샘플을 생성한다. 때때로 드럼과 베이스 라인 또는 멜로디 간격이 원래 버전을 반영하지만 생성된 샘플 중 어느 것도 원래 노래와 눈에 띄게 유사하지 않다. 또한 저자들은 샘플 9~12를 얻기 위해 샘플 1과 동일한 아티스트 및 가사를 조건으로 하는 여러 곡을 생성하였다. 샘플 10은 블루스 리프의 일부로 00:14에 하모닉을 연주하며 모델이 다양한 노래와 연주 스타일을 배웠음을 보여준다.
- Completions: 저자들은 12초의 기존 곡으로 모델을 priming하고 동일한 스타일로 완성하도록 요청하였다. Priming한 샘플에 노래가 포함되면 원래 곡과 리듬을 모방할 가능성이 더 크다. 더 일반적인 인트로로 준비된 노래는 더 다양한 경향이 있다. 초기에는 원본에 가까운 생성된 샘플도 약 30초 후에 완전히 새로운 음악으로 바뀐다.
- Full tree: 저자들은 보다 체계적인 방법으로 다양성을 이해하기 위해 동일한 세그먼트에서 여러 샘플을 생성하였다. 1분 샘플로 시작하여 1분 연장당 4회 독립적으로 샘플링하였다. 3분 표시까지 16개의 샘플이 있다. 이 트리를 ancestral sampling을 통해 얻은 다양한 가능성을 탐구하는 것으로 생각할 수 있다. 생성된 곡들에서 동일한 초기 세그먼트가 사용될 때에도 노래와 발전의 다양성을 들을 수 있다. 이 특정 샘플은 더 성공적으로 가사를 따른다. Window를 선형으로 이동해도 가사 정렬이 제대로 이루어지지 않는 힙합 및 랩과 같은 특정 장르의 경우 그럴듯한 노래를 얻을 가능성이 낮다.
Novelty: Jukebox는 다양한 스타일, 가사 및 오디오로 컨디셔닝할 수 있는 능력을 갖추었다.
- Novel styles: 저자들은 일반적으로 아티스트와 관련이 없는 특이한 장르의 노래를 생성하였다. 일반적으로 아티스트가 임베딩하는 것이 다른 정보를 압도하기 때문에 동일한 목소리를 사용하면서 새로운 스타일의 노래로 일반화하는 것이 상당히 어렵다. Joe Bonamassa와 Frank Sinatra 샘플에서 장르 임베딩에 따라 악기 편성, 에너지와 분위기의 약간의 변형을 들을 수 있다. 그러나 컨트리 가수 Alan Jackson과 힙합, 펑크와 같은 특이한 장르를 혼합하려는 시도는 의미 있는 방식으로 샘플을 컨트리 스타일에서 멀어지게 하지 않았다.
- Novel voices: 저자들은 목소리가 모델에 의해 합리적으로 잘 재생되는 아티스트를 선택하고 그들의 스타일 임베딩을 보간하여 새로운 목소리를 합성하였다. 예를 들어 샘플 4에서 Frank Sinatra와 Alan Jackson 사이의 일부 혼합은 여전히 Frank Sinatra와 유사하게 들린다. 대부분의 경우 모델은 모호하게 인식할 수 있지만 다른 보컬 특성을 유지하는 뚜렷한 음성으로 렌더링된다. Céline Dion 임베딩을 2로 나누어 컨디셔닝한 샘플 1과 2는 음색과 톤이 약간 다르지만 고유한 비브라토를 캡처한다. 또한 저자들은 듀엣을 만들기 위해 노래 중간에 포함된 스타일을 변경하여 실험하였다. 이것은 샘플링 중에 생성을 안내하는 또 다른 방법이다. 다른 음성으로 계속하는 것은 세그먼트가 간주로 끝날 때 가장 잘 작동하며, 그렇지 않으면 모델이 단어나 문장 중간에 음성을 혼합한다.
- Novel lyrics: 저자들은 GPT-2가 생성한 시와 소설 구절로 노래하도록 jukebox에게 요청하여 실제로 새로운 가사를 부를 수 있음을 입증하려고 하였다. 학습 데이터는 제한된 어휘와 제한된 구조의 노래 가사로 구성되어 있지만 모델은 대부분의 프롬프트를 따르고 합리적으로 발음할 수 있는 새로운 단어까지 노래하는 방법을 배웠다. 그러나 최상의 결과를 얻으려면 어려운 단어를 말할 때 철자를 사용하는 것이 유용하다. 텍스트가 길이와 운율 또는 리듬 품질 측면에서 주어진 아티스트의 가사 분포와 일치하는 경우 생성의 품질이 눈에 띄게 높아진다. 예를 들어 힙합의 가사는 대부분의 다른 장르보다 긴 경향이 있고, 흔히 강조되는 음절은 명확한 리듬을 형성하기 쉽다.
- Novel riffs: Jukebox는 불완전한 아이디어를 녹음하고 symbolic 표현으로 표로 만들 필요 없이 다양한 샘플을 탐색할 수 있는 능력을 가지고 있다. 저자들은 사내 뮤지션의 참신한 리프 녹음을 선별하고 샘플링 시 모델을 priming하였다. 샘플 6은 Elton John의 노래에서 널리 사용되지 않는 음악 스타일로 시작한다. 모델은 여전히 조율을 수행하고 더 발전시킨다. 마찬가지로 샘플 1의 시작 부분은 힙합에서 사용된 적이 없는 5/4 polymeter가 있는 재즈 곡이다. 이러한 참신함에도 불구하고 리듬은 노래 전체에 걸쳐 지속되며 랩과 자연스럽게 통합된다.
2. VQ-VAE Ablations
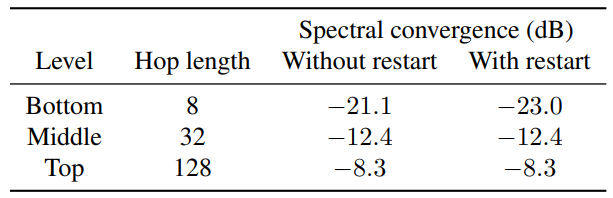
다음은 hop length에 따른 재구성 오차를 나타낸 표이다 (Spectral convergence거 작을수록 재구성 오차가 적음).
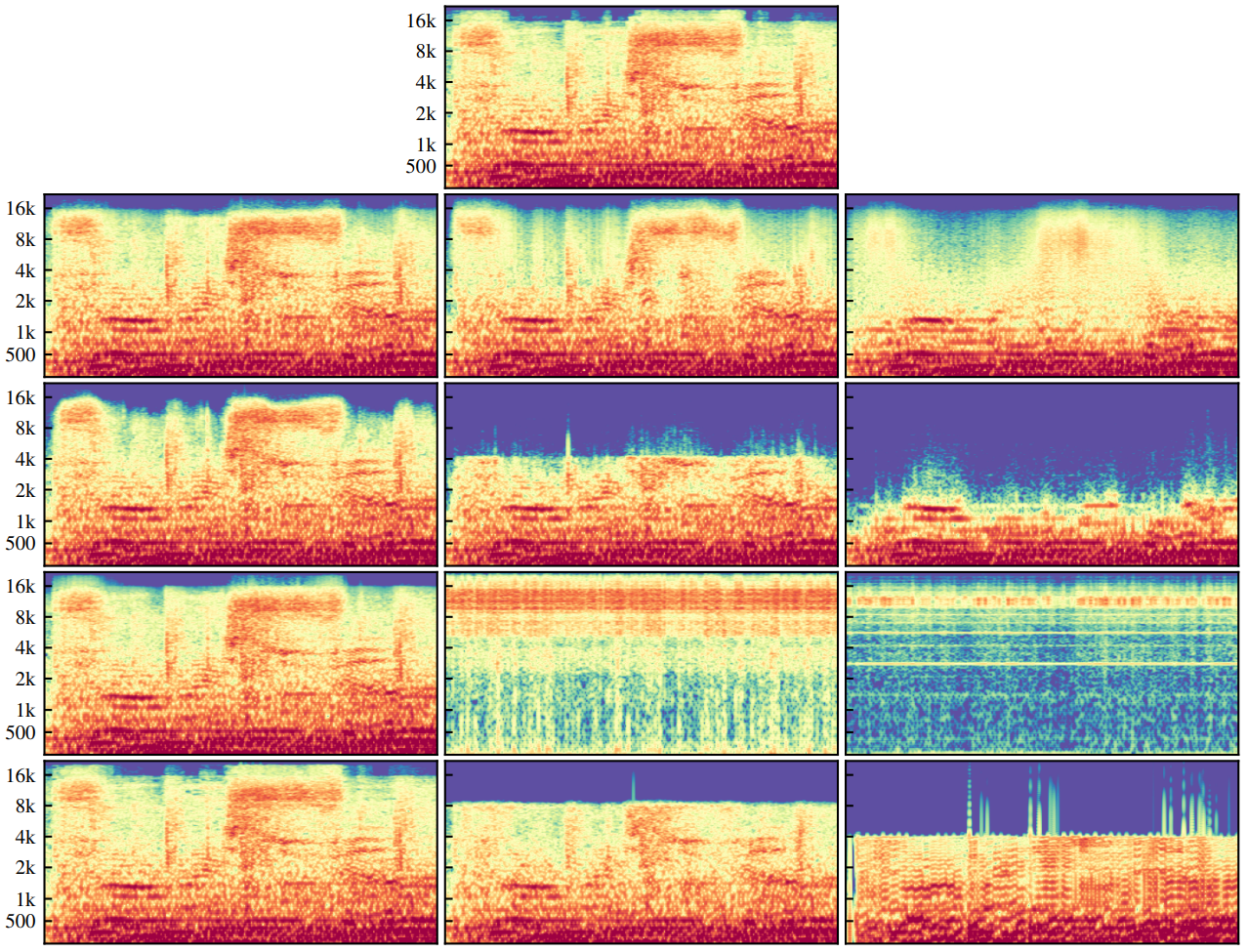
다음은 여러 VQ-VAE에 대한 재구성 결과이다. 왼쪽부터 bottom-level, middle-level, top-level 재구성 결과이다.
다음은 학습 중에 코드북의 엔트로피의 변화를 나타낸 그래프이다.
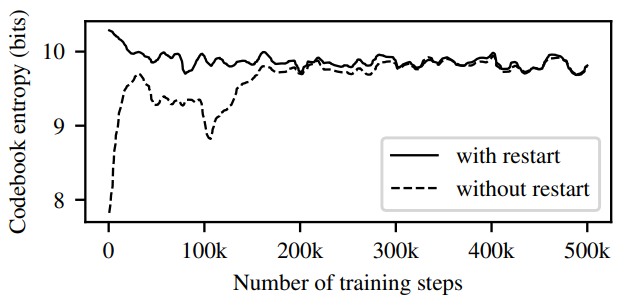
코드북 재시작은 학습 초기부터 더 높은 코드북 사용을 가져온다는 것을 알 수 있다.
다음은 코드북 크기에 따른 재구성 오차를 나타낸 표이다.

다음 표는 spectral loss를 사용하지 않거나 단일 autoencoder를 사용하면 top level 코드를 학습하기 어려움을 보여준다.
