[논문리뷰] Intrinsic Image Diffusion for Indoor Single-view Material Estimation
CVPR 2024. [Paper] [Page] [Github]
Peter Kocsis, Vincent Sitzmann, Matthias Nießner
Technical University of Munich | MIT EECS
19 Dec 2023

Introduction
Intrinsic image decomposition는 하나의 이미지에서 기하학적 속성, 재료 속성, 조명 속성을 예측하는 것을 목표로 한다. 그러나 근본적인 어려움은 조명과 재료의 복잡한 상호 작용의 결과로만 물체의 시각적 외형을 관찰할 수 있다는 사실에서 비롯되며, 이는 분해를 본질적으로 모호하게 만든다.
최근의 데이터 기반 알고리즘은 사실적으로 렌더링된 대규모 합성 데이터셋을 활용하여 상당한 개선을 보여주었다. 이러한 알고리즘들은 전반적인 재료 속성을 예측하는 데 인상적인 결과를 달성하지만, 고주파 디테일을 정확하게 포착하는 것은 여전히 과제이다.
기존 방법에서 관찰되는 한계는 외형 분해 문제에 대한 deterministic한 처리에 기인할 수 있다. 외형을 조명 속성과 재료 속성으로 분해하는 것은 조명 속성이 재료에 baking될 수 있고 그 반대의 경우도 마찬가지이기 때문에 매우 모호한 작업이다. 하나의 솔루션을 내야 한다는 제약을 부과함으로써 deterministic한 모델은 해공간의 로컬 또는 글로벌 평균을 예측하는 경향이 있어 앞서 언급한 문제가 발생한다. 저자들은 문제의 확률적 특성을 수용하여 해공간을 보다 포괄적으로 탐색할 것을 제안하였다.
본 논문에서는 하나의 뷰에 대한 외형 분해를 확률적인 문제로 공식화하는 것을 제안하였다. 이를 위해 입력 이미지로 컨디셔닝된 해공간에서 샘플링할 수 있는 생성 모델을 개발한다. 구체적으로, 단일 이미지의 기본 재료 속성을 예측하기 위해 조건부 diffusion model을 학습시킨다. 이를 통해 deterministic한 모델의 한계를 극복하고 외형 분해 문제에 대한 보다 포괄적이고 정확한 표현을 제공하는 것을 목표로 한다.
아직 대규모 현실 intrinsic image decomposition 데이터셋이 없기 때문에 이전 방법들은 일반적으로 합성 데이터에서 학습하고 실제 데이터셋인 IIW에서 fine-tuning하여 도메인 차이를 줄였다. 본 논문은 그 대신에 사전 학습된 Stable Diffusion V2 모델의 강력한 prior를 활용하고 이를 사실적인 합성 데이터셋인 InteriorVerse에서 fine-tuning한다.
본 논문의 접근 방식은 하나의 솔루션을 예측하는 데 국한되지 않는다. 따라서 로컬 또는 글로벌 평균 없이 주어진 관찰에 대한 명확하고 날카로운 설명을 제공한다. 또한 사전 학습된 diffusion model의 강력한 prior를 적용하여 합성 이미지에 대한 fine-tuning으로 인해 발생하는 도메인 차이를 줄이고, 실제 이미지의 prior에서 재료 추정에 도움이 될 수 있는 중요한 단서 (ex. semantic 정보)를 가져온다.
Method
- 입력: 하나의 입력 이미지 ($x \in \mathbb{R}^{H \times W \times 3}$)
- 출력: albedo, roughness, metallic ($\hat{m} \in \mathbb{R}^{H \times W \times 5}$)
1. Material representation
단일 이미지에서 재료를 추정하려면 재료 속성을 조명 속성에서 분리해야 한다. 이 task에는 두 가지 주요 과제가 있다.
- 외형 분해가 매우 모호하다. 여러 (재료, 조명) 쌍이 동일한 입력 뷰를 설명할 수 있다. 또한 그림자나 specular highlight와 같은 shading 효과를 재료에 baking하여 다양한 조명 조건에 대한 유효한 설명을 제공할 수 있다.
- 컴퓨터 그래픽스에 사용되는 재료 모델은 실제 반사율 속성의 근사치이다. 물리적 기반일 수 있지만 실제 반사율을 정확히 포착하지 못해 차이가 발생한다.
재료는 albedo, roughness, metallic 속성으로 구성된 물리 기반 GGX microfacet BRDF로 표현된다. BRDF 파라미터는 이미지로 생성하는데, 채널 R은 roughness이고, G는 metallic이며, B는 항상 0이다. Latent를 얻기 위해 BRDF 속성과 albedo를 각각 4$\times$64$\times$64로 인코딩한다.
2. Training
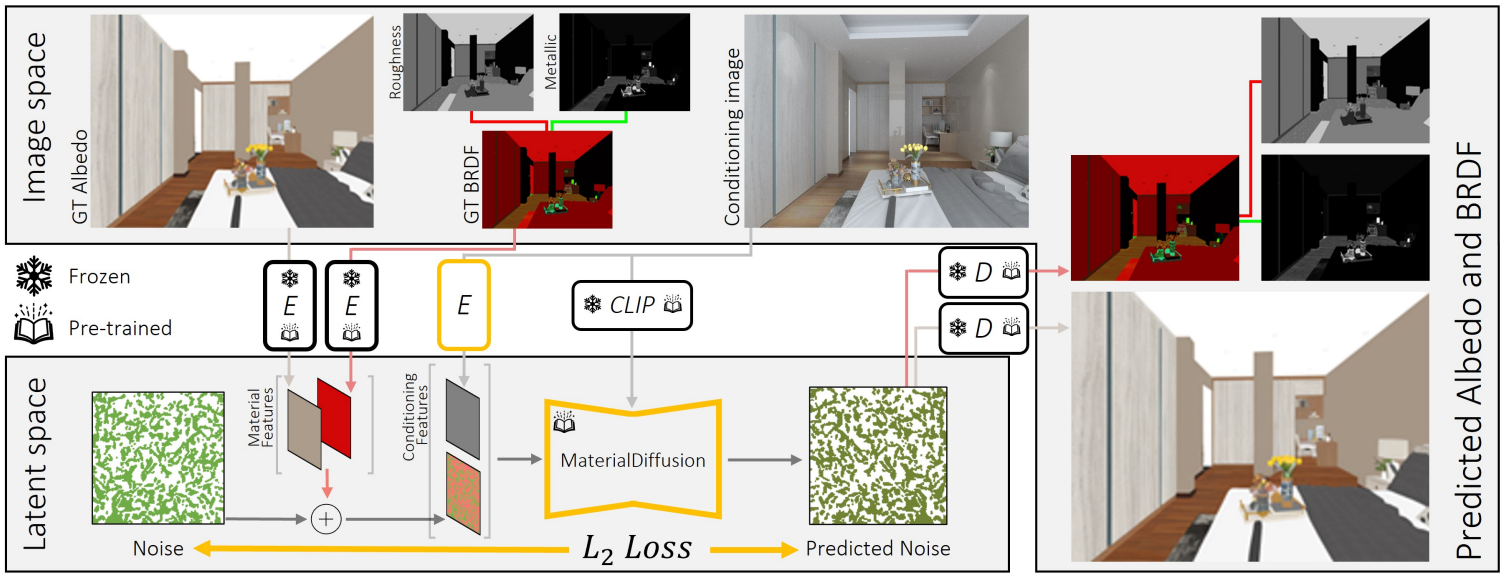
본 논문의 목표는 학습된 prior를 활용하여 재료 추정에 맞게 조정하는 것이다. 이를 위해 합성 데이터로 사전 학습된 텍스트 조건부 Stable Diffusion (SD) V2를 fine-tuning한다. SD V2와 마찬가지로 사전 학습된 고정 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$를 사용한 latent diffusion 아키텍처를 따른다.
Diffusion model을 컨디셔닝하기 위해 두 가지 방법으로 이미지 정보를 모델에 입력한다.
- 이미지를 학습된 인코더 $\mathcal{E}^\ast$로 인코딩하고 noisy한 입력 feature에 concatenate한다. 인코더 $\mathcal{E}^\ast$는 사전 학습된 인코더 $\mathcal{E}$와 동일한 아키텍처를 사용하지만 랜덤하게 초기화되고 3채널 feature를 제공한다. Latent 차원으로 단순하게 다운스케일링하면 고주파 디테일이 손실된다. 고정된 사전 학습된 인코더 $\mathcal{E}$를 사용하면 성능이 떨어지므로 재료 추정 시에는 최적의 예측을 위해 다른 feature 세트가 필요하다.
- Cross-attention conditioner로 CLIP 이미지 임베딩을 사용한다.
각 학습 step에서 albedo와 BRDF 맵이 있는 이미지 batch를 가져온다. 두 맵을 개별적으로 인코딩한 다음 latent space에서 concatenate하여 8채널의 material feature를 얻는다. 각 이미지에 대해 timestep $t \sim [1, 1000]$를 샘플링하고 material feature에 noise를 적용한다. 여기에 $\mathcal{E}^\ast$로 인코딩한 3채널의 컨디셔닝 feature를 concatenate하여 11채널로 모델에 입력한다. 모델은 추가된 noise $\epsilon$을 예측하며, 원본 nosie $\epsilon$와 예측된 noise $\epsilon_\theta$ 사이의 거리를 최소화하여 모델을 학습시킨다.
\[\begin{equation} L = \mathbb{E}_{m, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (\mathcal{E} (m) + \epsilon, t, x) \|_2^2] \end{equation}\]이전 방법들은 합성 데이터에서 학습된 prior를 더 작은 현실 데이터셋에서 fine-tuning하였다. 이와 달리, 본 논문의 방법은 대규모 실제 이미지 데이터에서 학습된 prior을 fine-tuning하고 합성 데이터에서 fine-tuning한다.
3. Inference
Inference 시에는 일반 diffusion process를 사용한다. 예측된 material feature를 albedo feature와 BRDF feature로 분할하고 각각 디코딩하여 albedo, roughness, metallic을 얻는다. 한 이미지에 대한 가능한 여러 솔루션을 샘플링한다.
4. Lighting optimization

높은 충실도의 일관된 재료 예측을 바탕으로 장면의 조명을 최적화하며, 하이브리드 조명 표현을 사용한다. 글로벌 및 아웃 오브 뷰 조명 효과의 경우 Spherical Gaussian (SG)으로 parameterize된 사전 통합 환경 조명을 사용한다. 그러나 실내 장면은 종종 물체 근처에 여러 개의 광원이 있고, emission profile이 서로 다르고 색상이 다양하여 공간적으로 다양한 조명 표현이 필요하기 때문에 이러한 표현만으로는 충분하지 않다. 제어 가능하면서도 표현력이 풍부한 표현을 위해 추가로 \(N_\textrm{light}\)개의 point light를 사용한다.
구체적으로, 글로벌 environment map과 각 point light에 대해 별도의 3채널 가중치가 있는 \(N_\textrm{sg}\)개의 SG를 사용한다. Point light 위치는 이미지 공간의 그리드에 초기화되며, 정규화된 깊이 공간에서 표면으로부터 normal 방향으로 0.01 offset만큼 3D로 backprojection된다. Emission profile은 최소한의 uniform emission으로 초기화된다.
예측된 재료 속성과 OmniData의 normal 추정치를 사용하여 장면을 다시 렌더링하고 L2 reconstruction loss로 조명 파라미터를 최적화한다. 각 픽셀에 대해 모든 광원을 고려하지만 가려짐은 고려하지 않는다. 저자들은 OmniData로 추정한 깊이의 절대값을 사용하면 최적화가 더 안정적이라는 것을 발견했다. 그렇지 않으면 광원이 장면 밖의 물체 뒤로 이동하더라도 더 이상 기울기를 받지 못하기 때문이다.
정규화가 없다면 이 표현은 실제 광원 주변의 구에 여러 개의 point light가 분포된 하나의 광원을 표현하는 것으로 끝날 수 있다. 이러한 시나리오를 피하기 위해 두 개의 정규화 항과 adaptive pruning을 적용하여 최소한의 point light를 사용하도록 한다. 모든 SG의 emission 가중치 $w_j$를 정규화하고 가장 가까운 표면 $d_\textrm{near}$의 역수로 페널티를 주어 반사에서 광원을 더 멀리 이동시킨다.
\[\begin{equation} L_\textrm{pos} = \sum_{i=1}^{N_\textrm{light}} \frac{1}{d_{i, \textrm{near}}}, \quad L_\textrm{val} = \sum_{i=1}^{N_\textrm{light}} \sum_{j=1}^{N_\textrm{sg}} w_{ij} \\ L = L_\textrm{rec} + \lambda_\textrm{pos} L_\textrm{pos} + \lambda_\textrm{val} L_\textrm{val} \end{equation}\]Experiments
- Fine-tuning 데이터셋: InteriorVerse
- 구현 디테일
- Stable Diffusion V2 fine-tuning
- optimizer: AdamW
- batch size: 40
- epochs: 250
- learning rate: $1 \times 10^{-5}$ (고정)
- 입력 이미지 전처리: 0.5를 평균으로 정규화 $\rightarrow$ $[0, 1]$로 클리핑 $\rightarrow$ $[-1, 1]$로 매핑
- 해상도: 256$\times$256 random crop
- 학습은 A6000 GPU 4개에서 약 6일 소요
- lighting 최적화
- \(\lambda_\textrm{pos} = 10^{-6}\), \(\lambda_\textrm{val} = 10^{-4}\), \(N_\textrm{light} = 6 \times 8\), \(N_\textrm{sg} = 2 \times 6\)
- optimizer: Adam
- 초기 learning rate: $5 \times 10^{-2}$
- loss가 정체되기 시작하면 learning rate를 0.5배로 낮추고 가장 약한 광원을 제거
- intensity가 가장 밝은 광원의 5%보다 작은 광원을 제거
- 학습은 A6000 GPU 1개에서 약 5~10분 소요
- Stable Diffusion V2 fine-tuning
1. Synthetic results
다음은 InteriorVerse에서 예측된 albedo의 품질을 다른 방법들과 비교한 것이다.
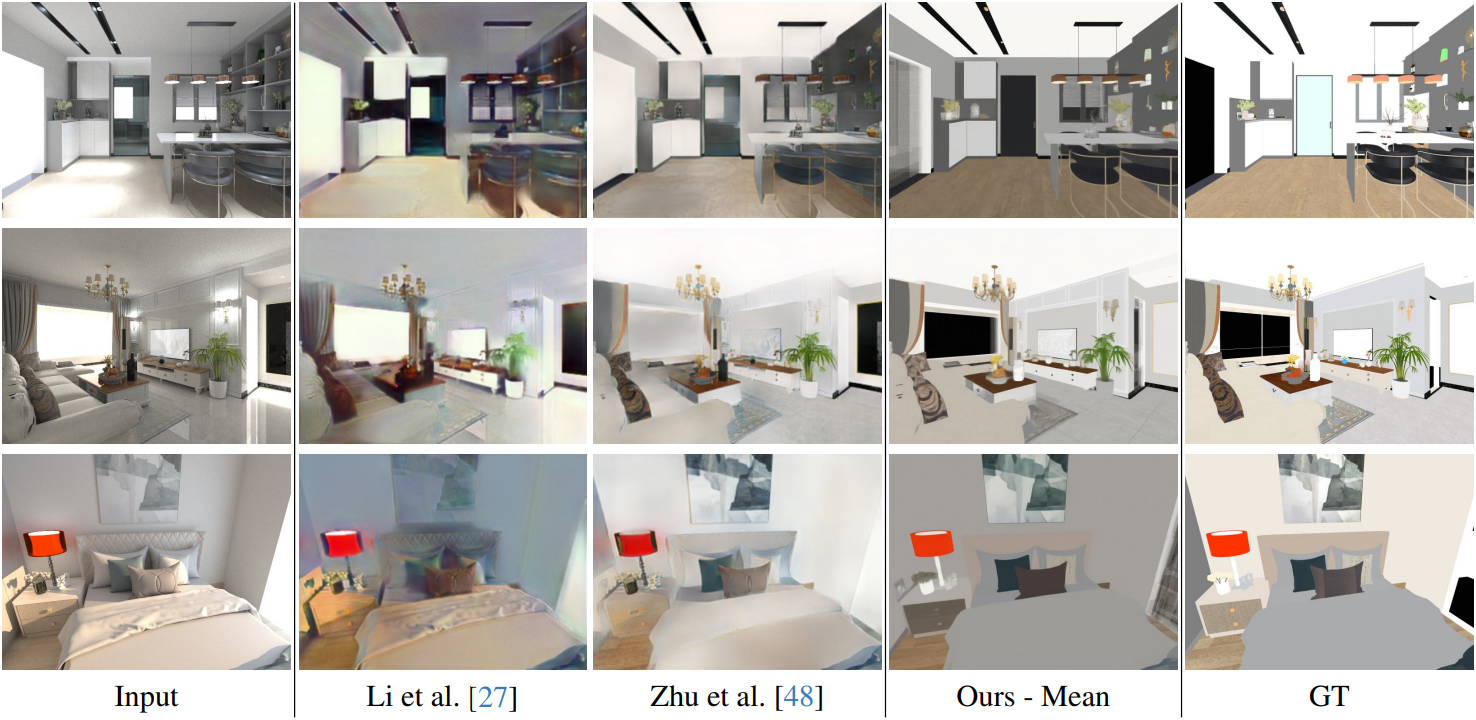
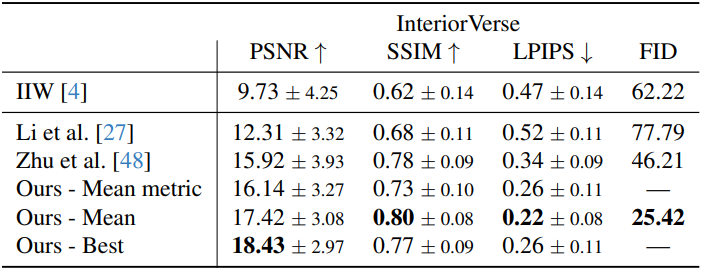
다음은 하나의 장면에 대한 예시 샘플들과 샘플 100개에 대한 분산을 시각화한 것이다.

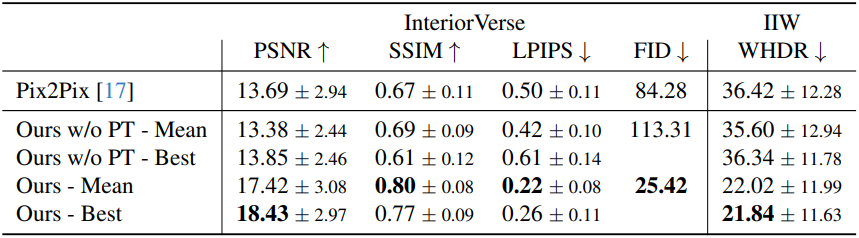
다음은 InteriorVerse에서 예측된 roughness와 metallic의 품질을 다른 방법들과 비교한 것이다.
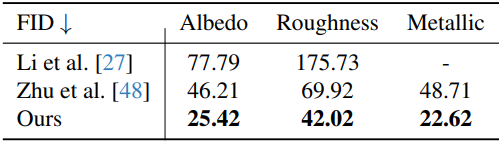
2. Real-world results
다음은 현실 데이터셋인 IIW와 ScanNet++에 대한 결과이다.

다음은 IIW에 대한 WHDR metric과 user-study로 평가한 Perceptual Quality (PQ)이다.
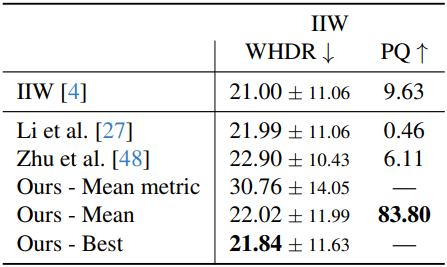
다음은 WHDR metric과 출력 albedo를 비교한 것이다. WHDR metric은 더 부드러운 결과를 선호하는 경향이 있으므로, 고주파 디테일에 대한 최적의 평가를 제공하지 못한다.

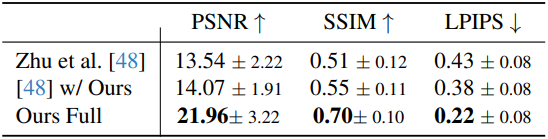
다음은 이미지 재구성 결과를 비교한 것이다.

3. Ablations
다음은 사전 학습된 prior 사용에 대한 ablation 결과이다.