[논문리뷰] Interpolating between Images with Diffusion Models
ICML 2023. [Paper] [Page] [Github]
Clinton J. Wang, Polina Golland
MIT CSAIL
24 Jul 2023

Introduction
이미지 편집은 오랫동안 컴퓨터 비전 및 생성 모델링의 중심 주제였다. 생성 모델의 발전으로 실제 이미지의 제어된 편집을 위한 점점 더 정교한 기술이 가능해졌으며, 최신 개발 중 많은 부분이 diffusion model에서 나타났다. 그러나 스타일 및/또는 콘텐츠가 다른 실제 이미지 간에 고품질 보간을 생성하는 기술은 현재까지 시연되지 않았다.
현재 이미지 보간 기술은 제한된 상황에서 작동한다. 생성된 이미지 간의 보간은 GAN에서 latent space의 특성을 연구하는 데 사용되었지만 이러한 보간은 이미지 매니폴드의 하위 집합 (ex. 사실적인 사람 얼굴)만 효과적으로 나타내기 때문에 임의의 실제 이미지로 확장하기 어려우며, 대부분의 실제 이미지를 제대로 재구성하지 못한다. 동영상 보간 기술은 스타일이 다른 이미지 사이를 부드럽게 보간하도록 설계되지 않았다. Style transfer 기술은 여러 프레임에 걸쳐 점차적으로 스타일과 콘텐츠를 동시에 전송하도록 설계되지 않았다.
본 논문은 사전 학습된 latent diffusion model을 사용하여 광범위한 도메인과 레이아웃의 이미지 간에 고품질 보간을 생성하는 방법을 소개한다. 선택적으로 포즈 추정과 CLIP 점수에 의해 가이드된다. 본 논문의 파이프라인은 텍스트 컨디셔닝, noise scheduling, 생성된 후보 중에서 수동으로 선택할 수 있는 옵션을 통해 상당한 사용자 제어를 제공하는 동시에 서로 다른 입력 이미지 쌍 간에 hyperparameter 튜닝이 거의 또는 전혀 필요하지 않기 때문에 쉽게 배포할 수 있다. 다양한 보간 방식을 비교하고 다양한 이미지 쌍 세트에 대한 정성적 결과를 제시한다.
Preliminaries
$x$를 실제 이미지라고 하자. latent diffusion model (LDM)은 인코더 $\mathcal{E}: x \mapsto z_0$, 디코더 $\mathcal{D}: z_0 \mapsto \hat{x}$, denoising U-Net $\epsilon_\theta: (z_t; t, c_\textrm{text}, c_\textrm{pose}) \mapsto \hat{\epsilon}$로 구성된다. Timestep $t$는 실제 이미지에서 파생된 latent 벡터 $z_0$가 각 step에서 소량의 noise를 합성하여 가우시안 분포 $z_T \sim \mathcal{N}(0, I)$로 매핑되는 diffusion process를 나타낸다. 각각의 noisy latent 벡터 $z_t$는 파라미터 $\alpha_t$와 $\sigma_t$에 대해
\[\begin{equation} z_t = \alpha_t z_0 + \sigma_t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]로 원래 입력과 관련될 수 있다. Denoising U-Net의 역할은 $\epsilon$를 추정하는 것이다. LDM은 여러 반복에 걸쳐 점진적으로 denoising을 수행하여 컨디셔닝 정보를 충실하게 통합하는 고품질 출력을 생성한다. $c_\textrm{text}$는 원하는 이미지를 설명하는 텍스트 (선택적으로 부정 프롬프트 포함)이고 $c_\textrm{pose}$는 인간 또는 의인화 주제에 대한 선택적 조건화 포즈를 나타낸다.
Real Image Interpolation
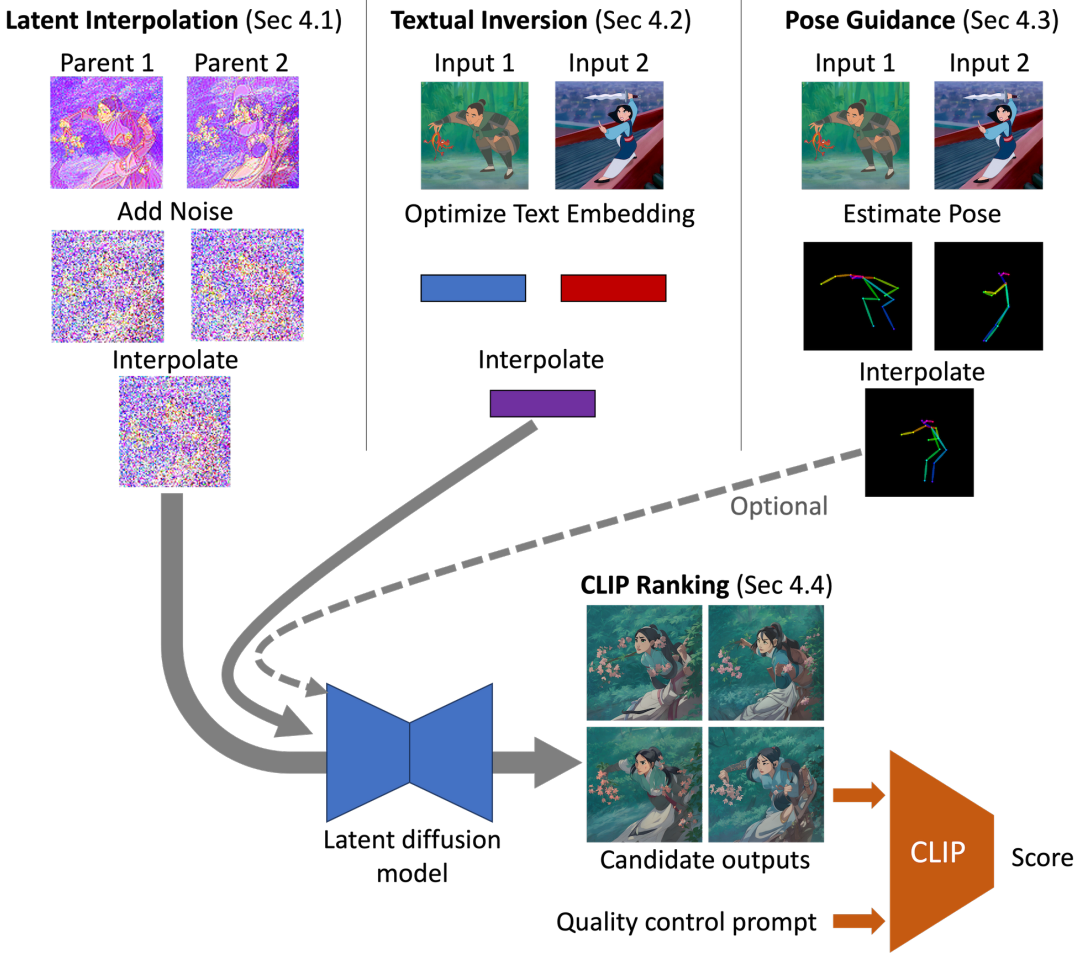
1. Latent interpolation
보간 시퀀스를 생성하기 위한 일반적인 전략은 주어진 두 개의 입력 이미지부터 시작하여 이미지 쌍을 반복적으로 보간하는 것이다. 부모 이미지의 각 쌍에 대해 latent 벡터에 공유 noise를 추가하고 보간한 다음 결과에서 noise를 제거하여 중간 이미지를 생성한다. 부모 latent 벡터에 추가할 noise의 양은 부드러운 보간을 장려하기 위해 부모가 시퀀스에서 서로 가까이 있는 경우 작아야 한다. 부모가 멀리 떨어져 있는 경우 LDM이 확률이 더 높고 다른 컨디셔닝 정보와 더 잘 일치하는 latent space에서 가까운 궤적을 탐색할 수 있도록 noise의 양이 더 커야 한다.
구체적으로 증가하는 timestep $\mathcal{T} = (t_1, \ldots, t_K)$의 시퀀스를 지정하고 다음 분기 구조를 사용하여 부모 이미지를 할당한다. 이미지 0과 $N$은 timestep $t_K$로 diffuse되고 평균화되어 이미지 $\frac{N}{2}$를 생성한다. 이미지 0과 $\frac{N}{2}$는 timestep $t_{K-1}$로 diffuse되어 이미지 $\frac{N}{4}$를 생성하고, 이미지 $\frac{N}{2}$과 $N$도 timestep $t_{K-1}$로 diffuse되어 이미지 $\frac{3N}{4}$를 생성하는 식이다. 각 부모 이미지 쌍에 개별적으로 noise를 추가함으로써 이 체계는 이미지가 부모 이미지에 가까워지도록 장려하지만 형제 이미지는 분리시킨다.
Interpolation type
Latent space와 텍스트 임베딩 보간에는 구형 선형 보간 (slerp)을 사용하고 포즈 보간에는 선형 보간을 사용한다. 경험적으로, slerp와 선형 보간 사이의 차이는 약간만 존재한다.
Noise schedule
저자들은 DDIM 샘플링을 수행하였으며, diffusion process가 최소 200개의 timestep으로 분할될 때 LDM의 품질이 더 일관됨을 발견했다. 경험적으로 schedule의 25% 미만으로 denoise된 latent 벡터는 종종 상위 이미지의 알파 합성과 유사한 반면 schedule의 65% 이상으로 생성된 이미지는 상위 이미지에서 크게 벗어날 수 있다. 각 보간에 대해 출력에서 원하는 변화량에 따라 이 범위 내에서 선형 noise schedule을 선택한다. 본 논문의 접근 방식은 유사한 결과를 산출하는 것으로 보이는 다양한 확률적 샘플러와 호환된다.
2. Textual inversion
사전 학습된 LDM은 특정 스타일의 고품질 출력을 생성하기 위해 텍스트 조건에 크게 의존한다. 각 이미지의 전체 내용 및/또는 스타일을 설명하는 초기 텍스트 프롬프트가 주어지면 textual inversion을 적용하여 임베딩을 이미지에 보다 구체적으로 적용할 수 있다. 특히 평소와 같이 텍스트 프롬프트를 인코딩한 다음 프롬프트 임베딩을 fine-tuning하여 이 임베딩으로 컨디셔닝될 때 임의의 noise 레벨에서 latent 벡터를 denoise할 때 LDM의 오차를 최소화한다. 구체적으로, loss
\[\begin{equation} \mathcal{L} (c_\textrm{text}) = \| \hat{\epsilon}_\theta (\alpha_t z_0 + \sigma_t \epsilon; t, c_\textrm{text}) − \epsilon \| \end{equation}\]와 $10^{−4}$의 learning rate로 경사 하강법을 100~500회 반복한다. 레이아웃이 복잡하거나 텍스트 프롬프트로 표현하기 어려운 스타일이 있는 이미지의 경우 반복 횟수를 늘릴 수 있다.
본 논문에서는 두 입력 이미지에 대해 동일한 초기 프롬프트를 지정하지만 완전히 자동화된 접근 방식을 캡션 모델로 대체할 수도 있다. 긍정 및 부정 텍스트 프롬프트가 모두 사용되고 최적화되며 각 이미지 쌍에 대해 부정 프롬프트를 공유한다. 사용자 지정 토큰이 필요하지 않으므로 전체 텍스트 임베딩을 최적화하도록 선택한다.
3. Pose guidance
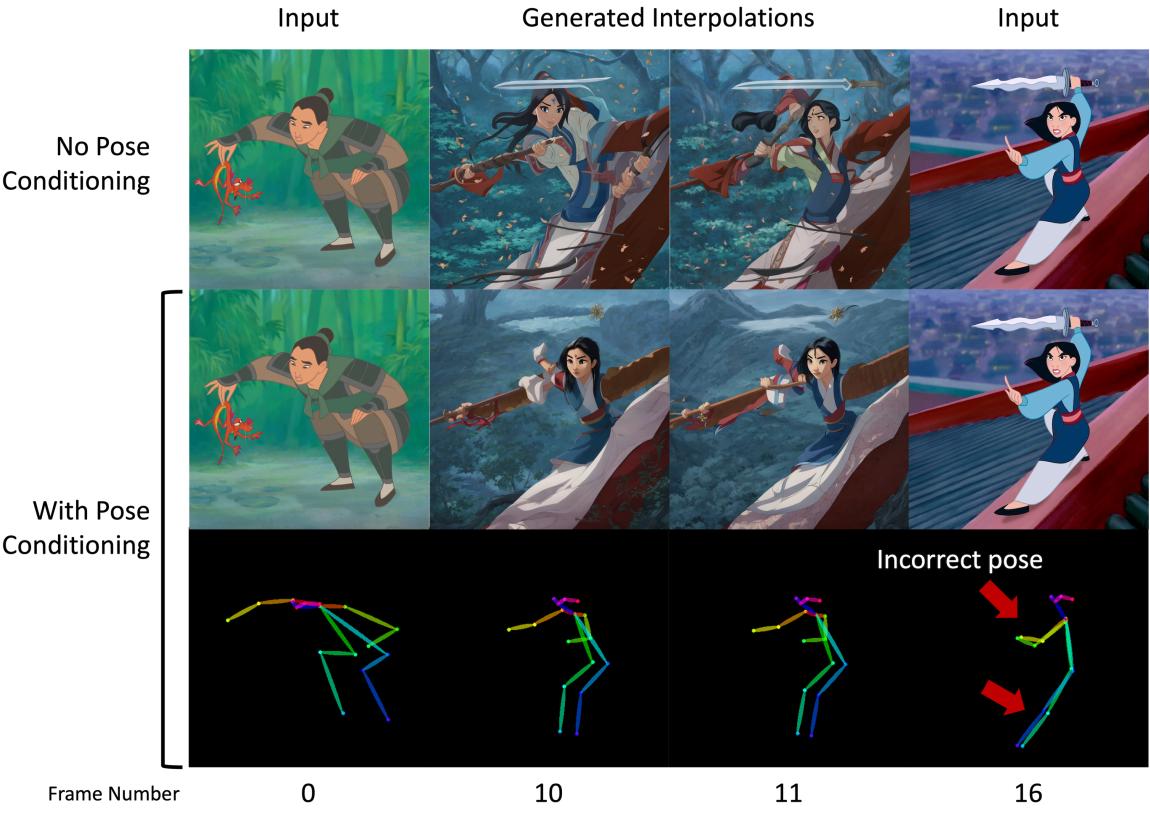
피사체의 포즈가 두 이미지 간에 크게 다른 경우 이미지 보간이 어렵고 종종 팔다리와 얼굴이 여러 개인 것과 같은 해부학적 오류가 발생한다. LDM에 포즈 컨디셔닝 정보를 통합하여 다른 포즈의 피사체 간에 보다 그럴듯한 전환을 얻는다. 아래 그림과 같이 OpenPose를 사용하여 만화 또는 인간이 아닌 피사체에 대한 style transfer의 도움으로 입력 이미지의 포즈를 얻는다.
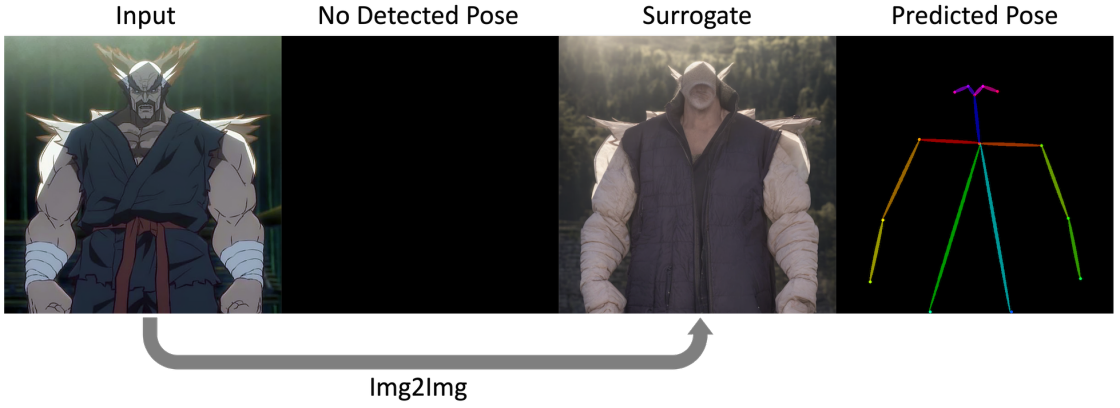
그런 다음 두 이미지의 모든 공유 키포인트 위치를 선형 보간하여 각 이미지의 중간 포즈를 얻는다. 결과 포즈는 임의의 이미지 입력을 컨디셔닝하는 강력한 방법인 ControlNet을 사용하여 LDM에 제공된다. 흥미롭게도 입력 이미지에 대해 잘못된 포즈가 예측되는 경우에도 포즈에 대한 컨디셔닝이 급격한 포즈 변경을 방지하기 때문에 여전히 우수한 보간을 생성한다는 것을 관찰할 수 있다 (아래 그림 참조).
4. CLIP ranking
LDM은 서로 다른 랜덤 시드를 사용하여 매우 다양한 품질과 특성의 출력을 생성할 수 있다. 이 문제는 하나의 잘못 생성된 이미지가 여기에서 파생된 다른 모든 이미지의 품질을 손상시키므로 실제 이미지 보간에서 복잡해진다. 따라서 속도보다 품질이 더 중요한 경우 서로 다른 랜덤 시드를 사용하여 여러 후보를 생성한 다음 CLIP으로 순위를 매길 수 있다. 서로 다른 noise 벡터를 사용하여 각 forward diffusion step을 반복하고 보간된 각 latent 벡터의 noise를 제거한 다음 지정된 긍정 및 부정 프롬프트로 디코딩된 이미지의 CLIP 유사도를 측정한다 (ex. 긍정: “고품질, 상세, 2D”, 부정: “흐릿한, 왜곡된, 3D 렌더링”). 양의 유사도에서 음의 유사도를 뺀 값이 가장 높은 이미지가 유지된다. 더 높은 수준의 제어와 품질이 필요한 애플리케이션에서 이 파이프라인은 사용자가 원하는 보간을 수동으로 선택하거나 특정 이미지에 대한 새 프롬프트 또는 포즈를 지정할 수 있는 인터랙티브 모드로 변경할 수 있다.
Experiments
1. Latent Interpolation
저자들은 다음과 같은 여러 baseline과 본 논문의 방식을 비교하였다.
Interpolate only
\[\begin{equation} z_0^0 := \mathcal{E} (x^0), \quad z_0^N := \mathcal{E} (x^N) \\ z_0^i = \textrm{slerp} (z_0^0, z_0^N, i/N) \\ x^i := \mathcal{D} (z_0^i) \end{equation}\]Interpolate-denoise
\[\begin{aligned} z_t^0 &= \alpha_t z_{t-1}^0 + \beta_t \epsilon_t \\ z_t^N &= \alpha_t z_{t-1}^N + \beta_t \epsilon_t \\ t &:= \textrm{frame_schedule} (i) \\ z_t^i &:= \textrm{slerp} (z_t^0, z_t^N, i/N) \\ z_0^i &:= \mu_\theta (z_t^i, t) \end{aligned}\]Denoise-interpolate-denoise (DID)
모든 중간 latent를 생성하기 위해 \(\{z_t^0\}\)와 \(\{z_t^N\}\)에 의존하는 경우 높은 noise 레벨의 인접 이미지는 denoising process 중에 크게 발산할 수 있다. 대신 다음과 같이 분기 패턴으로 이미지를 보간할 수 있다. 먼저 $z_{t_1}^0$과 $z_{t_1}^N$의 보간으로 $z_{t_1}^{N/2}$을 생성하고 시간 $t_2$까지 denoise한 다음 $z_{t_2}^0$과 $z_{t_2}^{N/2}$의 보간으로 $z_{t_2}^{N/4}$를 생성한다. 그리고 비슷하게 $z_{t_2}^{3N/4}$를 생성한다. 이 두 개의 새로운 latent는 시간 $t_3$까지 denoise될 수 있다. 분기 계수는 모든 레벨에서 수정할 수 있으므로 총 프레임 수가 2의 거듭제곱이 될 필요가 없다.
Results
다음은 동일한 입력에 대한 여러 보간 방식의 결과를 비교한 것이다.

다음은 여러 보간 방식을 정량적으로 비교한 표이다.

2. Extensions
다음은 보간을 이미지의 affine 변환과 결합한 결과이다.

Limitations
본 논문의 방법은 스타일과 레이아웃에 큰 차이가 있는 이미지 쌍을 보간하지 못할 수 있다.

위 그림은 모델이 피사체의 포즈를 감지 및 보간할 수 없는 경우 (상단), 프레임에 있는 개체 간의 semantic 매핑을 이해하지 못하는 경우 (가운데), 매우 다른 스타일 간에 설득력 있는 보간을 생성하는 데 어려움을 겪는 경우 (아래)의 예를 보여준다. 또한 모델이 때때로 가짜 텍스트를 삽입할 수 있으며, pose guidance가 주어져도 신체 부위를 혼동할 수 있다.