[논문리뷰] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
CVPR 2023. [Paper] [Github]
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, Xiaogang Wang, Yu Qiao
Shanghai AI Laboratory | Tsinghua University | Nanjing University | SenseTime Research | The Chinese University of Hong Kong
10 Nov 2022
Introduction
대규모 언어 모델에서 transformer의 놀라운 성공으로 vision transformer (ViT)도 컴퓨터 비전 분야를 휩쓸었고 대규모 vision foundation model의 연구 및 실행을 위한 주요 선택이 되고 있다. 일부 선구자들은 ViT를 10억 개 이상의 파라미터가 있는 매우 큰 모델로 확장하여 CNN을 능가하고 기본 분류, 감지, 분할을 포함한 광범위한 컴퓨터 비전 task에 대한 성능 한계를 크게 끌어올리려는 시도를 했다. 이러한 결과는 대규모 파라미터 및 데이터 시대에 CNN이 ViT보다 열등함을 시사하지만, CNN 기반 foundation model도 유사한 연산자/아키텍처 레벨 설계, scaling-up 파라미터, 방대한 데이터를 갖추고 있을 때 ViT와 비슷하거나 더 나은 성능을 달성할 수 있다.
CNN과 ViT 사이의 격차를 해소하기 위해 먼저 두 가지 측면에서 차이점을 요약한다.
- 연산자 레벨에서 ViT의 Multi-Head Self-Attention (MHSA)에는 장거리 의존성 (long-range dependency)과 적응형 공간 집계가 있다. 유연한 MHSA의 이점을 활용하여 ViT는 방대한 데이터에서 CNN보다 더 강력하고 robust한 표현을 학습할 수 있다.
- 아키텍처 관점에서 볼 때 ViT는 MHSA 외에도 Layer Normalization (LN), Feed-Forward Network (FFN), GELU 등 표준 CNN에 포함되지 않는 일련의 고급 구성 요소를 포함한다.
최근 연구들에서 의미 있는 시도가 있었지만 매우 큰 커널 (ex. 31$\times$31)이 있는 dense convolution을 사용하여 CNN에 장거리 의존성을 도입하기 위해서는 성능 및 모델 규모 측면에서 최신 대규모 ViT와 상당한 차이가 있다.
본 논문에서는 대규모 파라미터와 데이터로 효율적으로 확장할 수 있는 CNN 기반 foundation model을 설계하는 데 집중하였다. 특히 유연한 convolution 변형인 deformable convolution (DCN)으로 시작한다. Transformer와 유사한 일련의 맞춤형 블록 레벨 및 아키텍처 레벨 디자인과 결합하여 InternImage라는 새로운 convolution backbone 네트워크를 설계한다.
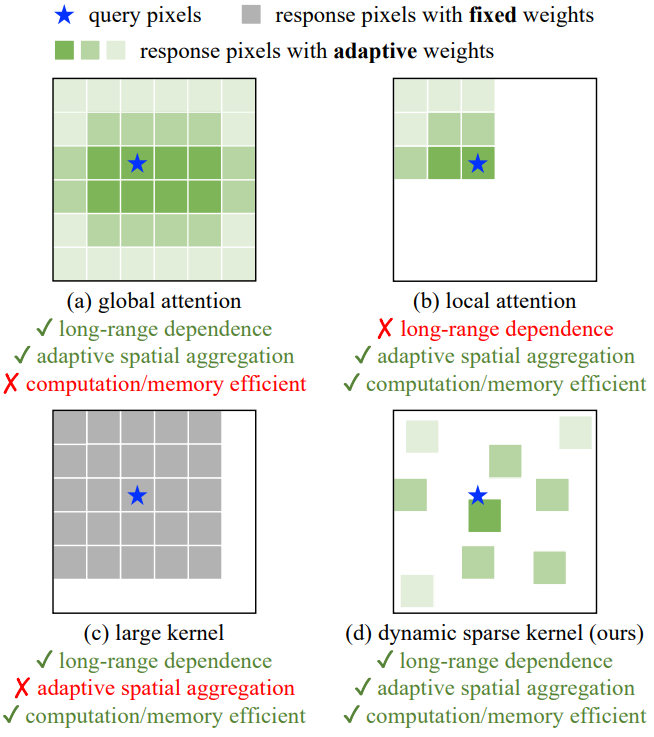
위 그림에서 볼 수 있듯이 31$\times$31과 같은 매우 큰 커널을 가진 최근 개선된 CNN과 달리 InternImage의 핵심 연산자는 3$\times$3의 공통 window 크기를 가진 dynamic sparse convolution이다. Dynamic sparse convolution의 특징은 다음과 같다.
- 샘플링 오프셋이 유연하다. 주어진 데이터에서 적절한 receptive field (장거리 또는 단거리)를 동적으로 학습한다.
- 샘플링 오프셋과 modulation 스칼라는 입력 데이터에 따라 적응적으로 조정되어 ViT와 같은 적응형 공간 집계를 달성할 수 있어 일반 convolution의 과도한 inductive bias를 줄인다.
- Convolutional window는 일반적인 3$\times$3으로, 크고 밀집된 커널로 인해 발생하는 최적화 문제와 고가의 비용을 방지한다.
앞서 언급한 설계를 통해 제안된 InternImage는 큰 파라미터 크기로 효율적으로 확장하고 대규모 학습 데이터에서 더 강력한 표현을 학습하여 광범위한 비전 task에서 대규모 ViT에 필적하거나 더 나은 성능을 달성할 수 있다.
Proposed Method
대규모 CNN 기반 foundation 모델을 설계하기 위해 deformable convolution v2 (DCNv2)라는 유연한 convolution 변형으로 시작하여 대규모 foundation model의 요구 사항에 더 잘 맞도록 이를 기반으로 약간의 조정을 한다. 그런 다음 최신 backbone에서 사용되는 고급 블록 설계와 튜닝된 convolution 연산자를 결합하여 기본 블록을 구축한다. 마지막으로 방대한 데이터에서 강력한 표현을 학습할 수 있는 대규모 convolution 모델을 구축하기 위해 DCN 기반 블록의 스태킹 및 스케일링 규칙을 탐색한다.
1. Deformable Convolution v3
Convolution vs. MHSA
이전 연구들에서는 CNN과 ViT의 차이점에 대해 광범위하게 논의했다. InternImage의 핵심 연산자를 결정하기 전에 먼저 일반적인 convolution과 MHSA의 주요 차이점을 요약한다.
- 장거리 의존성 (long-range dependencies): 큰 유효 receptive field (장거리 의존성)가 있는 모델이 일반적으로 다운스트림 비전 task에서 더 잘 수행된다는 것이 오랫동안 인식되어 왔지만 일반적인 3$\times$3 convolution이 쌓인 CNN의 사실상의 유효 receptive field는 상대적으로 작다. 매우 심층적인 모델을 사용하더라도 CNN 기반 모델은 여전히 성능을 제한하는 ViT와 같은 장거리 의존성을 획득할 수 없다.
- 적응형 공간 집계 (adaptive spatial aggregation): 가중치가 입력에 의해 동적으로 조절되는 MHSA와 비교할 때 일반 convolution은 정적 가중치와 2D locality, 이웃 구조, translation equivalence 등과 같은 강한 inductive bias를 가진 연산자이다. ViT보다 빠르게 수렴하고 학습 데이터가 덜 필요하지만 CNN이 웹 규모 데이터에서 더 일반적이고 강력한 패턴을 학습하는 것을 제한한다.
Revisiting DCNv2
Convolution과 MHSA 사이의 격차를 해소하는 직접적인 방법은 장거리 의존성과 적응형 공간 집계를 일반 convolution에 도입하는 것이다. 일반 convolution의 일반적인 변형인 DCNv2부터 시작한다. 입력 $x \in \mathbb{R}^{C \times H \times W}$와 현재 픽셀 $p_0$가 주어지면 DCNv2는 다음과 같이 공식화될 수 있다.
\[\begin{equation} y(p_0) = \sum_{k=1}^K w_k m_k x (p_0 + p_k + \Delta p_k) \end{equation}\]여기서 $K$는 총 샘플링 포인트 수를 나타내고 $k$는 샘플링 포인트를 열거한다. $w_k \in \mathbb{R}^{C \times C}$는 $k$번째 샘플링 포인트의 projection 가중치를 나타내고, $m_k \in \mathbb{R}$은 $k$번째 샘플링 포인트의 modulation 스칼라를 나타내며 시그모이드 함수에 의해 정규화된다. $p_k$는 일반 convolution과 동일하게 미리 정의된 그리드 샘플링 \(\{(−1, −1),(−1, 0), \ldots, (0, +1), \ldots, (+1, + 1)\}\)의 $k$번째 위치이고, $\Delta p_k$는 $k$번째 그리드 샘플링 위치에 해당하는 오프셋이다.
장거리 의존성의 경우 샘플링 오프셋 $\Delta p_k$가 유연하고 단거리 또는 장거리 feature와 상호 작용할 수 있음을 알 수 있다. 적응형 공간 집계의 경우 샘플링 오프셋 $\Delta p_k$와 modulation 스칼라 $m_k$ 모두 학습 가능하며 입력 $x$로 컨디셔닝된다. 따라서 DCNv2는 MHSA와 유사한 유리한 속성을 공유하고 있으며, 이는 저자들이 이 연산자를 기반으로 대규모 CNN 기반 foundation model을 개발하도록 동기를 부여했다.
Extending DCNv2 for Vision Foundation Models
일반적으로 DCNv2는 일반 convolution의 확장으로 사용되며, 일반 convolution의 사전 학습된 가중치를 로드하고 더 나은 성능을 위해 fine-tuning한다. 이는 처음부터 학습해야 하는 대규모 vision foundation model에 정확히 적합하지 않다. 본 논문에서는 이 문제를 해결하기 위해 다음과 같은 측면에서 DCNv2를 확장한다.
- Convolution 뉴런 간의 가중치 공유: 일반 convolution과 유사하게 원래 DCNv2의 서로 다른 convolution 뉴런은 독립적인 linear projection 가중치를 가지므로 해당 파라미터와 메모리 복잡도는 총 샘플링 포인트 수와 선형이므로 특히 대규모 모델에서 모델의 효율성을 크게 제한한다. 이 문제를 해결하기 위해 separable convolution에서 아이디어를 차용하고 원래 convolution 가중치 $w_k$를 깊이 부분과 포인트 부분으로 분리한다. 여기서 깊이 부분은 원래 modulation 스칼라 $m_k$가 담당하고 포인트 부분은 샘플링 포인트 간에 공유된 projection 가중치 $w$이다.
- Multi-group 메커니즘 도입: Multi-group (head) 디자인은 group convolution에서 처음 등장했으며 trasnformer의 MHSA에서 널리 사용되며 적응형 공간 집계와 함께 작동하고 서로 다른 위치의 서로 다른 표현 subspace에서 더 풍부한 정보를 효과적으로 학습한다. 이에 영감을 받아 공간 집계 프로세스를 $G$개의 그룹으로 나누었다. 각 그룹에는 개별 샘플링 오프셋 $\Delta p_{gk}$와 modulation 스케일 $m_{gk}$가 있으므로 단일 convolution 레이어의 서로 다른 그룹은 서로 다른 공간 집계 패턴을 가질 수 있고 다운스트림 task에 대해 더 강력한 feature를 제공한다.
- 샘플링 포인트에 따른 modulation 스칼라 정규화: 원본 DCNv2의 modulation 스칼라는 시그모이드 함수에 의해 element-wise로 정규화된다. 따라서 각 modulation 스칼라는 범위 $[0, 1]$에 있고 모든 샘플 포인트의 modulation 스칼라 합계는 안정적이지 않고 0에서 $K$까지 다양하다. 이로 인해 대규모 파라미터와 데이터로 학습할 때 DCNv2 레이어에서 불안정한 기울기가 발생한다. 불안정성 문제를 완화하기 위해 샘플 포인트를 따라 element-wise 시그모이드 정규화를 softmax 정규화로 변경한다. 이러한 방식으로 modulation 스칼라의 합은 1로 제한되어 다양한 규모의 모델 학습 프로세스를 보다 안정적으로 만든다.
앞서 언급한 수정 사항을 결합하여 확장된 DCNv2인 DCNv3는 다음과 같이 공식화할 수 있다.
\[\begin{equation} y (p_0) = \sum_{g=1}^G \sum_{k=1}^K w_g m_{gk} x_g (p_0 + p_k + \Delta p_{gk}) \end{equation}\]여기서 $G$는 집계 그룹의 총 개수를 나타낸다. $g$번째 그룹에 대해 $w_g \in \mathbb{R}^{C \times C’}$는 그룹의 위치와 무관한 projection 가중치를 나타내며 $C’ = C/G$는 그룹 차원을 나타낸다. $m_{gk} \in \mathbb{R}$은 차원 $K$를 따라 softmax 함수로 정규화된 $g$번째 그룹의 $k$번째 샘플링 포인트의 modulation 스칼라를 나타낸다. $x_g \in \mathbb{R}^{C’ \times H \times W}$는 슬라이스된 입력 feature map을 나타낸다. $\Delta p_{gk}$는 $g$번째 그룹의 그리드 샘플링 위치 $p_k$에 해당하는 오프셋이다.
일반적으로 DCN 시리즈의 확장인 DCNv3는 다음과 같은 세 가지 장점이 있다.
- 이 연산자는 장거리 의존성과 적응형 공간 집계 측면에서 일반 convolution의 결함을 보완했다.
- 일반적인 MHSA와 밀접하게 관련된 deformable attention과 같은 attention 기반 연산자와 비교하여 이 연산자는 convolution의 inductive bias를 상속하므로 더 적은 학습 데이터와 더 짧은 학습 시간으로 모델을 더 효율적으로 만든다.
- 이 연산자는 sparse sampling을 기반으로 하며, 이는 MHSA와 대형 커널 reparameterizing과 같은 이전 방법보다 더 계산 및 메모리 효율적이다. 또한 sparse sampling으로 인해 DCNv3은 장거리 의존성을 학습하는 데 3$\times$3 커널만 필요하므로 최적화가 더 쉽고 대형 커널에서 사용되는 reparameterizing과 같은 추가 보조 기술을 피할 수 있다.
2. InternImage Model
DCNv3를 핵심 연산자로 사용하면 새로운 질문을 할 수 있다.
DCNv3를 효과적으로 사용할 수 있는 모델을 구축하는 방법은 무엇인가?
먼저 모델의 기본 블록과 기타 필수 레이어에 대한 디테일을 제시한 다음 이러한 기본 블록에 대한 맞춤형 스태킹 전략을 탐색하여 InternImage라는 새로운 CNN 기반 foundation model을 구성한다. 마지막으로 제안된 모델에 대한 scaling-up 규칙을 연구하여 증가하는 파라미터로부터 이득을 얻는다.
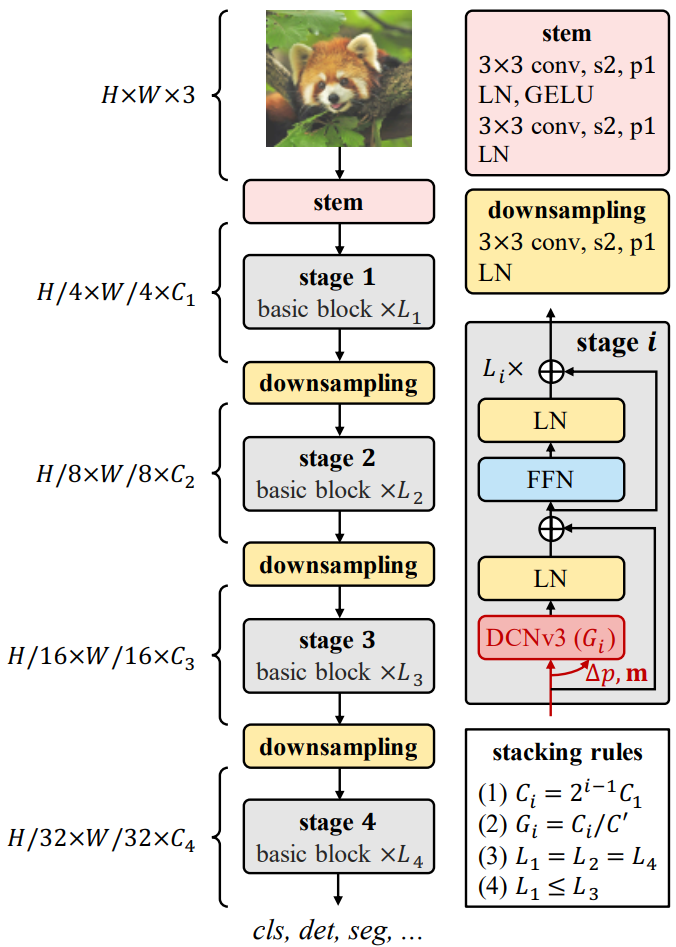
Basic block
기존 CNN에서 널리 사용되는 bottleneck과 달리 기본 블록의 설계는 LN, 피드포워드 네트워크 (FFN), GELU를 비롯한 고급 구성 요소가 장착된 ViT에 더 가깝다. 이 디자인은 다양한 비전 task에서 효율적인 것으로 입증되었다. 여기서 핵심 연산자는 DCNv3이고 샘플링 오프셋과 modulation 스케일은 separable convolution (3$\times$3 depth-wise convolution 후 linear projection)을 통해 입력 feature $x$를 전달하여 예측된다. 다른 구성 요소의 경우 기본적으로 post-normalization 설정을 사용하고 일반 trasnformer와 동일한 설계를 따른다.
Stem & downsampling layers
계층적 feature map을 얻기 위해 convolution stem과 다운샘플링 레이어를 사용하여 feature map의 크기를 다른 스케일로 resize한다. Stem 레이어는 입력 해상도를 4배로 줄이기 위해 첫 번째 stage 앞에 배치된다. 2개의 convolution, 2개의 LN 레이어, 1개의 GELU 레이어로 구성되며, 두 convolution의 커널 크기는 3, stride는 2, padding은 1이며 첫 번째 convolution의 출력 채널은 두 번째의 절반이다. 유사하게, 다운샘플링 레이어는 stride가 2이고 padding이 1인 3$\times$3 convolution으로 구성되며, 그 다음에는 하나의 LN 레이어가 있다. 두 stage 사이에 있으며 입력 feature map을 2배로 다운샘플링하는 데 사용된다.
Stacking rules
InternImage의 필수 hyperparameter는 다음과 같다.
- $C_i$: $i$번째 stage의 채널 수
- $G_i$: $i$번째 stage에서 DCNv3의 그룹 수
- $L_i$: $i$번째 stage에서 basic block의 수
본 논문의 모델은 4-stage이기 때문에 12개의 hyperparameter에 의해 변형이 결정되는데, 검색 공간이 너무 커서 완벽하게 열거하고 최적의 변형을 찾을 수 없다. 검색 공간을 줄이기 위해 다음과 같은 4개의 규칙을 둔다.
- $C_i = 2^{i-1} C_1$
- $G_i = C_i / C’$
- $L_1 = L_2 = L_4$
- $L_1 \le L_3$
첫 번째 규칙은 stage 1의 채널 수 $C_1$에 의해 결정되는 마지막 세 stage의 채널 수를 만들고, 두 번째 규칙은 stage들의 채널 수에 따른 그룹 수를 지정한다. 세 번째 규칙과 네 번째 규칙은 스태킹 패턴을 “AABA”로 단순화하며, stage 1, 2, 4의 블록 수가 동일하고 stage 3보다 작도록 한다. 이러한 규칙을 사용하면 4개의 hyperparameter $(C_1, C’, L_1, L_3)$만 사용하여 InternImage 변형을 정의할 수 있다.
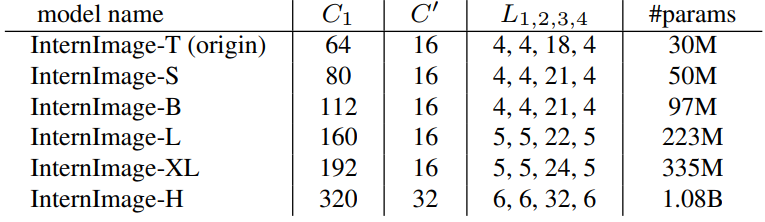
3천만 개의 파라미터가 있는 모델을 origin으로 선택하고 $C_1$을 \(\{48, 64, 80\}\)로, $L_1$을 \(\{1, 2, 3, 4, 5\}\)로, $C’$을 \(\{16, 32\}\)로 discretize한다. 이렇게 하면 원래의 거대한 검색 공간이 30개로 줄어들고 ImageNet에서 학습 및 평가하여 30개의 변형 중에서 최상의 모델을 찾을 수 있다. 실제로는 최상의 hyperparameter 설정 $(64, 16, 4, 18)$을 사용하여 origin model을 정의하고 이를 다른 스케일로 확장한다.
Scaling rules
앞서 언급한 제약 조건에서 최적의 origin model을 기반으로 파라미터 스케일링 규칙을 추가로 탐색한다. 특히 깊이 $D = 3L_1 + L_3$와 너비 $C_1$의 두 가지 스케일링 차원을 고려하고 $\alpha$, $\beta$, composite factor $\phi$를 사용하여 두 차원을 스케일링한다. 스케일링 규칙은 다음과 같이 쓸 수 있다.
\[\begin{equation} D' = \alpha^\phi D, \quad C'_1 = \beta^\phi C_1 \\ \textrm{where} \quad \alpha \ge 1, \; \beta \ge 1, \; \alpha \beta^{1.99} \approx 2 \end{equation}\]여기서 1.99는 InternImage에 고유하며 깊이를 일정하게 유지하고 모델 너비를 두 배로 늘려 계산한다. 저자들은 실험으로 최상의 스케일링 설정이 $\alpha = 1.09$, $\beta = 1.36$이라는 것을 알아냈으며, 이를 기반으로 다른 파라미터 스케일을 ConvNeXt와 복잡도가 유사하게 구성하여 InternImage-T/S/B/L/XL로 InternImage 변형을 구성하였다. 저자들은 능력을 추가로 테스트하기 위해 10억 개의 파라미터가 있는 더 큰 InternImage-H를 구축했으며 매우 큰 모델 너비를 수용하기 위해 그룹 차원 $C’$을 32로 변경했다. 구성은 표 1에 요약되어 있다.
Experiment
1. Image Classification
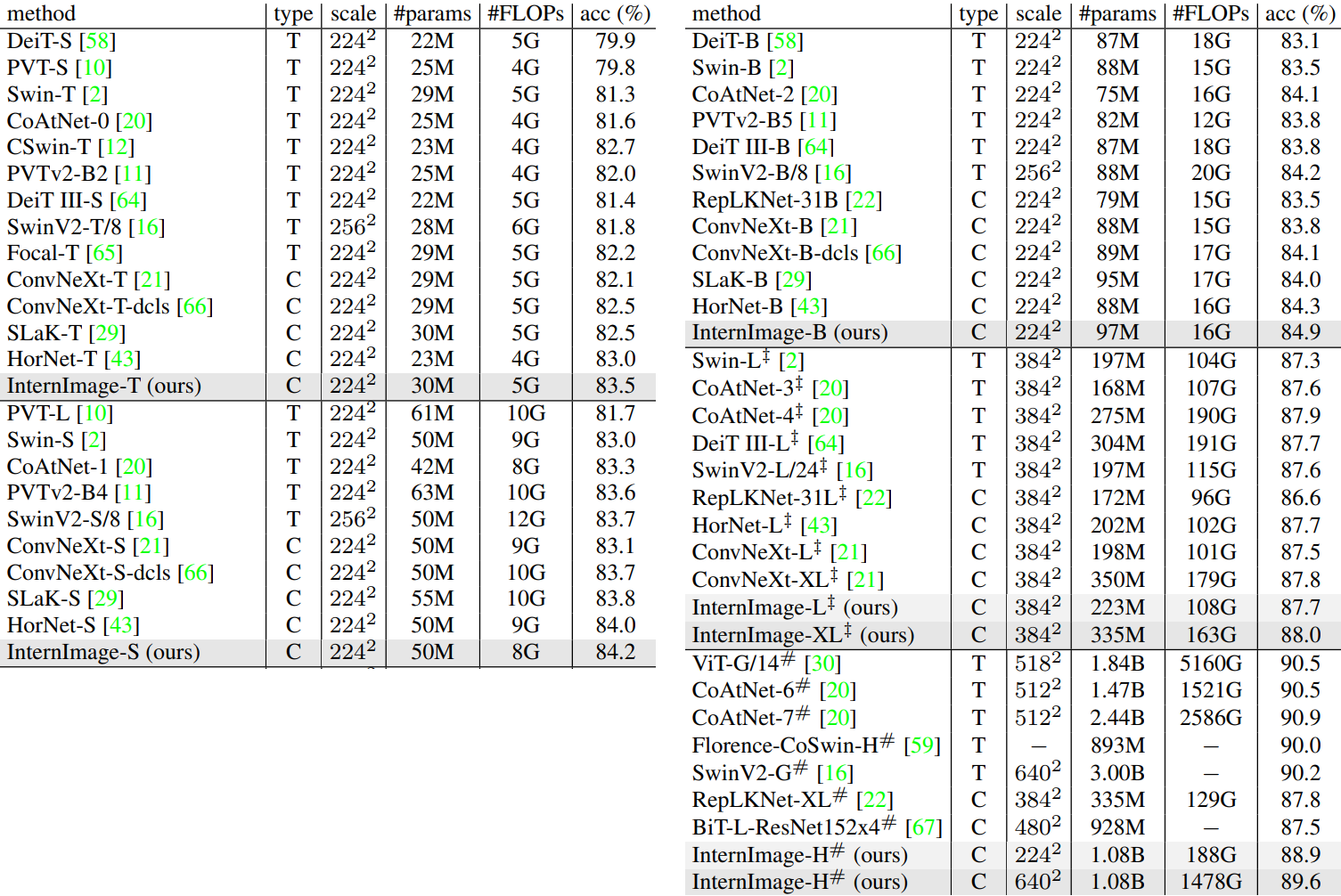
다음은 ImageNet validation set에서의 이미지 분류 성능을 나타낸 표이다.
2. Object Detection
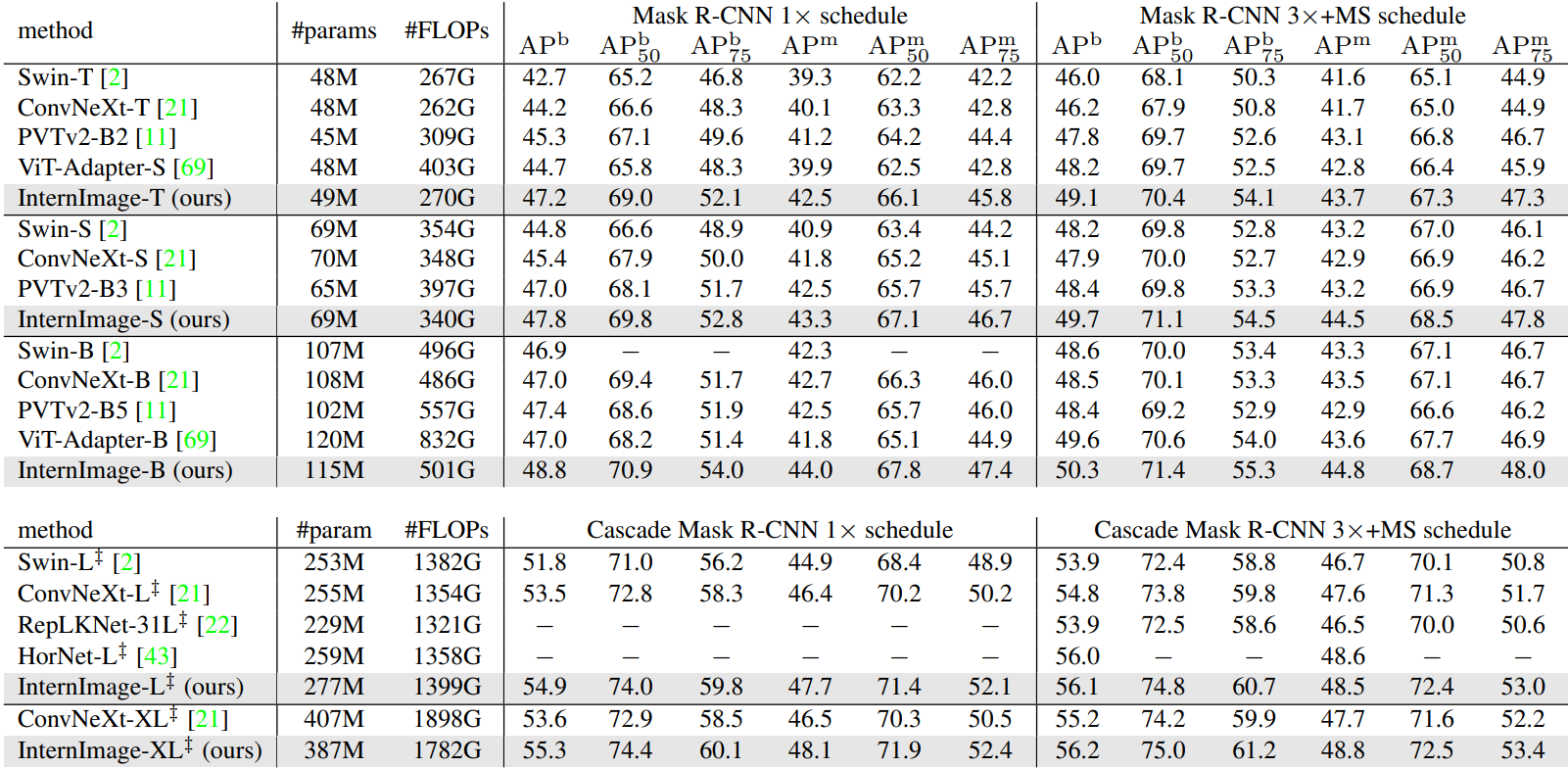
다음은 COCO val2017에서의 object detection과 instance segmentation 성능을 나타낸 표이다.
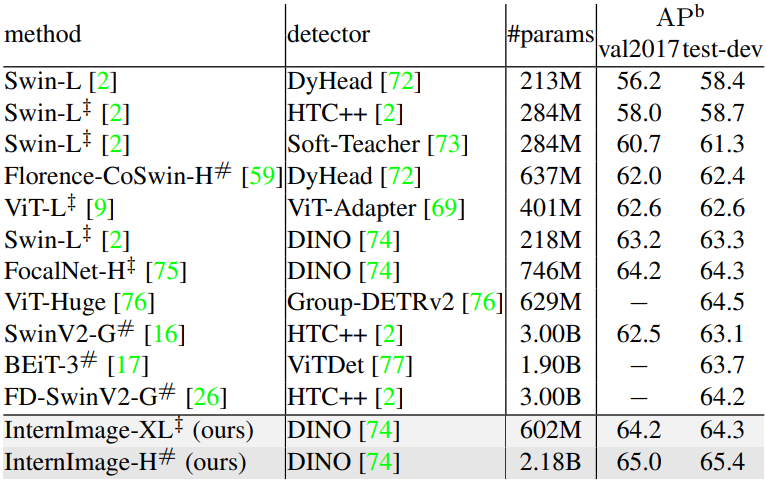
다음은 COCO val2017과 test-dev에서 SOTA detector와 성능을 비교한 표이다.
3. Semantic Segmentation
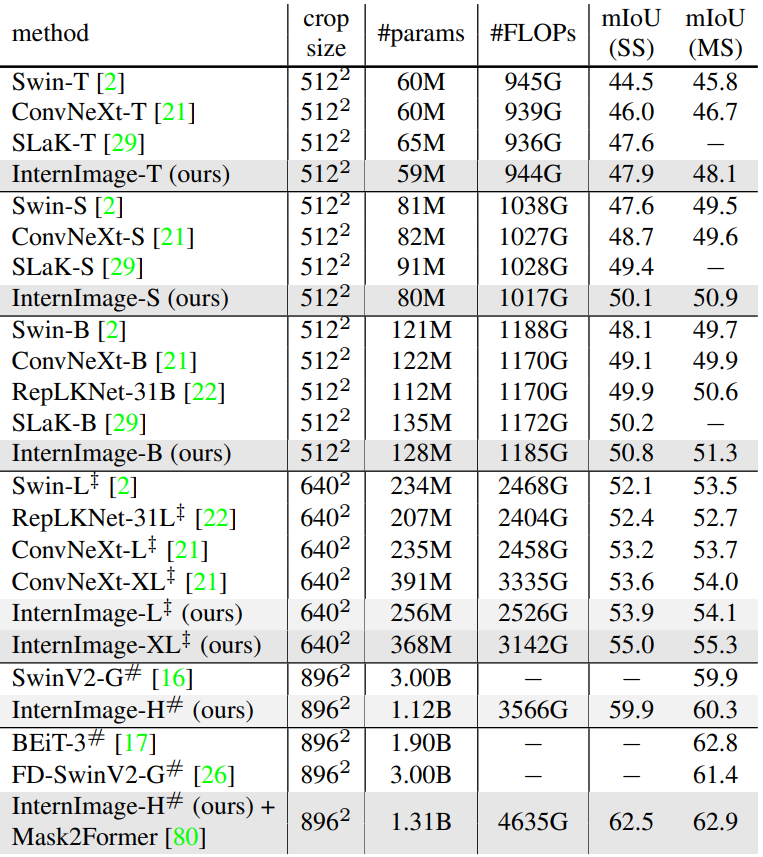
다음은 ADE20K validation set에서의 semantic segmentation 성능을 나타낸 표이다.
4. Ablation Study
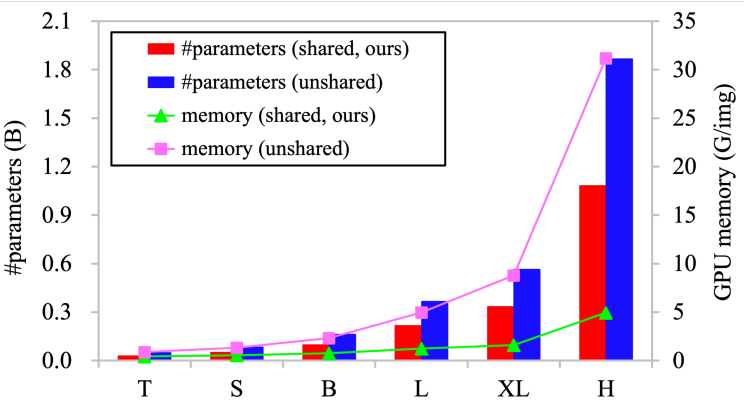
다음은 convolution 뉴런 간의 공유 가중치와 비공유 가중치에 대하혀 모델 파라미터와 GPU 메모리 사용량을 비교한 그래프이다.
다음은 DCNv3의 3가지 수정 사항에 대한 ablation 결과이다.

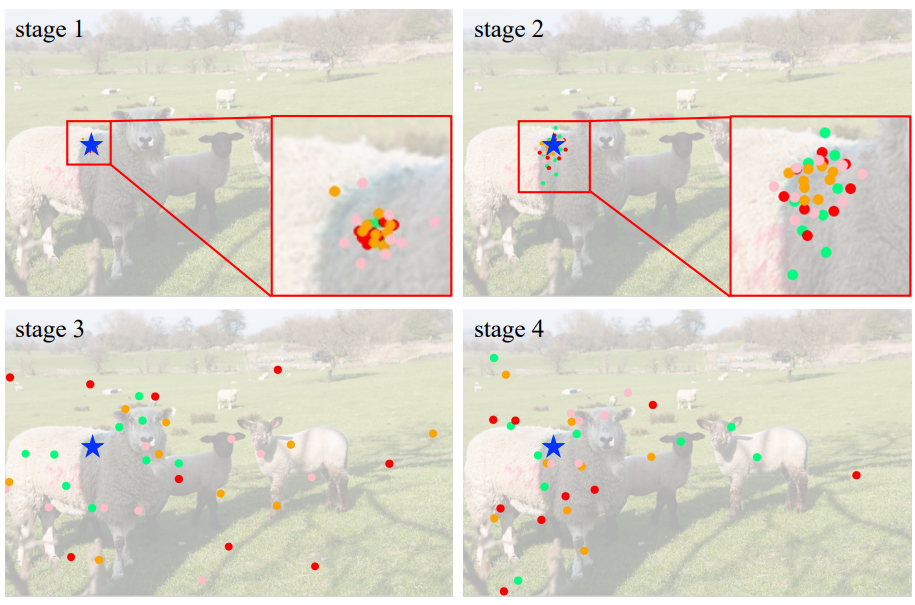
다음은 여러 stage의 여러 그룹에 대한 샘플링 위치를 시각화 한 것이다.