[논문리뷰] InstructPix2Pix: Learning to Follow Image Editing Instructions
CVPR 2023 (Highlight). [Paper] [Page] [Github]
Tim Brooks, Aleksander Holynski, Alexei A. Efros
University of California, Berkeley
12 Apr 2023

Introduction
본 논문은 이미지 편집을 위해 사람이 작성한 명령을 따르도록 생성 모델을 가르치는 방법을 제시한다. 이 task를 위한 학습 데이터는 대규모로 획득하기 어렵기 때문에 서로 다른 modality로 사전 학습된 GPT-3와 Stable Diffusion을 결합한 쌍으로 된 데이터셋을 생성하는 접근 방식을 제안한다. 이 두 모델은 두 modality에 걸친 task에 대한 학습 데이터를 만들기 위해 결합할 수 있는 언어 및 이미지에 대한 보완적인 지식을 캡처한다.
생성된 쌍 데이터를 사용하여 입력 이미지와 편집 방법에 대한 텍스트 명령이 주어지면 편집된 이미지를 생성하는 조건부 diffusion model을 학습시킨다. 본 논문의 모델은 forward pass에서 이미지 편집을 직접 수행하며 추가 예제 이미지, 입력/출력 이미지에 대한 전체 설명 또는 예제별 finetuning이 필요하지 않다. 합성 예제에 대해 전적으로 학습을 받았음에도 불구하고 본 논문의 모델은 임의의 실제 이미지와 자연적인 사람이 작성한 명령 모두에 대해 zero-shot 일반화를 달성한다. 본 논문의 모델은 사람의 명령에 따라 개체 교체, 이미지 스타일 변경, 설정 변경, 예술적 매체 등 다양한 편집들을 수행할 수 있는 직관적인 이미지 편집이 가능하다.
Method

1. Generating a Multi-modal Training Dataset
서로 다른 modality에서 작동하는 두 개의 대규모 사전 학습된 모델의 능력을 결합하여 텍스트 편집 명령과 편집 전후의 해당 이미지를 포함하는 multi-modal 학습 데이터셋을 생성한다.
Generating Instructions and Paired Captions
먼저 텍스트 도메인에서 대규모 언어 모델을 활용하여 이미지 캡션을 가져오고 편집 명령과 편집 후 결과 텍스트 캡션을 생성한다. 예를 들어, 입력 캡션 “말을 타는 소녀의 사진”이 제공되면 언어 모델은 “그녀가 용을 타게 하세요”라는 그럴듯한 편집 명령과 적절하게 수정된 출력 캡션 “용을 타는 소녀의 사진”을 모두 생성할 수 있다. 텍스트 도메인에서 작동하면 이미지 변경과 텍스트 명령 간의 대응 관계를 유지하면서 크고 다양한 편집 컬렉션을 생성할 수 있다.
모델은
- 입력 캡션
- 편집 명령
- 출력 캡션
의 세 가지 편집의 사람이 작성한 상대적으로 작은 데이터셋에서 GPT-3을 finetuning하여 학습한다. Finetuning 데이터셋을 생성하기 위해 저자들은 LAION-Aesthetics V2 6.5+ 데이터셋에서 700개의 입력 캡션을 샘플링하고 수동으로 명령과 출력 캡션을 작성했다. 이 데이터를 사용하여 기본 학습 파라미터를 사용하여 단일 epoch에 대해 GPT-3 Davinci 모델을 finetuning했다.
GPT-3의 방대한 지식과 일반화 능력을 활용하여 finetuning된 모델은 창의적이면서도 합리적인 명령과 캡션을 생성할 수 있다. 데이터셋은 이 학습된 모델을 사용하여 많은 수의 편집 및 출력 캡션을 생성하며 입력 캡션은 LAION-Aesthetics의 실제 이미지 캡션이다. 큰 크기, 콘텐츠의 다양성, 다양한 매체(사진, 그림, 디지털 아트워크)로 인해 LAION 데이터셋을 선택했다고 한다. LAION의 잠재적인 단점은 상당히 noisy하고 무의미하거나 설명이 없는 캡션이 많이 포함되어 있다는 것이다. 생성된 명령과 캡션의 최종 코퍼스는 454,445개의 예제로 구성된다.
사람이 작성한 데이터셋과 GPT-3가 생성한 데이터셋의 샘플은 아래 표와 같다.
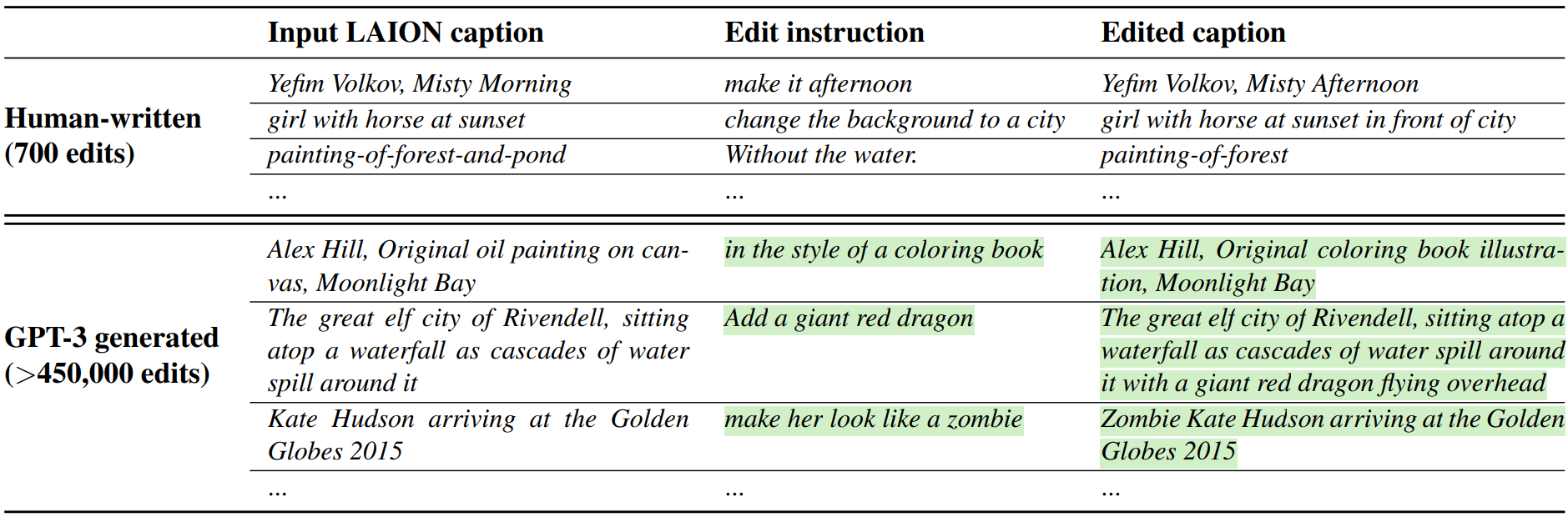
Generating Paired Images from Paired Captions
다음으로 사전 학습된 text-to-image 모델을 사용하여 한 쌍의 캡션(편집 전후 이미지 참조)을 한 쌍의 이미지로 변환한다. 한 쌍의 캡션을 해당 이미지 쌍으로 변환하는 데 있어 한 가지 문제는 text-to-image 모델이 조건 프롬프트의 아주 작은 변경에서도 이미지 일관성에 대한 보장을 제공하지 않는다는 것이다. 예를 들어 “고양이 그림”과 “검은 고양이 그림”이라는 매우 유사한 두 개의 프롬프트는 완전히 다른 고양이 이미지를 생성할 수 있다. 이는 모델이 이미지를 편집하도록 학습시키기 위한 supervision으로 이 쌍을 이룬 데이터를 사용하려는 목적에 적합하지 않다. 따라서 text-to-image diffusion model에서 여러 생성 결과가 유사하도록 장려하는 것을 목표로 하는 Prompt-to-Prompt를 사용한다. Prompt-to-Prompt는 몇 가지 denoising step에서 빌린 cross-attention 가중치를 통해 수행된다. 아래 그림은 Prompt-to-Prompt가 있거나 없는 샘플 이미지를 비교한 것이다.

이렇게 하면 생성된 이미지를 비슷하게 만드는 데 크게 도움이 되지만 다른 편집에는 이미지 space에서 다른 양의 변경이 필요할 수 있다. 예를 들어, 대규모 이미지 구조를 변경하는 것과 같은 더 큰 규모의 변경(예: 개체 이동, 다른 모양의 개체로 대체)은 생성된 이미지 쌍에서 덜 유사성을 요구할 수 있다. 다행스럽게도 Prompt-to-Prompt는 두 이미지 간의 유사성을 제어할 수 있는 파라미터로 attention 가중치를 공유한 denoising step의 비율 $p$를 사용한다. 안타깝게도 캡션과 편집 텍스트만으로 최적의 $p$ 값을 식별하는 것은 어렵다. 따라서 캡션 쌍당 각각 임의의 $p \sim \mathcal{U}(0.1, 0.9)$를 갖는 100개의 샘플 이미지 쌍을 생성하고 CLIP 기반 metric을 사용하여 이러한 샘플을 필터링한다. 이 metric은 두 이미지 캡션 간의 변경과 함께 두 이미지(CLIP space에서) 간의 변경 일관성을 측정한다. 이 필터링을 수행하면 이미지 쌍의 다양성과 품질을 최대화하는 데 도움이 될 뿐만 아니라 Prompt-to-Prompt와 Stable Diffusion에 대한 데이터 생성이 더욱 강력해진다.
2. InstructPix2Pix
생성된 학습 데이터를 사용하여 명령으로부터 이미지를 편집하는 조건부 diffusion model을 학습시킨다. 대규모 text-to-image latent diffusion model인 Stable Diffusion을 기반으로 한다.
Diffusion model은 데이터 분포의 score(고밀도 데이터를 가리키는 방향)를 추정하는 일련의 denoising autoencoder를 통해 데이터 샘플을 생성하는 방법을 학습한다. Latent diffusion은 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$가 있는 사전 학습된 VAE의 latent space에서 작동하여 diffusion model의 효율성과 품질을 향상시킨다. 이미지 $x$의 경우 diffusion process는 인코딩된 latent $z = \mathcal{E}(x)$에 noise를 추가하여 noise level이 timestep $t \in T$에 걸쳐 증가하는 noisy latent $z_t$를 생성한다. 이미지 조건 $c_I$와 텍스트 명령 조건 $c_T$가 주어지면 noisy latent $z_t$에 추가된 noise를 예측하는 네트워크 $\epsilon_\theta$를 학습한다. 다음 latent diffusion 목적 함수를 최소화한다.
\[\begin{equation} L = \mathbb{E}_{\mathcal{E}(x), \mathcal{E}(c_I), c_T, \epsilon \sim \mathcal{N}(0,1), t} [\| \epsilon - \epsilon_\theta (z_t, t, \mathcal{E}(c_I), c_T) \|_2^2] \end{equation}\]Pretraining is All You Need for Image-to-Image Translation 논문은 큰 이미지 diffusion model을 finetuning하는 것이 특히 쌍을 이룬 학습 데이터가 제한적인 경우 이미지 변환 task을 위해 처음부터 모델을 학습하는 것보다 성능이 우수함을 보여주었다. 따라서 방대한 text-to-image 생성 능력을 활용하여 사전 학습된 Stable Diffusion 체크포인트로 모델의 가중치를 초기화한다. 이미지 컨디셔닝을 지원하기 위해 추가 입력 채널을 첫 번째 convolution layer에 추가하여 $z_t$와 $\mathcal{E} (c_I)$를 concat한다. Diffusion model의 모든 가중치는 사전 학습된 체크포인트에서 초기화되고 새로 추가된 입력 채널에서 작동하는 가중치는 0으로 초기화된다. 원래 캡션용으로 의도된 것과 동일한 텍스트 컨디셔닝 메커니즘을 재사용하여 대신 텍스트 편집 명령 $c_T$를 입력으로 사용한다.
Classifier-free Guidance for Two Conditionings
Classifier-free diffusion guidance는 diffusion model에 의해 생성된 샘플의 품질과 다양성을 절충하는 방법이다. 클래스 조건부 및 텍스트 조건부 이미지 생성에서 일반적으로 사용되어 생성된 이미지의 시각적 품질을 개선하고 샘플 이미지가 조건에 더 잘 부합하도록 한다. Classifier-free guidance는 암시적 classifier $p_\theta (c \vert z_t)$가 컨디셔닝 $c$에 높은 likelihood를 할당하는 데이터 쪽으로 확률 질량을 효과적으로 이동시킨다.
Classifier-free guidance는 conditional 및 unconditional denoising를 위한 diffusion model을 공동으로 학습하고 inference 중에 두 score 추정치를 결합하여 구현한다. Unconditional denoising을 위한 학습은 학습 중 특정 확률로 컨디셔닝을 고정된 null 값 $c = \emptyset$로 간단히 설정하여 수행된다. Inference 중에 guidance scale $s \ge 1$을 사용하여 수정된 score 추정치 \(\tilde{e_\theta} (z_t, c)\)는 unconditional한 $e_\theta (z_t, \emptyset)$에서 멀어지고 conditional한 $e_\theta (z_t, c)$를 향하는 방향으로 extrapolate(외삽)된다.
\[\begin{equation} \tilde{e_\theta} (z_t, c) = e_\theta (z_t, \emptyset) + s \cdot (e_\theta (z_t, c) - e_\theta (z_t, \emptyset)) \end{equation}\]본 논문의 경우 score network $e_\theta (z_t, c_I, c_T)$에는 입력 이미지 $c_I$와 텍스트 명령 $c_T$라는 두 가지 컨디셔닝이 있다. 저자들은 두 컨디셔닝에 대해 classifier-free guidance를 활용하는 것이 유익한지 확인했다. Compositional Visual Generation with Composable Diffusion Models 논문은 조건부 diffusion model이 여러 다른 컨디셔닝 값에서 score 추정치를 구성할 수 있음을 보여주었다. 두 개의 별도 컨디셔닝 입력이 있는 모델에 동일한 개념을 적용한다. 학습하는 동안 5%의 예에 대해 $c_I = \emptyset_I$만, 5%의 예에 대해 $c_T = \emptyset_T$만, 그리고 5%의 예에 대해 $c_I = \emptyset_I$와 $c_T = \emptyset_T$를 랜덤하게 설정한다. 따라서 본 논문의 모델은 조건부 입력 둘 다 또는 둘 중 하나에 대해 conditional 또는 unconditional denoising이 가능하다.
생성된 샘플이 입력 이미지와 얼마나 강하게 일치하는지와 편집 명령과 얼마나 강하게 일치하는지를 절충하도록 조정할 수 있는 두 가지 guidance scale인 $s_I$와 $s_T$를 도입한다. 수정된 score 추정치는 다음과 같다.
\[\begin{aligned} \tilde{e_\theta} (z_t, c_I, c_T) &= e_\theta (z_t, \emptyset, \emptyset) \\ &+ s_I \cdot (e_\theta (z_t, c_I, \emptyset) - e_\theta (z_t, \emptyset, \emptyset)) \\ &+ s_T \cdot (e_\theta (z_t, c_I, c_T) - e_\theta (z_t, c_I, \emptyset)) \end{aligned}\]Results
다음은 모나리자를 다양한 예술적 매체로 변환한 결과이다.

다음은 새로운 컨텍스트와 주제를 가진 천지창조이다.

다음은 비틀즈의 Abbey Road 앨범 커버를 다양하게 변환한 결과이다.

다음은 여러 명령을 모델을 반복적으로 적용한 결과이다.

다음은 latent noise를 변경하여 동일한 입력 이미지와 명령에 대해 여러 이미지 편집을 생성한 결과이다.

1. Baseline comparisons
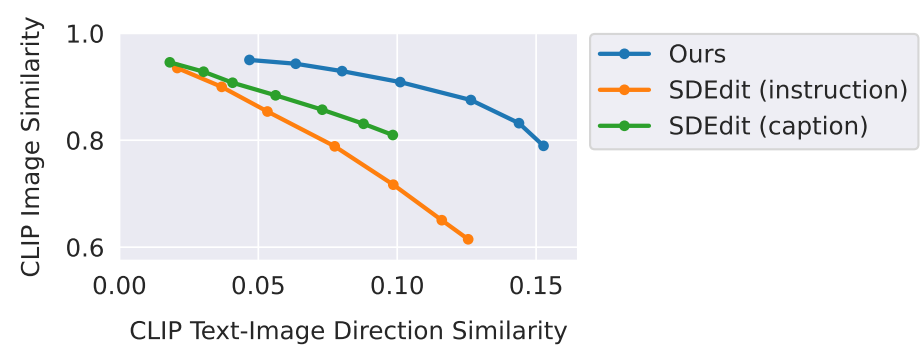
다음은 InstructPix2Pix를 다양한 편집 방법들과 비교한 것이다.

다음은 InstructPix2Pix와 SDEdit을 비교한 그래프이다.
2. Ablations
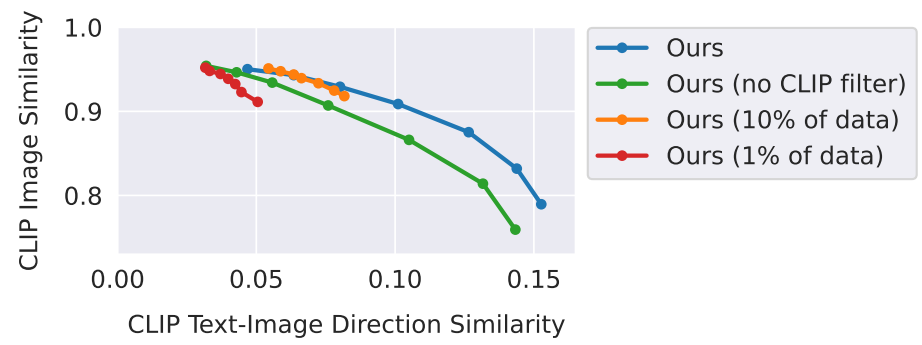
다음은 데이터셋 크기와 데이터셋 필터링 접근법에 대한 ablation study 결과이다. ($s_T$ 고정, $s_I \in [1.0, 2.2]$)
다음은 classifier-free guidance 가중치에 따른 결과를 나타낸 것이다. (텍스트 명령: “Turn him into a cyborg!”)

Limitations
InstructPix2Pix는 생성된 데이터셋의 시각적 품질에 의해 제한되며, 따라서 이미지를 생성하는 데 사용되는 diffusion model에 의해 제한된다. 또한, 새로운 편집으로 일반화하고 시각적 변경 사항과 텍스트 명령 사이의 올바른 연결을 만드는 InstructPix2Pix의 능력은 GPT-3 finetuning에 사용되는 사람이 작성한 명령, 명령을 만들고 캡션을 수정하는 GPT-3의 능력, 그리고 생성된 이미지를 수정하는 Prompt-to-Prompt 능력에 의해 제한된다. 특히, Stable Diffusion과 Prompt-to-Prompt에서와 마찬가지로 개체 수를 세고 공간 추론에 어려움을 겪는다.

실패 예시는 위 그림과 같다. 또한, InstructPix2Pix가 기반으로 하는 데이터 및 사전 학습된 모델에 편향이 있으므로 편집된 이미지는 이러한 편향을 상속하거나 다른 편향을 도입할 수 있다.