[논문리뷰] InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
arXiv 2024. [Paper] [Page] [Github]
Haofan Wang, Qixun Wang, Xu Bai, Zekui Qin, Anthony Chen
InstantX Team
3 Apr 2024

Introduction
Diffusion 기반 text-to-image 생성 모델은 색상, 소재, 분위기, 디자인, 구조와 같은 다양한 요소를 포함하는 스타일의 특성이 불확실하기 때문에 style transfer는 여전히 어려운 task로 남아 있다. 스타일의 다면적인 속성으로 인해 stylize된 데이터셋을 수집하고, 스타일을 정확하게 표현하고, style transfer 성공 여부를 평가하기가 어렵다.
이전 연구들에서는 공통 스타일을 공유하는 이미지 데이터셋에 대하여 diffusion model을 fine-tuning하는 경우가 많았다. 이는 시간이 많이 걸리고 동일한 스타일의 이미지들을 수집하기 어려워 일반화하는 데 제한이 있었다. 최근에는 fine-tuning 없이 style transfer를 하는 tuning-free 접근 방식에 대한 관심이 급증했으며, 크게 두 가지 그룹으로 분류될 수 있다.
- Adapter-free: 이 방법은 diffusion process 프로세스 내에서 self-attention의 힘을 활용한다. 공유된 attention 연산을 활용함으로써 주어진 레퍼런스 스타일 이미지에서 직접 key, value와 같은 feature들을 추출한다.
- Adapter 기반: 레퍼런스 스타일 이미지에서 상세한 이미지 표현을 추출하도록 설계된 경량 모델을 통합한다. 그런 다음 cross-attention 메커니즘을 통해 diffusion process에 이미지 표현을 통합한다. 이를 통해 생성 프로세스를 가이드하여 결과 이미지가 원하는 스타일과 정렬되도록 보장한다.
Tuning-free 방법은 몇 가지 과제에 직면해 있다. Adapter-free 접근 방식을 일반적인 이미지에 적용할 경우 DDIM inversion이나 유사한 방법을 통해 이미지를 latent noise로 다시 반전시켜야 한다. 그러나 이러한 inversion 프로세스로 인해 세밀한 디테일이 손실되어 생성된 이미지의 스타일 정보가 감소할 수 있다. 또한, inversion은 시간이 많이 걸려 실제 적용에서 단점이 된다. Adapter 기반 방법의 경우 레퍼런스 이미지 내의 콘텐츠와 스타일을 효과적으로 분리하여 스타일 강도와 콘텐츠 유실 간의 올바른 균형을 맞추는 것이 본질적으로 어렵다.
본 논문은 이러한 한계를 고려하여 기존 adapter 기반 방법을 기반으로 하는 새로운 tuning-free 메커니즘인 InstantStyle을 도입하였다. 이 메커니즘은 기존의 다른 attention 기반 주입 방법과 원활하게 통합되고 스타일과 콘텐츠를 효과적으로 분리할 수 있다. 보다 구체적으로, 더 나은 style transfer를 달성하는 간단하면서도 효과적인 두 가지 방법을 도입하였다.
- 이전의 adapter 기반 방법에서는 CLIP을 이미지 feature 추출기로 널리 사용했지만 feature space 내에서 feature 분리를 고려한 연구는 거의 없다. 콘텐츠는 일반적으로 스타일보다 텍스트로 설명하기가 더 쉽다. 텍스트와 이미지는 CLIP에서 feature space를 공유하므로 이미지 feature와 콘텐츠 텍스트 feature의 간단한 뺄셈 연산으로 콘텐츠 유실을 효과적으로 줄일 수 있다.
- 저자들은 diffusion model에 스타일 정보 주입을 담당하는 특정 레이어가 있음을 발견했다. 특정 스타일 블록에만 이미지 feature를 주입함으로써 스타일과 콘텐츠의 분리를 암시적으로 수행할 수 있다.
본 논문은 이 두 가지 간단한 전략만으로 스타일을 유지하면서 콘텐츠 유실 문제를 대부분 해결했다.
Methods
1. Motivations

스타일의 정의가 아직 결정되지 않았다. 스타일 일관성을 측정하는 metric이 부족하다. 여기서 핵심은 스타일에 통일된 정의가 부족하다는 것이다. 다양한 장면에서 스타일의 의미는 크게 다르다. 위 그림은 이미지 스타일의 다양성을 보여준다. 스타일은 일반적으로 하나의 요소가 아니라 여러 복잡한 요소의 조합이다. 이는 스타일의 정의를 상대적으로 주관적인 문제로 만들고 동일한 스타일에 대한 여러 가지 합리적인 해석을 통해 고유하지 않게 만든다.
그 결과 대규모로 동일한 스타일의 페어링에 대한 데이터를 수집하는 것이 어렵거나 심지어 불가능하다. 대규모 언어 모델을 사용하여 스타일 설명을 생성한 다음 Midjourney와 같은 text-to-image 생성 모델을 사용하여 특정 스타일의 이미지를 생성한 일부 이전 연구들이 있었다. 그러나 여기에는 몇 가지 문제가 있다. 첫째, 원래 생성된 데이터에는 잡음이 상당히 많고, 세분화된 스타일을 구별하기 어렵기 때문에 정리가 상당히 어렵다. 둘째, 세밀한 스타일 중 다수는 텍스트를 통해 명확하게 설명할 수 없기 때문에 스타일 수가 제한되는 경우가 많고 스타일 유형은 Midjourney의 능력에 따라 제한되어 다양성이 제한될 수 있다.

Inversion에 의한 스타일 열화. Inversion 기반 방법에서는 입력 레퍼런스 이미지와 텍스트 설명이 주어지면 이미지에 대해 DDIM inversion 기법을 사용하여 $x_T$부터 $x_0$까지의 반전된 궤적을 얻고 근사를 통해 이미지를 latent noise 표현으로 변환한다. 그런 다음 $x_T$와 새로운 프롬프트들에서 시작하여 정렬된 스타일을 사용하여 새 콘텐츠를 생성한다. 그러나 위 그림에서 볼 수 있듯이 실제 이미지에 대한 DDIM inversion은 local linearization 가정에 의존하기 때문에 불안정하며, 이로 인해 오차가 전파되어 잘못된 이미지 재구성과 콘텐츠 손실이 발생한다. Inversion 결과는 텍스처, 재료 등과 같은 세밀한 스타일 정보를 많이 잃게 된다. 이 경우 스타일을 잃은 이미지를 guidance 조건으로 사용하는 것은 분명히 style transfer를 효과적으로 달성할 수 없다. 또한 inversion process는 생성 속도가 매우 느리다.

스타일 강도와 콘텐츠 유실 간의 균형. 스타일 조건 주입에도 균형이 있다. 이미지 조건의 강도가 너무 높으면 콘텐츠가 유실될 수 있고, 강도가 너무 낮으면 스타일이 뚜렷하지 않을 수 있다. 그 핵심 이유는 이미지의 콘텐츠와 스타일이 결합되어 있고 스타일의 불확실한 속성으로 인해 둘을 분리하기 어려운 경우가 많기 때문이다. 따라서 일반적으로 스타일 강도와 텍스트 제어 가능성의 균형을 맞추기 위해 각 레퍼런스 이미지에 대해 세심한 가중치 조정이 필요하다.
2. Observations

Adapter의 능력이 과소평가되었다. 흥미롭게도 저자들은 대부분의 이전 연구들에서 IP-Adapter의 style transfer 능력에 대한 평가가 편향되어 있음을 발견했다. 그 중 일부는 고정된 파라미터를 사용하여 IP-Adapter의 텍스트 제어 기능이 약하다고 주장하는 반면 다른 연구들은 콘텐츠 유실 문제를 강조하였다. 이는 앞서 설명한 대로 적절한 강도가 설정되지 않은 것에 기인할 수 있다.
IP-Adapter는 K와 V의 두 세트를 사용하여 cross-attention의 텍스트와 이미지를 처리하고 최종적으로 선형적으로 가중치를 적용하므로 강도가 너무 높으면 필연적으로 텍스트의 제어 능력이 저하된다. 동시에 이미지의 콘텐츠와 스타일이 분리되지 않아 콘텐츠 유실 문제도 발생한다. 이를 수행하는 가장 간단하고 효과적인 방법은 더 낮은 강도를 사용하는 것이다. 그러나 가중치 조정이 매우 까다롭고 항상 작동하는 것은 아니다.

CLIP의 임베딩들은 서로 뺄 수 있다. 원래 CLIP 모델은 약하게 정렬된 대규모 텍스트-이미지 쌍에 대해 학습된 contrastive loss를 사용하여 공유된 embedding space 내에서 이미지와 텍스트 모달리티를 통합하는 것을 목표로 했다. 이전 adapter 기반 방법의 대부분은 사전 학습된 CLIP 이미지 인코더 모델을 사용하여 주어진 이미지에서 이미지 feature를 추출하였다. 이 중 CLIP 이미지 인코더의 글로벌 이미지 임베딩은 이미지의 전체적인 콘텐츠와 스타일을 포착할 수 있어 널리 활용되고 있다.
위 그림에서 볼 수 있듯이 CLIP의 feature space는 호환성이 좋으며 동일한 feature space의 feature는 더하고 뺄 수 있다. 이미지에 콘텐츠와 스타일 정보가 모두 포함되어 있고 스타일과 비교할 때 콘텐츠는 텍스트로 설명될 수 있으므로 새로운 feature가 여전히 CLIP space에 있다고 가정하면 이미지 feature의 콘텐츠 부분을 명시적으로 제거할 수 있다.
블록들의 영향은 동일하지 않다. CNN에 많은 연구에 따르면 얕은 convolution layer는 모양, 색상 등과 같은 낮은 레벨의 표현을 학습하는 반면, 상위 레벨 레이어는 semantic 정보에 중점을 둔다. Diffusion 기반 모델에도 동일한 논리가 존재한다. 텍스트 조건과 마찬가지로 이미지 조건도 일반적으로 cross-attention layer를 통해 주입되어 생성을 가이드한다.

저자들은 서로 다른 attention layer가 스타일 정보를 다르게 포착한다는 것을 발견했다. 저자들은 위 그림과 같은 실험에서 스타일 보존에 중요한 역할을 하는 두 개의 특수 레이어가 있음을 발견했다.
- up_blocks.0.attentions.1: 6번째 블록, 스타일을 캡처
- down_blocks.2.attentions.1: 4번째 블록, 공간 레이아웃을 찾아냄
3. Methodology
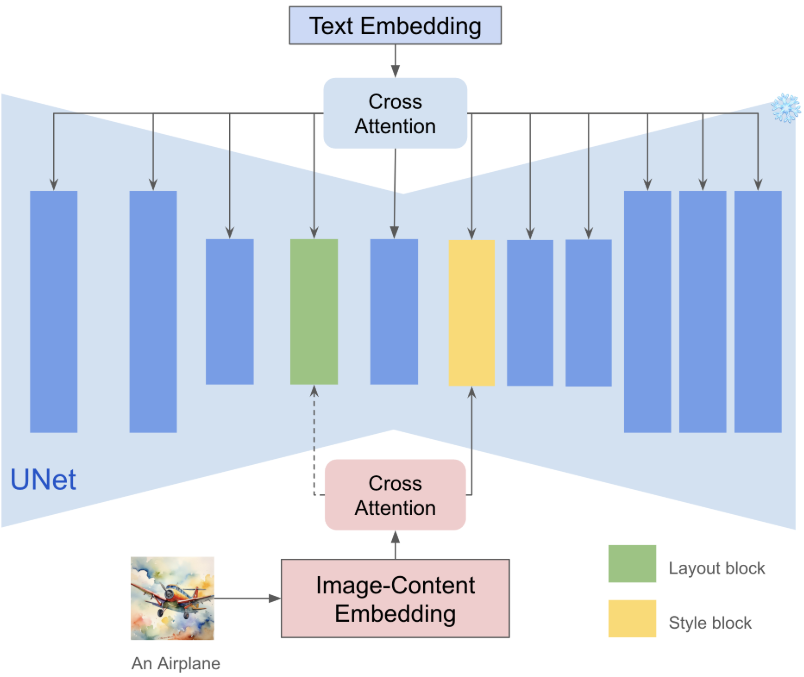
이미지에서 콘텐츠를 분리. 불확실한 스타일 속성에 비해 콘텐츠는 일반적으로 텍스트로 표현될 수 있으므로 CLIP의 텍스트 인코더를 사용하여 콘텐츠 텍스트의 특성을 콘텐츠 표현으로 추출할 수 있다. 동시에 CLIP의 이미지 인코더를 사용하여 레퍼런스 이미지의 feature를 추출한다. 이미지 feature에서 콘텐츠 텍스트 feature를 빼면 스타일과 콘텐츠를 명시적으로 분리할 수 있으므로 CLIP의 이점을 누릴 수 있다. 이 전략은 간단하지만 콘텐츠 유실을 완화하는 데 매우 효과적이다.
스타일 블록에만 삽입. 6번째 블록은 스타일을 캡처하고 4번째 블록은 공간 레이아웃을 찾는다. 이미지 feature를 스타일 블록에 주입하여 스타일을 원활하게 transfer할 수 있다. 또한 adapter의 파라미터 수가 대폭 줄어들어 텍스트 제어 능력도 향상된다. 이를 통해 스타일 정보를 암시적으로 추출하여 스타일의 강도를 잃지 않으면서 콘텐츠 유실을 더욱 방지할 수 있다.
Experiments
- 구현 디테일
- Diffusion model: Stable Diffusion XL (SDXL)
- Adapter: 사전 학습된 IP-Adapter
1. Qualitative Results
다음은 본 논문의 방법으로 style transfer를 진행한 결과들이다.


다음은 이미지 기반 stylization 결과이다.

2. Comparison to Previous Methods
다음은 기존 방법들과 비교한 결과이다.

3. Ablation Study
다음은 CLIP 임베딩들을 서로 빼는 것의 효과를 시각화한 것이다.

다음은 전략의 효과를 비교한 것이다.
